Diffusion Model
【碎碎念】感觉Diffusion Model里面的数学公式太多了QwQ,所以自己稍微梳理一下。
我自己是听B站的课程:李宏毅课程听懂的,感觉讲得很清楚
概念模型
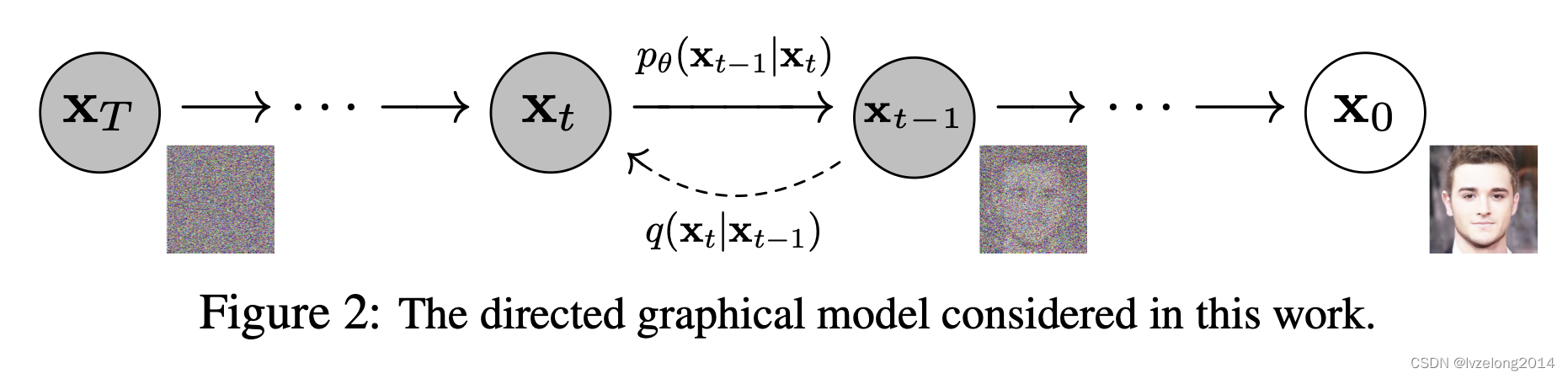
Diffusion Model的基本思想就是:
- 把一张图片通过 T T Tstep 添加高斯噪声,最后会形成一个高斯分布, N ( 0 , I ) \mathcal N(0,\mathbf{I}) N(0,I)
- 把添加噪声的每步图片 x 0 ⋯ x T x_0\cdots x_T x0⋯xT看成随机过程,则形成一个马尔可夫链,每一步是已知的 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)
- 设置一个Network,网络中的参数 θ \theta θ作为先验,如果能预测出逆过程 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt),就可以从噪声图片生成图片
算法流程

主算法流程如上图,解释以下大致思路:
训练部分:
- Sample一张图片 x 0 \mathbf{x}_0 x0
- 选择一个步骤 t t t
- 优化目标:Denoise网络,给定 t t t和 t t t步的噪图,能够预测 t − 1 t-1 t−1步到 t t t步添加的噪声长什么样子
推理部分:
- Sample一张噪图
- 从 T T T步开始一步一步通过Denoise推理出真实图片
实际上上述只是一个非常粗略的解释,要真正理解这个算法,还有如下几个问题要解决:
- 如何生成 t t t步的噪图
- 形式化Denoise的优化目标
生成t步的噪图
每一步逐渐混入方差为
β
i
\beta_i
βi的高斯噪声,得到下面的式子
q
(
x
t
∣
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
q(\mathbf{x}_t|\mathbf{x}_{t-1})=\mathcal N(\mathbf{x}_t;\sqrt{1-\beta_t} \mathbf{x}_{t-1},\beta_t \mathbf{I})
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
用重参数化的写法是:
x
t
=
1
−
β
t
x
t
−
1
+
β
t
ϵ
t
ϵ
t
∼
N
(
0
,
I
)
\mathbf{x_t}=\sqrt{1-\beta_t}\mathbf{x}_{t-1}+\sqrt \beta_t \epsilon_t \\ \epsilon_t\sim\mathcal N(0,\mathbf{I})
xt=1−βtxt−1+βtϵtϵt∼N(0,I)
进一步推到
x t = 1 − β t x t − 1 + β t ϵ t = 1 − β t ( 1 − β t − 1 x t − 2 + β t − 1 ϵ t − 1 ) + β t ϵ t = ( 1 − β t ) ( 1 − β t − 1 ) x t − 2 + 1 − ( 1 − β t ) ( 1 − β t − 1 ) ϵ = ⋯ = α t x 0 + 1 − α t ϵ , α t = ∏ i = 1 t 1 − β t \mathbf{x}_t=\sqrt {1 - \beta_t} \mathbf{x}_{t-1}+\sqrt {\beta_t} \epsilon_t \\ = \sqrt{1-\beta_t}(\sqrt{1-\beta_{t-1}}\mathbf{x}_{t-2}+\sqrt {\beta_{t-1}}\epsilon_{t-1})+\sqrt {\beta_t} \epsilon_t \\ =\sqrt{(1-\beta_t)(1-\beta_{t-1})}\mathbf{x}_{t-2}+\sqrt{1 - (1 - \beta_t)(1-\beta_{t-1})}\epsilon \\ =\cdots \\ = \sqrt{\alpha_t}\mathbf{x}_0+\sqrt{1-\alpha_t}\mathbf\epsilon,\\ \alpha_t=\prod_{i=1}^t 1-\beta_t xt=1−βtxt−1+βtϵt=1−βt(1−βt−1xt−2+βt−1ϵt−1)+βtϵt=(1−βt)(1−βt−1)xt−2+1−(1−βt)(1−βt−1)ϵ=⋯=αtx0+1−αtϵ,αt=i=1∏t1−βt
这是根据高斯的可加性原理推导得出的结论。也就是,不需要一步步加,可以一次性推导到位。
优化目标
假设整体的
T
T
T步网络生成的概率分布是
p
θ
p_\theta
pθ,那么其实优化的目标可以是:
max
θ
E
x
0
∼
p
d
a
t
a
(
x
0
)
[
l
o
g
p
θ
(
x
0
)
]
\max_\theta \mathbb{E}_{x_0\sim p_{data}(x_0)}[logp_\theta(\mathbf{x}_0)]
θmaxEx0∼pdata(x0)[logpθ(x0)]
这个优化目标可以解释为Sample所有数据集的图片,这些图片被 p θ p_\theta pθ 生成的概率乘积最大(取了个log)
接下来其实利用了一个著名的VLB(变分下界)的定理,这个定理再VAE中使用过,具体的证明可以看视频,这里直接出结论:
log
p
θ
(
x
0
)
≥
E
x
1
⋯
x
T
∼
q
(
x
1
⋯
x
T
∣
x
0
)
[
log
p
θ
(
x
0
⋯
x
T
)
q
(
x
1
⋯
x
T
∣
x
0
)
]
\log p_\theta(\mathbf{x}_0)\geq \mathbb E_{\mathbf{x}_1\cdots \mathbf{x}_T\sim q(\mathbf{x}_1\cdots \mathbf{x}_T|\mathbf{x}_0)}[\log \frac{p_\theta(\mathbf{x}_0\cdots \mathbf{x}_T)}{q(\mathbf{x_1}\cdots \mathbf{x}_T|\mathbf{x}_0)}]
logpθ(x0)≥Ex1⋯xT∼q(x1⋯xT∣x0)[logq(x1⋯xT∣x0)pθ(x0⋯xT)]
原论文经过了一番精彩的数学推导(注意,这段推导是取符号转化成最小化的Loss,所以符号要反着看):
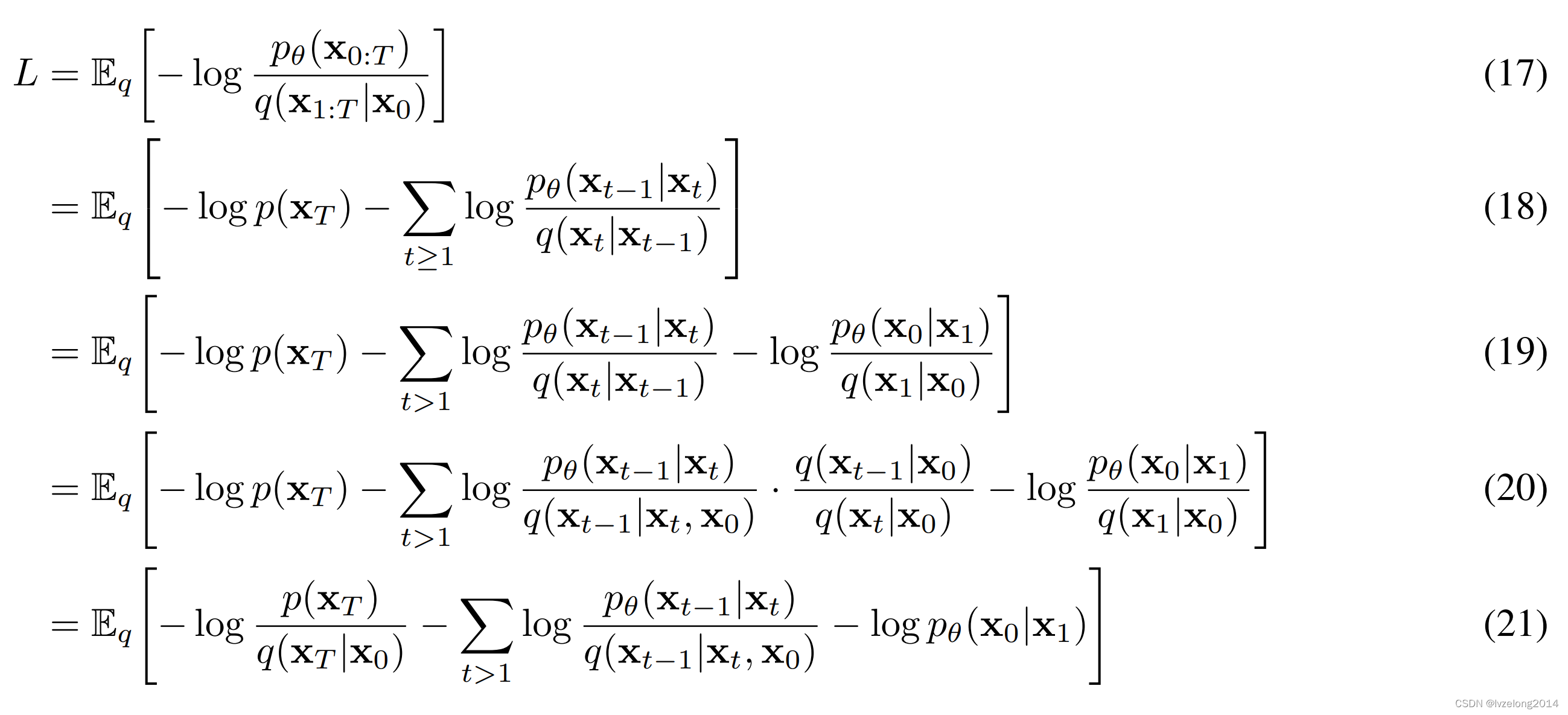
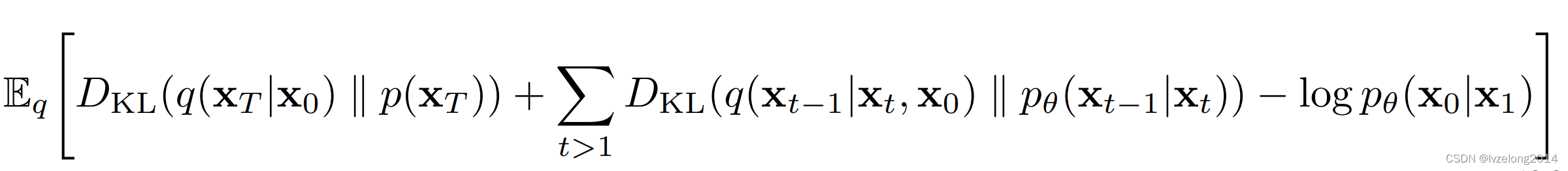
关于这段推导变换的精妙之处,先占个坑,暂时没想出来~
注意到
p
(
x
T
)
p(\mathbf{x}_T)
p(xT)就是变换到最后的噪声图,而
q
(
x
T
∣
x
0
)
q(\mathbf{x}_T|\mathbf{x}_0)
q(xT∣x0)是一个固定的过程,这两者都和网络没关系,所以可以直接在优化项中舍去。
q ( x t − 1 ∣ x t , x 0 ) q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0) q(xt−1∣xt,x0)的推导
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
−
1
,
x
t
,
x
0
)
q
(
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
0
)
q
(
x
t
∣
x
0
)
q
(
x
0
)
=
q
(
x
t
∣
x
t
−
1
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
q(x_{t-1}|x_t,x_0)=\frac{q(x_{t-1},x_t,x_0)}{q(x_t,x_0)}=\frac{q(x_t|x_{t-1})q(x_{t-1}|x_0)q(x_0)}{q(x_t|x_0)q(x_0)}=\frac{q(x_t|x_{t-1})q(x_{t-1}|x_0)}{q(x_t|x_0)}
q(xt−1∣xt,x0)=q(xt,x0)q(xt−1,xt,x0)=q(xt∣x0)q(x0)q(xt∣xt−1)q(xt−1∣x0)q(x0)=q(xt∣x0)q(xt∣xt−1)q(xt−1∣x0)
发现等式后面每项都是已知的,然后开始经过一番魔幻推导

结果就是还是一个高斯分布
梳理一下思路:我们现在有两个高斯分布
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_t,x_0)
q(xt−1∣xt,x0),
p
θ
(
x
t
−
1
∣
x
t
)
p_\theta(x_{t-1}|x_t)
pθ(xt−1∣xt),后者就是我们的降噪网络,我们的目标是让我们的降噪网络和
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_t,x_0)
q(xt−1∣xt,x0)的分布尽量接近。
再进一步思考,实际上
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_t,x_0)
q(xt−1∣xt,x0)的意思就是给定初始图片,
t
→
t
−
1
t\to t-1
t→t−1这个逆过程的分布
而我们的网络是要生成一个降噪网络,这个优化目标告诉我们,需要在没有初始图片的情况下去拟合这个
t
→
t
−
1
t\to t-1
t→t−1
非常的合理,只不过使用了严谨的数学公式去推导了这个过程罢了。
关于最后一项,说是和VAE类似的处理方法,先占个坑,不解释
优化过程
- q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)是一个高斯分布,那我们让 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt)也是高斯分布就行了。
- q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)的方差是确定的,那我们让 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt)的方差和它一样就行了
- 所以最后我们需要最小化的,就是两者的平均值。
继续化简

我们让两者形式一致,最后我们需要predict只剩下最后一小项
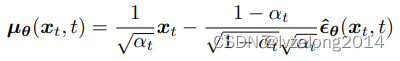
这就是Alog1,2的来源
这篇文章到这里就暂告一段落了,参考文献:
https://arxiv.org/pdf/2208.11970.pdf