目录
1、定义log.py日志
2、在基础封装层初始化类uitls.__init__.py中选择了日志的打印级别,
3、定义页面基础类base_page.py,定义了页面找元素的方法,
4、将百度页面的元素以代码形式保存,baidu.py
5、重新封装浏览器方法, browser.py
6、编写测试用例
简介:
企业级自动化测试中,要写的代码太多了,写着写着会发现很多的代码都重复的写,而且硬编码导致了代码很冗余,一大坨一大坨,当出现了问题后,不好剖析原因以及快速找到对应的解决办法。
写成POM三层架构就方便管理代码,而且避免了代码的冗余。
目的:使代码结构清晰,方便管理代码,将代码和业务分开来,一定程度实现了解耦合性。
文件夹层级如下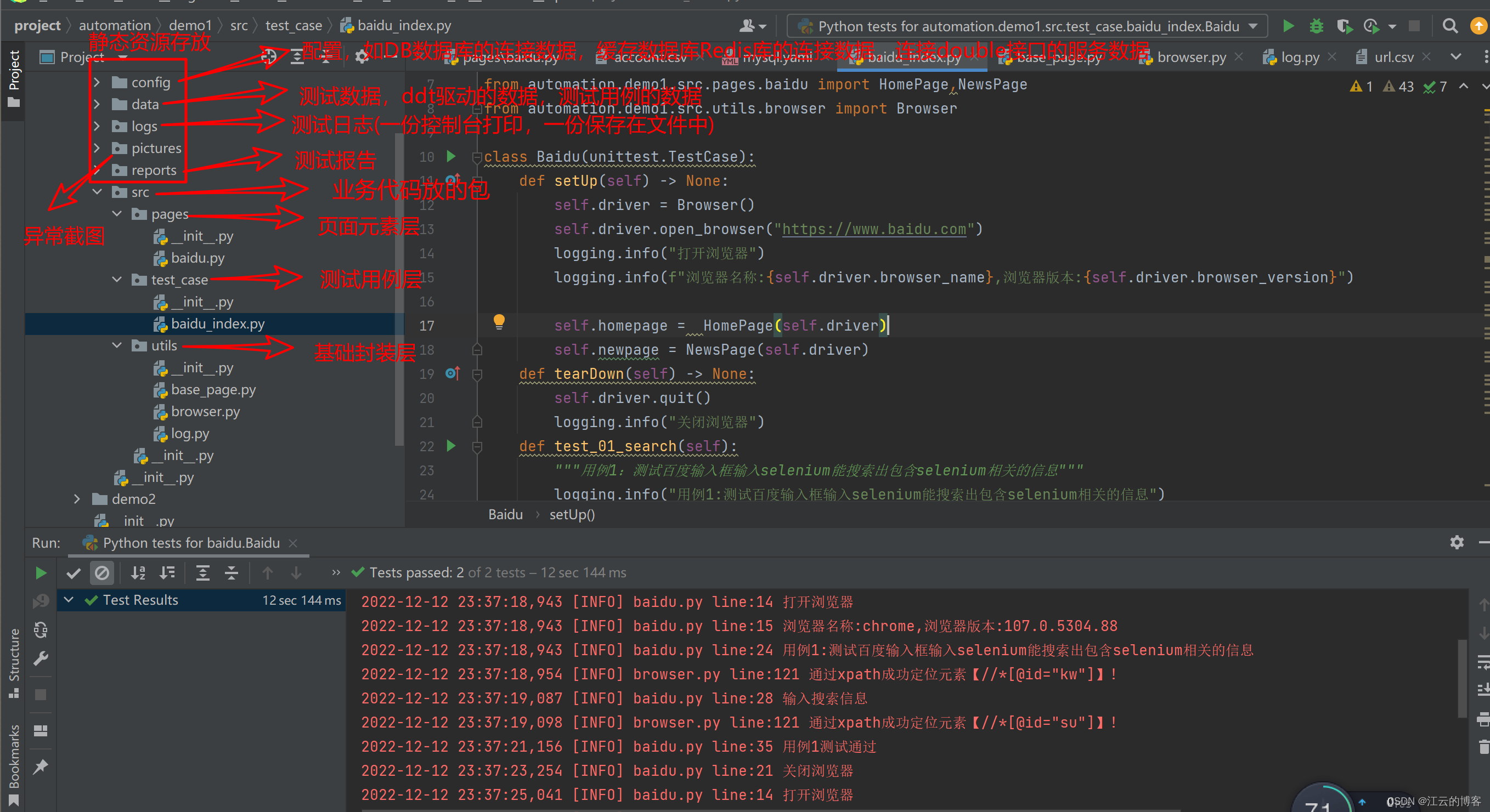
1、定义log.py日志
①定义了日志的存放的位置,
②定义的日志的最大存放大小,
③定义了日志的输出格式,
④日志即打印在控制台上也写入日志文件中,
import os
import logging
import time
from logging.handlers import RotatingFileHandler
def log(log_level="DEBUG"):
logger = logging.getLogger()
logger.setLevel(log_level)
log_size = 1024*1024*20
dir_name = "../../logs/"
if not os.path.exists(dir_name):
os.mkdir(dir_name)
time_str = time.strftime("%Y%m%d",time.localtime())
fh = RotatingFileHandler(dir_name+f"{time_str}.log",encoding="utf-8",maxBytes=log_size,backupCount=100)
#将日志输出到控制台
ch = logging.StreamHandler()
#设置输出日志格式
formatter = logging.Formatter(
fmt="%(asctime)s [%(levelname)s] %(filename)s line:%(lineno)s %(message)s",
)
#为handler指定输出格式,注意大小写
fh.setFormatter(formatter)
ch.setFormatter(formatter)
#为logger添加的日志处理器
logger.addHandler(fh)
logger.addHandler(ch)2、在基础封装层初始化类uitls.__init__.py中选择了日志的打印级别,
在browser.py中会使用,使用日志时只需导入logging包,使用logging.info("日志信息")的方式即可
from .log import log
log("INFO")3、定义页面基础类base_page.py,定义了页面找元素的方法,
①专门服务于页面类,用于寻找元素,
②使用了显示等待,设置了没找到元素时重复寻找的次数和隔多长时间找一次
③定义了driver驱动,则继承他的类在实例化时需要传入驱动
class BasePage(object):
def __init__(self,driver):
self.__driver = driver
def find_element(self,by,value,times=10,wait_time=1)->object:
return self.__driver.until_find_element(by,value,times=times,wait_time=wait_time)4、将百度页面的元素以代码形式保存,baidu.py
①HomePage类继承了BasePage类,则可使用他的方法
②方法上添加@property,则调用这方法时可以像调用属性的方式一样(如:eles=对象.link_xinwen)
from automation.demo1.src.utils.base_page import BasePage
class HomePage(BasePage):
@property
def link_xinwen(self):
return self.find_element('xpath', '//*[@id="s-top-left"]/a[1]')
@property
def link_hao123(self):
return self.find_element('xpath', '//*[@id="s-top-left"]/a[2]')
@property
def link_ditu(self):
return self.find_element('xpath', '//*[@id="s-top-left"]/a[3]')
@property
def link_tieba(self):
return self.find_element('xpath', '//*[@id="s-top-left"]/a[4]')
@property
def link_shipin(self):
return self.find_element('xpath', '//*[@id="s-top-left"]/a[5]')
@property
def link_tupian(self):
return self.find_element('xpath', '//*[@id="s-top-left"]/a[6]')
@property
def link_wangpan(self):
return self.find_element('xpath', '//*[@id="s-top-left"]/a[7]')
@property
def link_gengduo(self):
return self.find_element('xpath', '//*[@id="s-top-left"]/div/a')
@property
def shurukuang(self):
return self.find_element('xpath', '//*[@id="kw"]')
@property
def baiduyixia(self):
return self.find_element('xpath', '//*[@id="su"]')
@property
def shezhi(self):
return self.find_element('xpath', '//*[@id="s-usersetting-top"]')
@property
def denglu(self):
return self.find_element('xpath', '//*[@id="s-top-loginbtn"]')
@property
def link_fanyi(self):
return self.find_element('xpath','//*[@id="s-top-more"]/div[1]/a[1]')
class NewsPage(BasePage):
@property
def help_link(self):
return self.find_element("xpath",'//*[@id="sbox"]/tbody/tr/td[2]/table/tbody/tr/td[2]/a')
5、重新封装浏览器方法, browser.py
①初始化寻找驱动
②打开浏览器,输入地址,且最大化
③切换窗口
④悬浮到元素
④JS下拉滚动条
⑤下拉滚动条到某位置
⑥下拉滚动条到某元素
⑦JS点击元素
⑧JS使元素变为可点击状态
⑨JS修元素属性
⑩获取浏览器名字和版本
11,智能寻找元素
12,智能点击元素
import logging
import time
from selenium.webdriver import Chrome, Firefox, ActionChains
from selenium.common.exceptions import NoSuchElementException, ElementNotInteractableException
class Browser(Chrome, Firefox):
def __init__(self, browser_type="chrome", driver_path=None, *args, **kwargs):
"""
:param browser_type:浏览器类型,如果不传则默认是谷歌浏览器
:param driver_path:驱动的地址
:param args:可变列表参数
:param kwargs:可变字典参数
"""
# 检查browser_type是否合法
if browser_type not in ["chrome", "firefox"]:
logging.error("browser_type浏览器类型即不是谷歌也不是火狐")
raise ValueError("browser_type浏览器类型既不是谷歌也不是火狐")
self.__browser_type = browser_type
# 根据__browser_type的类型选择对于的驱动
if self.__browser_type == "chrome":
if driver_path:
Chrome.__init__(self, executable_path=f"{driver_path}/chromedirver.exe", *args, **kwargs)
else:
Chrome.__init__(self, *args, **kwargs)
elif self.__browser_type == 'firefox':
if driver_path:
Firefox.__init__(self, executable_path=f"{driver_path}/geckodriver.exe", *args, **kwargs)
else:
Firefox.__init__(self, *args, **kwargs)
#打开页面且最大化,习惯性需要最大化,不然容易出现问题
def open_browser(self, url):
self.get(url)
self.maximize_window()
# 切换窗口
def switch_to_new_page(self):
# 获取目前窗口与最后窗口的对比
current_handle = self.current_window_handle
handles = self.window_handles
if current_handle != handles[-1]:
self.switch_to.window(handles[-1])
# 悬浮到元素
def suspension(self, ele):
ActionChains(self).move_to_element(ele).perform()
# 下拉滚动条-通过滚动滚动条
def scrollTo1(self):
self.execute_script("document.documentElement.scrollTop=10000")
time.sleep(1)
# 下拉滚动条-通过位置
def scrollTo2(self):
self.execute_script("window.scrollTo(0,100000)")
time.sleep(1)
# 下拉滚动条到某元素
def scrollTo3(self, ele):
self.execute_script("arguments[0].scrollIntoView()", ele)
time.sleep(1)
# 使用js点击元素
def js_click(self, button):
self.execute_script("$(arguments[0]).click();", button)
# 使元素变成可点击状态
def js_enable(self,ele):
self.execute_script('arguments[0].removeAttribute(\"disabled\")',ele)
# 修改元素不可点击的状态
def js_disable(self,ele):
self.execute_script('arguments[0].setAttribute(arguments[1],arguments[2])',ele,'disabled','enable')
@property
def browser_name(self):
return self.capabilities["browserName"]
@property
def browser_version(self):
return self.capabilities["browserVersion"]
def until_find_element(self, by, value, times=10, wait_time=0.5):
"""
用于定位元素
:param by:定位元素的方式
:param value:定位元素的值
:param times:定位元素的重试次数
:param wait_time:定位元素失败的等待时间
:return:返回定位的元素
"""
# 检查by的合法性
if by not in ["id", "name", "class", "tag", "text", "partial_text", "css", "xpath"]:
logging.error(f"无效的定位方式:{by},请输入id,name,class,tag,text,partial_text,css,xpath")
for i in range(times):
# 定位元素
el = None
try:
if by == "id":
el = super().find_element_by_id(value)
elif by == "name":
el = super().find_element_by_name(value)
elif by == "class":
el = super().find_element_by_class_name(value)
elif by == "tag":
el = super().find_element_by_tag_name(value)
elif by == "text":
el = super().find_element_by_link_text(value)
elif by == "partial_text":
el = super().find_element_by_partial_link_text(value)
elif by == "css":
el = super().find_element_by_css_selector(value)
elif by == "xpath":
el = super().find_element_by_xpath(value)
except NoSuchElementException:
logging.error(f"通过{by}未能找到元素【{value}】,正在进行第{i + 1}此重试...")
time.sleep(wait_time)
else:
# 如果成功定位元素则返回元素
logging.info(f"通过{by}成功定位元素【{value}】!")
return el
logging.error(f"通过{by}无法定位元素【{value}】,请检查...")
raise NoSuchElementException(f"哦通过{by}无法定位元素【{value}】,请检查...")
def click(self,button,repeat=5):
for i in repeat:
# 判断元素是否可见和可点击
if(button.is_displayed() and button.is_enabled()):
button.click()
return
logging.info(f"元素{button},是不可见得,或者是不可点击的")
raise ElementNotInteractableException(f"元素{button},是不可见的,或者是不可点击的")
if __name__ == '__main__':
try:
browser = Browser()
browser.open_browser('http://sahitest.com/demo/clicks.htm')
ele_disable1 = browser.find_element('xpath','/html/body/form/input[5]')
# browser.js_click(ele_disable1)
browser.js_enable(ele_disable1)
browser.addAttribute(browser,ele_disable1,'disable')
time.sleep(2)
ele_disable1.click()
finally:
time.sleep(15)
browser.quit()
6、编写测试用例
①起始工作,打开浏览器输入地址
②结束工作,关闭浏览器
①用例1:测试百度输入框输入selenium能搜索出包含selenium相关的信息
②用例2:测试通过百度首页进入新闻界面
③用例3:测试能进入hao123界面
。。。。。。
import unittest
import time
import logging
from selenium.webdriver import ActionChains
from automation.demo1.src.pages.baidu import HomePage,NewsPage
from automation.demo1.src.utils.browser import Browser
class Baidu(unittest.TestCase):
def setUp(self) -> None:
self.driver = Browser()
self.driver.open_browser("https://www.baidu.com")
logging.info("打开浏览器")
logging.info(f"浏览器名称:{self.driver.browser_name},浏览器版本:{self.driver.browser_version}")
self.homepage = HomePage(self.driver)
self.newpage = NewsPage(self.driver)
def tearDown(self) -> None:
self.driver.quit()
logging.info("关闭浏览器")
def test_01_search(self):
"""用例1:测试百度输入框输入selenium能搜索出包含selenium相关的信息"""
logging.info("用例1:测试百度输入框输入selenium能搜索出包含selenium相关的信息")
#输入搜索信息
self.homepage.shurukuang.send_keys("selenium_automation")
logging.info("输入搜索信息")
#点击按钮
self.homepage.baiduyixia.click()
time.sleep(2)
#校验搜索结果
els = self.driver.find_element_by_partial_link_text("Selenium")
self.assertIsNotNone(els)
logging.info("用例1测试通过")
def test_02_access_help_news(self):
"""用例2:测试通过百度首页进入新闻界面"""
logging.info("用例2:测试通过百度首页能进入新闻界面")
#点击新闻链接
self.homepage.link_xinwen.click()
logging.info("点击新闻链接")
#切换窗口
self.driver.switch_to_new_page()
logging.info("切换窗口")
#点击游戏链接
self.newpage.help_link.click()
logging.info("点击游戏链接")
#校验url
current_rul = self.driver.current_url
self.assertEqual(current_rul,"https://help.baidu.com/")
logging.info("用例2测试通过")
def test_03_access_hao123(self):
"""用例3:测试能进入hao123界面"""
logging.info("用例3:测试能进入hao123界面")
self.homepage.link_hao123.click()
self.driver.switch_to_new_page()
logging.info("切换窗口")
#校验url
current_url = self.driver.current_url
self.assertEqual(current_url,"https://www.hao123.com/?src=from_pc")
logging.info("用例3测试通过")
def test_04_access_map(self):
"""用例4:测试能进入地图界面"""
logging.info("用例4:测试能进入地图界面")
self.homepage.link_ditu.click()
logging.info("切换窗口")
self.driver.switch_to_new_page()
#校验url
current_url = self.driver.current_url
els= self.driver.find_element('xpath','//*[@id="componseLeft"]/p')
self.assertIsNotNone(els)
logging.info("用例4测试通过")
def test_05_access_tieba(self):
"""用例5: 测试能进入贴啊界面"""
logging.info("用例5:测试能进入贴吧界面")
self.homepage.link_tieba.click()
logging.info("切换窗口")
self.driver.switch_to_new_page()
#校验url
current_url = self.driver.current_url
self.assertEqual(current_url,"https://tieba.baidu.com/index.html")
logging.info("用例5通过测试覅")
def test_06_access_shiping(self):
"""用例6:能进入视频界面"""
logging.info("用例6:能进入视频界面")
self.homepage.link_shipin.click()
logging.info("切换窗口")
self.driver.switch_to_new_page()
#校验url
current_url = self.driver.current_url
self.assertEqual(current_url,"https://haokan.baidu.com/?sfrom=baidu-top")
logging.info("用例6测试通过")
def test_07_access_tupian(self):
"""用例7:能进入图片界面"""
logging.info("用例7:能进入视频界面")
self.homepage.link_tupian.click()
logging.info("切换窗口")
self.driver.switch_to_new_page()
#校验rul
current_url = self.driver.current_url
self.assertEqual(current_url,"https://image.baidu.com/")
logging.info("用例7测试通过")
def test_08_access_wangpan(self):
"""用例8:能进入网盘界面"""
logging.info("用例8:能进入网盘界面")
self.homepage.link_wangpan.click()
logging.info("切换窗口")
self.driver.switch_to_new_page()
#校验url
current_url = self.driver.current_url
self.assertEqual(current_url,"https://pan.baidu.com/?from=1026962h")
logging.info("用例8测试通过")
def test_09_access_gengduo(self):
"""用例9:能进入更多界面"""
logging.info("用例9:能进入更多界面")
self.homepage.link_gengduo.click()
logging.info("切换窗口")
self.driver.switch_to_new_page()
#校验url
current_url = self.driver.current_url
self.assertEqual(current_url,"https://www.baidu.com/more/")
logging.info("用例9测试通过")
def test_10_access_fanyi(self):
"""用例10,能进入翻译页面"""
logging.info("用例10:能进入翻译页面")
#悬浮到设置元素上,后点击进入翻译页面
self.driver.suspension(self.homepage.link_gengduo)
self.homepage.link_fanyi.click()
#校验url
self.driver.switch_to_new_page()
current_url = self.driver.current_url
self.assertEqual(current_url,"https://fanyi.baidu.com/")
logging.info("用例10测试通过")
if __name__ == '__main__':
unittest.main()
SeleniumGUI自动化POM三层架构结束,欢迎进我主页观看其它技术类文章~~
![[附源码]Python计算机毕业设计动漫网站Django(程序+LW)](https://img-blog.csdnimg.cn/b87f0f24a3514af3a3d1b1ed38c1c599.png)



![[附源码]Nodejs计算机毕业设计基于JAVA语言的宠物寄养管理Express(程序+LW)](https://img-blog.csdnimg.cn/b9b4f97591ee4aa4a0d47373e9600cbf.png)