1 单选题
- ID3算法、C4.5算法、CART算法都是( )研究方向的算法。
A . 决策树 B. 随机森林
C. 人工神经网络 D. 贝叶斯学习
参考答案:A
- ( )作为机器学习重要算法之一,是一种利用多个树分类器进行分类和预测的方法。
A . 决策树 B. 随机森林
C. 人工神经网络 D. 贝叶斯学习
参考答案:B
- ()是一种具有非线性适应性信息处理能力的算法,可克服传统人工智能方法对模式识别、语音识别、非结构化信息处理方面的缺陷。
A . 决策树 B. 随机森林
C. 人工神经网络 D. 贝叶斯学习
参考答案:C
- ()是机器学习较早的研究方向,其源于英国数学家托马斯.贝叶斯在1763年发表的一篇论文中提到的贝叶斯定理。
A . 决策树 B. 随机森林
C. 人工神经网络 D. 贝叶斯学习
参考答案:D
- 基于学习策略进行分类,机器学习可分为( )。
A. 模拟人脑的机器学习和采用数学方法的机器学习
B. 归纳学习、演绎学习、类比学习、分析学习
C. 监督学习、无监督学习、强化学习
D. 结构化学习、非结构化学习
参考答案:A
- 机器学习按学习方法大致可分为( )。
A. 模拟人脑的机器学习和采用数学方法的机器学习
B. 归纳学习、演绎学习、类比学习、分析学习
C. 监督学习、无监督学习、强化学习
D. 结构化学习、非结构化学习
参考答案:B
- 机器学习按学习方式大致可分为( )。
A. 模拟人脑的机器学习和采用数学方法的机器学习
B. 归纳学习、演绎学习、类比学习、分析学习
C. 监督学习、无监督学习、强化学习
D. 结构化学习、非结构化学习
参考答案:C
- 机器学习按数据形式大致可分为( )。
A. 模拟人脑的机器学习和采用数学方法的机器学习
B. 归纳学习、演绎学习、类比学习、分析学习
C. 监督学习、无监督学习、强化学习
D. 结构化学习、非结构化学习
参考答案:D
- 机器学习的实质是( )。
A. 根据现有数据,寻找输入数据和输出数据的映射关系/函数
B. 建立数据模型
C. 衡量输入数据和输出数据的映射关系/函数的好坏
D. 挑出输入数据和输出数据的最佳映射关系/函数
参考答案: A
- 越复杂的模型,在training data set表现出越好的误差性能,但在testing data set中并不总是表现出好的误差性能,这种现象被称为( )?
A. 过拟合
B. 泛化性能
C. 欠拟合
D. 泛化能力
参考答案: A
- K近邻算法是( )。
A.有监督学习
B.无监督学习
C.半监督学习
D.自主学习
参考答案: A
- 在数据预处理阶段,我们常常对数值特征进行归一化或标准化(standardization, normalization)处理。这种处理方式理论上不会对下列哪个模型产生很大影响?()
A. k k k-Means
B. k k k-NN
C. 决策树
参考答案:C
分析: k k k-Means和 k k k-NN都需要使用距离。而决策树对于数值特征,只在乎其大小排序,而非绝对大小。不管是标准化或者归一化,都不会影响数值之间的相对大小。关于决策树如何对数值特征进行划分。
- 下面哪个情形不适合作为
k
k
k-Means迭代终止的条件?
A. 前后两次迭代中,每个聚类中的成员不变
B. 前后两次迭代中,每个聚类中样本的个数不变
C. 前后两次迭代中,每个聚类的中心点不变
参考答案:B
分析:A和C是等价的,因为中心点是聚类中成员各坐标的均值
- 关于欠拟合(under-fitting),下面哪个说法是正确的?
A. 训练误差较大,测试误差较小
B. 训练误差较小,测试误差较大
C. 训练误差较大,测试误差较大
参考答案:C
当欠拟合发生时,模型还没有充分学习训练集中基本有效信息,导致训练误差太大。测试误差也会较大,因为测试集中的基本信息(分布)是与训练集相一致的。
- 关于集成学习(ensemble learning),下面说法正确的是:
A. 单个模型都是使用同一算法
B. 在集成学习中,使用“平均权重”会好于使用“投票”
C. 单个模型之间有低相关性
参考答案:C
- 以下说法哪些是正确的?
A. 在使用 k k k-NN算法时,k通常取奇数
B. k k k-NN是有监督学习算法
C.在使用 k k k-NN算法时, k k k取值越大,模型越容易过拟合
D. k k k-NN和 k k k-Means都是无监督学习算法
参考答案:B
- (单选题)不属于神经网络常用学习算法的是( )。
A. 监督学习
B. 增强学习
C. 观察与发现学习
D. 无监督学习
参考答案: C
- (单选题)
( ) 是一门用计算机模拟或实现人类视觉功能的新兴学科,其主要研究目标是使计算机具有通过二维图像认知三维环境信息的能力。
A. 机器视觉
B. 语音识别
C. 机器翻译
D. 机器学习
参考答案: A
- (单选题)在图灵测试中,如果有超过( )的测试者不能分清屏幕后的对话者是人还是机器,就可以说这台计算机通过了测试并具备人工智能。
A. 30%
B. 40%
C. 50%
D. 60%
参考答案: A
- (单选题)知识图谱可视为包含多种关系的图。在图中,每个节点是一个实体(如人名、地名、事件和活动等),任意两个节点之间的边表示这两个节点之间存在的关系。下面对知识图谱的描述,哪一句话的描述不正确( )
A. 知识图谱中一条边可以用一个三元组来表示
B. 知识图谱中一条边连接了两个节点,可以用来表示这两个节点存在某一关系
C. 知识图谱中两个节点之间仅能存在一条边
D. 知识图谱中的节点可以是实体或概念
参考答案:C
- 以下哪个步骤不是机器学习所需的预处理工作( )
A. 数值属性的标准化
B. 变量相关性分析
C. 异常值分析
D. 与用户讨论分析需求
参考答案: D
- 数据预处理对机器学习是很重要的,下面说法正确的是( )
A. 数据预处理的效果直接决定了机器学习的结果质量
B. 数据噪声对神经网络的训练没什么影响
C. 对于有问题的数据都直接删除即可
D. 预处理不需要花费大量的时间
参考答案: A
- 谷歌新闻每天收集非常多的新闻,并运用( )方法再将这些新闻分组,组成若干类有关联的新闻。于是,搜索时同一组新闻事件往往隶属同一主题的,所以显示到一起。
A. 回归
B. 分类
C. 聚类
D. 关联规则
参考答案: C
- 回归问题和分类问题的区别是什么?
A. 回归问题与分类问题在输入属性值上要求不同
B. 回归问题有标签,分类问题没有
C. 回归问题输出值是连续的,分类问题输出值是离散的
D. 回归问题输出值是离散的,分类问题输出值是连续的
参考答案: C
- 有关数据质量不正确的说法是( )
A. 错误的数据将可能产生有害于决策的结果
B. 因为数据量很大,所以数据质量差一些也对机器学习没多大影响
C. 数据预处理的重要目的是提高机器学习结果的质量
D. 从业务系统提取的脏数据需要预处理才能进行建模工作
参考答案: B
- 假设你正在做天气预报,并使用算法预测明天气温(摄氏度/华氏度),你会把这当作一个分类问题还是一个回归问题?
A. 分类
B. 回归
参考答案: B
- 假设你在做股市预测。你想预测某家公司是否会在未来7天内宣布破产(通过对之前面临破产风险的类似公司的数据进行训练)。你会把这当作一个分类问题还是一个回归问题?
A. 分类
B. 回归
参考答案: A
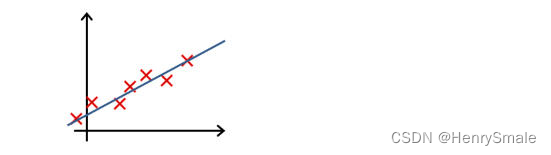
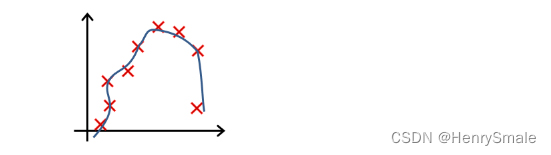
-
下列哪一个图片的假设与训练集过拟合?
A.
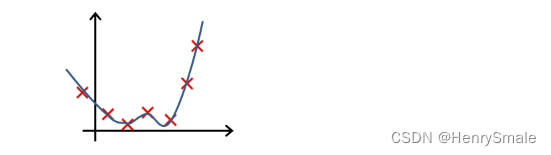
B.
C.
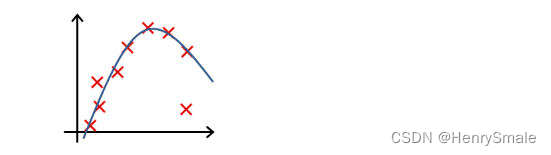
D.
参考答案: A -
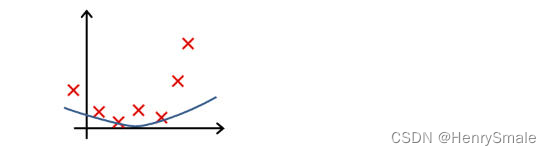
下列哪一个图片的假设与训练集欠拟合?
A.
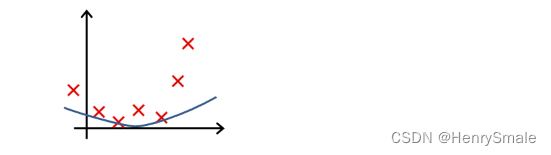
B.
C.
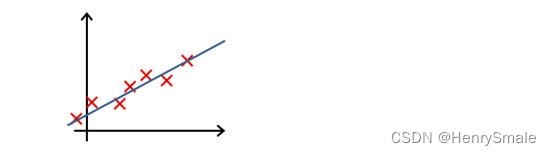
D.
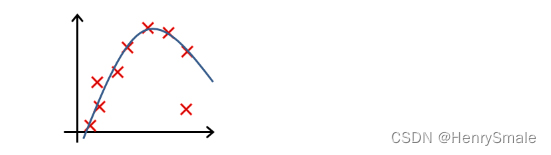
参考答案: A -
给定一定数量的红细胞、白细胞图像以及它们对应的标签,设计出一个红、白细胞分类器,这属于什么问题?
A. 有监督学习
B. 半监督学习
C. 无监督学习
D. 其他答案都正确
参考答案: A
- 已知变量x与y正相关,且由观测数据算得x的样本平均值为3,y的样本平均值为3.5,则由该观测数据算得的线性回归方程可能是( )。
A. y=0.4x+2.3
B. y=2x-2.4
C. y=-2x+9.5
D. y=-0.3x+4.4
参考答案: A
- ( )属于机器学习中的回归问题。
A. 根据房屋特性预测房价
B. 预测短信是否为垃圾短信
C. 识别车牌
D. 机场安检人脸识别
参考答案: A
- 以下哪个选项是尚未实现的人工智能技术?( )
A. 无人驾驶
B. 人工智能下围棋
C. 智能导航
D. 人脑芯片
参考答案: D
- 以下哪个选项是已经实现的人工智能技术?( )
A. 有情感的机器人
B. 通过图灵测试的语音应答机器人
C. 自我进化的机器人
D. 智能导航
参考答案: D
- 当前的人工智能处于( )阶段。
A. 弱人工智能
B. 强人工智能
C. 超人工智能
D. 非人工智能
参考答案: A
- 若得到如下一颗决策树,则属性值为(色泽 = 乌黑,根蒂 = 稍蜷,敲声 = 浊响,纹理 = 清晰,脐部 = 稍凹,触感 = 硬滑)的西瓜应判别为()
A. 好瓜
B. 坏瓜
C. 好瓜坏瓜都行
D. 无法判断
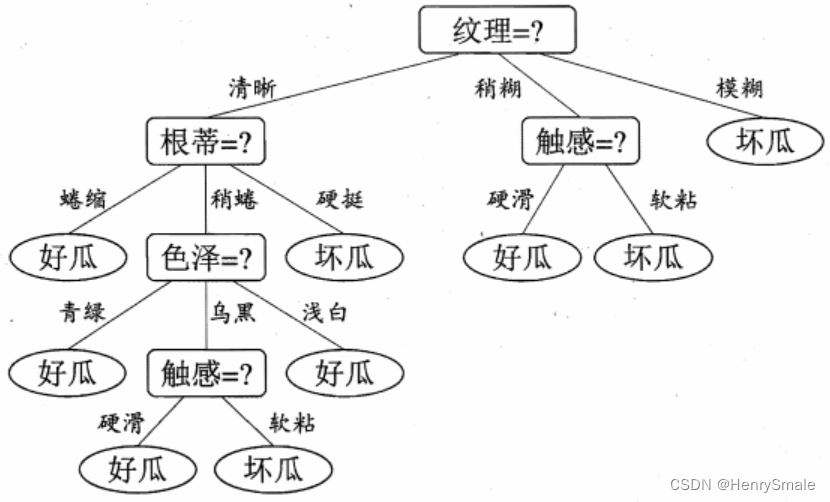
参考答案: A
- 若神经网络结构中输入层有a个神经元,紧跟其后的隐藏层有b个神经元,则从输入层到该隐藏层的权重个数是( )
A. a + b
B. a - b
C. a * b
D. a/b
参考答案: C
- 在聚类中,样本数据()
A. 有标签信息
B. 没有标签信息
C. 标签信息可有可无
D. 不同的聚类情况不一样
参考答案: B
- 聚类试图将样本划分为若干个不相交的子集,每个子集称为( )
A. 类
B. 树
C. 簇
D. 点
参考答案: C
- 根据下图,查准率的定义是( )
A. P = T P T P + F N P = \frac{TP}{TP + FN} P=TP+FNTP
B. P = T P T N + F N P = \frac{TP}{TN + FN} P=TN+FNTP
C. P = T P T P + F P P = \frac{TP}{TP + FP} P=TP+FPTP
D. P = T P T P + T N P = \frac{TP}{TP + TN} P=TP+TNTP

参考答案: C
分析: T P TP TP指 “预测为正(Positive), 预测正确(True)” (可以这样记忆:第一位表示该预测是否正确,第二位表示该预测结果为正还是负) , 于是,我们可以这样理解查准率 P = T P T P + F P P = \frac{TP}{TP + FP} P=TP+FPTP : 所有预测为正例的样本中,预测准确的比例;召回率 R = T P T P + T N R = \frac{TP}{TP + TN} R=TP+TNTP:所有预测准确的样本中,正例所占的比例。
2 多选题
- 下面属于训练集(Training data set)和测试集(Testing data set)区别表述的是
A. Testing data set用于测试寻找到的函数的效果
B. Training data set用于寻找函数
C. Training data set用于挑选模型
D. Training data set用于构建模型
参考答案: ABCD
- 机器学习的方法由( )等几个要素构成。
A. 损失函数
B. 优化算法
C. 模型
D. 模型评估指标
参考答案: ABCD
- 下列哪些学习问题不属于监督学习?( )
A. 聚类
B. 回归
C. 分类
D. 降维
参考答案: AD
- 下面的一些问题最好使用有监督的学习算法来解决,而其他问题则应该使用无监督的学习算法来解决。以下哪一项你会使用监督学习?(选择所有适用的选项)在每种情况下,假设有适当的数据集可供算法学习。
A. 根据一个人的基因(DNA)数据,预测他/她的未来10年患糖尿病的几率
B. 根据心脏病患者的大量医疗记录数据集,尝试了解是否有多种类型的心脏病患者群,我们可以为其量身定制不同的治疗方案
C. 让计算机检查一段音频,并对该音频中是否有人声(即人声歌唱)或是否只有乐器(而没有人声)进行分类
D. 给出1000名医疗患者对实验药物的反应(如治疗效果、副作用等)的数据,发现患者对药物的反应属于哪种类别或“类型”
参考答案: AD
- 当数据集中样本类别不均衡时,常采用哪些方法来解决?()
A. 降采样
B. 升采样
C. 人造数据
D. 更换分类算法
E. 以上都不是。
参考答案: ACD