网站:http://www.sxdyc.com/diffLimmaAnalyse
一、limma简介
什么是limma? 首先要明白,不管哪种差异分析,其本质都是广义线性模型。 limma也是广义线性模型的一种,其对每个gene的表达量拟合一个线性方程。 limma的分析过程包括ANOVA分析、线性回归等,可以用于RNA-Seq和芯片数据的差异分析表达。这种方法可以对基因表达量拟合一个线性方程,从而得到差异表达的基因,在R语言中有相关的包。
二、使用须知(几个概念)
1、Group:表示的是样本的分组信息。差异分析中,一般只有两组,进行比较,即A和B组进行比较;
2、P值:P值即概率,反映某一事件发生的可能性大小。在差异分析中,p值的大小反应的是分组样本的重复性,组内重复性越好,p值往往越小,在分析的过程中,我们一般认为满足p<0.05的情况下,该特征(基因)差异才是真正的差异基因,而不是由于离群样本过高/过低导致的假阳性结果。
三、使用方法
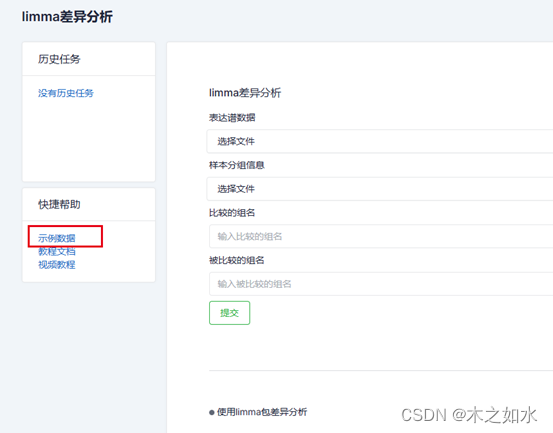
1.打开网址(http://www.sxdyc.com/singleCollectionTool?href-diff),选择“limma差异分析”
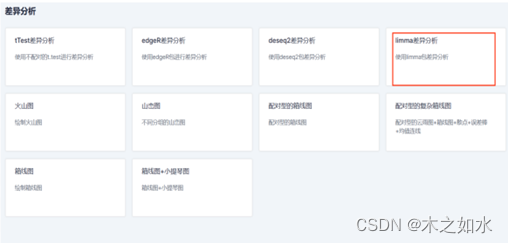
- 准备数据
一个全基因的表达谱矩阵,其中行为基因,列为样本
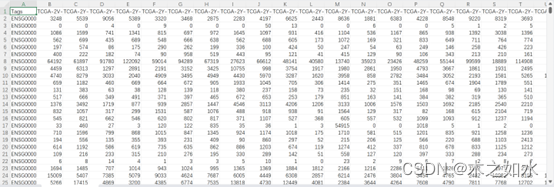
一个样本分组信息,包含两列,第一列为样本名,第二列为分组情况。

- 输入“比较的组名”和“被比较的组名”,点击提交
这里输入的是比较组为C1,被比较组为C2,代表该差异分析为C1vsC2

获取到的结果,log2(FC)>0的基因为在C1组中高表达,log2(FC)<0的基因为在C1组中低表达
4.输入分析队列名,点击提交
5.等待完成,查看结果
- 等待结果,查看结果
结果需要注意的是:列名错位,A列其实是基因,B为logFC,C为AveExpr,D为t,E为P.Value,F为adj.P.Val,G为B值
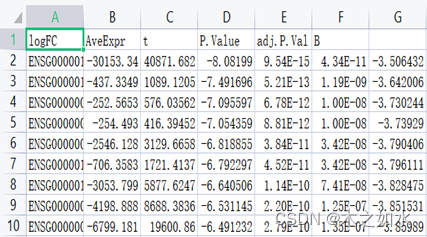
四、结果分析
- logFC中的FC即 fold change,表示两样品(组)间表达量的比值,对其取以2为底的对数之后即为logFC。
- adj.P.Val即False Discovery Rate,错误发现率,是通过对差异显著性p值(p-value)进行校正得到的。
注意:在自测数据中,由于样本较少,在选择差异分析时,可以选择p值而不是FDR(校正后的p值)
当然,如果不清楚数据是什么样的,可以选择下载我们的示例数据,还可以关注公众号:豆芽数据分析