1、简介
机器学习框架中使用自定义的Loss函数,
2、应用
(1)sklearn
from sklearn.metrics import max_error
from sklearn.metrics import make_scorer
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import Ridge
def custom_loss(y_true, y_pred, **kwargs):
# Define your custom loss calculation here
y_true = np.array(y_true)
y_pred = np.array(y_pred)
if y_true.ndim == 1 :
y_true = y_true.reshape((-1, 1))
if y_pred.ndim == 1:
y_pred = y_pred.reshape((-1, 1))
loss = max(y_true-y_pred)
return loss
data = pd.DataFrame(np.array([[i for i in range(0,300)],[i for i in range(100,400)],[i for i in range(200,500)]]).T,columns=['a','b','c'])
X_train ,y_train = data[['a','b']],data[['c']]
clf = Ridge()
custom_scorer = make_scorer(custom_loss, greater_is_better=False)
# Create and train a model using the custom loss function
# model = Ridge()
scores = cross_val_score(clf, X_train, y_train, cv=5, scoring=custom_scorer)输出是cv=5,交叉验证的5个结果,评估模型

(2)pycaret
from pycaret.regression import *
from pycaret.datasets import get_data
import pandas as pd
import numpy as np
from sklearn.metrics import max_error
from sklearn.metrics import make_scorer
def custom_loss(y_true, y_pred, **kwargs):
# Define your custom loss calculation here
y_true = np.array(y_true)
y_pred = np.array(y_pred)
if y_true.ndim == 1 :
y_true = y_true.reshape((-1, 1))
if y_pred.ndim == 1:
y_pred = y_pred.reshape((-1, 1))
loss = max(y_true-y_pred)
return loss
# # load sample dataset
# # data = get_data('insurance')
data = pd.DataFrame(np.array([[i for i in range(0,300)],[i for i in range(100,400)],[i for i in range(200,500)]]).T,columns=['a','b','c'])
s = setup(data, target='c')
# custom_loss = make_scorer(custom_loss)
add_metric('custom_loss', 'Custom Loss', custom_loss)
best = compare_models()
predict_model(best)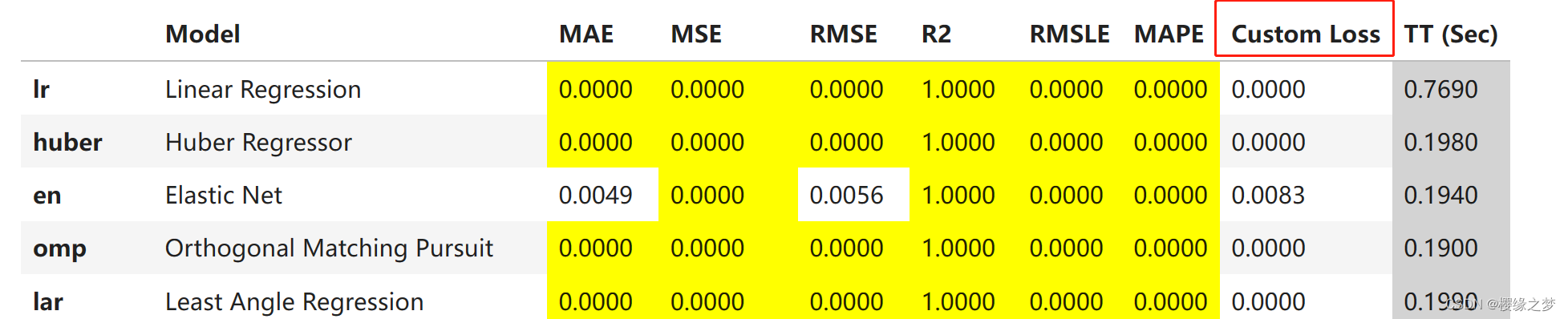
3、深度学习框架
(1)torch
import torch
import torch.nn as nn
import numpy as np
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def get_x_y():
np.random.seed(0)
x = np.random.randint(0, 50, 300)
y_values = 2 * x + 21
x = np.array(x, dtype=np.float32)
y = np.array(y_values, dtype=np.float32)
x = x.reshape(-1, 1)
y = y.reshape(-1, 1)
return x, y
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim) # 输入的个数,输出的个数
def forward(self, x):
out = self.linear(x)
return out
class CustomLoss(nn.Module):
def __init__(self):
super(CustomLoss, self).__init__()
self.mse_loss = nn.MSELoss()
def forward(self, x, y):
mse_loss = torch.mean(torch.pow((x - y), 2))
return mse_loss
if __name__ == '__main__':
input_dim = 1
output_dim = 1
x_train, y_train = get_x_y()
model = LinearRegressionModel(input_dim, output_dim)
epochs = 1000 # 迭代次数
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
# model_loss = nn.MSELoss() # 使用MSE作为loss
model_loss = CustomLoss() # 自定义loss
# 开始训练模型
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs: torch.Tensor = model(inputs)
# 计算损失
loss = model_loss(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
参看:pytorch自定义loss损失函数_python_脚本之家