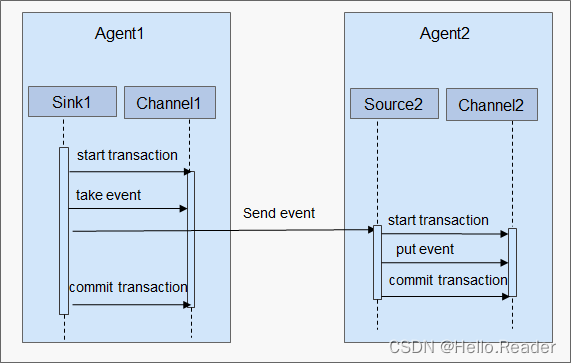
一、前言
最近,我一直在各个地方进行 TiDB 的 Poc 测试。在这些测试中,客户特别关注同城双中心或者两地三中心的架构体系,经常会找我了解 TiDB 灾备架构的实现方案和底层逻辑。基于客户对 RPO =0 的要求,我一般会向他们介绍 DR Auto-Sync 架构,也就是官网中的自适应同步模式,这是唯一能保证 RPO =0 的灾备架构。
根据 PoC 测试的经验,结合专栏的文章,我总结了开启 DR Auto-Sync 和主中心故障恢复的流程及注意事项。
二、什么是 DR Auto-Sync
TiDB 通常采用多 AZ 部署方案保证集群高可用和容灾能力。多 AZ 部署方案包括单区域多 AZ 部署模式、双区域多 AZ 部署模式等多种部署模式。单区域双 AZ 部署方案,即在同一区域部署两个 AZ,成本更低,同样能满足高可用和容灾要求。该部署方案采用自适应同步模式,即 Data Replication Auto Synchronous,简称 DR Auto-Sync。
单区域双 AZ 部署方案下,两个 AZ 通常位于同一个城市或两个相邻城市(例如北京和廊坊),相距 50 km 以内,AZ 间的网络连接延迟小于 1.5 ms,带宽大于 10 Gbps。

- 该集群采用推荐的 6 副本模式,其中 AZ1 中放 3 个 Voter,AZ2 中放 2 个 Follower 副本和 1 个 Learner 副本。TiKV 按机房的实际情况打上合适的 Label。
- 副本间通过 Raft 协议保证数据的一致性和高可用,对用户完全透明。
该部署方案定义了三种状态来控制和标示集群的同步状态,该状态约束了 TiKV 的同步方式。集群的复制模式可以自动在三种状态之间自适应切换。要了解切换过程,请参考状态转换。
- sync:同步复制模式,此时从 AZ (DR) 至少有一个副本与主 AZ (PRIMARY) 进行同步,Raft 算法保证每条日志按 Label 同步复制到 DR。
- async:异步复制模式,此时不保证 DR 与 PRIMARY 完全同步,Raft 算法使用经典的 majority 方式复制日志。
- sync-recover:恢复同步,此时不保证 DR 与 PRIMARY 完全同步,Raft 逐步切换成 Label 复制,切换成功后汇报给 PD。
三、设置 DR Auto-Sync 架构
本次准备的集群如下:

存储拓扑如下:

本次会设置 3+2+1 的架构,也就是6 副本(3 个 Voter 副本在主中心,2 个 Follower 副本和 1 个 Learner 副本在备中心)
Step1:设置 Label
在 PD 中的设置:

这里的zone 也可以写成 az 或是其他,但是一定要和后续配置保持一致。
TiKV 中的设置:

这里的 labels 要与 PD 的设置保持一致。
Step2:设置 Placement Rules 规划
新建一个文件 Untitled-1.json,写入如下代码:
[
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "voters",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3,
"label_constraints": [{"key": "zone", "op": "in", "values": ["west"]}],
"location_labels": ["zone","rack","host"]},
{
"group_id": "pd",
"id": "followers",
"start_key": "",
"end_key": "",
"role": "follower",
"count": 2,
"label_constraints": [{"key": "zone", "op": "in", "values": ["east"]}],
"location_labels": ["zone", "rack", "host"]},
{
"group_id": "pd",
"id": "learners",
"start_key": "",
"end_key": "",
"role": "learner",
"count": 1,
"label_constraints": [{"key": "zone", "op": "in", "values": ["east"]}],
"location_labels": ["zone", "rack", "host"]
}
]
}
]注意项:
- id不能重复,建议写 voters,followers,learners 用于区分各副本用途
- role 写副本的角色
- location_labels 需要与 PD 的 label 保持一致
- label_constraints 可以填写不同的颗粒度,比如中心、机架、机器。但是key的值,必须在 PD 的 label 中存在,比如颗粒度是中心,key 就需要写成 zone,颗粒度是机器,key需要写成host
- 备份原始 Placement Rules,便于回退:pd-ctl config placement-rules rule-bundle load --out="default.json"
Step3:启用自适应同步模式
使用 pd-ctl 设置:
tiup ctl:v7.1.0pd -u http://10.3.65.146:2379-i# 设置 placement-rules
config placement-rules rule-bundle save --in="rule.json"
config set replication-mode dr-auto-sync
config set replication-mode dr-auto-sync label-key zone
config set replication-mode dr-auto-sync primary west
config set replication-mode dr-auto-sync dr east
config set replication-mode dr-auto-sync primary-replicas 3
config set replication-mode dr-auto-sync dr-replicas 2
说明:
- replication-mode 为待启用的复制模式,以上示例中设置为 dr-auto-sync。默认使用 majority 算法。
- label-key 用于区分不同的中心,需要和 Placement Rules 相匹配。
- primary 是主中心 zone 的值,即 west。
- dr 是备中心 zone 的值,即 east。
- primary-replicas 是主中心副本的数量。
- dr-replicas 是备中心副本的数量。

Step4:查看DR Auto-Sync架构状态
1. 设置自适应同步模式后region状态

我们能够观察到,刚设置自适应同步模式后,PD 会检测到大量 miss peer 和 pending peer,也就时说,设置完成后,集群的三副本会直接变为六副本,多出来的三个部分没有及时补全,才会出现丢失副本和补充副本的现象。所以我们需要等待一些时间,或者调整store limit 参数,加速补充副本,直到 learner peer 稳定。这个时候,DR Auto-Sync 架构状态才是正常的。
让我们看看稳定后的leader和region分布吧:

由于只设置了三个 voter,所以 leader 都集中在三个 voter 所在 TiKV 节点上,region 在所有节点上分布均衡。如果主中心停止两个 voter,还需要让集群正常提供服务,可以把两个 follower 副本改为 voter,一共五个 voter 就可以满足这类需求。
如果设置您设置好的 DR Auto-Sync 架构不满足以上 region 的状态及分布,可能是设置出现问题,需要重新检查。
2. 检查设置
config showall
config placement-rulesshow

3. 查看同步状态
curl http://10.3.65.146:2379/pd/api/v1/replication_mode/status{
"mode": "dr-auto-sync",
"dr-auto-sync": {
"label_key": "zone",
"state": "sync",
"state_id": 64861,
"acid_consistent": true
}
}四、主中心故障,集群恢复
在 DR Auto-Sync 架构中的集群,如果主中心突然故障无法启动,该怎么办呢?以下是官方文档,因为操作有丢失数据的风险,没有给出详细的解决方案。

以下是根据 PoC 测试的经验,结合专栏的文章整理的集群恢复步骤:
(一)主中心故障前的准备工作
Step1:查看主dc的store信息
selectSTORE_ID,STORE_STATE,ADDRESS fromINFORMATION_SCHEMA.TIKV_STORE_STATUS;
记录好主中心的 store_id 恢复数据时需要用到。
Step2:转移集群信息文件并删除主中心相关节点
scp -r .tiup/storage/cluster/clusters/tidb-bbg 10.3.65.146:/home/tidb/.tiup/storage/cluster/clusters/
vi .tiup/storage/cluster/clusters/tidb-bbg/meta.yaml拷贝集群信息主要是保证在主中心访问不了的情况下,备中心还能够使用 tiup 对集群进行管理。如果 tiup 不在主中心可以忽略此步骤。删除主中心相关节点是因为备中心会以新集群启动,然后做有损恢复,主中心的 tikv 会作为不可能上线的情况处理。
ps:在 PoC 测试中,我发现不删除主中心相关节点也能正常恢复集群,但是对生产环境来说肯定还是有风险的。
(二)主中心故障后的处理
Step1:启动PD节点
如果备中心集群状态的 PD 是启动状态,可跳过对 PD 的操作。如果备中心集群状态的 PD 是 down,则需要登录到该 PD 节点机器上,增加启动参数:
scp -r .tiup/storage/cluster/clusters/tidb-bbg 10.3.65.146:/home/tidb/.tiup/storage/cluster/clusters/
vi .tiup/storage/cluster/clusters/tidb-bbg/meta.yaml使用 tiup restart 重启 pd 节点:
tiupclusterrestarttidb-bbg-N10.3.65.136:2379查看集群状态,如果 PD 启动后,则需要执行:
tiup pd-recover--from-old-member --endpoints=http://10.3.65.136:2379模拟主中心故障:

启动 PD 节点:


Step2:切换 Placement Rules 规划
用初始值来代替 DR Auto-Sync 的 Placement Rules 规划:
config placement-rules rule-bundle save --in="default.json"Step3:取消DR Auto-sync
设置成以前的三副本:
config setreplication-modemajorityStep4:有损恢复
去掉主中心的store,这里的 id 是之前用 sql 查出来的 store_id:
unsaferemove-failed-stores 1,4,5Step5:查看 store 状态
unsaferemove-failed-stores show看到如下字样,即表示恢复完成,集群可正常提供服务。

集群状态如下,备中心的节点均正常。(由于 PD 分布不太对,我把137上的 PD 当成主中心做的实践)

region分布:

到此,集群恢复已经完成。
五、总结
- 在开启 DR Auto-Sync 架构之前,务必要仔细核对各项配置的准确性。由于我之前不熟悉,配置写错了,而且没有报错信息,导致 DR Auto-Sync 架构的 region 状态一直与预期不符。
- DR Auto-Sync 架构对网络延迟和带宽有一定要求,必须满足才能避免出现问题。例如,插入的数据会一直等待 learner 写入完成才算插入完成,而网络延迟越高,写入速度就越慢。
- 在生产环境中,必须做好数据备份和备中心的准备工作,以确保数据的安全性。数据量越大,备中心的恢复耗时就会越长,需要合理安排时间来完成这些工作。
作者:蔡一凡|后端开发工程师
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,后台回复数据库,加入数据库技术交流群。