From
- Python中强大的通用ORM框架:SQLAlchemy:https://zhuanlan.zhihu.com/p/444930067
- Python ORM之SQLAlchemy全面指南:https://zhuanlan.zhihu.com/p/387078089
SQLAlchemy 文档:https://www.sqlalchemy.org/
SQLAlchemy入门和进阶:https://zhuanlan.zhihu.com/p/27400862
1、ORM、SQLAlchemy 简介
ORM 技术:Object-Relational Mapping,把 "关系数据库的表结构" 映射到 "对象" 上。所以ORM框架应运而生。在Python中,最有名的ORM框架是 SQLAlchemy 。
SQLAlchemy 是 Python 中一款非常优秀的 ORM 框架,它可以与任意的第三方 web 框架相结合,如 flask、tornado、django、fastapi 等。
SQLALchemy 相较于 Django ORM 来说更贴近原生的 SQL 语句,因此学习难度较低。
SQLALchemy 由以下5个部分组成:
- Engine:框架引擎
- Connection Pooling:数据库链接池
- Dialect:方言,调用不同的数据库 API(Oracle, postgresql, Mysql) 并执行对应的 SQL语句。即 数据库DB API 种类。
- Schema / Types:" 类 到 表" 之间的映射规则
- SQL Exprression Language:SQL表达式语言
图示如下:
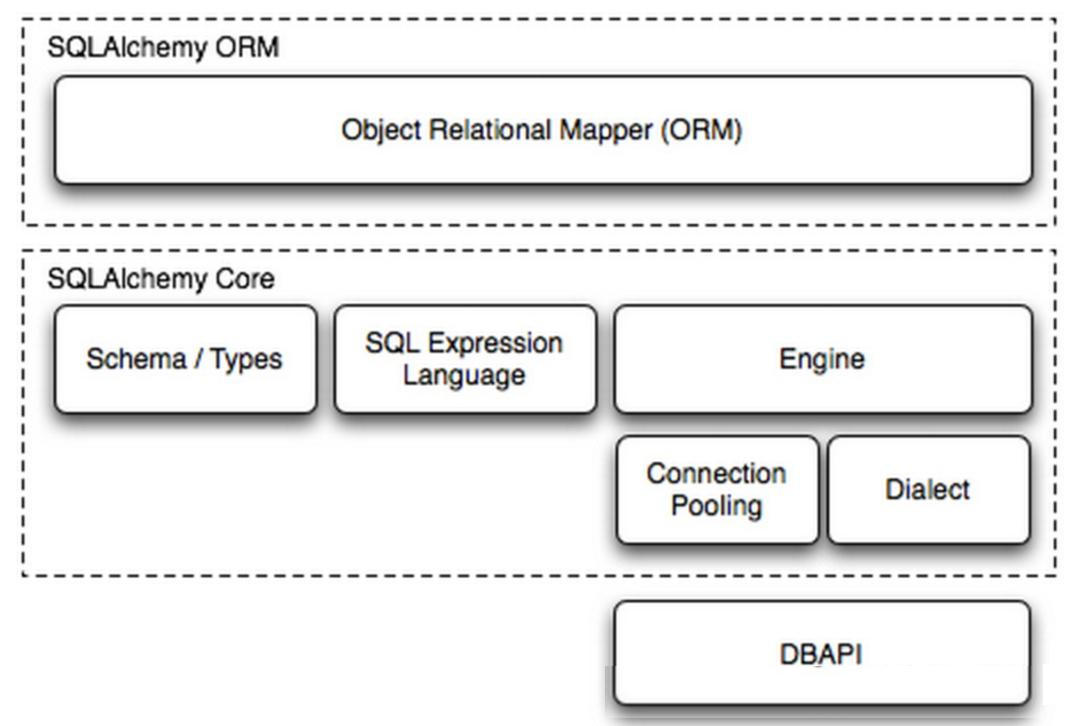
运行流程:
- 首先用户输入的操作会交由ORM对象
- 接下来ORM对象会将用户操作提交给SQLALchemy Core
- 其次该操作会由Schema/Types以及SQL Expression Language转换为SQL语句
- 然后Egine会匹配用户已经配置好的egine,并从链接池中去取出一个链接
- 最终该链接会通过Dialect调用DBAPI,将SQL语句转交给DBAPI去执行
安装 sqlalchemy
安装:pip install sqlalchemy
数据库 连接 字符串
SQLAlchemy 必须依赖其他操纵数据库的模块才能进行使用,也就是上面提到的 DBAPI。
SQLAlchemy 配合 DBAPI 使用时,链接字符串也有所不同,如下所示:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
连接 引擎
任何SQLAlchemy应用程序的开始都是一个Engine对象,此对象充当连接到特定数据库的中心源,提供被称为connection pool的对于这些数据库连接。
Engine对象通常是一个只为特定数据库服务器创建一次的全局对象,并使用一个URL字符串进行配置,该字符串将描述如何连接到数据库主机或后端。
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///:memory:', echo=True)
create_engine 的参数有很多,我列一些比较常用的:
- echo=False -- 如果为真,引擎将记录所有语句以及
repr()其参数列表的默认日志处理程序。 - enable_from_linting -- 默认为True。如果发现给定的SELECT语句与将导致笛卡尔积的元素取消链接,则将发出警告。
- encoding -- 默认为
utf-8 - future -- 使用2.0样式
- hide_parameters -- 布尔值,当设置为True时,SQL语句参数将不会显示在信息日志中,也不会格式化为 StatementError 对象。
- listeners -- 一个或多个列表
PoolListener将接收连接池事件的对象。 - logging_name -- 字符串标识符,默认为对象id的十六进制字符串。
- max_identifier_length -- 整数;重写方言确定的最大标识符长度。
- max_overflow=10 -- 允许在连接池中“溢出”的连接数,即可以在池大小设置(默认为5)之上或之外打开的连接数。
- pool_size=5 -- 在连接池中保持打开的连接数
- plugins -- 要加载的插件名称的字符串列表。
声明 映射
也就是在 Python 中创建的一个类,对应着数据库中的一张表,类的每个属性,就是这个表的字段名,这种 类对应于数据库中表的类,就称为映射类。
我们要创建一个映射类,是基于基类定义的,每个映射类都要继承这个基类 declarative_base()。
>>> from sqlalchemy.orm import declarative_base
>>> Base = declarative_base()
既然我们有了一个“基”类,就可以根据它定义任意数量的映射类。
我们将新建一张名为users的表,也就是用户表。一个名为User类将是我们映射此表的类。在类中,我们定义了要映射到的表的详细信息,主要是表名以及列的名称和数据类型:
from sqlalchemy import Column, Integer, String
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
def __repr__(self):
return "<User(name='%s', fullname='%s', nickname='%s')>" % (
self.name,
self.fullname,
self.nickname,
)
__tablename__ 代表表名
Column : 代表数据表中的一列,内部定义了数据类型
primary_key:主键
创建表到数据库
通过定义User类,我们已经定义了关于表的信息,称为table metadata,也就是表的元数据。我们可以通过检查__table__属性:
User.__table__
Table('users', MetaData(),
Column('id', Integer(), table=<users>, primary_key=True, nullable=False),
Column('name', String(), table=<users>),
Column('fullname', String(), table=<users>),
Column('nickname', String(), table=<users>), schema=None)
开始创建表:
>>> Base.metadata.create_all(engine)
BEGIN...
CREATE TABLE users (
id INTEGER NOT NULL,
name VARCHAR,
fullname VARCHAR,
nickname VARCHAR,
PRIMARY KEY (id)
)
[...] ()
COMMIT
创建映射类的实例
映射完成后,现在让我们创建一个User对象的实例:
>>> ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')
>>> ed_user.name
'ed'
>>> ed_user.nickname
'edsnickname'
>>> str(ed_user.id)
'None'
此时,实例对象只是在环境的内存中有效,并没有在表中真正生成数据。
创建会话
>>> from sqlalchemy.orm import sessionmaker
>>> Session = sessionmaker(bind=engine)
# 实例化
>>> session = Session()
我们对表的所有操作,都是通过会话实现的。
添加和更新对象
>>> ed_user = User(name='ed', fullname='Ed Jones', nickname='edsnickname')
>>> session.add(ed_user)
这里我们新增了一个用户,此时这个数据并没有被同步的数据库中,而是处于等待的状态。
只有执行了 commit() 方法后,才会真正在数据表中创建数据。
如果我们查询数据库,则首先刷新所有待处理信息,然后立即发出查询。
>>> our_user = session.query(User).filter_by(name='ed').first()
>>> our_user
<User(name='ed', fullname='Ed Jones', nickname='edsnickname')>
此时得到的结果也并不是数据库表中的最终数据,而是映射类的一个对象。
回滚
在 commit() 之前,对实例对象的属性所做的更改,可以进行回滚,回到更改之前。
>>> session.rollback()
本质上只是把某一条数据(也就是映射类的实例)从内存中删除而已,并没有对数据库有任何操作。
查询
通过 query 关键字查询。
>>> for instance in session.query(User).order_by(User.id):
... print(instance.name, instance.fullname)
ed Ed Jones
wendy Wendy Williams
mary Mary Contrary
fred Fred Flintstone
- query.filter() 过滤
- query.filter_by() 根据关键字过滤
- query.all() 返回列表
- query.first() 返回第一个元素
- query.one() 有且只有一个元素时才正确返回
- query.one_or_none(),类似one,但如果没有找到结果,则不会引发错误
- query.scalar(),调用one方法,并在成功时返回行的第一列
- query.count() 计数
- query.order_by() 排序
query.join() 连接查询
>>> session.query(User).join(Address).\
... filter(Address.email_address=='jack@google.com').\
... all()
[<User(name='jack', fullname='Jack Bean', nickname='gjffdd')>]
query(column.label()) 可以为字段名(列)设置别名:
>>> for row in session.query(User.name.label('name_label')).all():
... print(row.name_label)
ed
wendy
mary
fred
aliased()为查询对象设置别名:
>>> from sqlalchemy.orm import aliased
>>> user_alias = aliased(User, name='user_alias')SQL>>> for row in session.query(user_alias, user_alias.name).all():
... print(row.user_alias)
<User(name='ed', fullname='Ed Jones', nickname='eddie')>
<User(name='wendy', fullname='Wendy Williams', nickname='windy')>
<User(name='mary', fullname='Mary Contrary', nickname='mary')>
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>
查询常用筛选器运算符
# 等于
query.filter(User.name == 'ed')# 不等于
query.filter(User.name != 'ed')# like和ilike
query.filter(User.name.like('%ed%'))
query.filter(User.name.ilike('%ed%')) # 不区分大小写# in
query.filter(User.name.in_(['ed', 'wendy', 'jack']))
query.filter(User.name.in_(
session.query(User.name).filter(User.name.like('%ed%'))
))
# not in
query.filter(~User.name.in_(['ed', 'wendy', 'jack']))# is
query.filter(User.name == None)
query.filter(User.name.is_(None))# is not
query.filter(User.name != None)
query.filter(User.name.is_not(None))# and
from sqlalchemy import and_
query.filter(and_(User.name == 'ed', User.fullname == 'Ed Jones'))
query.filter(User.name == 'ed', User.fullname == 'Ed Jones')
query.filter(User.name == 'ed').filter(User.fullname == 'Ed Jones')# or
from sqlalchemy import or_
query.filter(or_(User.name == 'ed', User.name == 'wendy'))# match
query.filter(User.name.match('wendy'))
使用文本 SQL
文字字符串可以灵活地用于Query 查询。
>>> from sqlalchemy import text
SQL>>> for user in session.query(User).\
... filter(text("id<224")).\
... order_by(text("id")).all():
... print(user.name)
ed
wendy
mary
fred
使用冒号指定绑定参数。要指定值,请使用Query.params()方法:
>>> session.query(User).filter(text("id<:value and name=:name")).\
... params(value=224, name='fred').order_by(User.id).one()
<User(name='fred', fullname='Fred Flintstone', nickname='freddy')>
一对多
一个用户可以有多个邮件地址,意味着我们要新建一个表与用户表进行映射和查询。
>>> from sqlalchemy import ForeignKey
>>> from sqlalchemy.orm import relationship>>> class Address(Base):
... __tablename__ = 'addresses'
... id = Column(Integer, primary_key=True)
... email_address = Column(String, nullable=False)
... user_id = Column(Integer, ForeignKey('users.id'))
...
... user = relationship("User", back_populates="addresses")
...
... def __repr__(self):
... return "<Address(email_address='%s')>" % self.email_address>>> User.addresses = relationship(
... "Address", order_by=Address.id, back_populates="user")
ForeignKey定义两列之间依赖关系,表示关联了用户表的用户ID
relationship 告诉ORMAddress类本身应链接到User类,back_populates 表示引用的互补属性名,也就是本身的表名。
多对多
除了表的一对多,还存在多对多的关系,例如在一个博客网站中,有很多的博客BlogPost,每篇博客有很多的Keyword,每一个Keyword又能对应很多博客。
对于普通的多对多,我们需要创建一个未映射的Table构造以用作关联表。如下所示:
>>> from sqlalchemy import Table, Text
>>> # association table
>>> post_keywords = Table('post_keywords', Base.metadata,
... Column('post_id', ForeignKey('posts.id'), primary_key=True),
... Column('keyword_id', ForeignKey('keywords.id'), primary_key=True)
... )
下一步我们定义BlogPost和Keyword,使用互补 relationship 构造,每个引用post_keywords表作为关联表:
>>> class BlogPost(Base):
... __tablename__ = 'posts'
...
... id = Column(Integer, primary_key=True)
... user_id = Column(Integer, ForeignKey('users.id'))
... headline = Column(String(255), nullable=False)
... body = Column(Text)
...
... # many to many BlogPost<->Keyword
... keywords = relationship('Keyword',
... secondary=post_keywords,
... back_populates='posts')
...
... def __init__(self, headline, body, author):
... self.author = author
... self.headline = headline
... self.body = body
...
... def __repr__(self):
... return "BlogPost(%r, %r, %r)" % (self.headline, self.body, self.author)
>>> class Keyword(Base):
... __tablename__ = 'keywords'
...
... id = Column(Integer, primary_key=True)
... keyword = Column(String(50), nullable=False, unique=True)
... posts = relationship('BlogPost',
... secondary=post_keywords,
... back_populates='keywords')
...
... def __init__(self, keyword):
... self.keyword = keyword
多对多关系的定义特征是secondary关键字参数引用Table表示关联表的对象。
2、使用 SQLAlchemy 操作 表
创建单表
SQLAlchemy 不允许修改表结构,如果需要修改表结构则必须删除旧表,再创建新表,或者执行原生的 SQL 语句 ALERT TABLE 进行修改。
这意味着在使用非原生SQL语句修改表结构时,表中已有的所有记录将会丢失,所以我们最好一次性的设计好整个表结构避免后期修改:
# models.py
import datetime
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import scoped_session
from sqlalchemy import (
create_engine,
Column,
Integer,
String,
Enum,
DECIMAL,
DateTime,
Boolean,
UniqueConstraint,
Index,
)
from sqlalchemy.ext.declarative import declarative_base
# 基础类
Base = declarative_base()
# 创建引擎
engine = create_engine(
"mysql+pymysql://tom:123@192.168.0.120:3306/db1?charset=utf8mb4",
# "mysql+pymysql://tom@127.0.0.1:3306/db1?charset=utf8mb4", # 无密码时
# 超过链接池大小外最多创建的链接
max_overflow=0,
# 链接池大小
pool_size=5,
# 链接池中没有可用链接则最多等待的秒数,超过该秒数后报错
pool_timeout=10,
# 多久之后对链接池中的链接进行一次回收
pool_recycle=1,
# 查看原生语句(未格式化)
echo=True,
)
# 绑定引擎
Session = sessionmaker(bind=engine)
# 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象conn
# 内部会采用threading.local进行隔离
session = scoped_session(Session)
class UserInfo(Base):
"""必须继承Base"""
# 数据库中存储的表名
__tablename__ = "userInfo"
# 对于必须插入的字段,采用nullable=False进行约束,它相当于NOT NULL
id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")
name = Column(String(32), index=True, nullable=False, comment="姓名")
age = Column(Integer, nullable=False, comment="年龄")
phone = Column(DECIMAL(6), nullable=False, unique=True, comment="手机号")
address = Column(String(64), nullable=False, comment="地址")
# 对于非必须插入的字段,不用采取nullable=False进行约束
gender = Column(Enum("male", "female"), default="male", comment="性别")
create_time = Column(DateTime, default=datetime.datetime.now, comment="创建时间")
last_update_time = Column(
DateTime, onupdate=datetime.datetime.now, comment="最后更新时间"
)
delete_status = Column(Boolean(), default=False, comment="是否删除")
__table__args__ = (
UniqueConstraint("name", "age", "phone"), # 联合唯一约束
Index("name", "addr", unique=True), # 联合唯一索引
)
def __str__(self):
return f"object : <id:{self.id} name:{self.name}>"
if __name__ == "__main__":
# 删除表
Base.metadata.drop_all(engine)
# 创建表
Base.metadata.create_all(engine)
记录操作
新增记录
新增单条记录:
# 获取链接池、ORM表对象
import models
user_instance = models.UserInfo(
name="Jack",
age=18,
phone=330621,
address="Beijing",
gender="male"
)
models.session.add(user_instance)
# 提交
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()批量新增
批量新增能减少TCP链接次数,提升插入性能:
# 获取链接池、ORM表对象
import models
user_instance1 = models.UserInfo(
name="Tom",
age=19,
phone=330624,
address="Shanghai",
gender="male"
)
user_instance2 = models.UserInfo(
name="Mary",
age=20,
phone=330623,
address="Chongqing",
gender="female"
)
models.session.add_all(
(
user_instance1,
user_instance2
)
)
# 提交
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()修改记录
修改某些记录:
# 获取链接池、ORM表对象
import models
# 修改的信息:
# - Jack -> Jack + son
# 在SQLAlchemy中,四则运算符号只能用于数值类型
# 如果是字符串类型需要在原本的基础值上做改变,必须设置
# - age -> age + 1
# synchronize_session=False
models.session.query(models.UserInfo)\
.filter_by(name="Jack")\
.update(
{
"name": models.UserInfo.name + "son",
"age": models.UserInfo.age + 1
},
synchronize_session=False
)
# 本次修改具有字符串字段在原值基础上做更改的操作,所以必须添加
# synchronize_session=False
# 如果只修改年龄,则不用添加
# 提交
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()删除记录
删除记录用的比较少,了解即可,一般都是像上面那样增加一个delete_status的字段,如果为1则代表删除:
# 获取链接池、ORM表对象
import models
models.session.query(models.UserInfo).filter_by(name="Mary").delete()
# 提交
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()单表查询
基本查询
查所有记录、所有字段,all()方法将返回一个列表,内部包裹着每一行的记录对象:
# 获取链接池、ORM表对象
import models
result = models.session.query(models.UserInfo)\
.all()
print(result)
# [<models.UserInfo object at 0x7f4d3d606fd0>, <models.UserInfo object at 0x7f4d3d606f70>]
for row in result:
print(row)
# object : <id:1 name:Jackson>
# object : <id:2 name:Tom>
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()查所有记录、某些字段(注意,下面返回的元组实际上是一个命名元组,可以直接通过.操作符进行操作):
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo.id,
models.UserInfo.name,
models.UserInfo.age
).all()
print(result)
# [(1, 'Jackson', 19), (2, 'Tom', 19)]
for row in result:
print(row)
# (1, 'Jackson', 19)
# (2, 'Tom', 19)
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()只拿第一条记录,first()方法将返回单条记录对象(注意,下面返回的元组实际上是一个命名元组,可以直接通过.操作符进行操作):
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo.id,
models.UserInfo.name,
models.UserInfo.age
).first()
print(result)
# (1, 'Jackson', 19)
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()AS别名
通过字段的label()方法,我们可以为它取一个别名:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo.name.label("s_name"),
models.UserInfo.age.label("s_age")
).all()
for row in result:
print(row.s_name)
print(row.s_age)
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()条件查询
一个条件的过滤:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo,
).filter(
models.UserInfo.name == "Jackson"
).all()
# 上面是Python语句形式的过滤条件,由filter方法调用
# 亦可以使用ORM的形式进行过滤,通过filter_by方法调用
# 如下所示
# .filter_by(name="Jackson").all()
# 个人更推荐使用filter过滤,它看起来更直观,更简单,可以支持 == != > < >= <=等常见符号
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()AND查询:
# 获取链接池、ORM表对象
import models
# 导入AND
from sqlalchemy import and_
result = models.session.query(
models.UserInfo,
).filter(
and_(
models.UserInfo.name == "Jackson",
models.UserInfo.gender == "male"
)
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()OR查询:
# 获取链接池、ORM表对象
import models
# 导入OR
from sqlalchemy import or_
result = models.session.query(
models.UserInfo,
).filter(
or_(
models.UserInfo.name == "Jackson",
models.UserInfo.gender == "male"
)
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()NOT查询:
# 获取链接池、ORM表对象
import models
# 导入NOT
from sqlalchemy import not_
result = models.session.query(
models.UserInfo,
).filter(
not_(
models.UserInfo.name == "Jackson",
)
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()范围查询
BETWEEN查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo,
).filter(
models.UserInfo.age.between(15, 21)
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f11391ea2b0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()包含查询
IN查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo,
).filter(
models.UserInfo.age.in_((18, 19, 20))
).all()
# 过滤成功的结果数量
print(len(result))
# 2
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7fdeeaa774f0>, <models.UserInfo object at 0x7fdeeaa77490>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()NOT IN,只需要加上~即可:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo,
).filter(
~models.UserInfo.age.in_((18, 19, 20))
).all()
# 过滤成功的结果数量
print(len(result))
# 0
# 过滤成功的结果
print(result)
# []
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()模糊匹配
LIKE查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo,
).filter(
models.UserInfo.name.like("Jack%")
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7fee1614f4f0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()分页查询
对结果all()返回的列表进行一次切片即可:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo,
).all()[0:1]
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7fee1614f4f0>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()排序查询
ASC升序、DESC降序,需要指定排序规则:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.UserInfo,
).filter(
models.UserInfo.age > 12
).order_by(
models.UserInfo.age.desc()
).all()
# 过滤成功的结果数量
print(len(result))
# 2
# 过滤成功的结果
print(result)
# [<models.UserInfo object at 0x7f90eccd26d0>, <models.UserInfo object at 0x7f90eccd2670>]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()聚合分组
聚合分组与having过滤:
# 获取链接池、ORM表对象
import models
# 导入聚合函数
from sqlalchemy import func
result = models.session.query(
func.sum(models.UserInfo.age)
).group_by(
models.UserInfo.gender
).having(
func.sum(models.UserInfo.id > 1)
).all()
# 过滤成功的结果数量
print(len(result))
# 1
# 过滤成功的结果
print(result)
# [(Decimal('38'),)]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()多表查询
多表创建
五表关系:
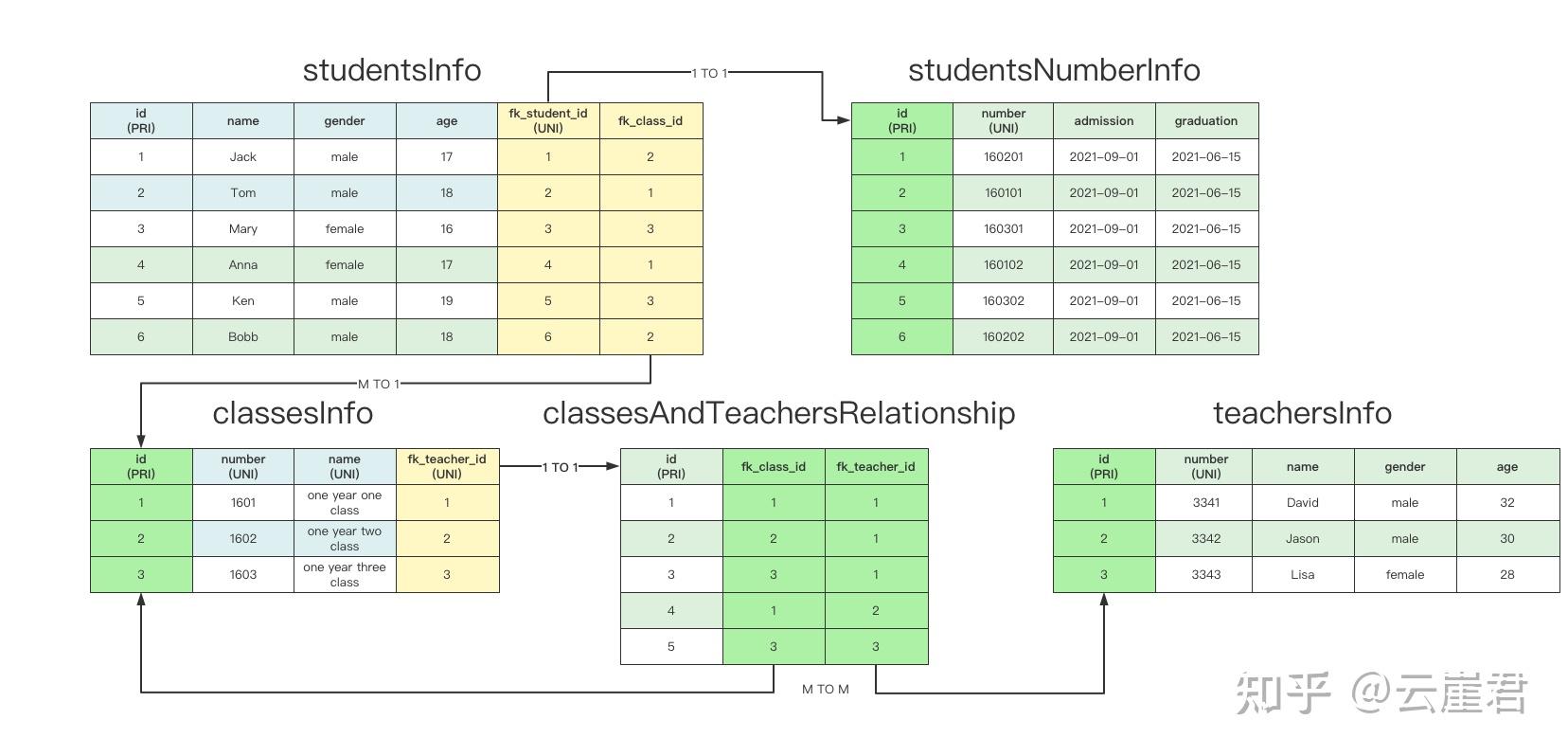
建表语句:
# models.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import relationship
from sqlalchemy import (
create_engine,
Column,
Integer,
Date,
String,
Enum,
ForeignKey,
UniqueConstraint,
)
from sqlalchemy.ext.declarative import declarative_base
# 基础类
Base = declarative_base()
# 创建引擎
engine = create_engine(
"mysql+pymysql://tom:123@192.168.0.120:3306/db1?charset=utf8mb4",
# "mysql+pymysql://tom@127.0.0.1:3306/db1?charset=utf8mb4", # 无密码时
# 超过链接池大小外最多创建的链接
max_overflow=0,
# 链接池大小
pool_size=5,
# 链接池中没有可用链接则最多等待的秒数,超过该秒数后报错
pool_timeout=10,
# 多久之后对链接池中的链接进行一次回收
pool_recycle=1,
# 查看原生语句
# echo=True
)
# 绑定引擎
Session = sessionmaker(bind=engine)
# 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象
# 内部会采用threading.local进行隔离
session = scoped_session(Session)
class StudentsNumberInfo(Base):
"""学号表"""
__tablename__ = "studentsNumberInfo"
id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")
number = Column(Integer, nullable=False, unique=True, comment="学生编号")
admission = Column(Date, nullable=False, comment="入学时间")
graduation = Column(Date, nullable=False, comment="毕业时间")
class TeachersInfo(Base):
"""教师表"""
__tablename__ = "teachersInfo"
id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")
number = Column(Integer, nullable=False, unique=True, comment="教师编号")
name = Column(String(64), nullable=False, comment="教师姓名")
gender = Column(Enum("male", "female"), nullable=False, comment="教师性别")
age = Column(Integer, nullable=False, comment="教师年龄")
class ClassesInfo(Base):
"""班级表"""
__tablename__ = "classesInfo"
id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")
number = Column(Integer, nullable=False, unique=True, comment="班级编号")
name = Column(String(64), nullable=False, unique=True, comment="班级名称")
# 一对一关系必须为连接表的连接字段创建UNIQUE的约束,这样才能是一对一,否则是一对多
fk_teacher_id = Column(
Integer,
ForeignKey(
"teachersInfo.id",
ondelete="CASCADE",
onupdate="CASCADE",
),
nullable=False,
unique=True,
comment="班级负责人"
)
# 下面这2个均属于逻辑字段,适用于正反向查询。在使用ORM的时候,我们不必每次都进行JOIN查询,而恰好正反向的查询使用频率会更高
# 这种逻辑字段不会在物理层面上创建,它只适用于查询,本身不占据任何数据库的空间
# sqlalchemy的正反向概念与Django有所不同,Django是外键字段在那边,那边就作为正
# 而sqlalchemy是relationship字段在那边,那边就作为正
# 比如班级表拥有 relationship 字段,而老师表不曾拥有
# 那么用班级表的这个relationship字段查老师时,就称为正向查询
# 反之,如果用老师来查班级,就称为反向查询
# 另外对于这个逻辑字段而言,根据不同的表关系,创建的位置也不一样:
# - 1 TO 1:建立在任意一方均可,查询频率高的一方最好
# - 1 TO M:建立在M的一方
# - M TO M:中间表中建立2个逻辑字段,这样任意一方都可以先反向,再正向拿到另一方
# - 遵循一个原则,ForeignKey建立在那个表上,那个表上就建立relationship
# - 有几个ForeignKey,就建立几个relationship
# 总而言之,使用ORM与原生SQL最直观的区别就是正反向查询能带来更高的代码编写效率,也更加简单
# 甚至我们可以不用外键约束,只创建这种逻辑字段,让表与表之间的耦合度更低,但是这样要避免脏数据的产生
# 班级负责人,这里是一对一关系,一个班级只有一个负责人
leader_teacher = relationship(
# 正向查询时所链接的表,当使用 classesInfo.leader_teacher 时,它将自动指向fk的那一条记录
"TeachersInfo",
# 反向查询时所链接的表,当使用 teachersInfo.leader_class 时,它将自动指向该老师所管理的班级
backref="leader_class",
)
class ClassesAndTeachersRelationship(Base):
"""任教老师与班级的关系表"""
__tablename__ = "classesAndTeachersRelationship"
id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")
# 中间表中注意不要设置单列的UNIQUE约束,否则就会变为一对一
fk_teacher_id = Column(
Integer,
ForeignKey(
"teachersInfo.id",
ondelete="CASCADE",
onupdate="CASCADE",
),
nullable=False,
comment="教师记录"
)
fk_class_id = Column(
Integer,
ForeignKey(
"classesInfo.id",
ondelete="CASCADE",
onupdate="CASCADE",
),
nullable=False,
comment="班级记录"
)
# 多对多关系的中间表必须使用联合唯一约束,防止出现重复数据
__table_args__ = (
UniqueConstraint("fk_teacher_id", "fk_class_id"),
)
# 逻辑字段
# 给班级用的,查看所有任教老师
mid_to_teacher = relationship(
"TeachersInfo",
backref="mid",
)
# 给老师用的,查看所有任教班级
mid_to_class = relationship(
"ClassesInfo",
backref="mid"
)
class StudentsInfo(Base):
"""学生信息表"""
__tablename__ = "studentsInfo"
id = Column(Integer, primary_key=True, autoincrement=True, comment="主键")
name = Column(String(64), nullable=False, comment="学生姓名")
gender = Column(Enum("male", "female"), nullable=False, comment="学生性别")
age = Column(Integer, nullable=False, comment="学生年龄")
# 外键约束
# 一对一关系必须为连接表的连接字段创建UNIQUE的约束,这样才能是一对一,否则是一对多
fk_student_id = Column(
Integer,
ForeignKey(
"studentsNumberInfo.id",
ondelete="CASCADE",
onupdate="CASCADE"
),
nullable=False,
comment="学生编号"
)
# 相比于一对一,连接表的连接字段不用UNIQUE约束即为多对一关系
fk_class_id = Column(
Integer,
ForeignKey(
"classesInfo.id",
ondelete="CASCADE",
onupdate="CASCADE"
),
comment="班级编号"
)
# 逻辑字段
# 所在班级, 这里是一对多关系,一个班级中可以有多名学生
from_class = relationship(
"ClassesInfo",
backref="have_student",
)
# 学生学号,这里是一对一关系,一个学生只能拥有一个学号
number_info = relationship(
"StudentsNumberInfo",
backref="student_info",
)
if __name__ == "__main__":
# 删除表
Base.metadata.drop_all(engine)
# 创建表
Base.metadata.create_all(engine)插入数据:
# 获取链接池、ORM表对象
import models
import datetime
models.session.add_all(
(
# 插入学号表数据
models.StudentsNumberInfo(
number=160201,
admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),
graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))
),
models.StudentsNumberInfo(
number=160101,
admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),
graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))
),
models.StudentsNumberInfo(
number=160301,
admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),
graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))
),
models.StudentsNumberInfo(
number=160102,
admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),
graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))
),
models.StudentsNumberInfo(
number=160302,
admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),
graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))
),
models.StudentsNumberInfo(
number=160202,
admission=datetime.datetime.date(datetime.datetime(2016, 9, 1)),
graduation=datetime.datetime.date(datetime.datetime(2021, 6, 15))
),
# 插入教师表数据
models.TeachersInfo(
number=3341, name="David", gender="male", age=32,
),
models.TeachersInfo(
number=3342, name="Jason", gender="male", age=30,
),
models.TeachersInfo(
number=3343, name="Lisa", gender="female", age=28,
),
# 插入班级表数据
models.ClassesInfo(
number=1601, name="one year one class", fk_teacher_id=1
),
models.ClassesInfo(
number=1602, name="one year two class", fk_teacher_id=2
),
models.ClassesInfo(
number=1603, name="one year three class", fk_teacher_id=3
),
# 插入中间表数据
models.ClassesAndTeachersRelationship(
fk_class_id=1, fk_teacher_id=1
),
models.ClassesAndTeachersRelationship(
fk_class_id=2, fk_teacher_id=1
),
models.ClassesAndTeachersRelationship(
fk_class_id=3, fk_teacher_id=1
),
models.ClassesAndTeachersRelationship(
fk_class_id=1, fk_teacher_id=2
),
models.ClassesAndTeachersRelationship(
fk_class_id=3, fk_teacher_id=3
),
# 插入学生表数据
models.StudentsInfo(
name="Jack", gender="male", age=17, fk_student_id=1, fk_class_id=2
),
models.StudentsInfo(
name="Tom", gender="male", age=18, fk_student_id=2, fk_class_id=1
),
models.StudentsInfo(
name="Mary", gender="female", age=16, fk_student_id=3,
fk_class_id=3
),
models.StudentsInfo(
name="Anna", gender="female", age=17, fk_student_id=4,
fk_class_id=1
),
models.StudentsInfo(
name="Bobby", gender="male", age=18, fk_student_id=6, fk_class_id=2
),
)
)
models.session.commit()
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()JOIN查询
INNER JOIN:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.StudentsInfo.name,
models.StudentsNumberInfo.number,
models.ClassesInfo.number
).join(
models.StudentsNumberInfo,
models.StudentsInfo.fk_student_id == models.StudentsNumberInfo.id
).join(
models.ClassesInfo,
models.StudentsInfo.fk_class_id == models.ClassesInfo.id
).all()
print(result)
# [('Jack', 160201, 1602), ('Tom', 160101, 1601), ('Mary', 160301, 1603), ('Anna', 160102, 1601), ('Bobby', 160202, 1602)]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()LEFT JOIN只需要在每个JOIN中指定isouter关键字参数为True即可:
session.query(
左表.字段,
右表.字段
)
.join(
右表,
链接条件,
isouter=True
).all()RIGHT JOIN需要换表的位置,SQLALchemy本身并未提供RIGHT JOIN,所以使用时一定要注意驱动顺序,小表驱动大表(如果不注意顺序,MySQL优化器内部也会优化):
session.query(
左表.字段,
右表.字段
)
.join(
左表,
链接条件,
isouter=True
).all()UNION&UNION ALL
将多个查询结果联合起来,必须使用filter(),后面不加all()方法。
因为all()会返回一个列表,而filter()返回的是一个<class 'sqlalchemy.orm.query.Query'>查询对象,此外,必须单拿某一个字段,不能不指定字段直接query():
# 获取链接池、ORM表对象
import models
students_name = models.session.query(models.StudentsInfo.name).filter()
students_number = models.session.query(models.StudentsNumberInfo.number)\
.filter()
class_name = models.session.query(models.ClassesInfo.name).filter()
result = students_name.union_all(students_number).union_all(class_name)
print(result.all())
# [
# ('Jack',), ('Tom',), ('Mary',), ('Anna',), ('Bobby',),
# ('160101',), ('160102',), ('160201',), ('160202',), ('160301',), ('160302',),
# ('one year one class',), ('one year three class',), ('one year two class',)
# ]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()子查询
子查询使用subquery()实现,如下所示,查询每个班级中年龄最小的人:
# 获取链接池、ORM表对象
import models
from sqlalchemy import func
# 子查询中所有字段的访问都需要加上c的前缀
# 如 sub_query.c.id、 sub_query.c.name等
sub_query = models.session.query(
# 使用label()来为字段AS一个别名
# 后续访问需要通过sub_query.c.alias进行访问
func.min(models.StudentsInfo.age).label("min_age"),
models.ClassesInfo.id,
models.ClassesInfo.name
).join(
models.ClassesInfo,
models.StudentsInfo.fk_class_id == models.ClassesInfo.id
).group_by(
models.ClassesInfo.id
).subquery()
result = models.session.query(
models.StudentsInfo.name,
sub_query.c.min_age,
sub_query.c.name
).join(
sub_query,
sub_query.c.id == models.StudentsInfo.fk_class_id
).filter(
sub_query.c.min_age == models.StudentsInfo.age
)
print(result.all())
# [('Jack', 17, 'one year two class'), ('Mary', 16, 'one year three class'), ('Anna', 17, 'one year one class')]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询
上面我们都是通过JOIN进行查询的,实际上我们也可以通过逻辑字段relationship进行查询。
下面是正向查询的示例,正向查询是指从有relationship逻辑字段的表开始查询:
# 查询所有学生的所在班级,我们可以通过学生的from_class字段拿到其所在班级
# 另外,对于学生来说,班级只能有一个,所以have_student应当是一个对象
# 获取链接池、ORM表对象
import models
students_lst = models.session.query(
models.StudentsInfo
).all()
for row in students_lst:
print(f"""
student name : {row.name}
from : {row.from_class.name}
""")
# student name : Mary
# from : one year three class
# student name : Anna
# from : one year one class
# student name : Bobby
# from : one year two class
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()下面是反向查询的示例,反向查询是指从没有relationship逻辑字段的表开始查询:
# 查询所有班级中的所有学生,学生表中有relationship,并且它的backref为have_student,所以我们可以通过班级.have_student来获取所有学生记录
# 另外,对于班级来说,学生可以有多个,所以have_student应当是一个序列
# 获取链接池、ORM表对象
import models
classes_lst = models.session.query(
models.ClassesInfo
).all()
for row in classes_lst:
print("class name :", row.name)
for student in row.have_student:
print("student name :", student.name)
# class name : one year one class
# student name : Jack
# student name : Anna
# class name : one year two class
# student name : Tom
# class name : one year three class
# student name : Mary
# student name : Bobby
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()总结,正向查询的逻辑字段总是得到一个对象,反向查询的逻辑字段总是得到一个列表。
反向方法
使用逻辑字段relationship可以直接对一些跨表记录进行增删改查。
由于逻辑字段是一个类似于列表的存在(仅限于反向查询,正向查询总是得到一个对象),所以列表的绝大多数方法都能用。
<class 'sqlalchemy.orm.collections.InstrumentedList'>
- append()
- clear()
- copy()
- count()
- extend()
- index()
- insert()
- pop()
- remove()
- reverse()
- sort()下面不再进行实机演示,因为我们上面的几张表中做了很多约束。
# 比如
# 给老师增加班级
result = session.query(Teachers).first()
# extend方法:
result.re_class.extend([
Classes(name="三年级一班",),
Classes(name="三年级二班",),
])
# 比如
# 减少老师所在的班级
result = session.query(Teachers).first()
# 待删除的班级对象,集合查找比较快
delete_class_set = {
session.query(Classes).filter_by(id=7).first(),
session.query(Classes).filter_by(id=8).first(),
}
# 循换老师所在的班级
# remove方法:
for class_obj in result.re_class:
if class_obj in delete_class_set:
result.re_class.remove(class_obj)
# 比如
# 清空老师所任教的所有班级
# 拿出一个老师
result = session.query(Teachers).first()
result.re_class.clear()查询案例
1)查看每个班级共有多少学生:
JOIN查询:
# 获取链接池、ORM表对象
import models
from sqlalchemy import func
result = models.session.query(
models.ClassesInfo.name,
func.count(models.StudentsInfo.id)
).join(
models.StudentsInfo,
models.ClassesInfo.id == models.StudentsInfo.fk_class_id
).group_by(
models.ClassesInfo.id
).all()
print(result)
# [('one year one class', 2), ('one year two class', 2), ('one year three class', 1)]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询:
# 获取链接池、ORM表对象
import models
result = {}
class_lst = models.session.query(
models.ClassesInfo
).all()
for row in class_lst:
for student in row.have_student:
count = result.setdefault(row.name, 0)
result[row.name] = count + 1
print(result.items())
# dict_items([('one year one class', 2), ('one year two class', 2), ('one year three class', 1)])
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()2)查看每个学生的入学、毕业年份以及所在的班级名称:
JOIN查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.StudentsNumberInfo.number,
models.StudentsInfo.name,
models.ClassesInfo.name,
models.StudentsNumberInfo.admission,
models.StudentsNumberInfo.graduation
).join(
models.StudentsInfo,
models.StudentsInfo.fk_class_id == models.ClassesInfo.id
).join(
models.StudentsNumberInfo,
models.StudentsNumberInfo.id == models.StudentsInfo.fk_student_id
).order_by(
models.StudentsNumberInfo.number.asc()
).all()
print(result)
# [
# (160101, 'Tom', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160102, 'Anna', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160201, 'Jack', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160202, 'Bobby', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160301, 'Mary', 'one year three class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15))
# ]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询:
# 获取链接池、ORM表对象
import models
result = []
student_lst = models.session.query(
models.StudentsInfo
).all()
for row in student_lst:
result.append((
row.number_info.number,
row.name,
row.from_class.name,
row.number_info.admission,
row.number_info.graduation
))
print(result)
# [
# (160101, 'Tom', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160102, 'Anna', 'one year one class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160201, 'Jack', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160202, 'Bobby', 'one year two class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15)),
# (160301, 'Mary', 'one year three class', datetime.date(2016, 9, 1), datetime.date(2021, 6, 15))
# ]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()3)查看David所教授的学生中年龄最小的学生:
JOIN查询:
# 获取链接池、ORM表对象
import models
result = models.session.query(
models.TeachersInfo.name,
models.StudentsInfo.name,
models.StudentsInfo.age,
models.ClassesInfo.name
).join(
models.ClassesAndTeachersRelationship,
models.ClassesAndTeachersRelationship.fk_class_id == models.ClassesInfo.id
).join(
models.TeachersInfo,
models.ClassesAndTeachersRelationship.fk_teacher_id == models.TeachersInfo.id
).join(
models.StudentsInfo,
models.StudentsInfo.fk_class_id == models.ClassesInfo.id
).filter(
models.TeachersInfo.name == "David"
).order_by(
models.StudentsInfo.age.asc(),
models.StudentsInfo.id.asc()
).limit(1).all()
print(result)
# [('David', 'Mary', 16, 'one year three class')]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询:
# 获取链接池、ORM表对象
import models
david = models.session.query(
models.TeachersInfo
).filter(
models.TeachersInfo.name == "David"
).first()
student_lst = []
# 反向查询拿到任教班级,反向是一个列表,所以直接for
for row in david.mid:
cls = row.mid_to_class
# 通过任教班级,反向拿到其下的所有学生
cls_students = cls.have_student
# 遍历学生
for student in cls_students:
student_lst.append(
(
david.name,
student.name,
student.age,
cls.name
)
)
# 筛选出年龄最小的
min_age_student_lst = sorted(
student_lst, key=lambda tpl: tpl[2])[0]
print(min_age_student_lst)
# ('David', 'Mary', 16, 'one year three class')
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()4)查看每个班级的负责人是谁,以及任课老师都有谁:
JOIN查询:
# 获取链接池、ORM表对象
import models
from sqlalchemy import func
# 先查任课老师
sub_query = models.session.query(
models.ClassesAndTeachersRelationship.fk_class_id.label("class_id"),
func.group_concat(models.TeachersInfo.name).label("have_teachers")
).join(
models.ClassesInfo,
models.ClassesAndTeachersRelationship.fk_class_id == models.ClassesInfo.id
).join(
models.TeachersInfo,
models.ClassesAndTeachersRelationship.fk_teacher_id == models.TeachersInfo.id
).group_by(
models.ClassesAndTeachersRelationship.fk_class_id
).subquery()
result = models.session.query(
models.ClassesInfo.name.label("class_name"),
models.TeachersInfo.name.label("leader_teacher"),
sub_query.c.have_teachers.label("have_teachers")
).join(
models.TeachersInfo,
models.ClassesInfo.fk_teacher_id == models.TeachersInfo.id
).join(
sub_query,
sub_query.c.class_id == models.ClassesInfo.id
).all()
print(result)
# [('one year one class', 'David', 'Jason,David'), ('one year two class', 'Jason', 'David'), ('one year three class', 'Lisa', 'David,Lisa')]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()正反查询:
# 获取链接池、ORM表对象
import models
result = []
# 获取所有班级
classes_lst = models.session.query(
models.ClassesInfo
).all()
for cls in classes_lst:
cls_message = [
cls.name,
cls.leader_teacher.name,
[],
]
for row in cls.mid:
cls_message[-1].append(row.mid_to_teacher.name)
result.append(cls_message)
print(result)
# [['one year one class', 'David', ['David', 'Jason']], ['one year two class', 'Jason', ['David']], ['one year three class', 'Lisa', ['David', 'Lisa']]]
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close()原生SQL
查看执行命令
如果一条查询语句是filter()结尾,则该对象的__str__方法会返回格式化后的查询语句:
print(
models.session.query(models.StudentsInfo).filter()
)
SELECT `studentsInfo`.id AS `studentsInfo_id`, `studentsInfo`.name AS `studentsInfo_name`, `studentsInfo`.gender AS `studentsInfo_gender`, `studentsInfo`.age AS `studentsInfo_age`, `studentsInfo`.fk_student_id AS `studentsInfo_fk_student_id`, `studentsInfo`.fk_class_id AS `studentsInfo_fk_class_id`
FROM `studentsInfo`执行原生命令
执行原生命令可使用session.execute()方法执行,它将返回一个cursor游标对象,如下所示:
# 获取链接池、ORM表对象
import models
cursor = models.session.execute(
"SELECT * FROM studentsInfo WHERE id = (:uid)", params={'uid': 1})
print(cursor.fetchall())
# 关闭链接,亦可使用session.remove(),它将回收该链接
models.session.close() # 获取链接池、ORM表对象
![【LeetCode】数据结构题解(11)[用队列实现栈]](https://img-blog.csdnimg.cn/a5c4695c00b94865831cb79d75a45b32.png)