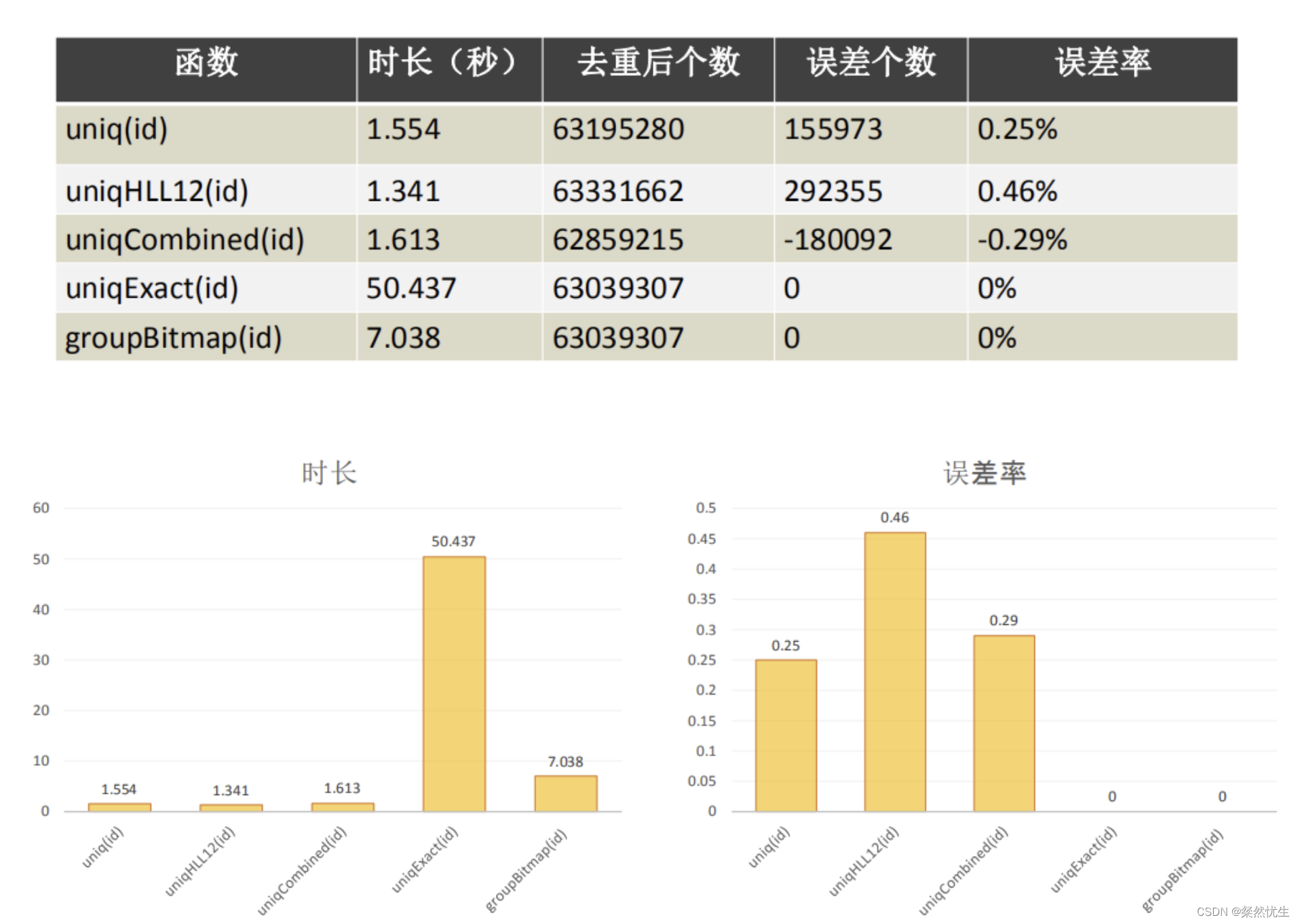
四 、Mysql开发
102 可以使用MySQL直接存储文件吗?
可以使用 BLOB (binary large object),用来存储二进制大对象的字段类型。
TinyBlob 255 值的长度加上用于记录长度的1个字节(8位)
Blob 65K值的长度加上用于记录长度的2个字节(16位)
MediumBlob 16M值的长度加上用于记录长度的3个字节(24位)
LongBlob 4G 值的长度加上用于记录长度的4个字节(32位)。
103 什么时候存,什么时候不存?
存:需要高效查询并且文件很小的时候
不存:文件比较大,数据量多或变更频繁的时候
104 存储的时候有遇到过什么问题吗?
- 上传数据过大sql执行失败 调整max_allowed_packet
- 主从同步数据时比较慢
- 应用线程阻塞
- 占用网络带宽
- 高频访问的图片无法使用浏览器缓存
105 Emoji乱码怎么办?
使用utf8mb4
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的
unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,一般情况
下使用utf8也就够了。
106 如何存储ip地址?
- 使用字符串
- 使用无符号整型
4个字节即解决问题
可以支持范围查询
INET_ATON() 和 INET_NTOA() ipv6 使用 INET6_ATON() 和 INET6_NTOA()
107 长文本如何存储?
可以使用Text存储
TINYTEXT(255长度)
TEXT(65535)
MEDIUMTEXT(int最大值16M)
LONGTEXT(long最大值4G)
108 大段文本如何设计表结构?
- 或将大段文本同时存储到搜索引擎
- 分表存储
- 分表后多段存储
109 大段文本查找时如何建立索引?
- 全文检索,模糊匹配最好存储到搜索引擎中
- 指定索引长度
- 分段存储后创建索引
110 有没有在开发中使用过TEXT,BLOB 数据类型
BLOB 之前做ERP的时候使用过,互联网项目一般不用BLOB
TEXT 文献,文章,小说类,新闻,会议内容 等
111 日期,时间如何存取? - 使用 TIMESTAMP,DATETIME
- 使用字符串
112 TIMESTAMP,DATETIME 的区别是什么?
跨时区的业务使用 TIMESTAMP,TIMESTAMP会有时区转换
数据类型 MySQL 5.6.4之前需要存储 MySQL 5.6.4之后需要存储
DATETIME 8 bytes 5 bytes + 小数秒存储
TIMESTAMP 4 bytes 4 bytes + 小数秒存储
分秒数精度 存储字节大小
0 0 bytes
1,2 1 bytes
3,4 2 bytes
5,6 3 bytes
1、两者的存储方式不一样:
对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,
将其又转化为客户端当前时区进行返回。
而对于DATETIME,不做任何改变,基本上是原样输入和输出。
2、存储字节大小不同

3、两者所能存储的时间范围不一样:
timestamp所能存储的时间范围为:‘1970-01-01 00:00:01.000000’ 到 ‘2038-01-19
03:14:07.999999’。
datetime所能存储的时间范围为:‘1000-01-01 00:00:00.000000’ 到 ‘9999-12-31 23:59:59.999999’。
113 为什么不使用字符串存储日期?
字符串无法完成数据库内部的范围筛选
在大数据量存储优化索引时,查询必须加上时间范围
114 如果需要使用时间戳 timestamp和int该如何选择?
int 存储空间小,运算查询效率高,不受时区影响,精度低
timestamp 存储空间小,可以使用数据库内部时间函数比如更新,精度高,需要注意时区转换,
timestamp更易读
一般选择timestamp,两者性能差异不明显,本质上存储都是使用的int
115 char与varchar的区别?如何选择?
1.char的优点是存储空间固定(最大255),没有碎片,尤其更新比较频繁的时候,方便数据文件指针的
操作,所以存储读取速度快。缺点是空间冗余,对于数据量大的表,非固定长度属性使用char字段,空
间浪费。
2.varchar字段,存储的空间根据存储的内容变化,空间长度为L+size,存储内容长度加描述存储内容长
度信息,优点就是空间节约,缺点就是读取和存储时候,需要读取信息计算下标,才能获取完整内容。
116 财务计算有没有出现过错乱?
第一类:锁包括多线程,数据库,UI展示后超时提交等
第二类:应用与数据库浮点运算精度丢失
- 应用开发问题:多线程共享数据读写,
- 之前有过丢失精度的问题,使用decimal解决
- 使用乘法替换除法
- 使用事务保证acid特性
- 更新时使用悲观锁 SELECT … FOR UPDATE
- 数据只有标记删除
- 记录详细日志方便溯源
117 decimal与float,double的区别是什么?
float:浮点型,4字节,32bit。
double:双精度实型,8字节,64位
decimal:数字型,128bit,不存在精度损失
对于声明语法DECIMAL(M,D),自变量的值范围如下:
M是最大位数(精度),范围是1到65。可不指定,默认值是10。
D是小数点右边的位数(小数位)。范围是0到30,并且不能大于M,可不指定,默认值是0。
例如字段 salary DECIMAL(5,2),能够存储具有五位数字和两位小数的任何值,因此可以存储在salary列
中的值的范围是从-999.99到999.99。
18 浮点类型如何选型?为什么?
需要不丢失精度的计算使用DECIMAL
仅用于展示没有计算的小数存储可以使用字符串存储
低价值数据允许计算后丢失精度可以使用float double
整型记录不会出现小数的不要使用浮点类型
119 预编译sql是什么?
完整解释:
https://dev.mysql.com/doc/refman/8.0/en/prepare.html
PreparedStatement
120 预编译sql有什么好处?
预编译sql会被mysql缓存下来
作用域是每个session,对其他session无效,重新连接也会失效
提高安全性防止sql注入
select * from user where id =?
“1;delete from user where id = 1”;
编译语句有可能被重复调用,也就是说sql相同参数不同在同一session中重复查询执行效率明显比
较高
mysql 5,8 支持服务器端的预编译
121 子查询与join哪个效率高?
子查询虽然很灵活,但是执行效率并不高。
122 为什么子查询效率低?
在执行子查询的时候,MYSQL创建了临时表,查询完毕后再删除这些临时表
子查询的速度慢的原因是多了一个创建和销毁临时表的过程。
而join 则不需要创建临时表 所以会比子查询快一点
123 join查询可以无限叠加吗?Mysql对join查询有什么限制吗?
建议join不超过3张表关联,mysql对内存敏感,关联过多会占用更多内存空间,使性能下降
Too many tables; MySQL can only use 61 tables in a join;
系统限制最多关联61个表
124 join 查询算法了解吗?
Simple Nested-Loop Join:SNLJ,简单嵌套循环连接
Index Nested-Loop Join:INLJ,索引嵌套循环连接
Block Nested-Loop Join:BNLJ,缓存块嵌套循环连接
125 如何优化过多join查询关联?
适当使用冗余字段减少多表关联查询
驱动表和被驱动表(小表join大表)
业务允许的话 尽量使用inner join 让系统帮忙自动选择驱动表
关联字段一定创建索引
调整JOIN BUFFER大小
126 是否有过mysql调优经验?
调优:
- sql调优
- 表(结构)设计调优
- 索引调优
- 慢查询调优
- 操作系统调优
- 数据库参数调优
127 开发中使用过哪些调优工具?
官方自带:
EXPLAIN
mysqldumpslow
show profiles 时间
optimizer_trace
第三方:性能诊断工具,参数扫描提供建议,参数辅助优化
**128 如何监控线上环境中执行比较慢的sql? 129 如何分析一条慢sql?130 如何查看当前sql使用了哪个索引?
可以使用EXPLAIN,选择索引过程可以使用 optimizer_trace
131 索引如何进行分析和调优?
132 EXPLAIN关键字中的重要指标有哪些? **
详解文章
https://blog.csdn.net/weixin_45817985/article/details/132085347
133 MySQL数据库cpu飙升的话你会如何分析
重点是定位问题。
先
1 使用top观察mysqld的cpu利用率
- 切换到常用的数据库
- 使用show full processlist;查看会话
- 观察是哪些sql消耗了资源,其中重点观察state指标
- 定位到具体sql
2 pidstat
- 定位到线程
- 在PERFORMANCE_SCHEMA.THREADS中记录了thread_os_id 找到线程执行的sql
- 根据操作系统id可以到processlist表找到对应的会话
- 在会话中即可定位到问题sql
3 使用show profile观察sql各个阶段耗时
4 服务器上是否运行了其他程序
5 检查一下是否有慢查询
6 pref top
使用pref 工具分析哪些函数引发的cpu过高来追踪定位
134 某个表有数千万数据,查询比较慢,如何优化?说一下思路
- 前端优化 减少查询
- 合并请求:多个请求需要的数据尽量一条sql拿出来
- 会话保存:和用户会话相关的数据尽量一次取出重复使用
- 避免无效刷新
- 多级缓存 不要触及到数据库
- 应用层热点数据高速查询缓存(低一致性缓存)
- 高频查询大数据量镜像缓存(双写高一致性缓存)
- 入口层缓存(几乎不变的系统常量)
- 使用合适的字段类型,比如varchar换成char
- 一定要高效使用索引。
- 使用explain 深入观察索引使用情况
- 检查select 字段最好满足索引覆盖
- 复合索引注意观察key_len索引使用情况
- 有分组,排序,注意file sort,合理配置相应的buffer大小
- 检查查询是否可以分段查询,避免一次拿出过多无效数据
- 多表关联查询是否可以设置冗余字段,是否可以简化多表查询或分批查询
- 分而治之:把服务拆分成更小力度的微服务
- 冷热数据分库存储
- 读写分离,主被集群 然后再考虑分库分表
- 等
135 count(列名)和 count(*)有什么区别?
count()是 SQL92 定义的
标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
count(*) :对全表统计,比如一百行的表 有一列name的80行为空 此时统计的还是100
count(列名):只对一列进行统计,上面的情况count(name)就是99
如果忽略意义上的不同单独从效率上来说:
1)count(列名)在此列是主键的时候一定是快于count((*)的
2)在此列是索引的时候
如果索引列不非空那么 count(*)无法使用索引 所以要慢
如果索引非空 那么基本一样快
另外,count(列名)是和列的偏移有关的,偏移越大,代价越大,所以常用的列应该尽量排放在前面。
说明:count()会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行