目录
- 一、Selenium
- 1.为什么要学习Selenium
- (1)什么是Selenium
- (2)为什么使用selenium?
- (3)代码演示
- 2. selenium的基本使用
- (1)如何安装selenium
- (2)selenium的使用步骤
- (3)代码的演示(含初次运行时报错的解决办法、selenium获取网页源码的代码)
- 3.selenium的元素定位
- (1)引
- (2)元素定位的定义与方法
- (3)代码演示
- 4.selenium的元素信息
- (1)访问元素信息
- (2)代码演示
- 5.selenium的交互
- (1)交互
- (2)代码演示
- 二、Phantomjs
- 1. Phantomjs的基本使用
- (1)什么是Phantomjs
- (2)如何使用Phantomjs
- (3)代码演示
- 三、Headless
- 1. Headless的基本使用
- (1)什么是Headless
- (2)配置
- (3)代码的演示
说明:该文章是学习 尚硅谷在B站上分享的视频 Python爬虫教程小白零基础速通的 p51-104而记录的笔记,笔记来源于本人,关于python基础可以去CSDN上阅读本人学习黑马程序员的笔记。 若有侵权,请联系本人删除。笔记难免可能出现错误或笔误,若读者发现笔记有错误,欢迎在评论里批评指正。 请合法合理使用爬虫,不爬取任何涉密以及涉及隐私的内容,合理控制请求次数,爬取的内容未经授权请不要用于商用,保护自己,免受牢狱之灾。
在学习urllib、解析的时候,我们都是模拟浏览器向服务器发送请求,这样做,数据或多或少有一些数据缺失甚至是无法获取数据,这是由于“模拟浏览器”的行为导致的,会有各种反爬手段判断收到的请求是否是爬虫程序,此时就要引入Selenium,进而驱动真实的浏览器。当然,Selenium存在速度有点慢,效率不够高的问题,当然这也是能解决的,故引入Phantomjs。
还有一点需要说明,跟着b站视频学习到最后,发现好几个程序在使用selenium操控浏览器时,最后并没有关闭浏览器,大家在学习时可以加上下面的一句代码。
# 关闭浏览器
browser.quit()
一、Selenium
1.为什么要学习Selenium
(1)什么是Selenium

(2)为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载。
(3)代码演示
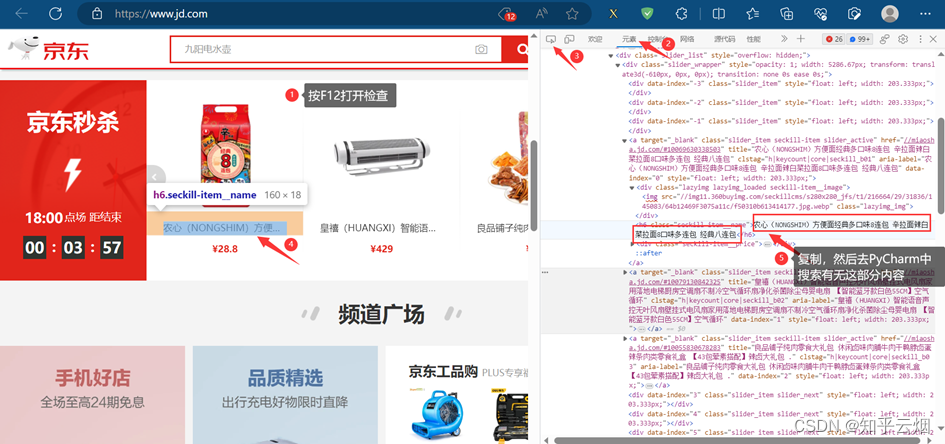
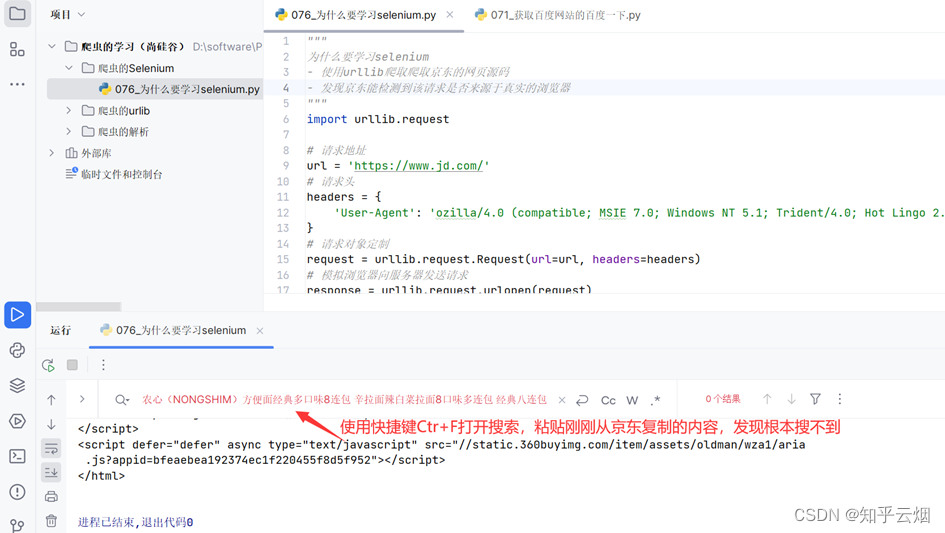
本次将要演示urllib获取京东(“https://www.jd.com/”)的网页源码,从而说明使用的urllib获取京东的网页源码会缺失秒杀的一些数据,进而引入下一节将要使用的selenium。
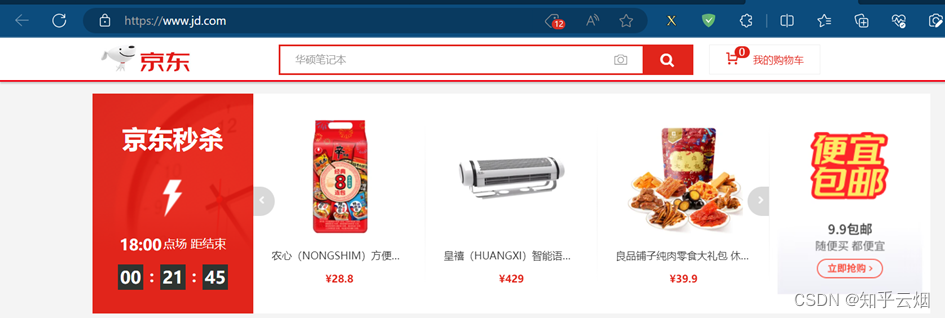
在PyCharm中创建文件夹“爬虫的Selenium”,创建文件“076_为什么要学习selenium.py”。
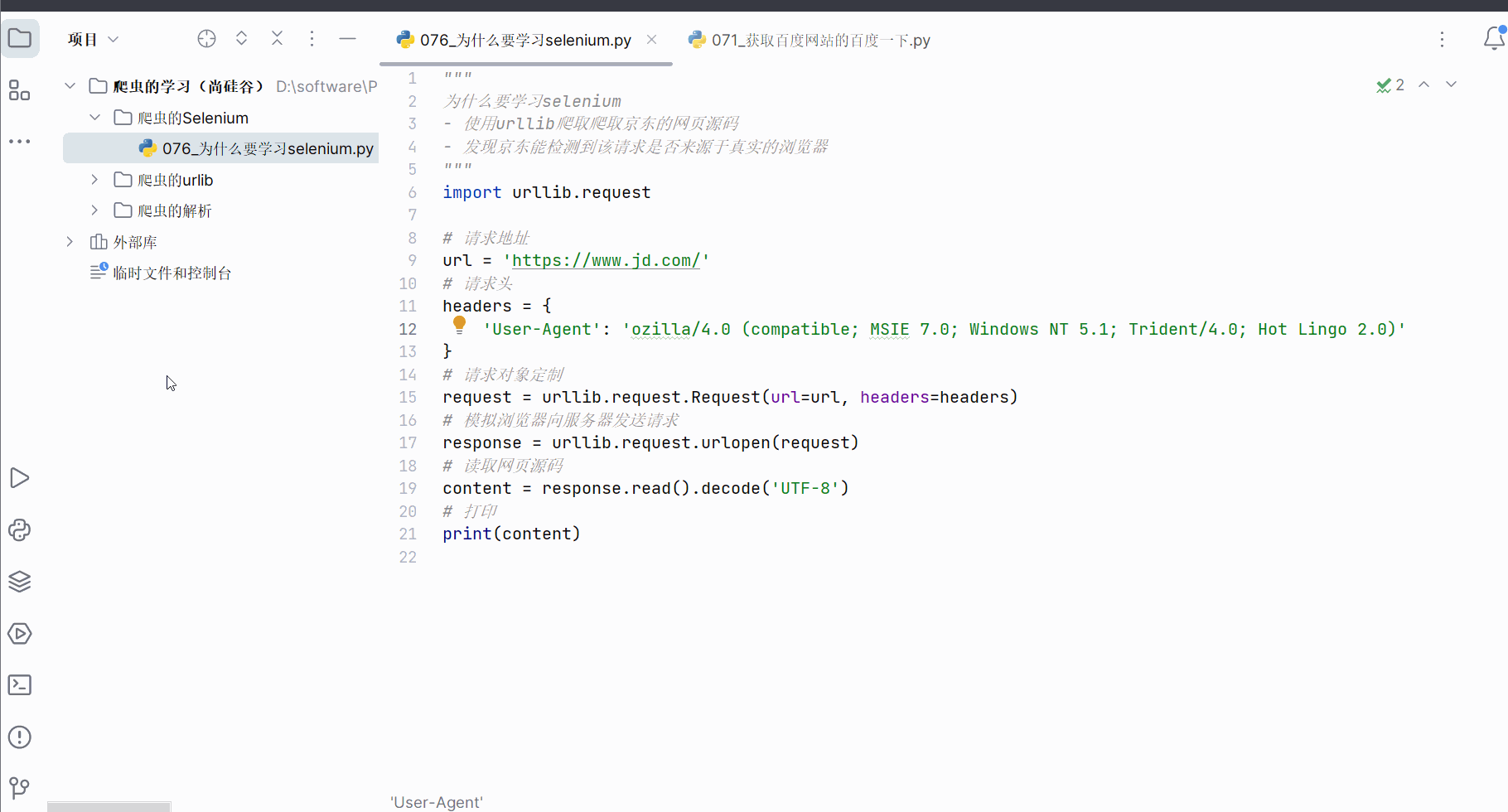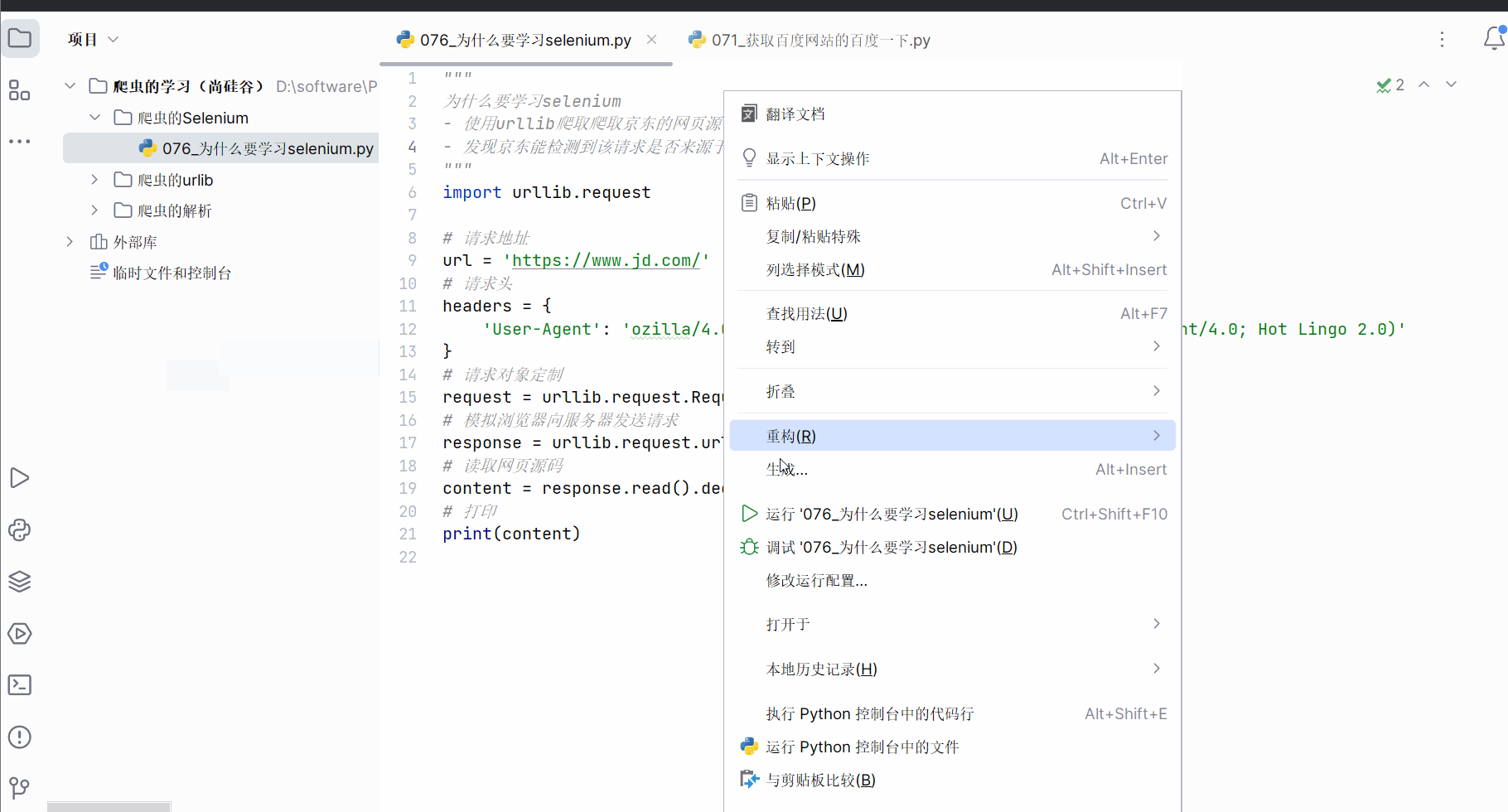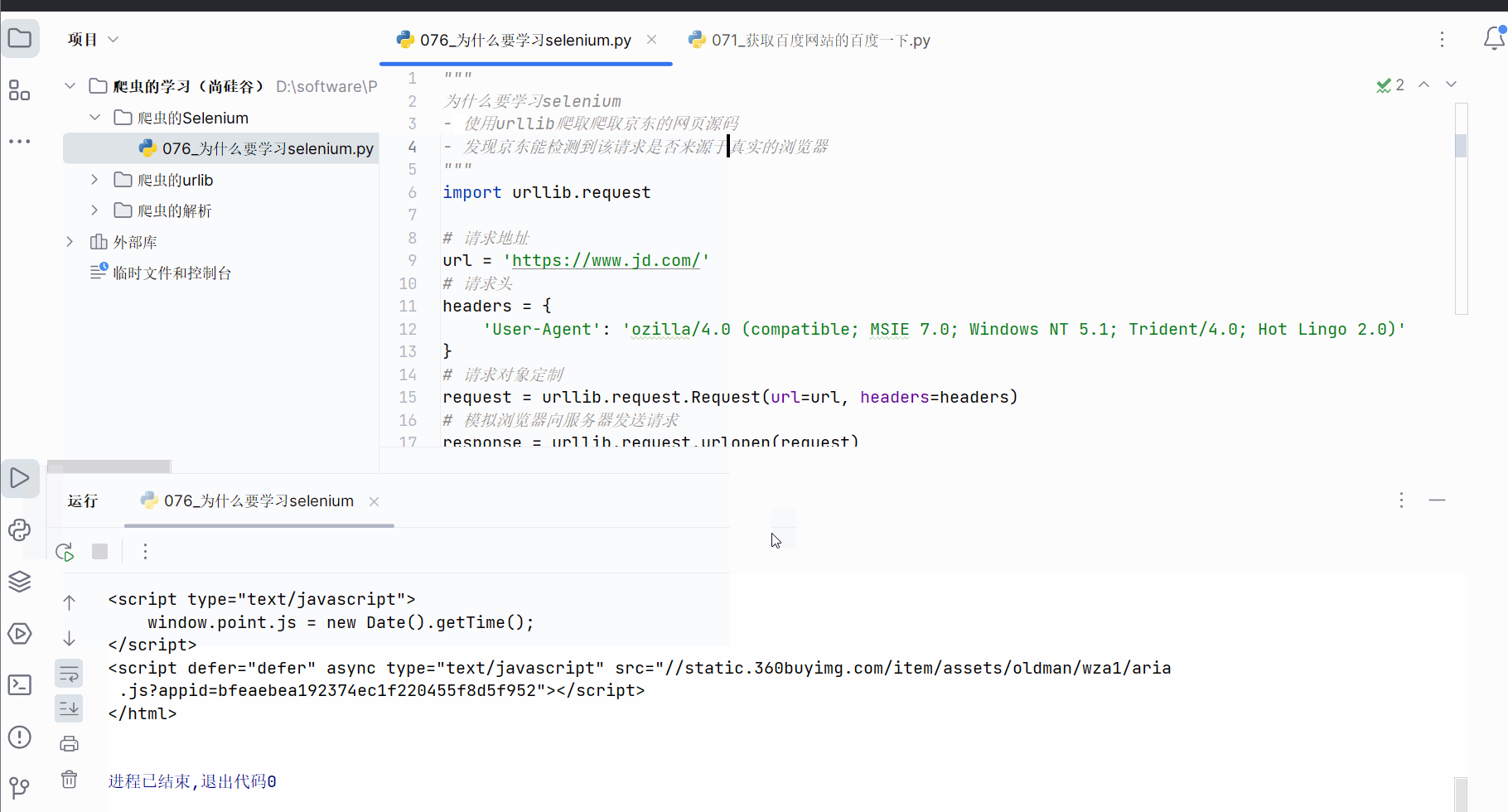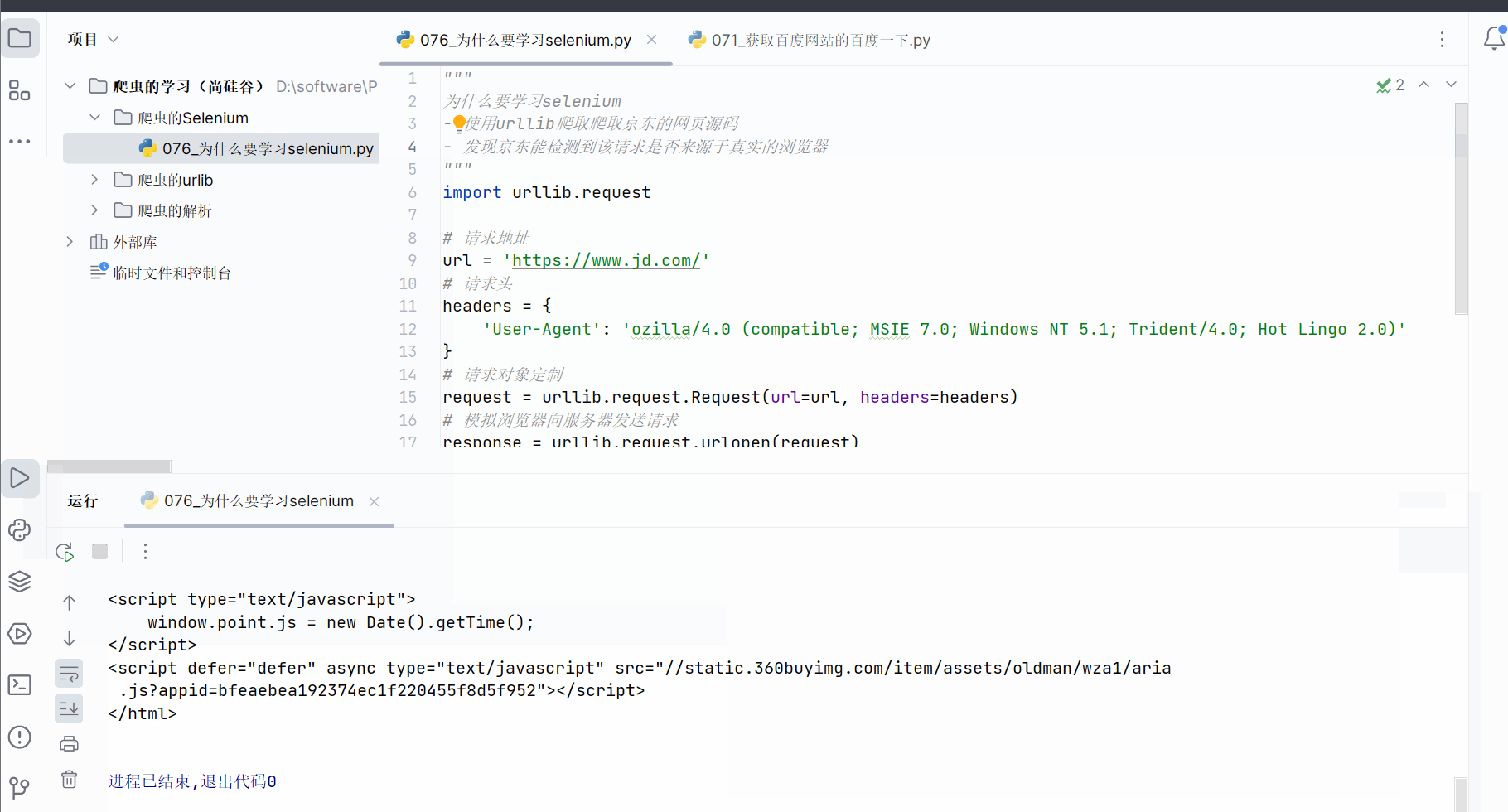
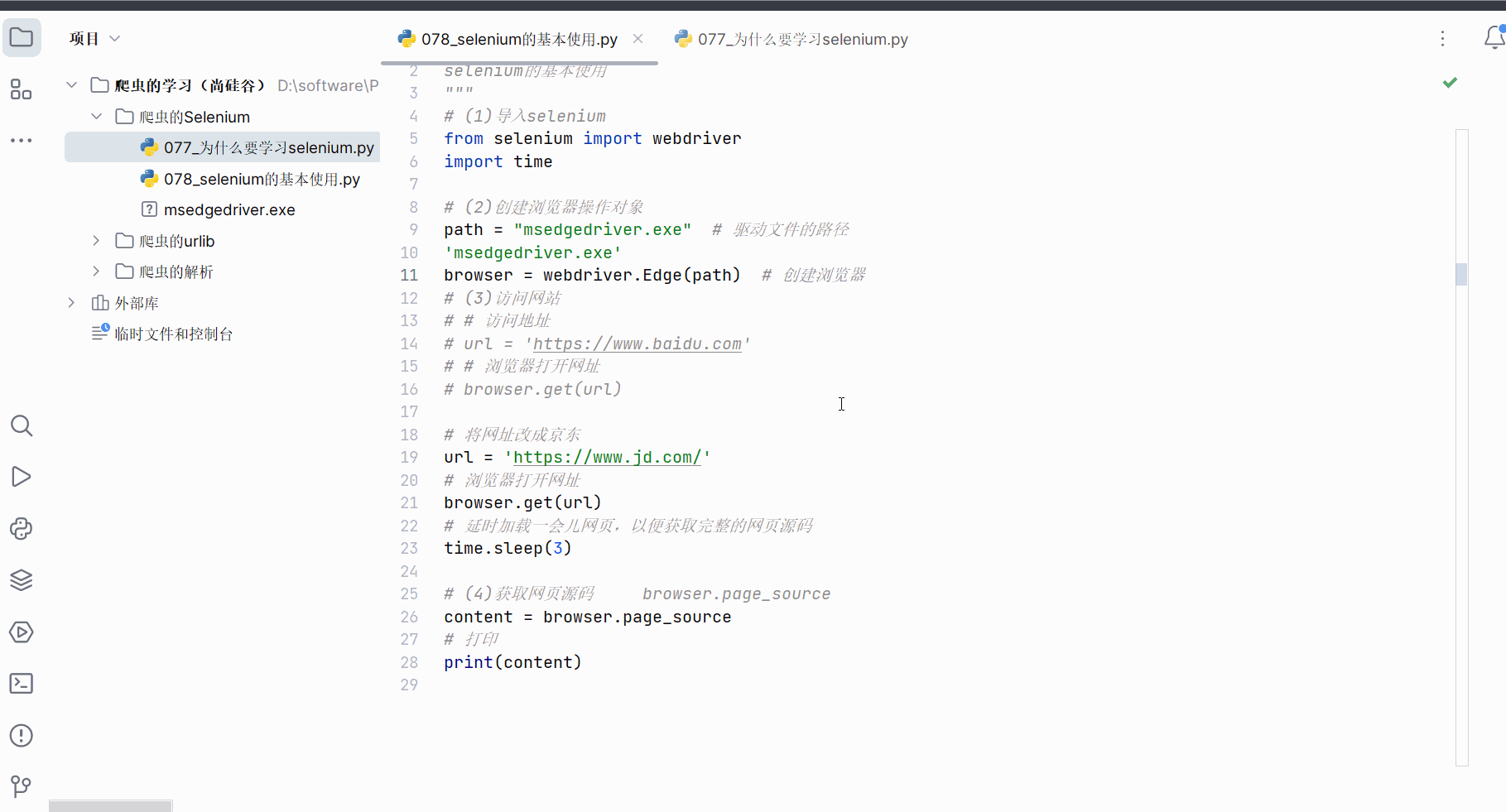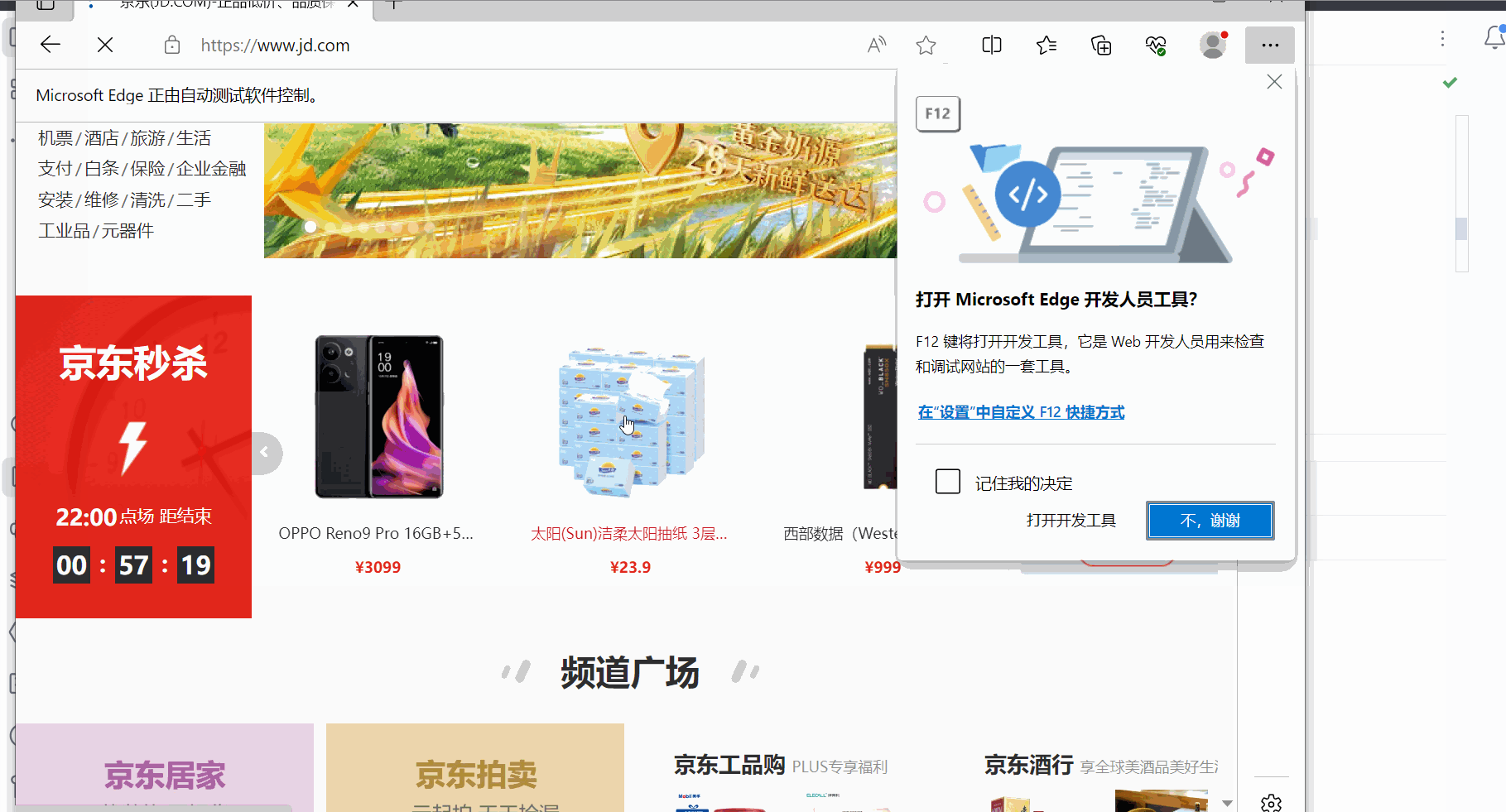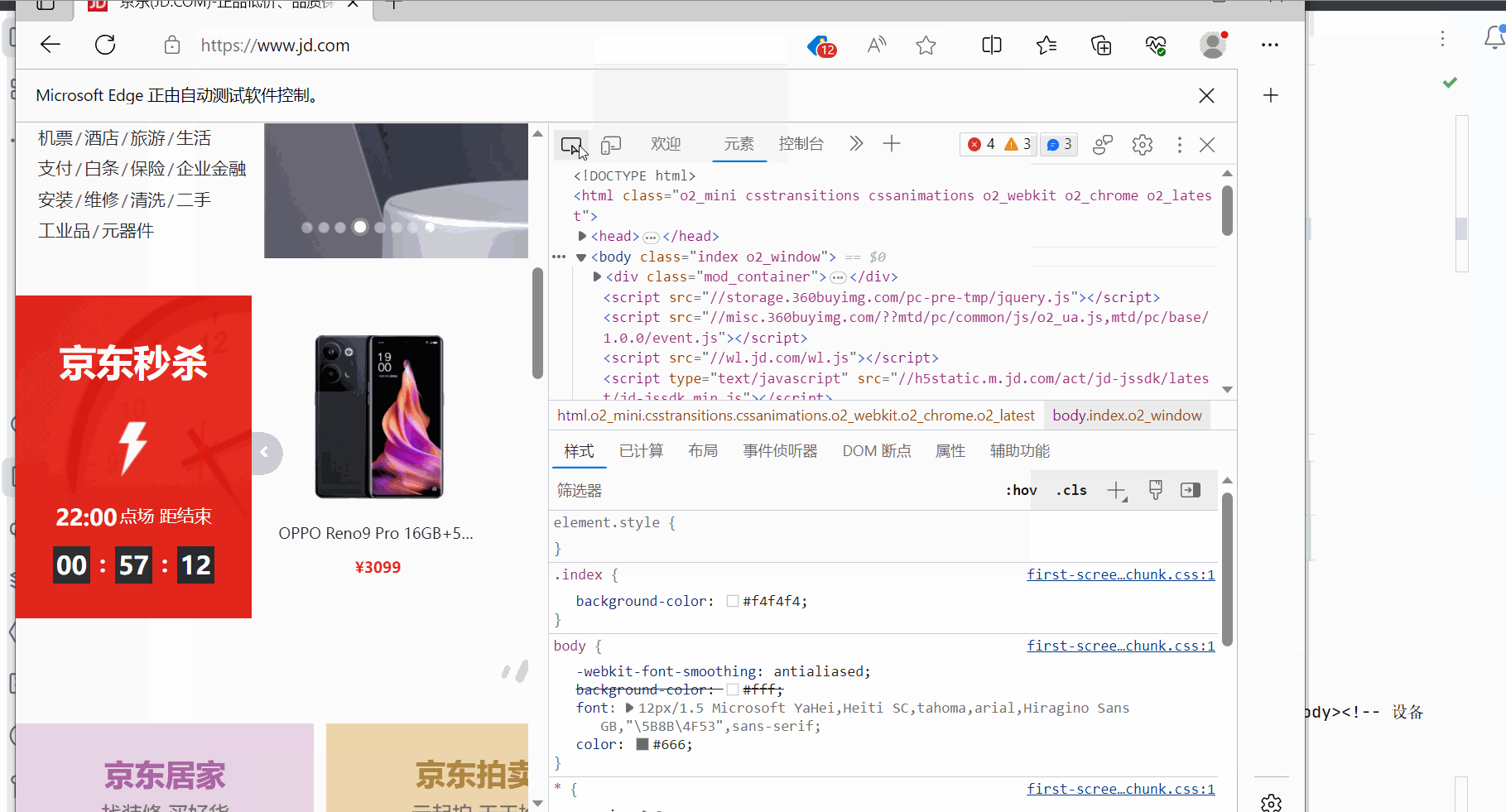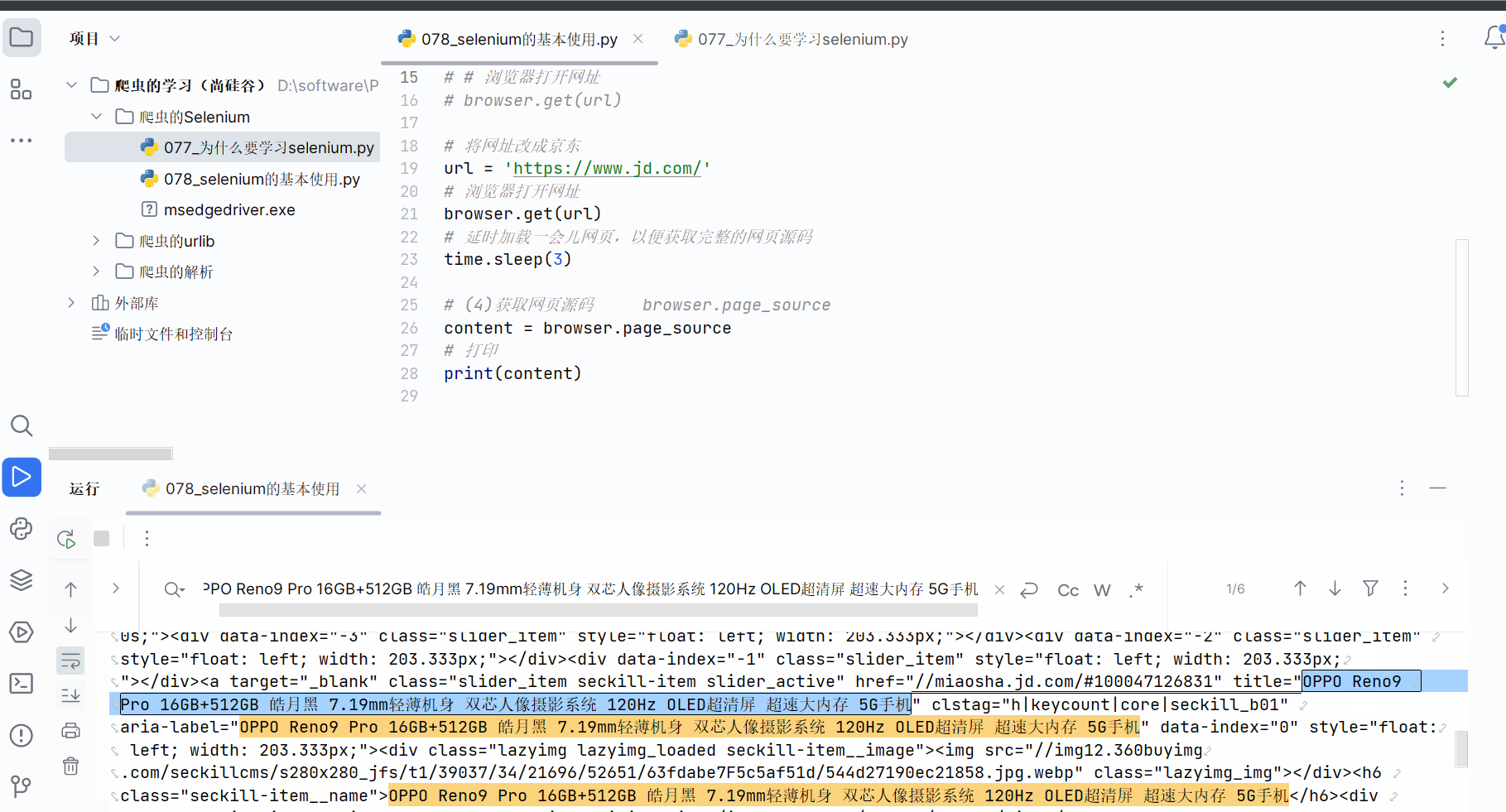
使用的urllib获取京东的网页源码,搜索秒杀中的数据,发现确实是少了秒杀的内容。因此,下一节将学习并说明selenium能驱动真实浏览器去获取数据,不会缺少内容。
"""
为什么要学习selenium
- 使用urllib爬取爬取京东的网页源码
- 发现京东能检测到该请求是否来源于真实的浏览器
"""
import urllib.request
# 请求地址
url = 'https://www.jd.com/'
# 请求头
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Tri-dent/4.0; Hot Lingo 2.0)'
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 读取网页源码
content = response.read().decode('UTF-8')
# 打印
print(content)
2. selenium的基本使用
(1)如何安装selenium

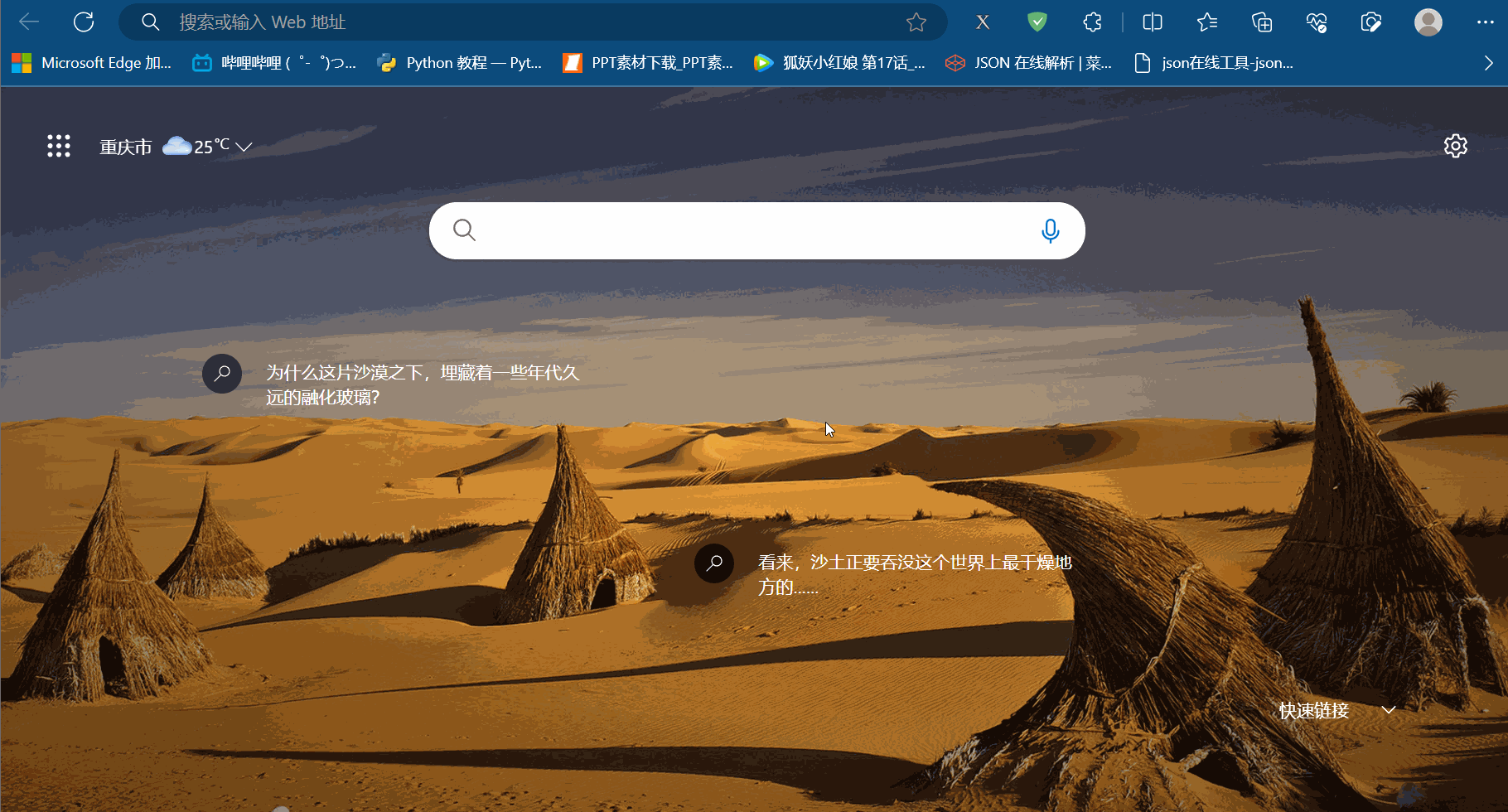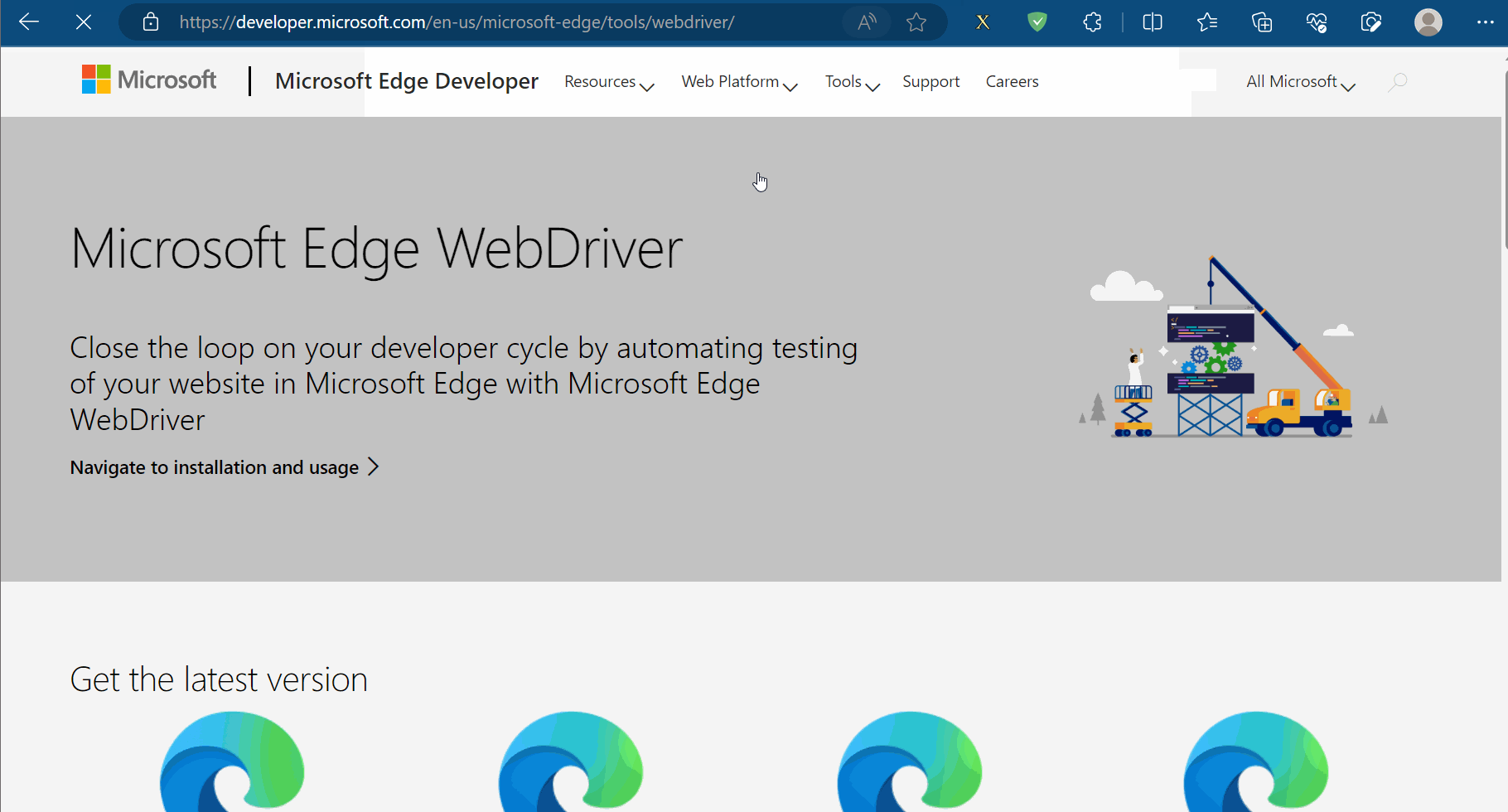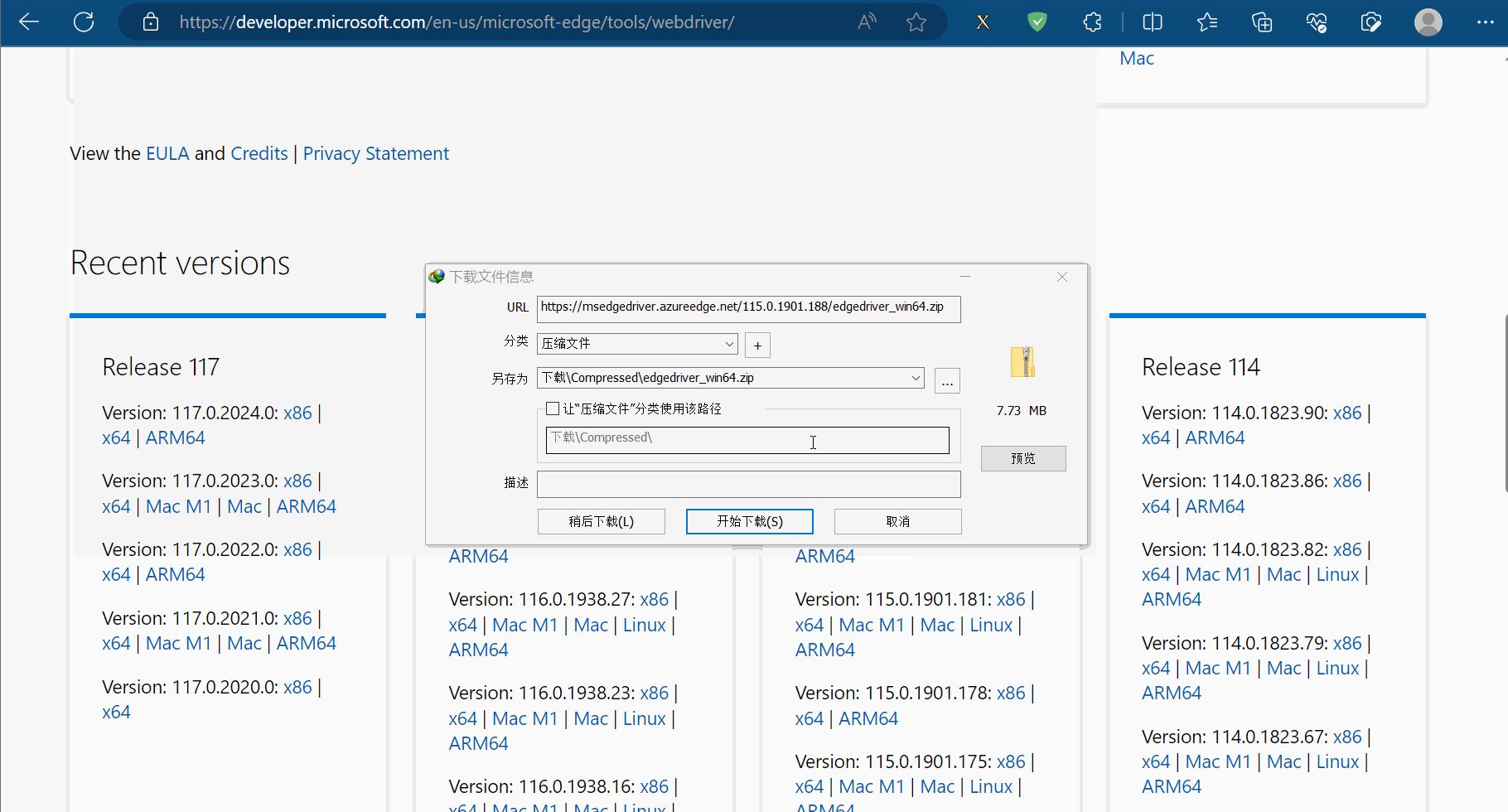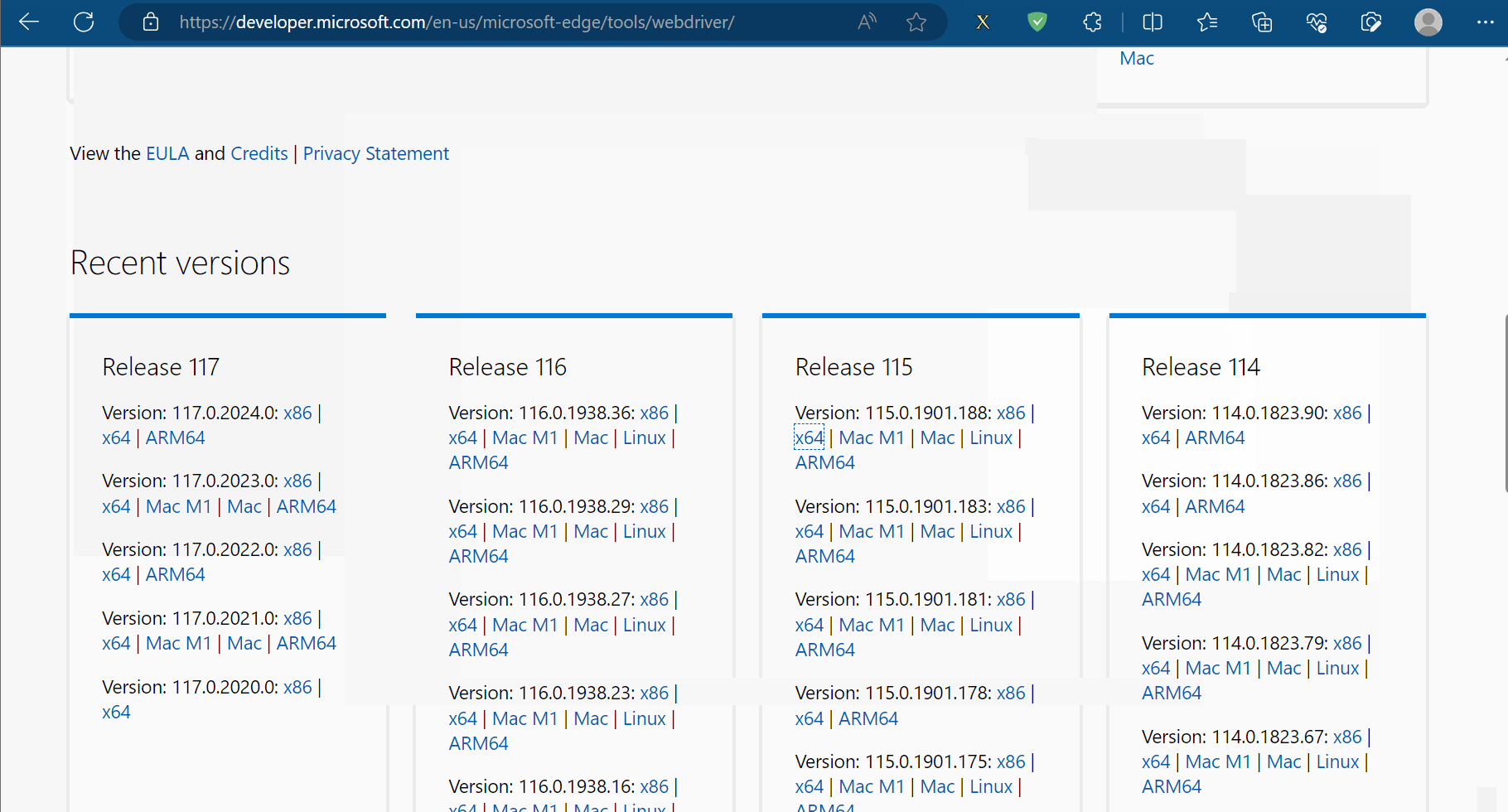
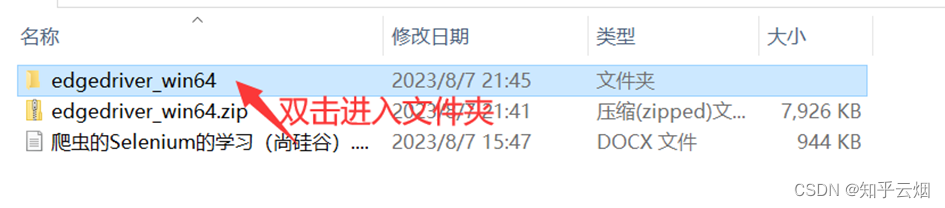
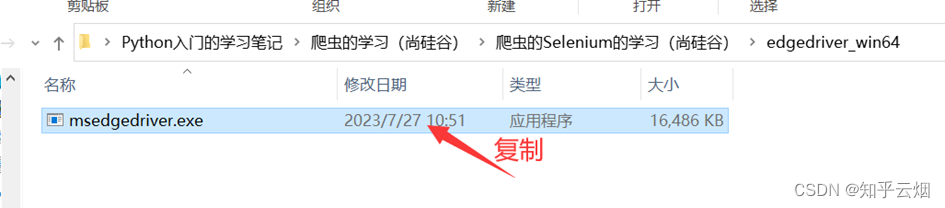
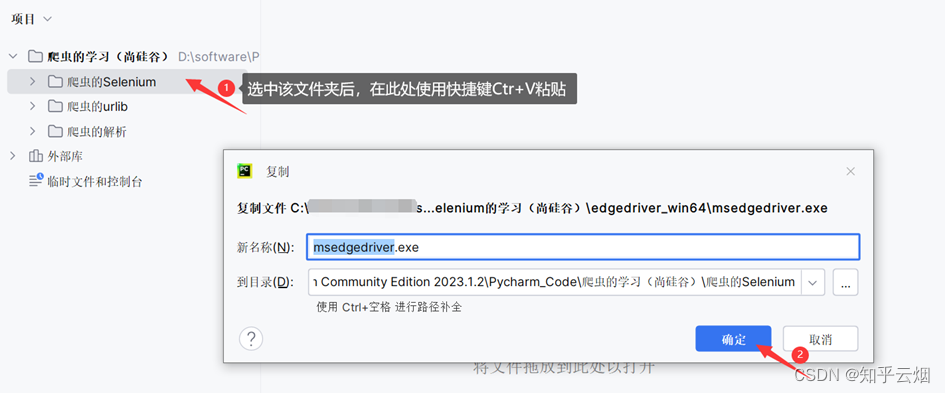
安装具体步骤如下:①准备需要的浏览器驱动,本人使用的是Edge浏览器,故需要准备和浏览器相同版本的驱动,具体为:先查看浏览器的版本号,再去“https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/”中下载一个版本号相同的浏览器驱动。然后对下载的文件进行解压,再将其中的exe文件复制到文件夹“爬虫的Selenium”中。

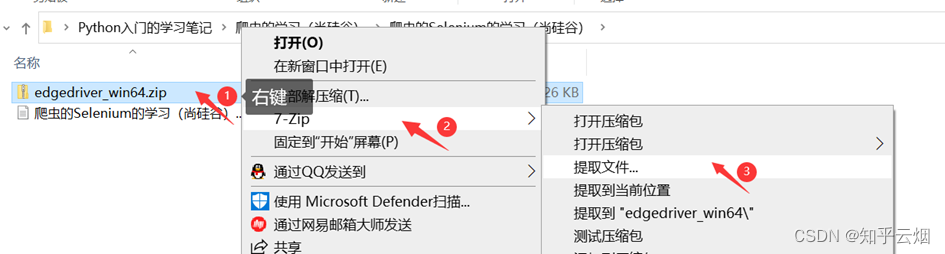
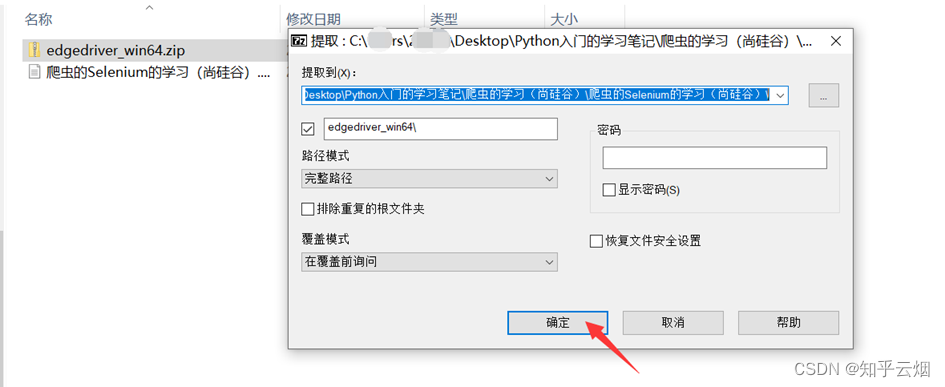

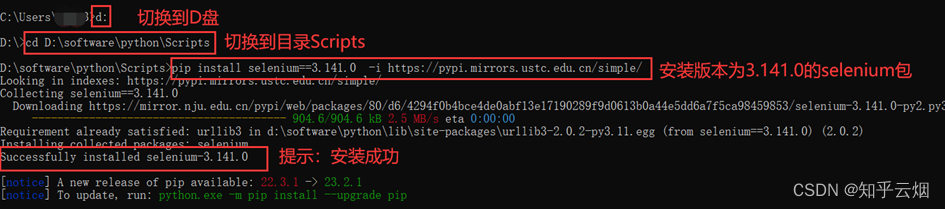
②安装第三方包selenium,具体为:打开命令提示符,将当前目录切换到文件夹Scripts中,使用安装指令“pip install selenium==3.141.0 -i https://pypi.mirrors.ustc.edu.cn/simple/”后等待一会儿即可安装完成(注意:此处下载selenium时请指定老版本,即3.141.0,不然后续操作可能会出现问题)。


(2)selenium的使用步骤

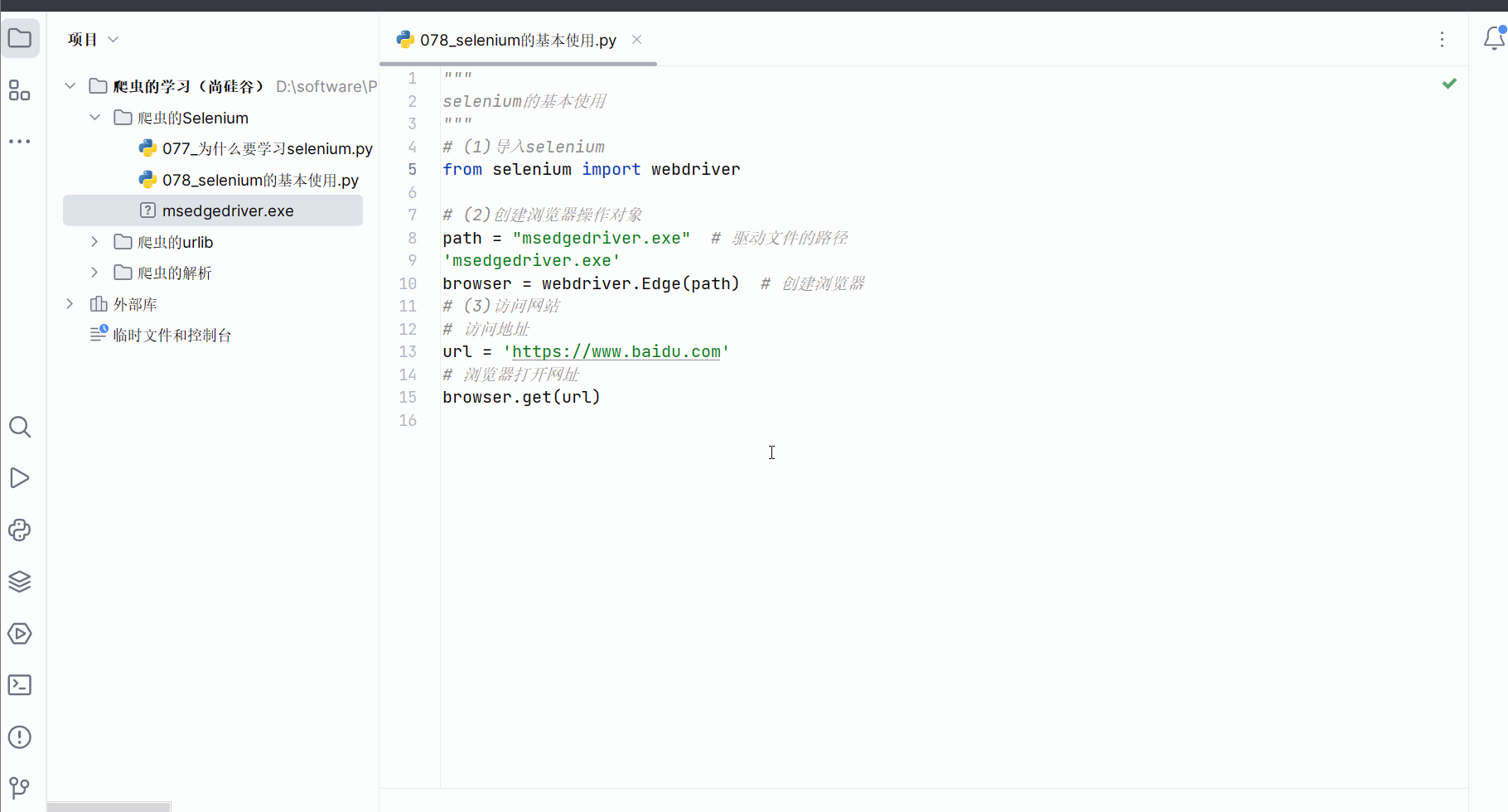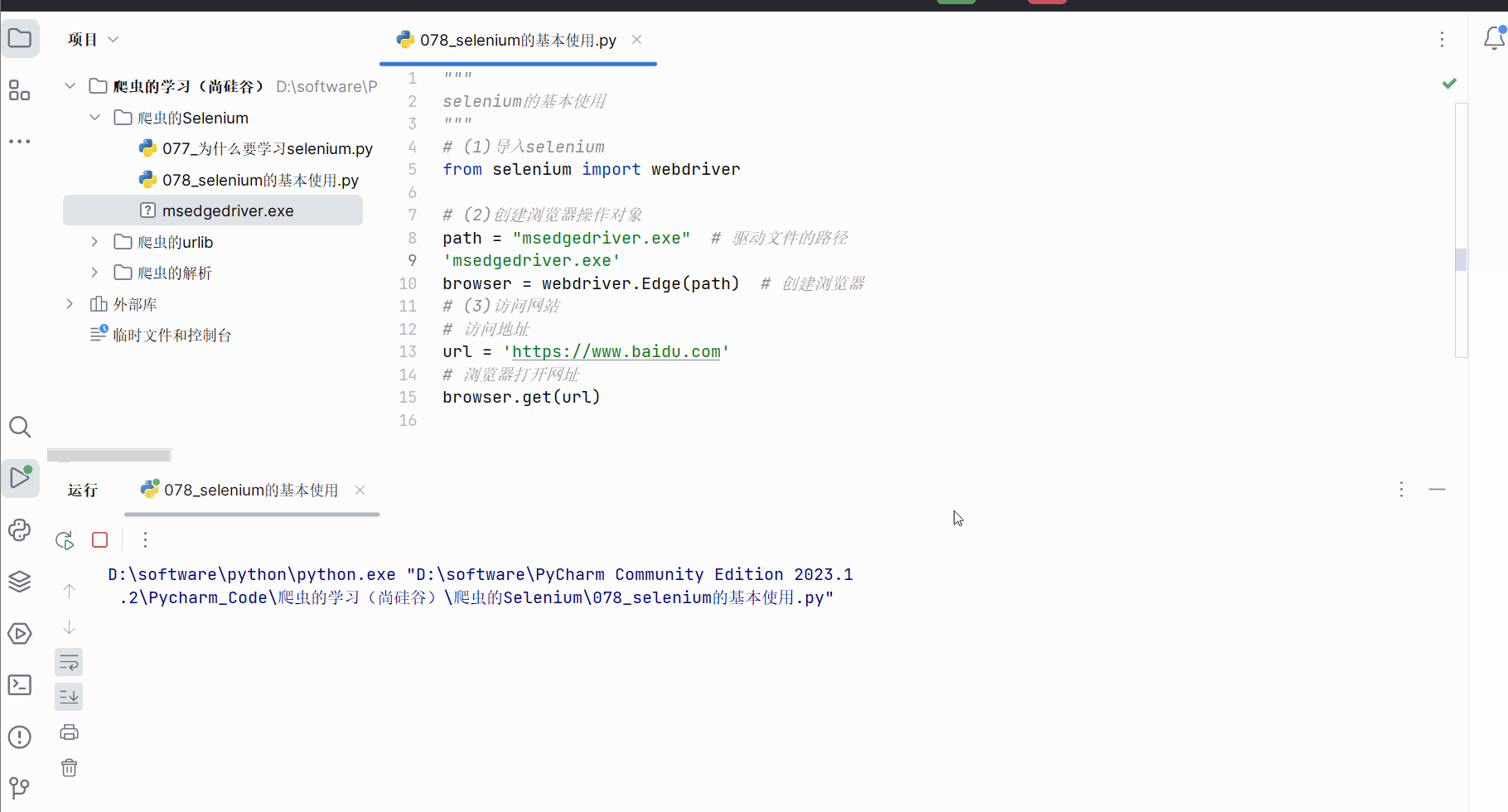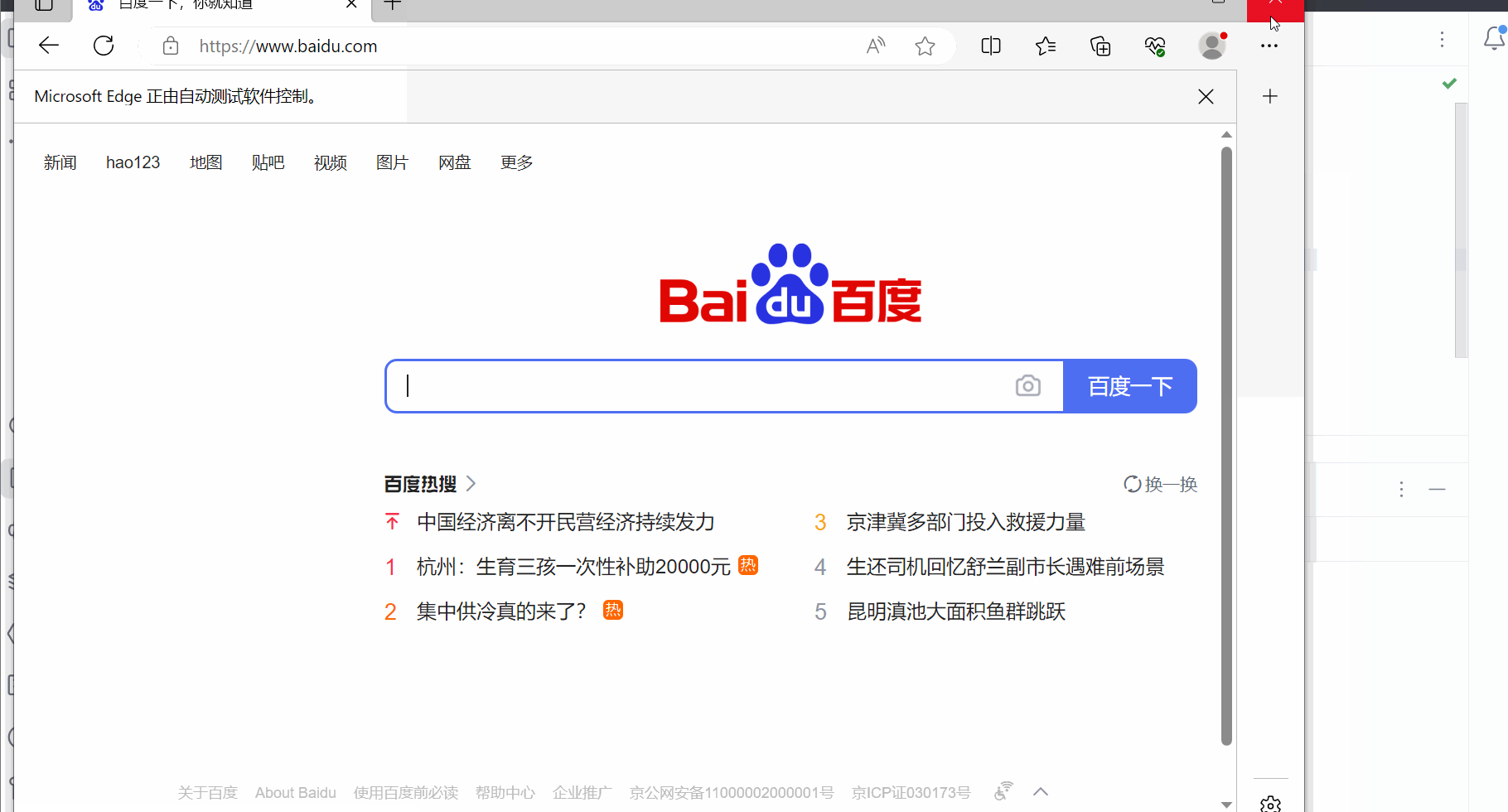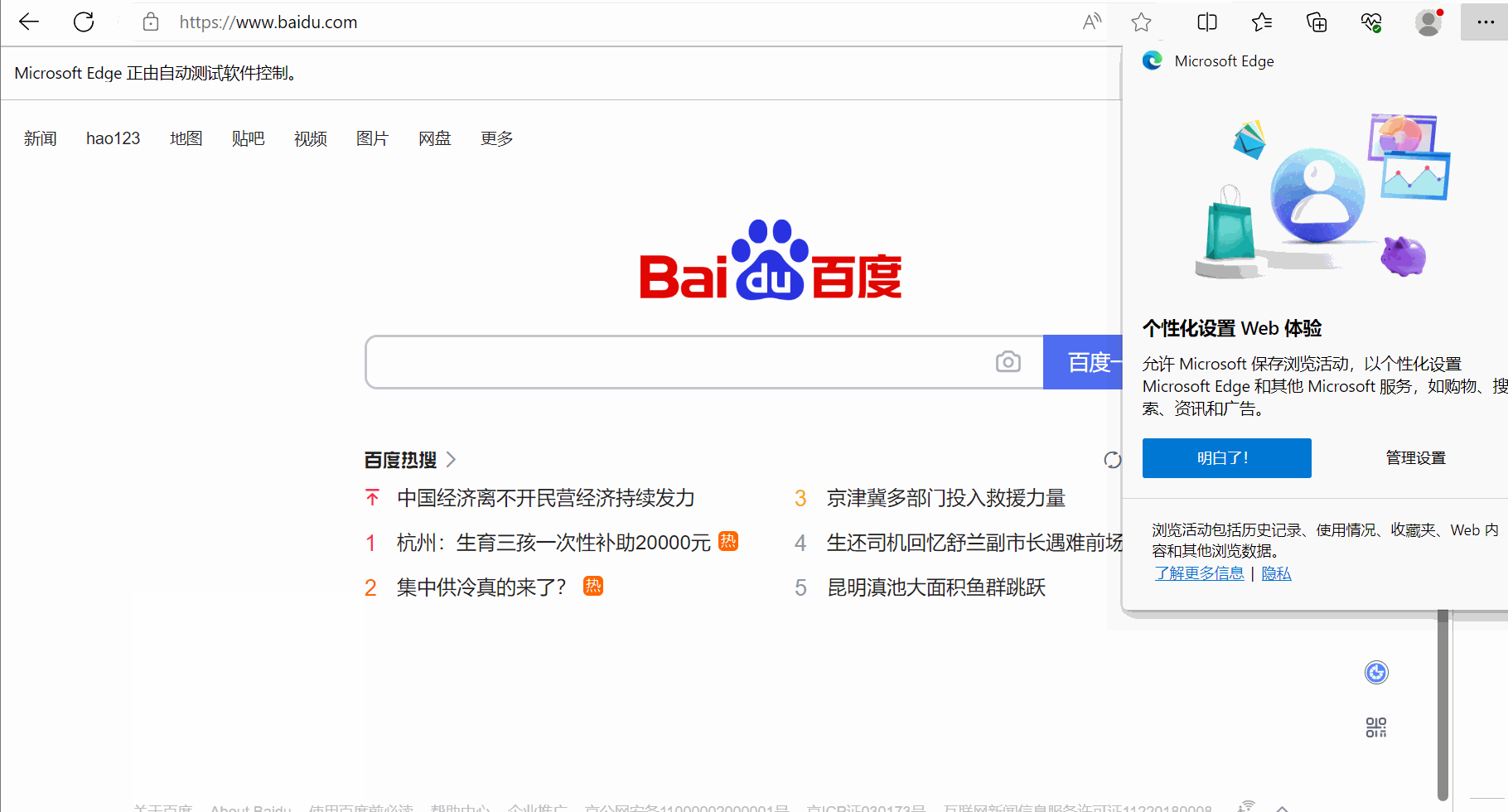
(3)代码的演示(含初次运行时报错的解决办法、selenium获取网页源码的代码)
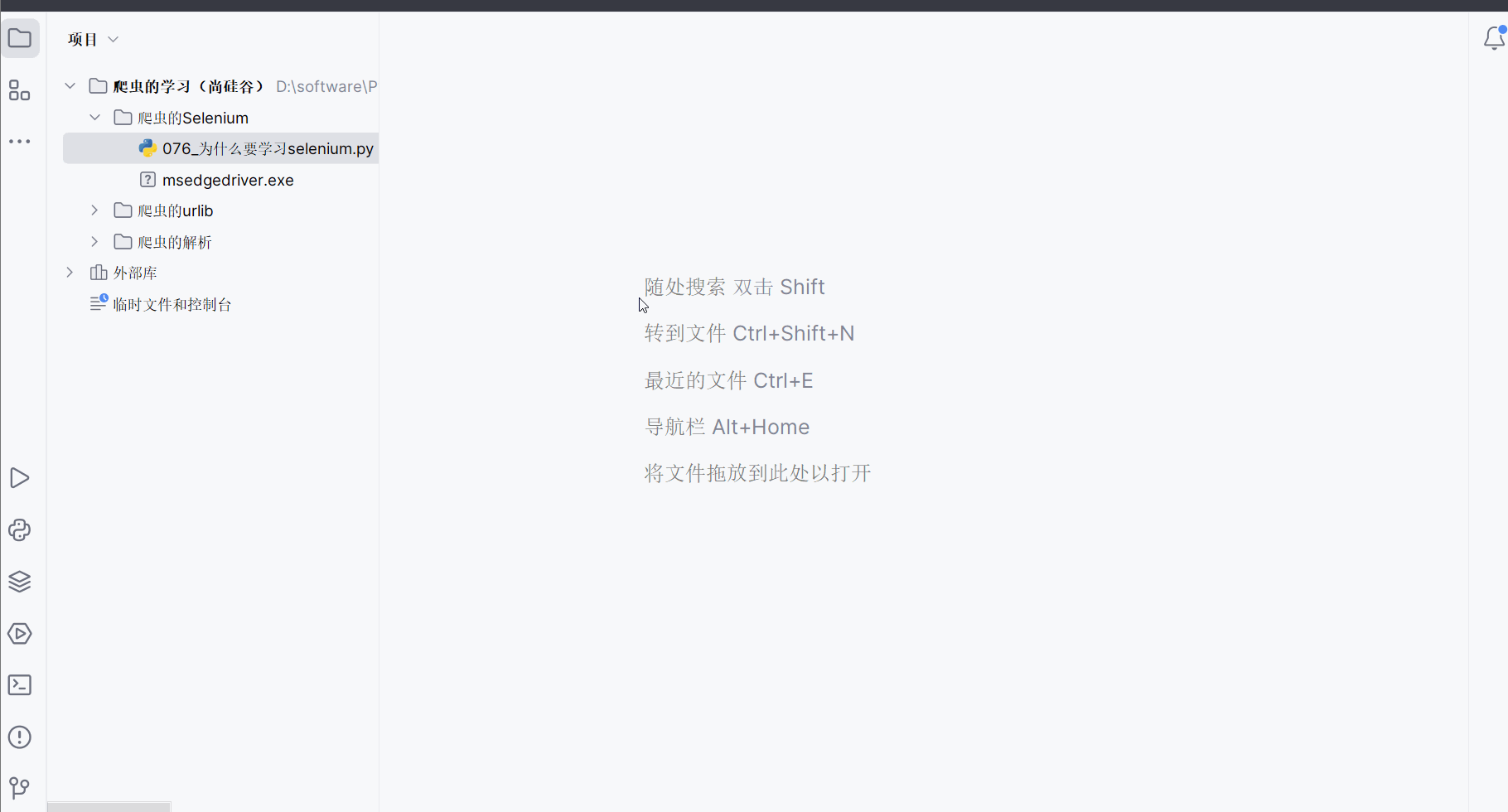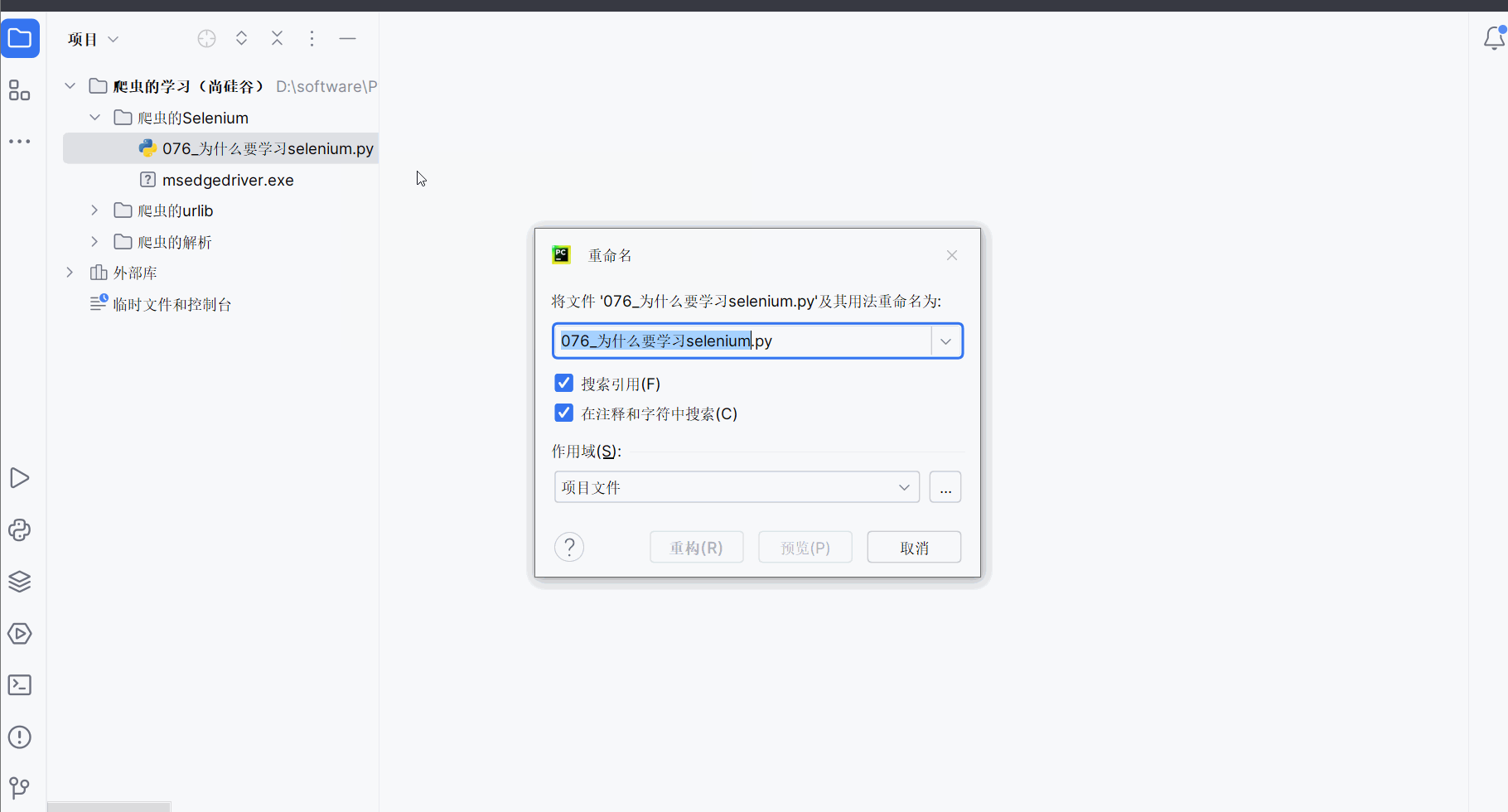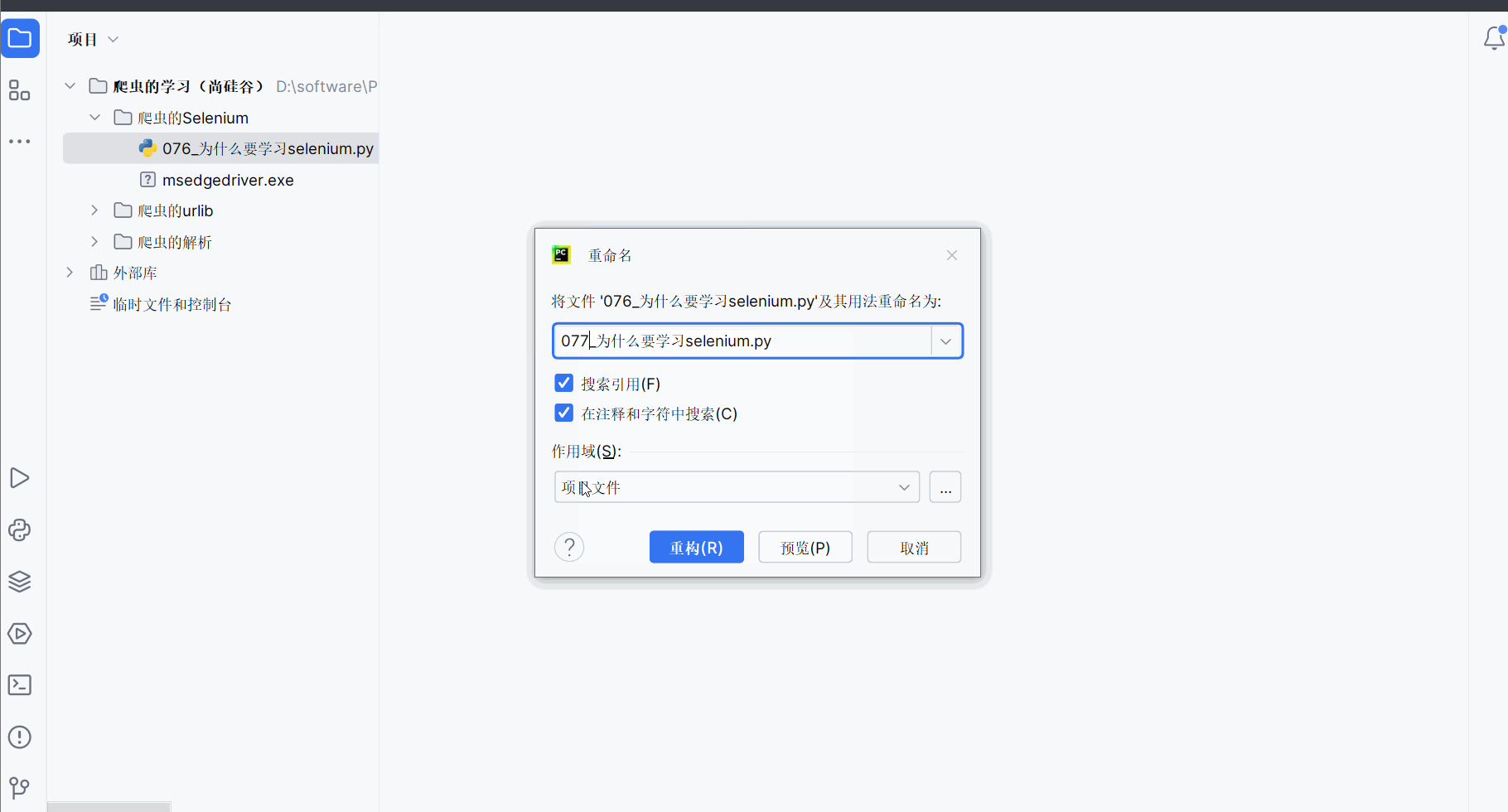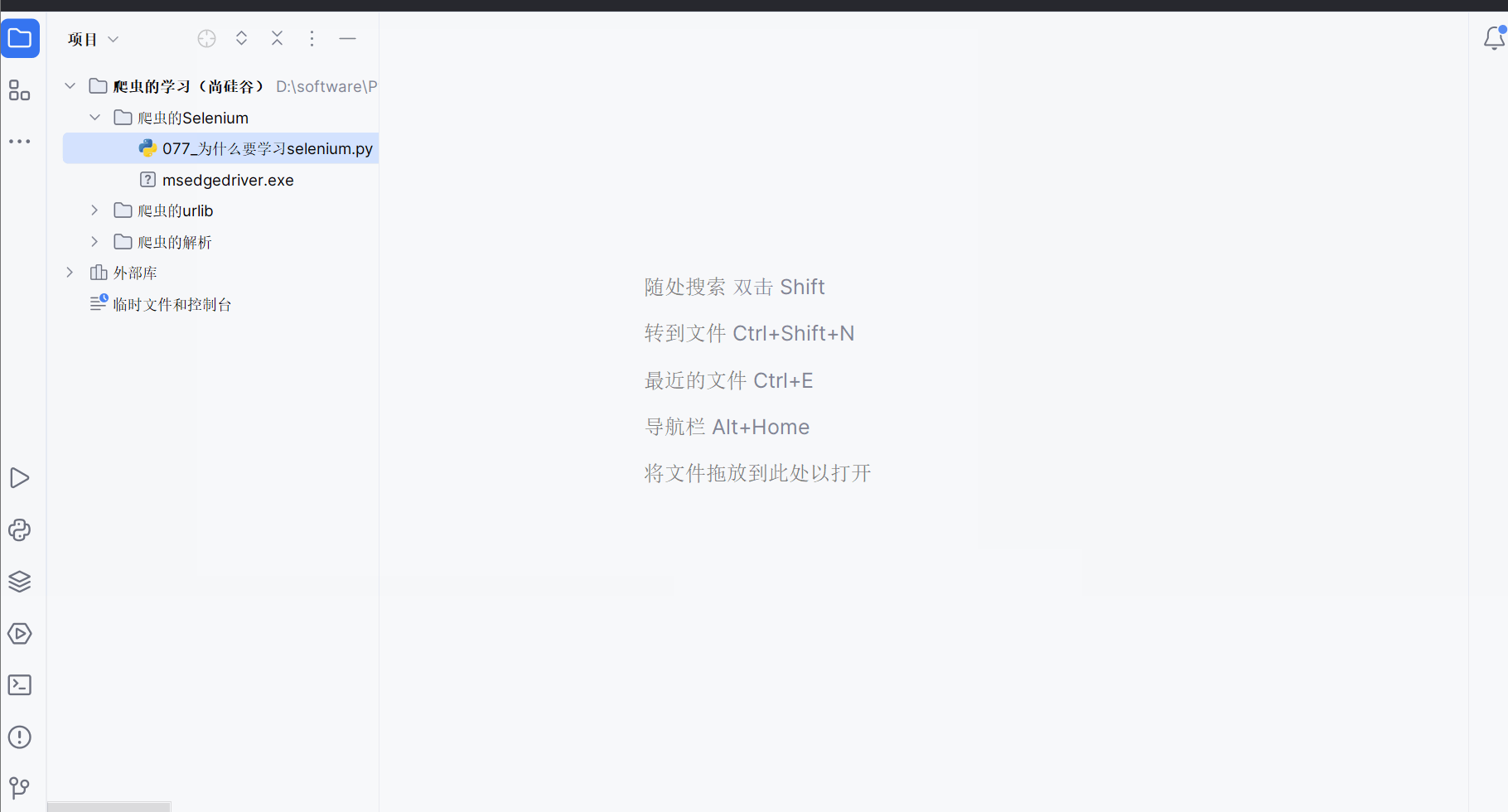
尴尬,之前创的文件“076_为什么要学习selenium.py”的编号写错了,应在PyCharm中选中该文件后,使用重命名快捷键Shift+F6,然后改为“077_为什么要学习selenium.py”。
创建文件“078_selenium的基本使用.py”。
如下编写代码,运行后报错。查询半天后(“https://blog.csdn.net/weixin_60535956/article/details/131660133”),发现这是由于selenium版本和urllib3版本不兼容导致的。
"""
selenium的基本使用
"""
# (1)导入selenium
from selenium import webdriver
# (2)创建浏览器操作对象
path = "msedgedriver.exe" # 驱动文件的路径
browser = webdriver.Edge(path) # 创建浏览器
# (3)访问网站
# 访问地址
url = 'https://www.baidu.com'
# 浏览器打开网址
browser.get(url)
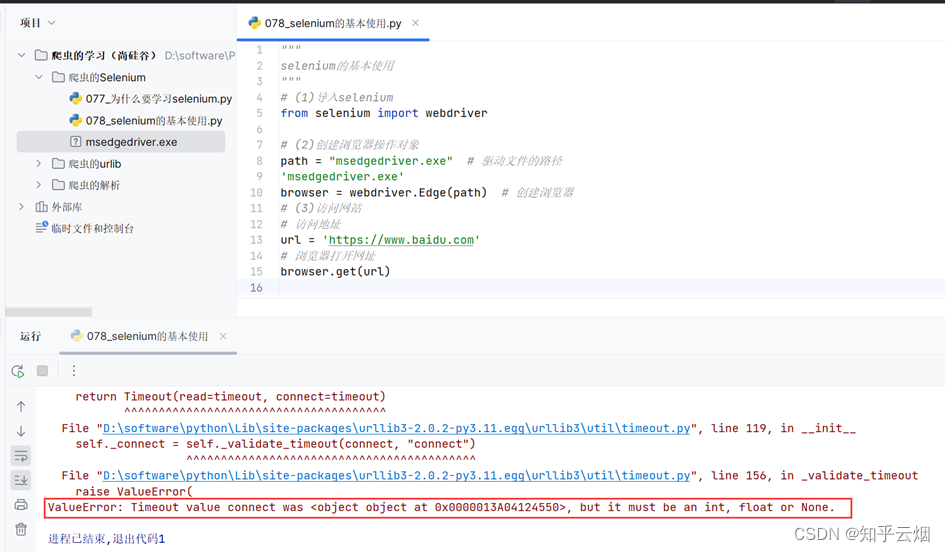
然后,如下图,去修改urllib3的版本为1.26.2,再次运行就好使了。
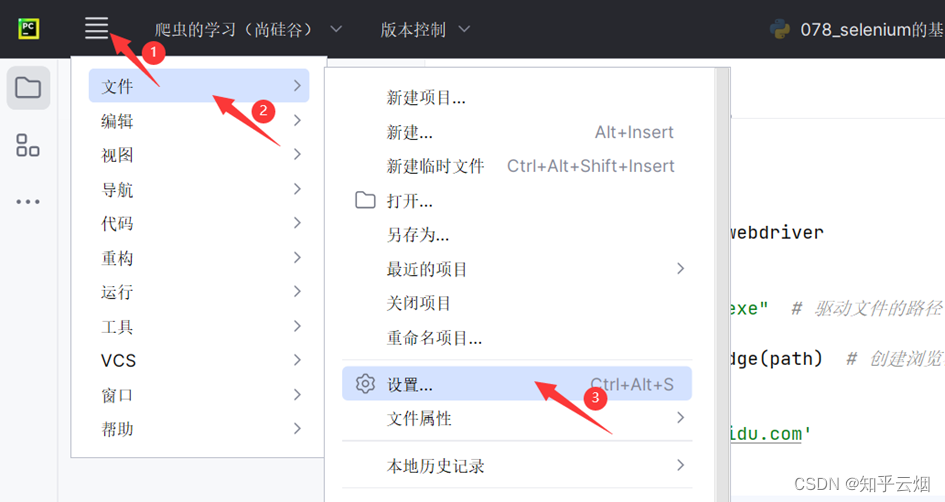
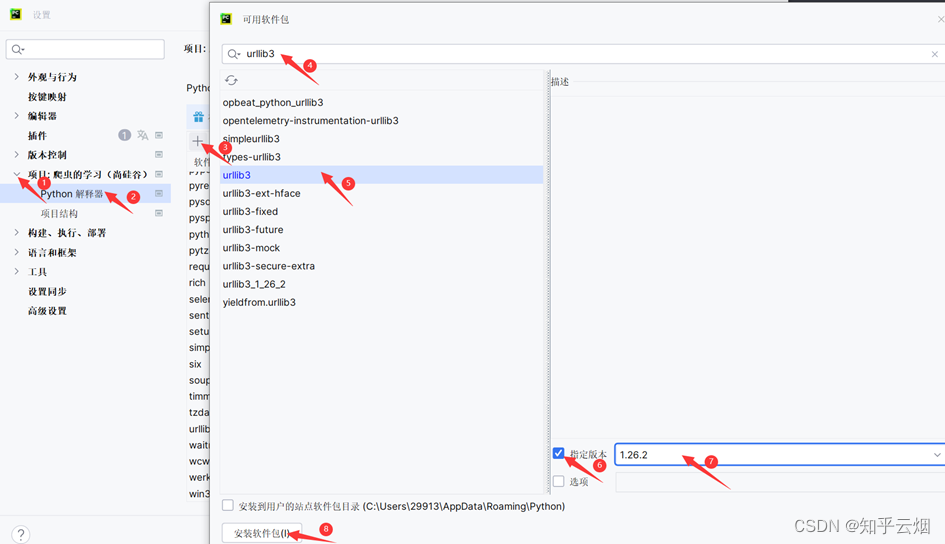
等待一会,安装完成。

之后,就可以正常运行程序了。
如下继续编写代码,发现selenium获取的京东的网页源码就有秒杀的数据。可见,由于selenium是直接驱动真实浏览器的,不会导致数据的损失。(注:如果还没有获取到秒杀数据,需要加点延时,即代码中的“time.sleep(3)”,然后在网页打开时且在延时时间内滑动浏览器将京东的秒杀数据加载出来)
"""
selenium的基本使用
"""
# (1)导入selenium
from selenium import webdriver
import time
# (2)创建浏览器操作对象
path = "msedgedriver.exe" # 驱动文件的路径
browser = webdriver.Edge(path) # 创建浏览器
# (3)访问网站
# # 访问地址
# url = 'https://www.baidu.com'
# # 浏览器打开网址
# browser.get(url)
# 将网址改成京东
url = 'https://www.jd.com/'
# 浏览器打开网址
browser.get(url)
# 延时加载一会儿网页,以便获取完整的网页源码
time.sleep(3)
# (4)获取网页源码 browser.page_source
content = browser.page_source
# 打印
print(content)
3.selenium的元素定位
(1)引
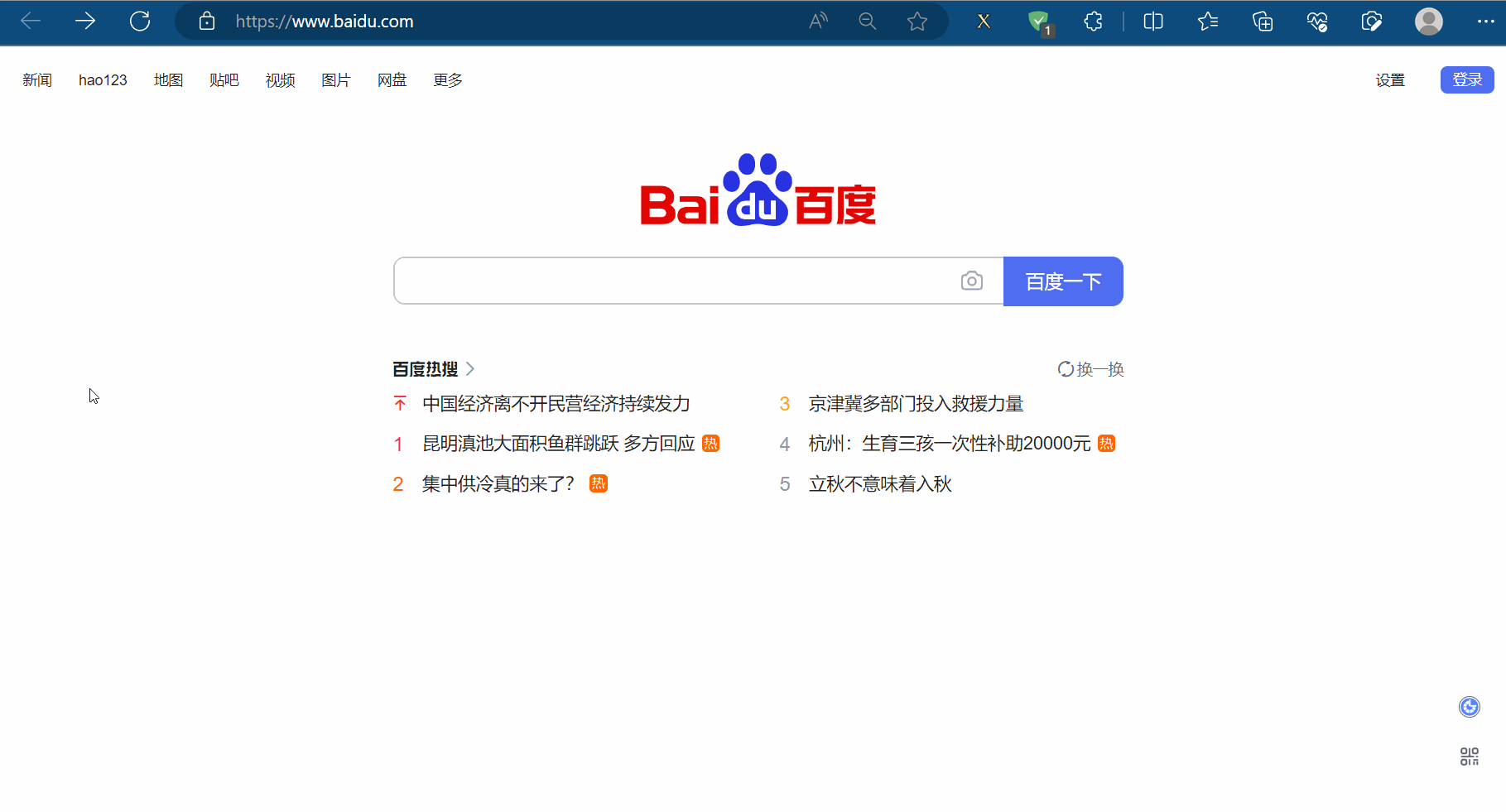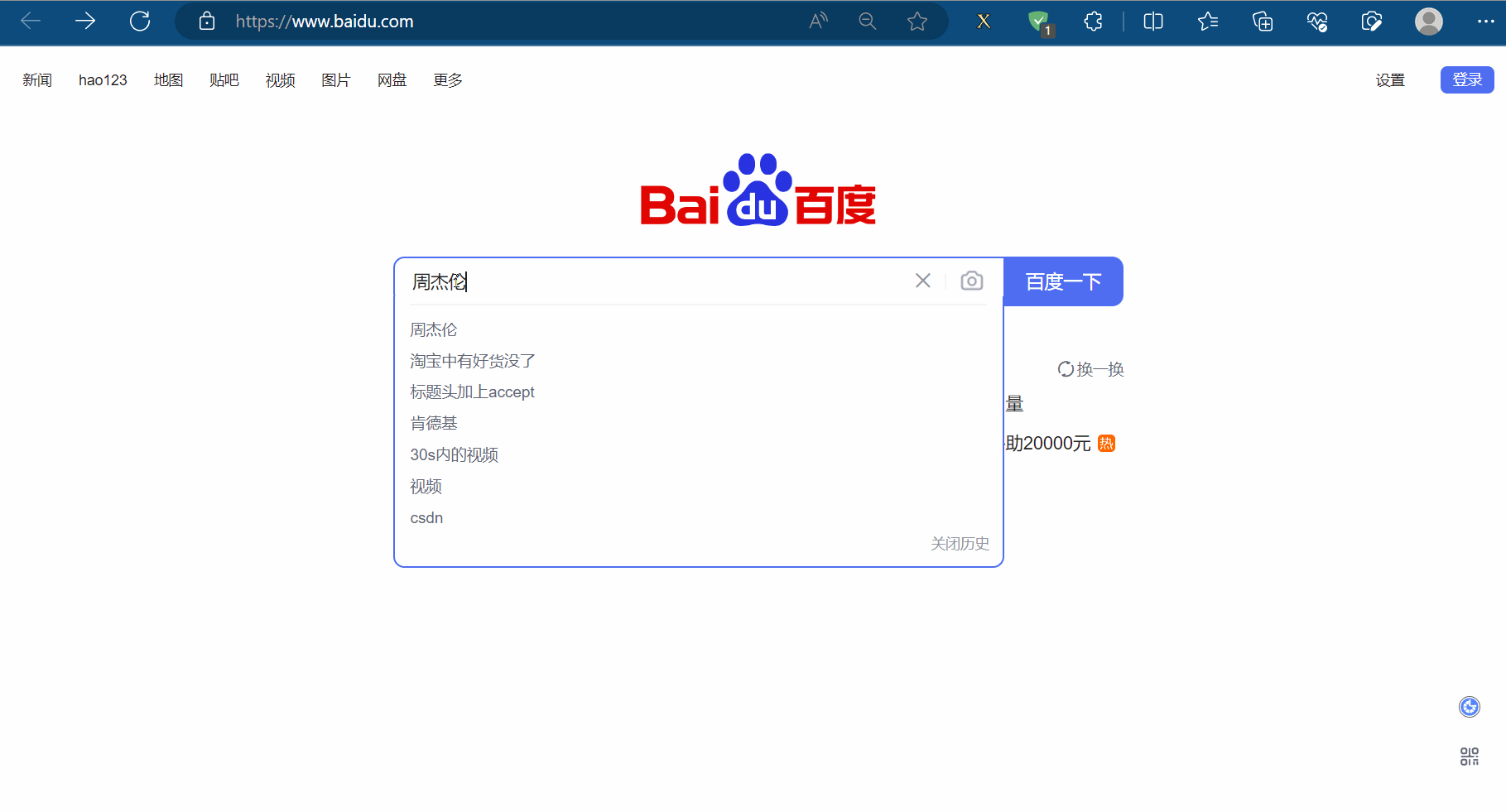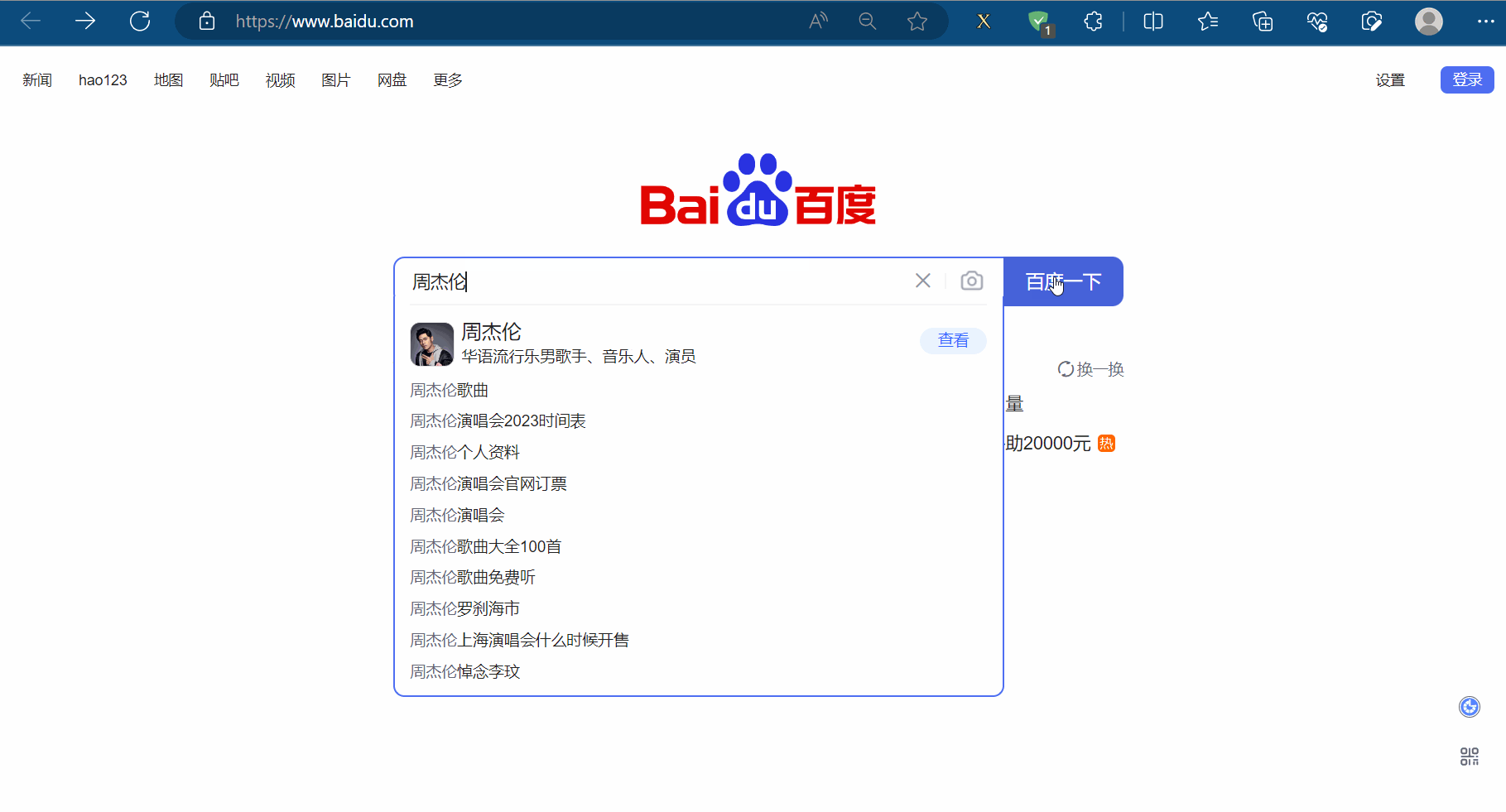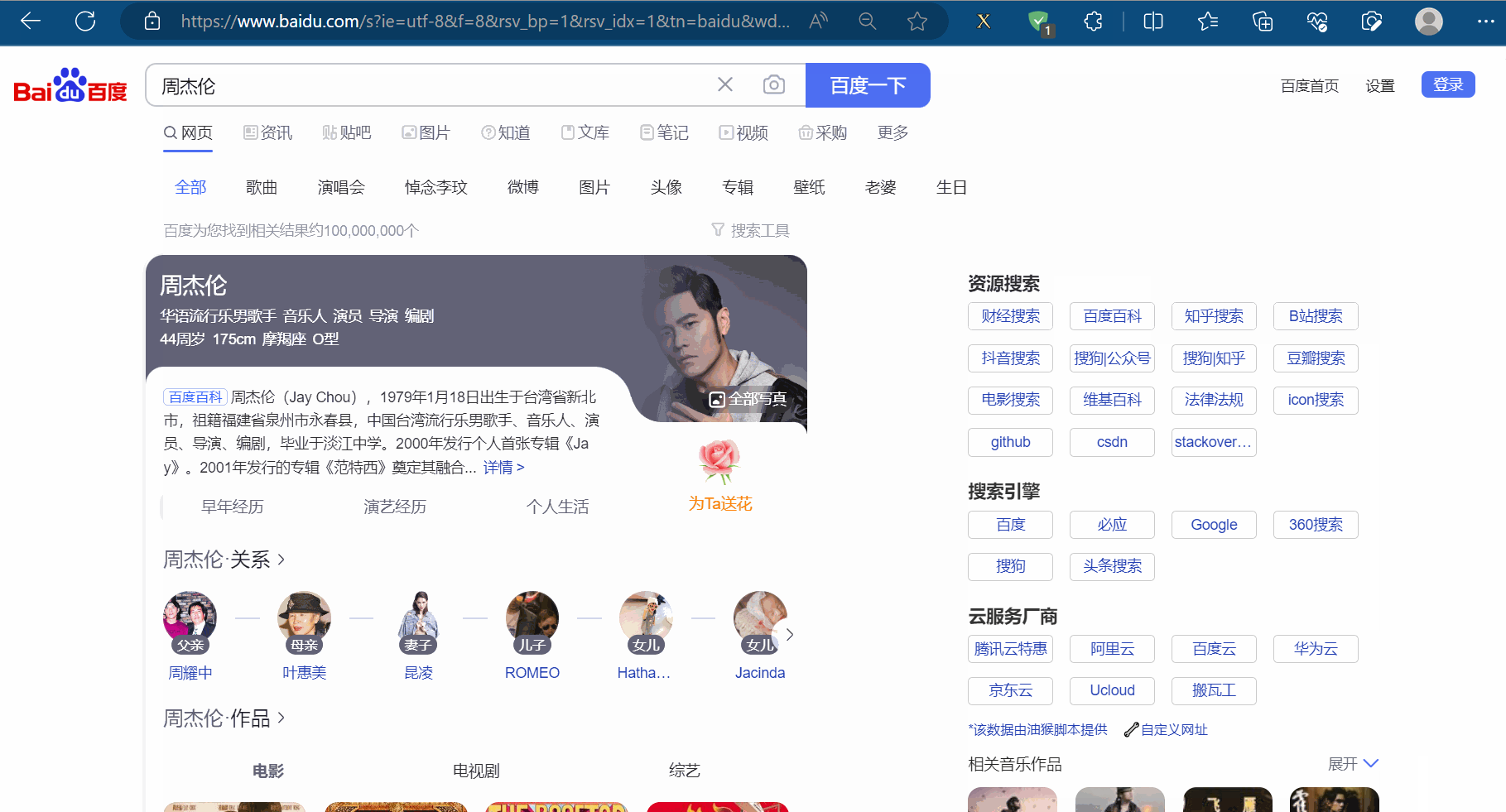
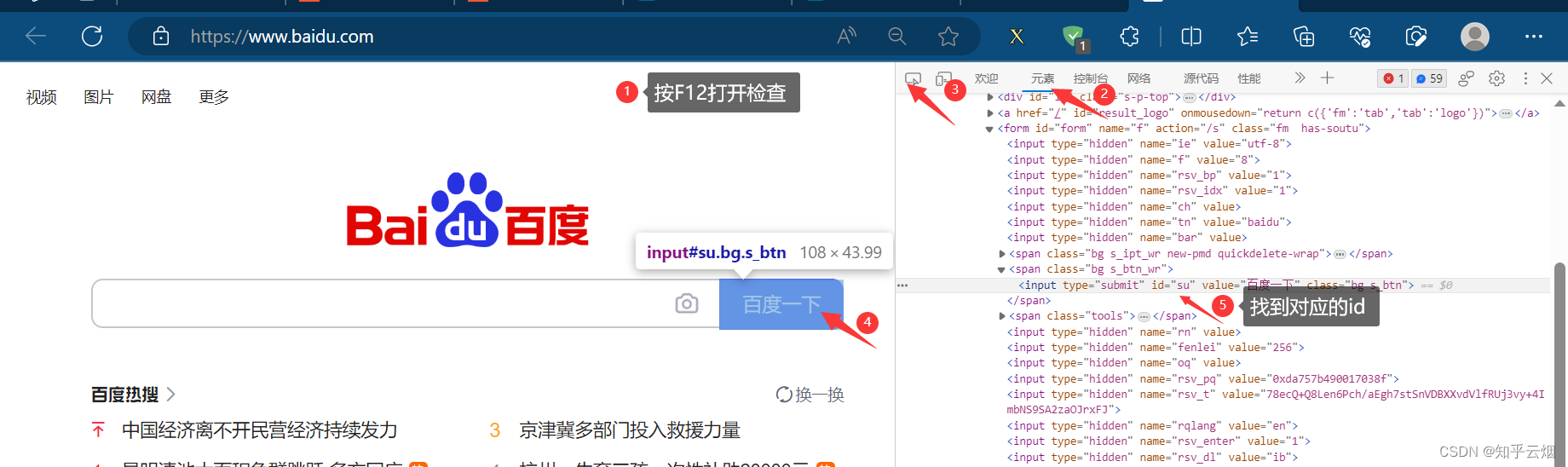
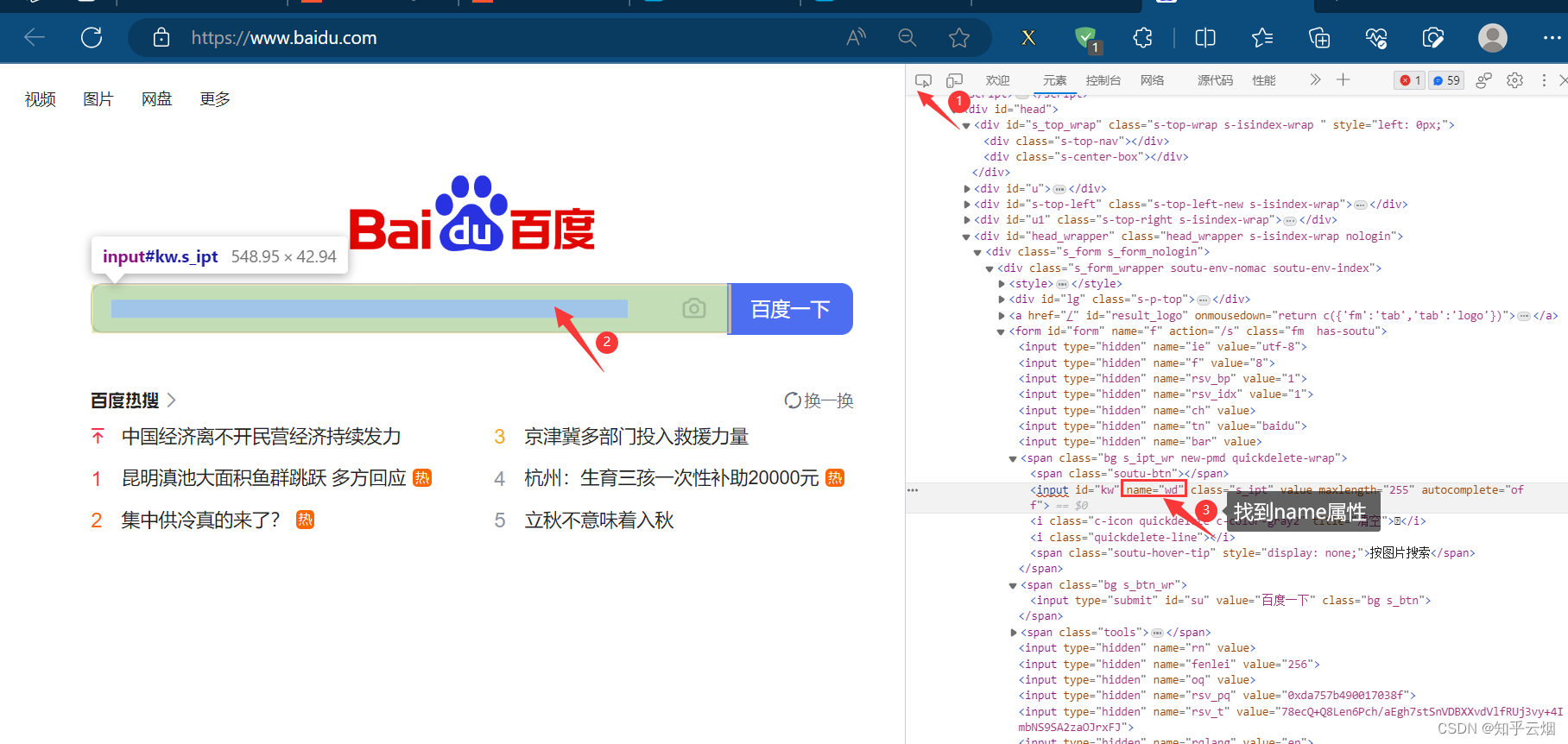
如下图所示,如果我们需要使用程序在百度(“https://www.baidu.com/”)中输入“周杰伦”,然后点击“百度一下”,会跳到一个新的页面。其中,使用程序找到“百度一下”的过程称为元素定位。
(2)元素定位的定义与方法

其实,上面的方法可以改成只记方法find_element/find_elements,这两个方法的语法相同,只是是寻找一个元素还是所有元素的差别,具体使用方法如下:
# 元素定位
# 根据id找到"百度一下"
button = browser.find_element(by='id', value='su')
print(button)
# 根据name找到搜索框
button = browser.find_element(by='name', value='wd')
print(button)
# 根据xpath路径寻找“百度一下”
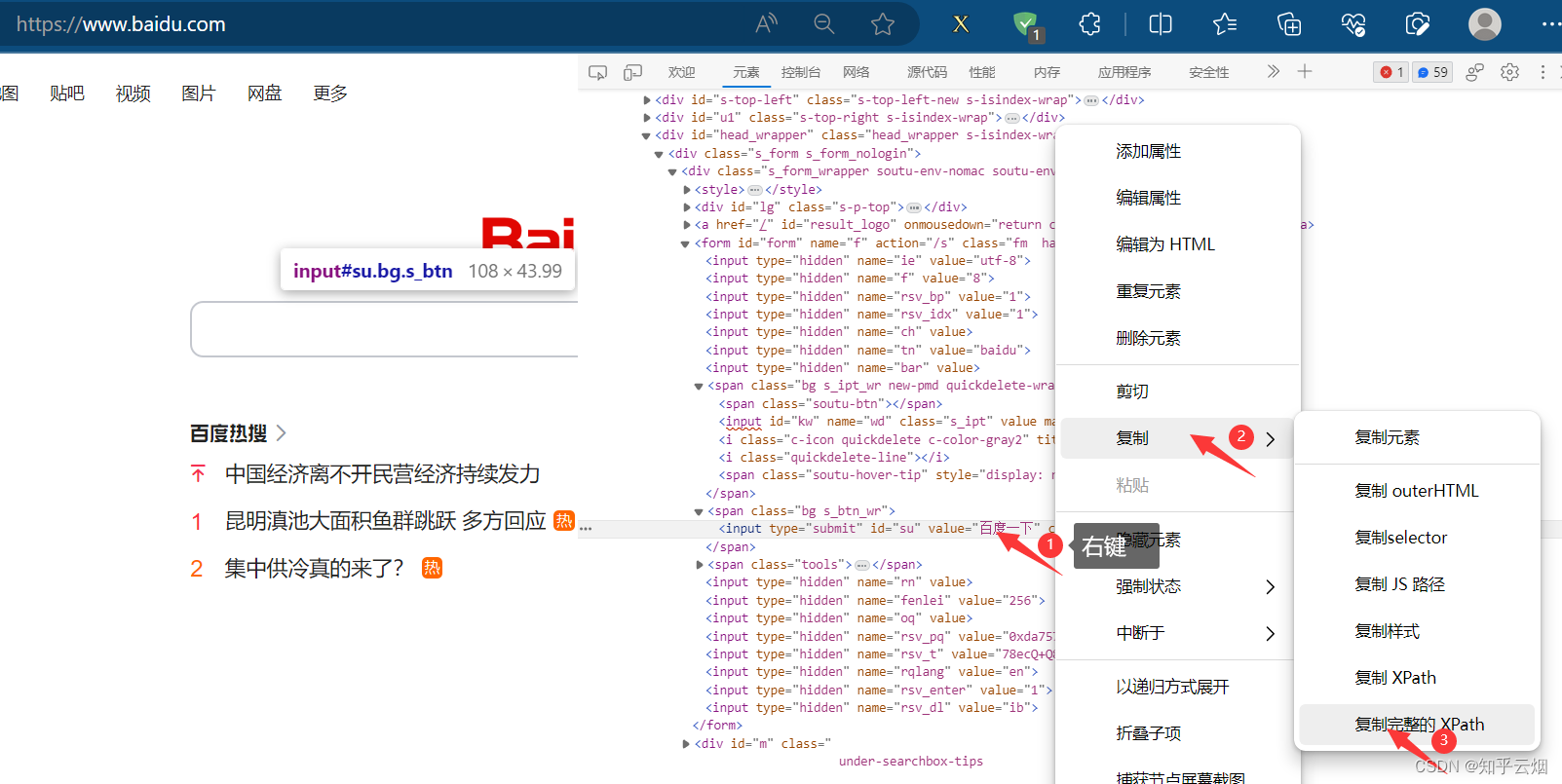
button = browser.find_element(by='xpath', val-ue='/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input')
print(button)
# 根据标签名字获取对象
button = browser.find_elements(by='tag name', value='input')
print(button)
# 使用bs4的语法来获取对象
button = browser.find_elements(by="css selector", value='#su')
print(button)
# 寻找链接文本(对应html的a标签)
button = browser.find_element(by='link text', value='地图')
print(button)
(3)代码演示
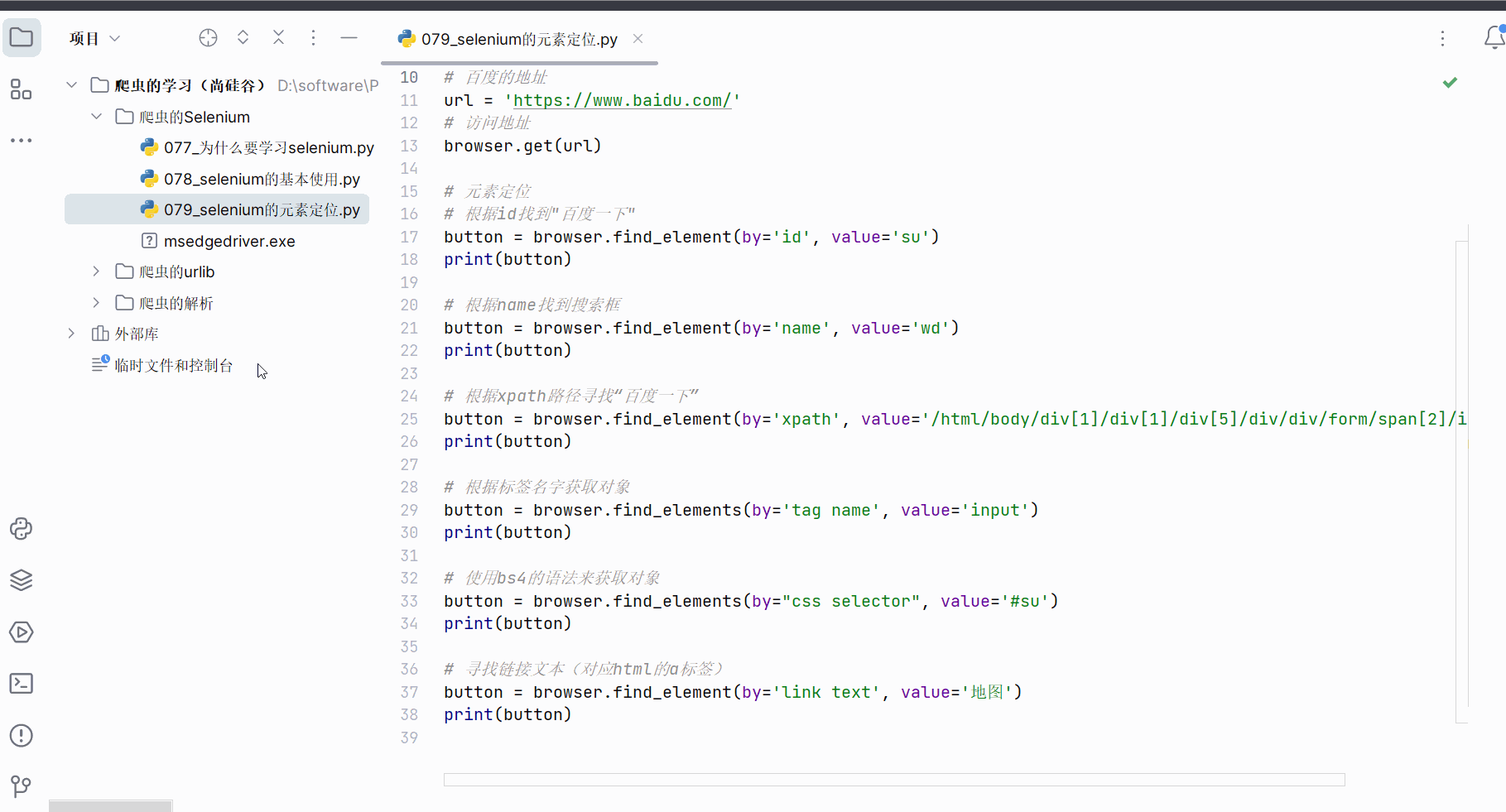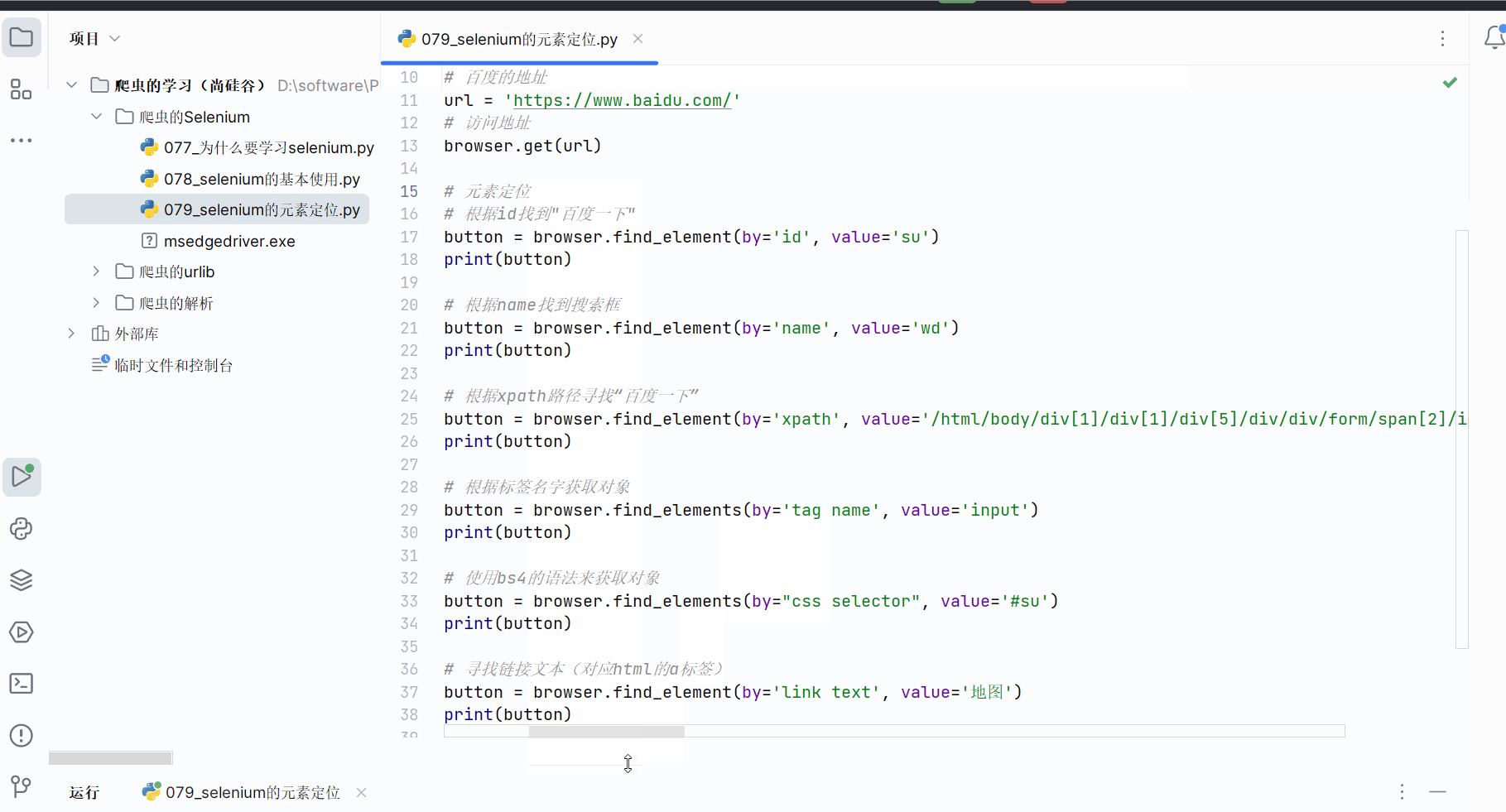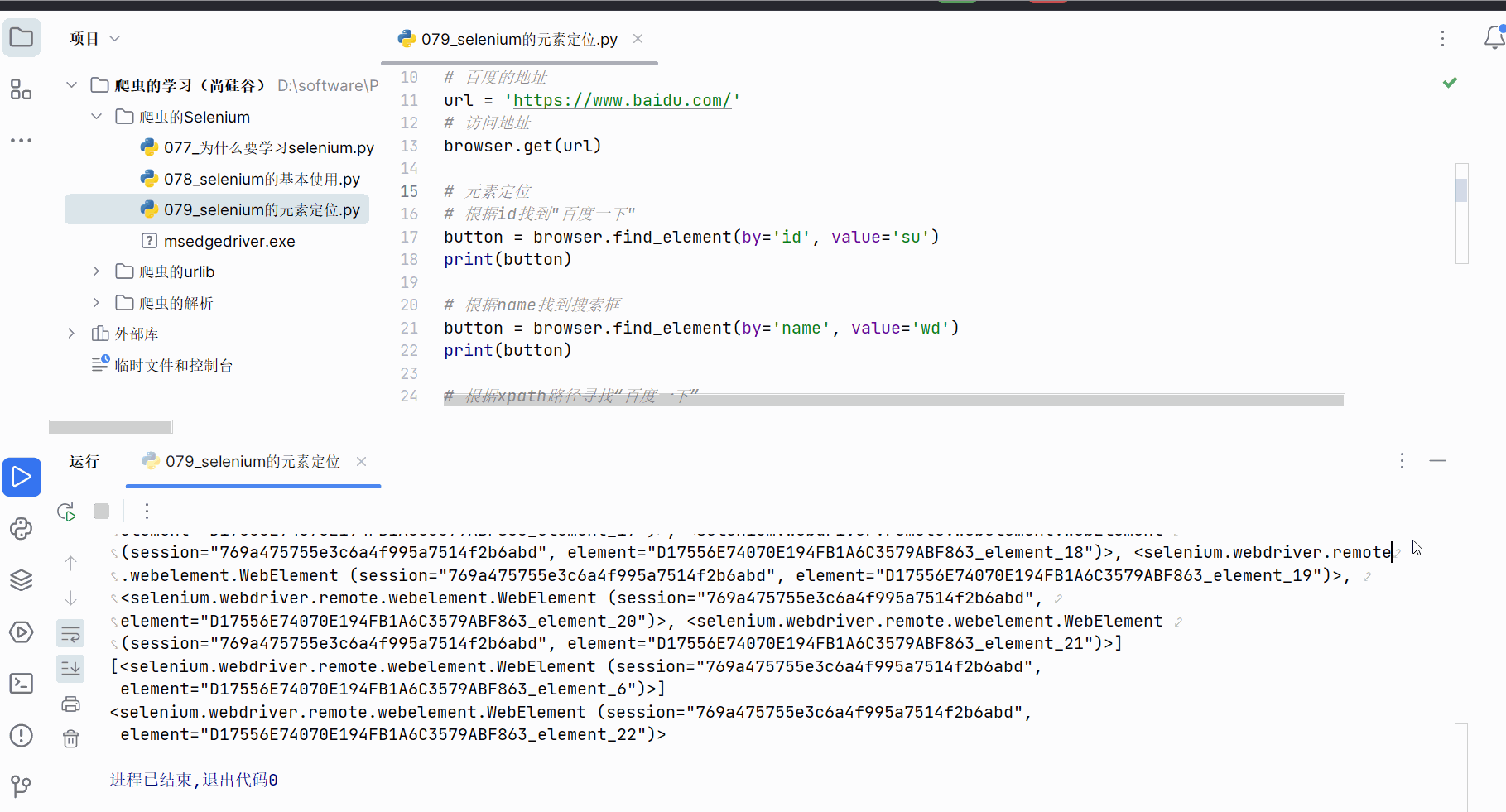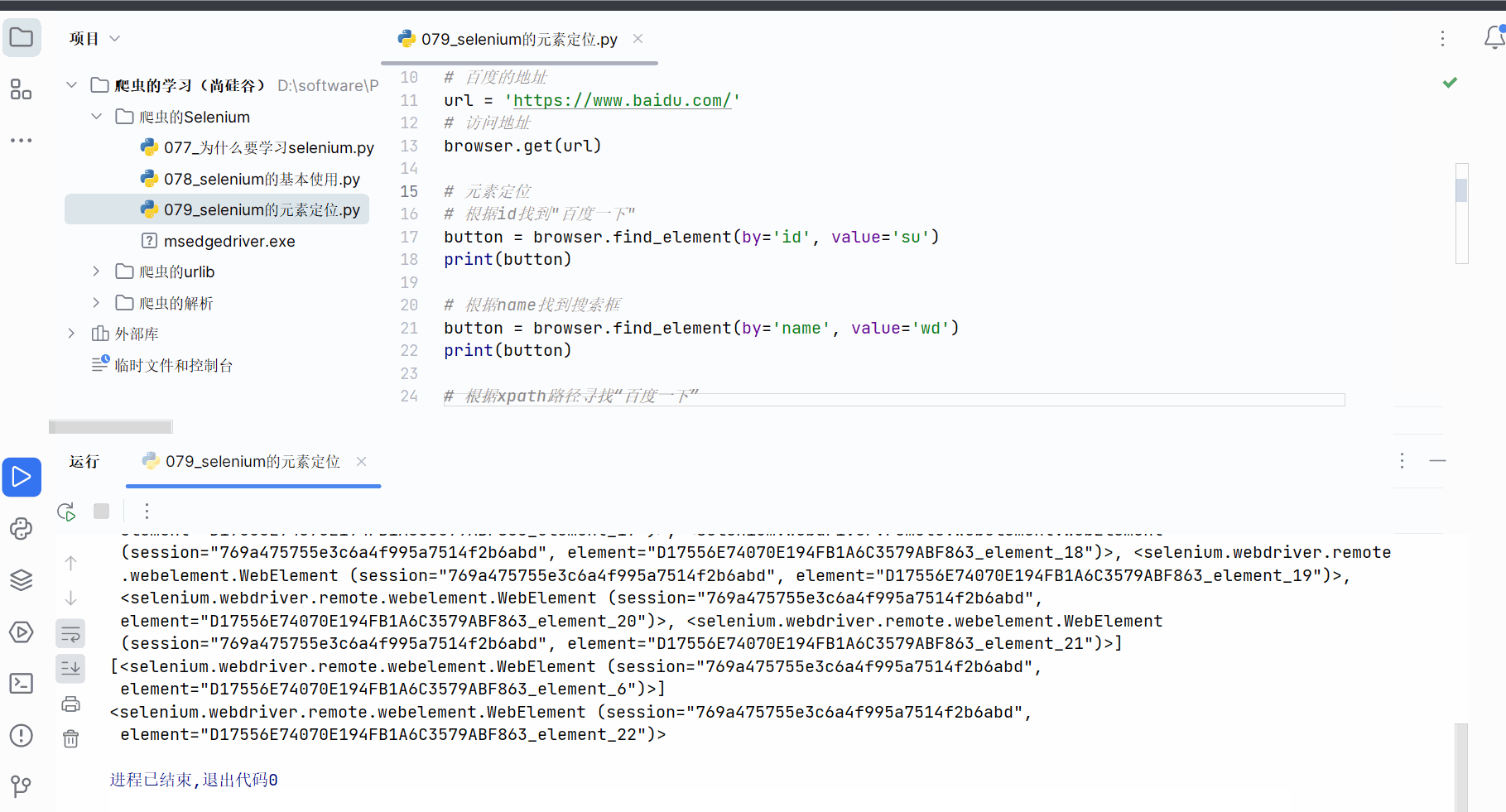
创建文件“079_selenium的元素定位.py”。
如下编程,熟悉使用元素定位的方法,具体根据id、name等属性、xpath路径、bs4路径、标签名字、链接名字来寻找元素对象。
"""
selenium的元素定位的演示
"""
from selenium import webdriver
# 浏览器驱动的路径
path = 'msedgedriver.exe'
# 创建浏览器对象
browser = webdriver.Edge(path)
# 百度的地址
url = 'https://www.baidu.com/'
# 访问地址
browser.get(url)
# 元素定位
# 根据id找到"百度一下"
button = browser.find_element(by='id', value='su')
print(button)
# 根据name找到搜索框
button = browser.find_element(by='name', value='wd')
print(button)
# 根据xpath路径寻找“百度一下”
button = browser.find_element(by='xpath', val-ue='/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input')
print(button)
# 根据标签名字获取对象
button = browser.find_elements(by='tag name', value='input')
print(button)
# 使用bs4的语法来获取对象
button = browser.find_elements(by="css selector", value='#su')
print(button)
# 寻找链接文本(对应html的a标签)
button = browser.find_element(by='link text', value='地图')
print(button)
4.selenium的元素信息
(1)访问元素信息
获取元素属性
.get_attribute(‘class’)
获取元素文本
text
获取标签名
tag_name
(2)代码演示
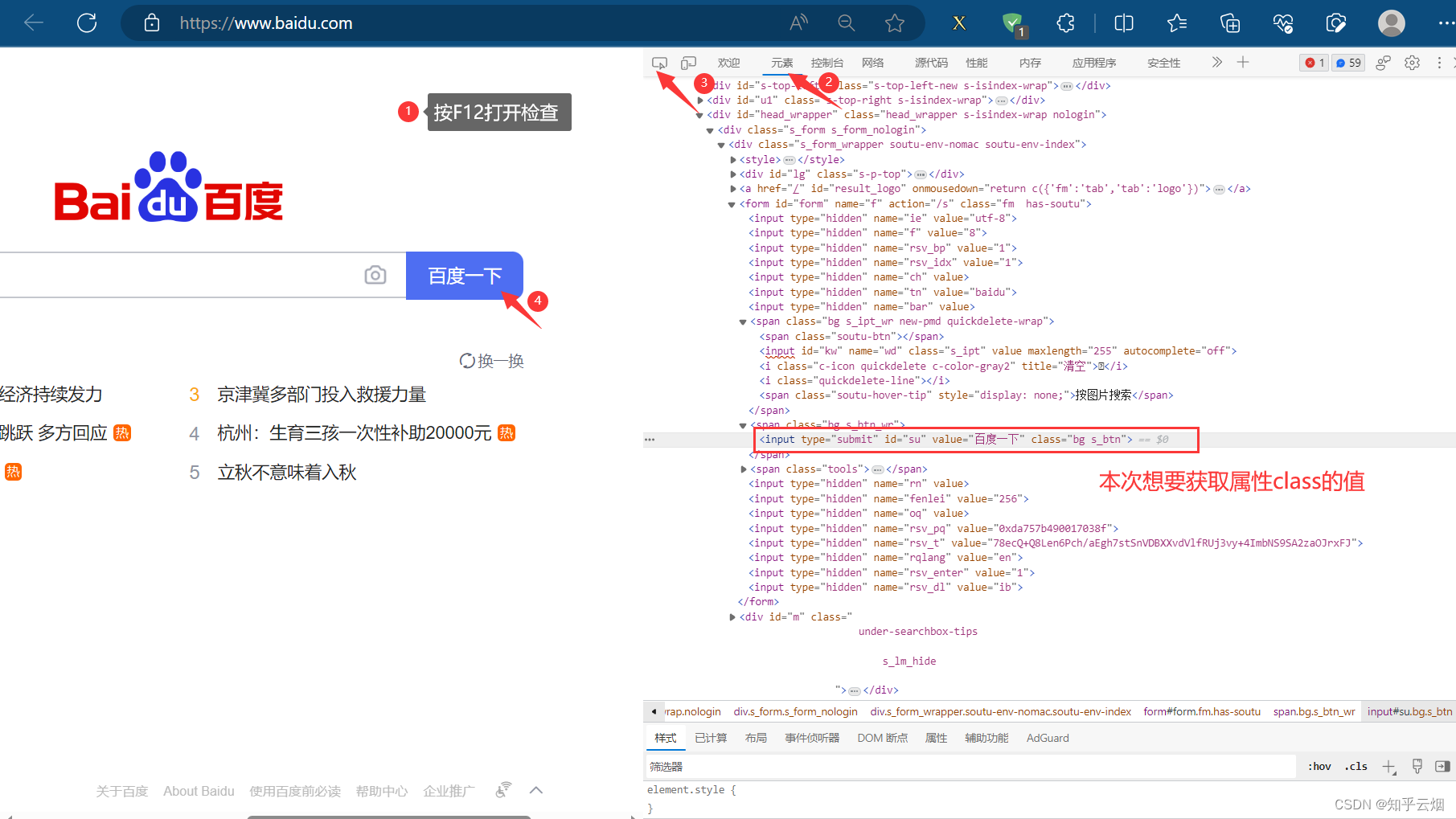
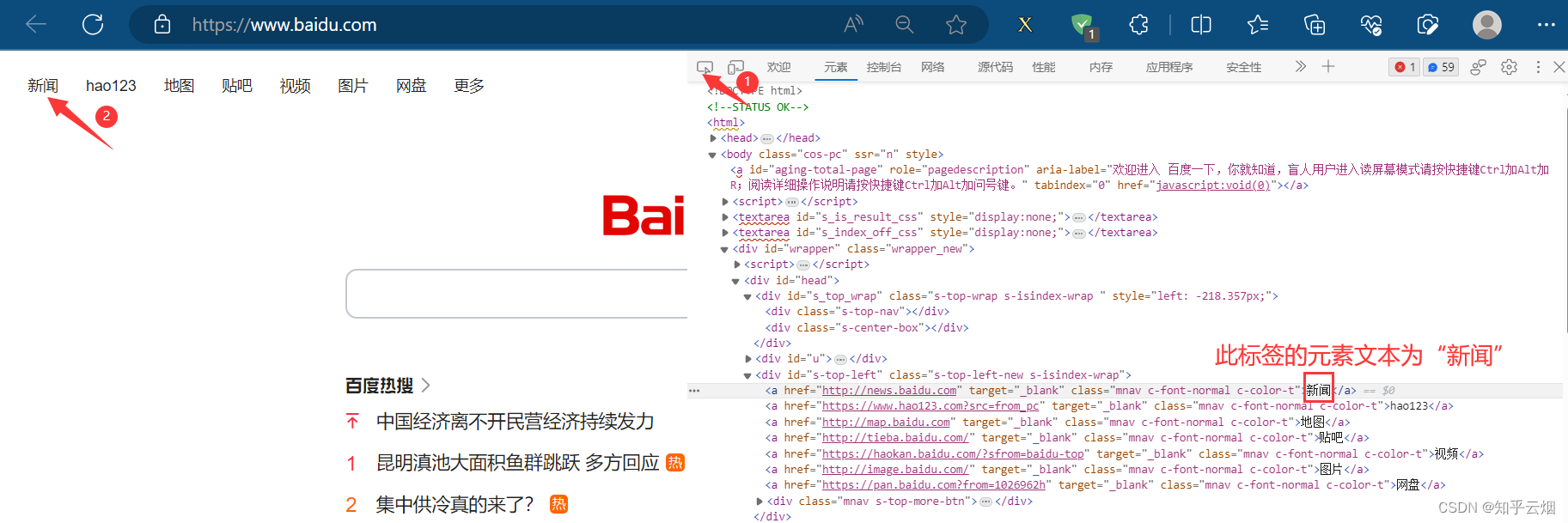
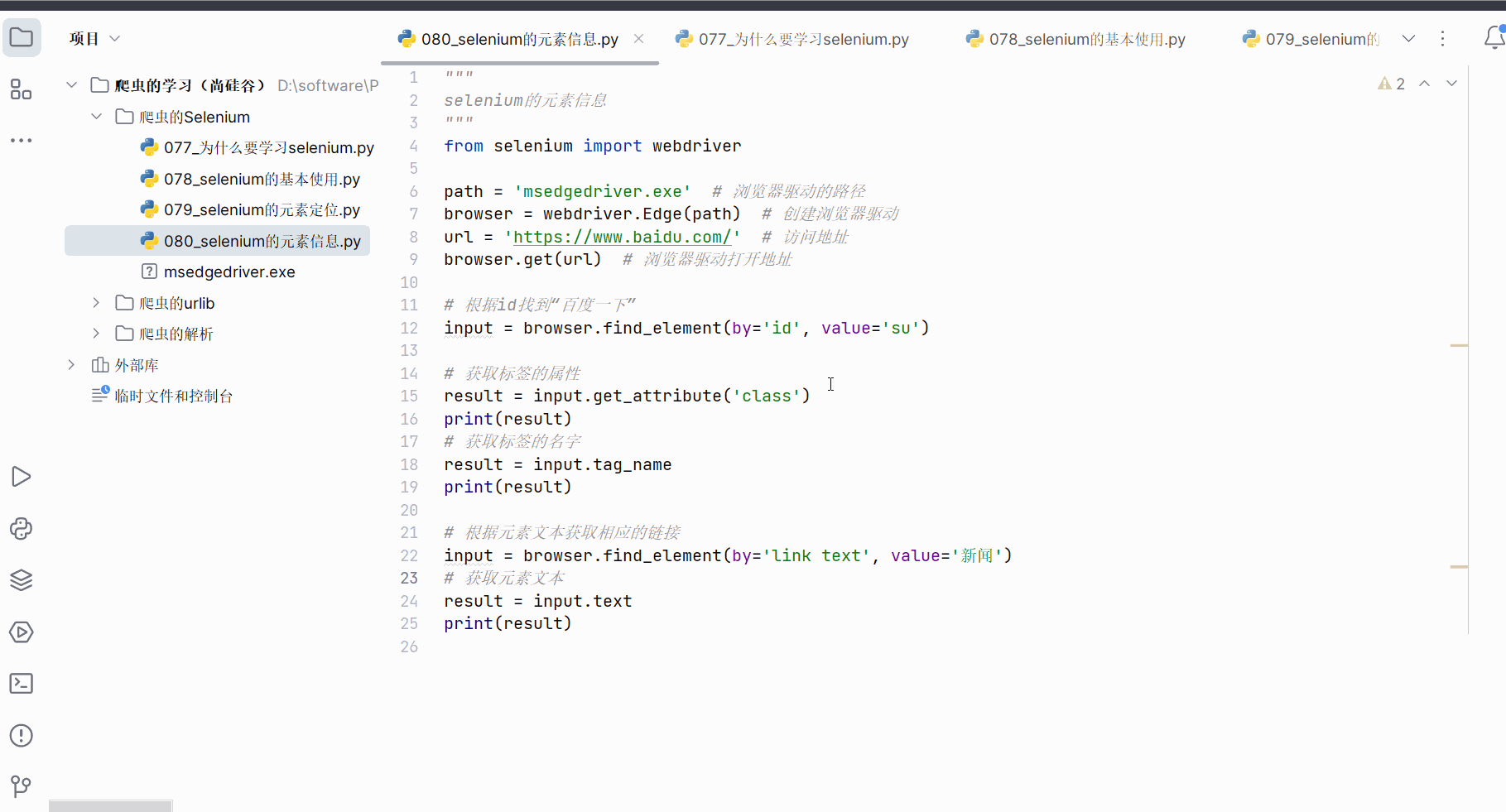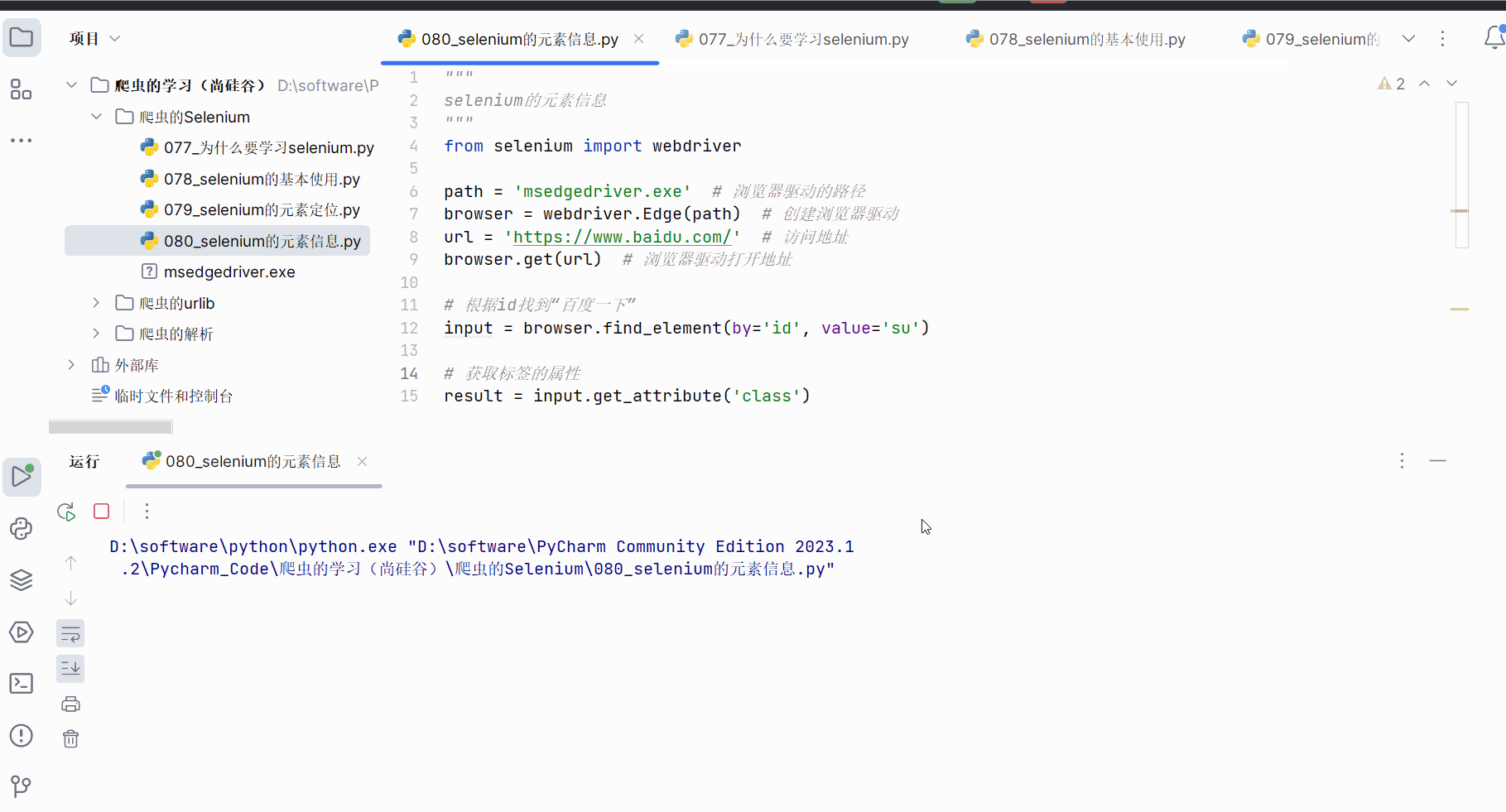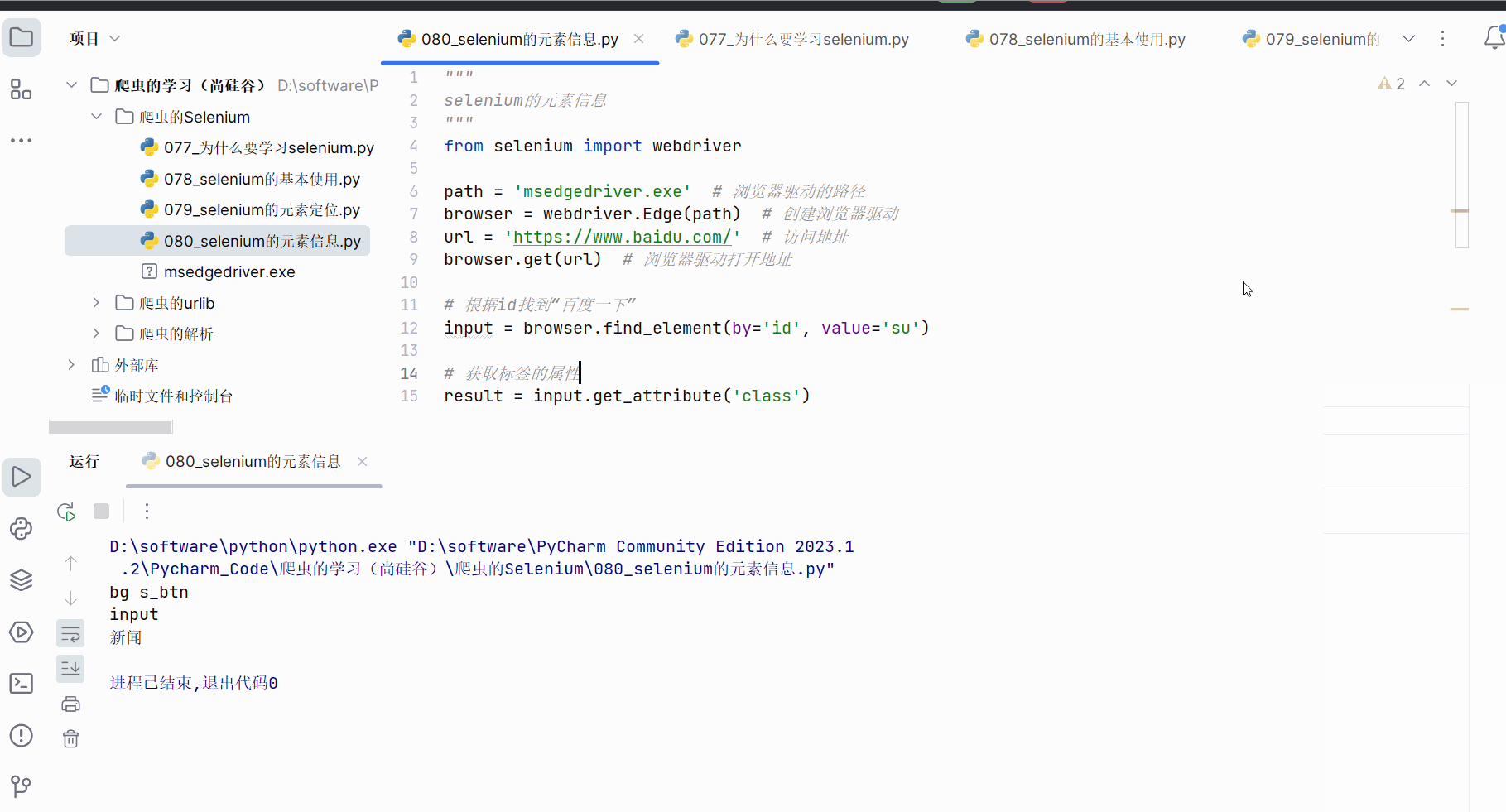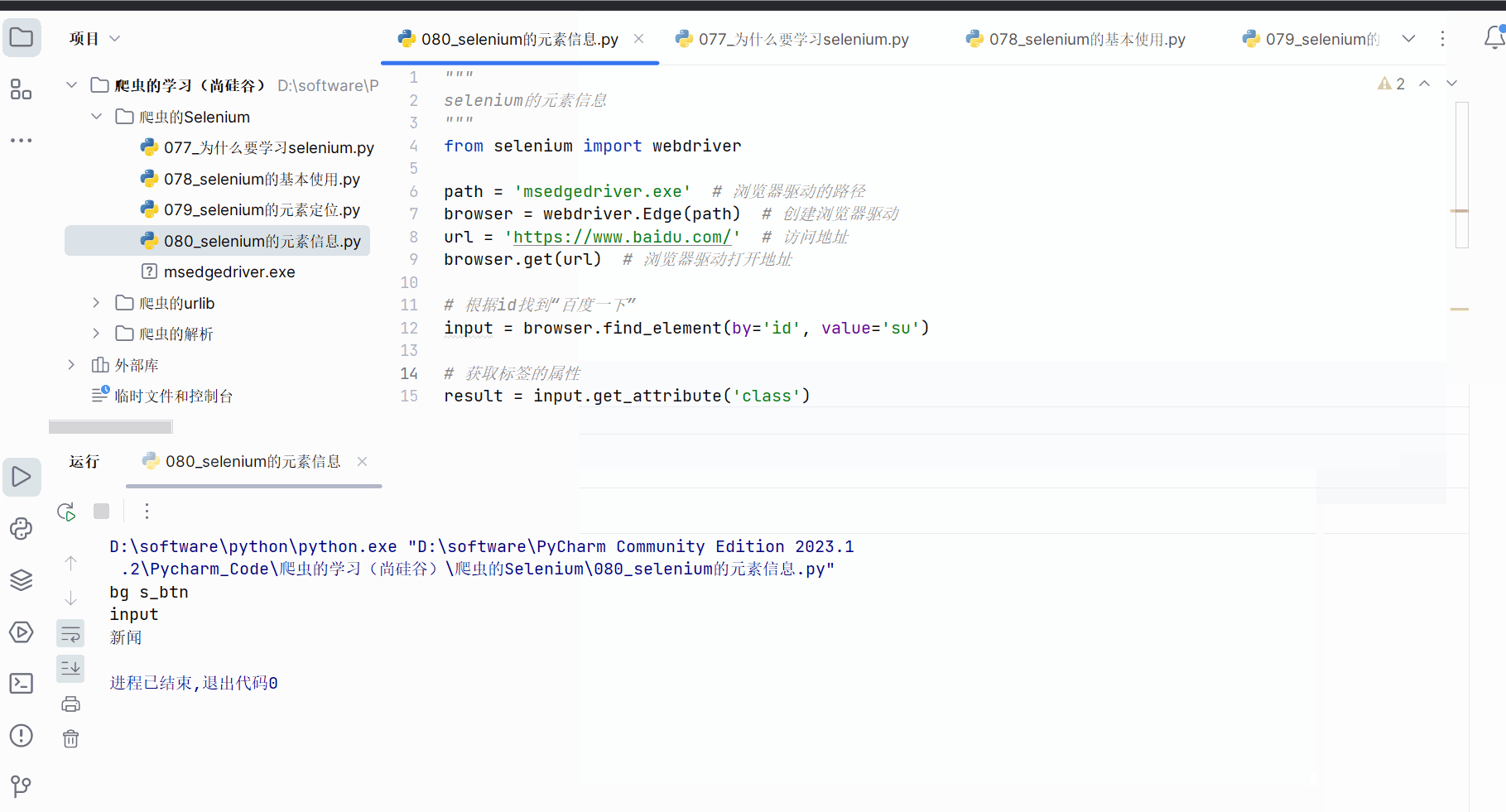
如下图所示,本次想要获取元素“百度一下”对应的属性class的值、标签名、和“新闻”的元素文本。
创建文件“080_selenium的元素信息.py”。
如下编程,熟悉元素信息的语法。
"""
selenium的元素信息
"""
from selenium import webdriver
path = 'msedgedriver.exe' # 浏览器驱动的路径
browser = webdriver.Edge(path) # 创建浏览器驱动
url = 'https://www.baidu.com/' # 访问地址
browser.get(url) # 浏览器驱动打开地址
# 根据id找到“百度一下”
input = browser.find_element(by='id', value='su')
# 获取标签的属性
result = input.get_attribute('class')
print(result)
# 获取标签的名字
result = input.tag_name
print(result)
# 根据元素文本获取相应的链接
input = browser.find_element(by='link text', value='新闻')
# 获取元素文本
result = input.text
print(result)
5.selenium的交互
(1)交互
点击:click()
输入:send_keys()
后退操作:browser.back()
前进操作:browser.forword()
模拟JS滚动:
js=‘document.documentElement.scrollTop=100000’
browser.execute_script(js) 执行js代a码
获取网页代码:page_source
退出:browser.quit()
(2)代码演示
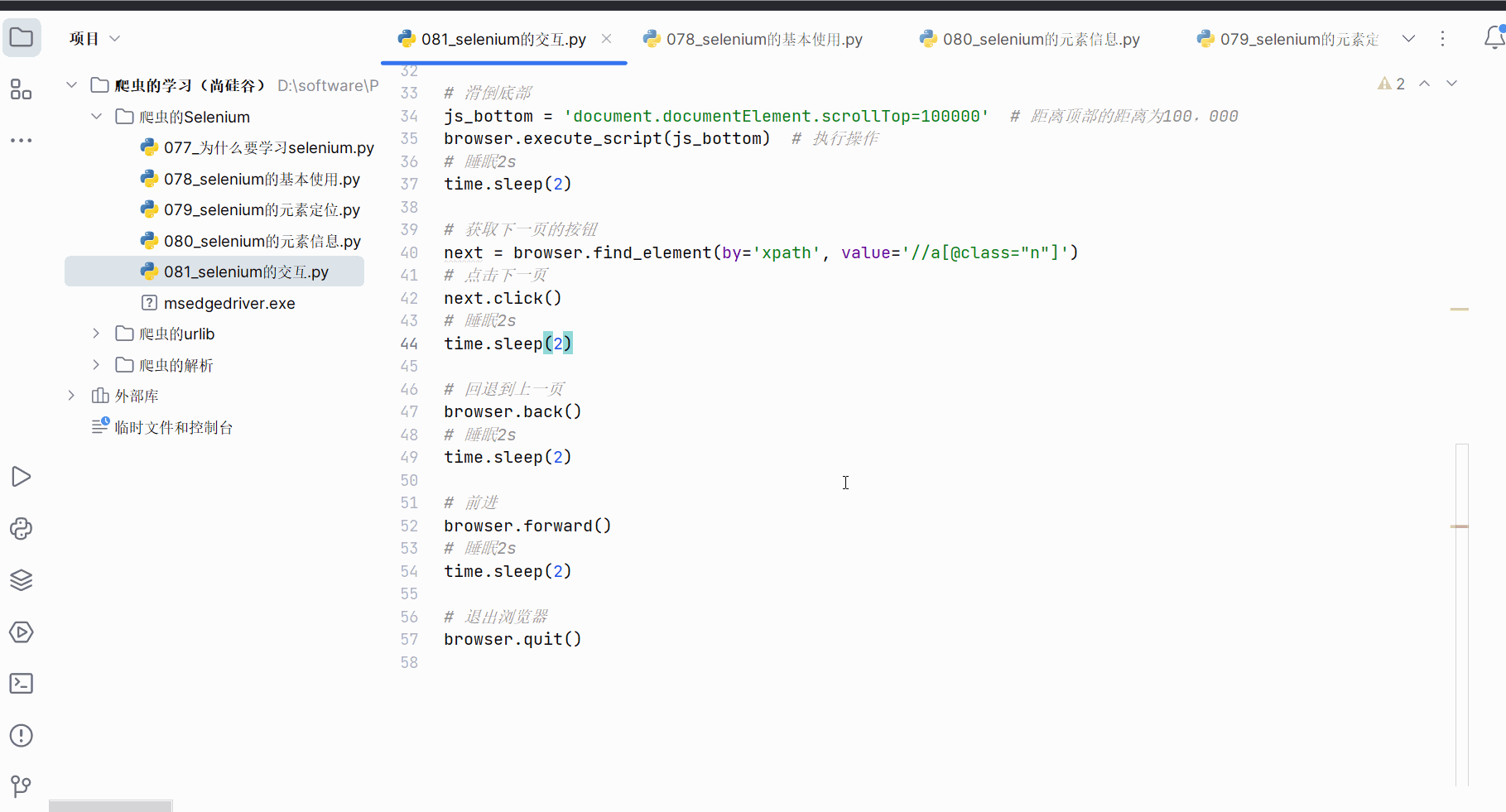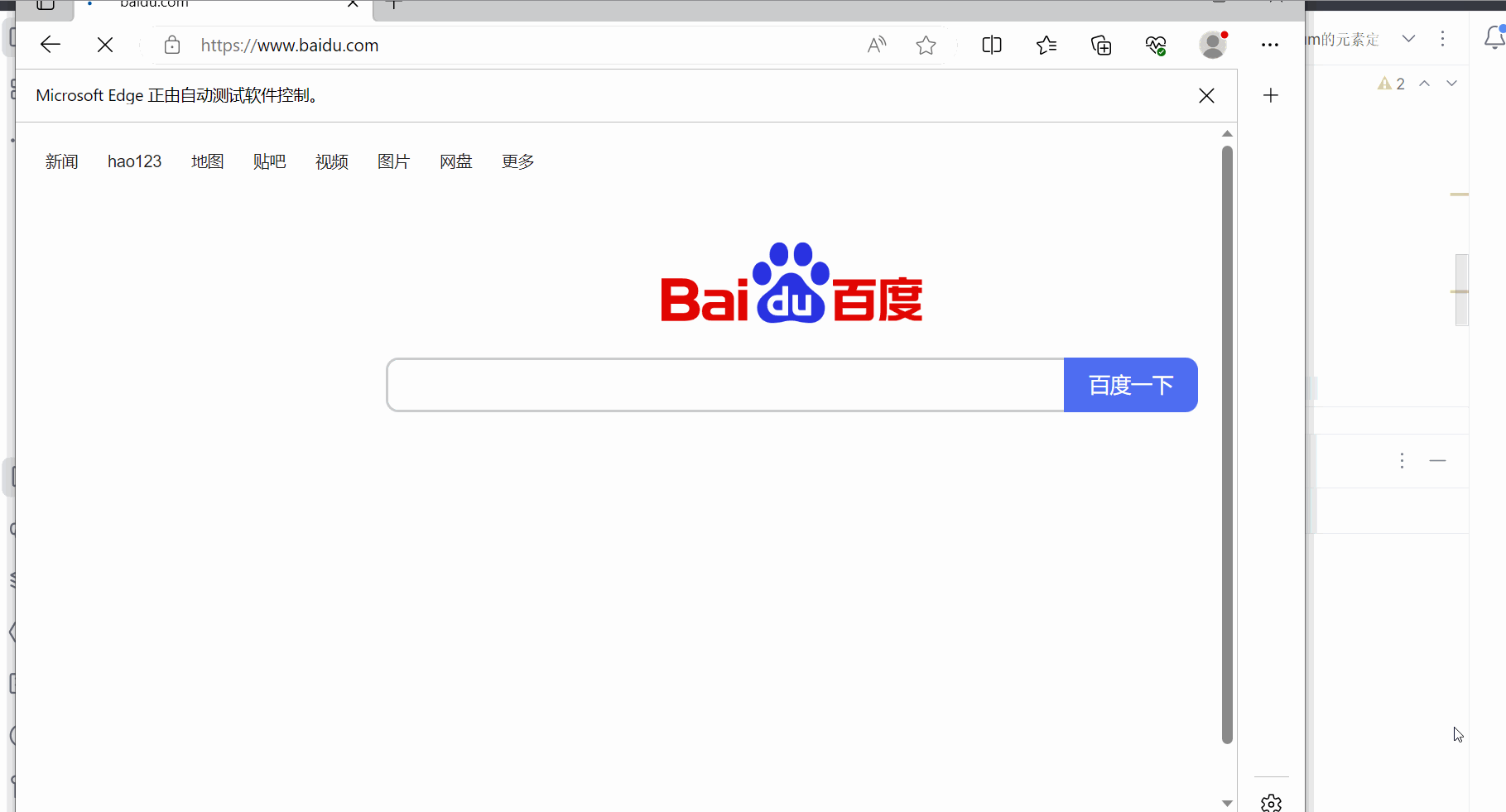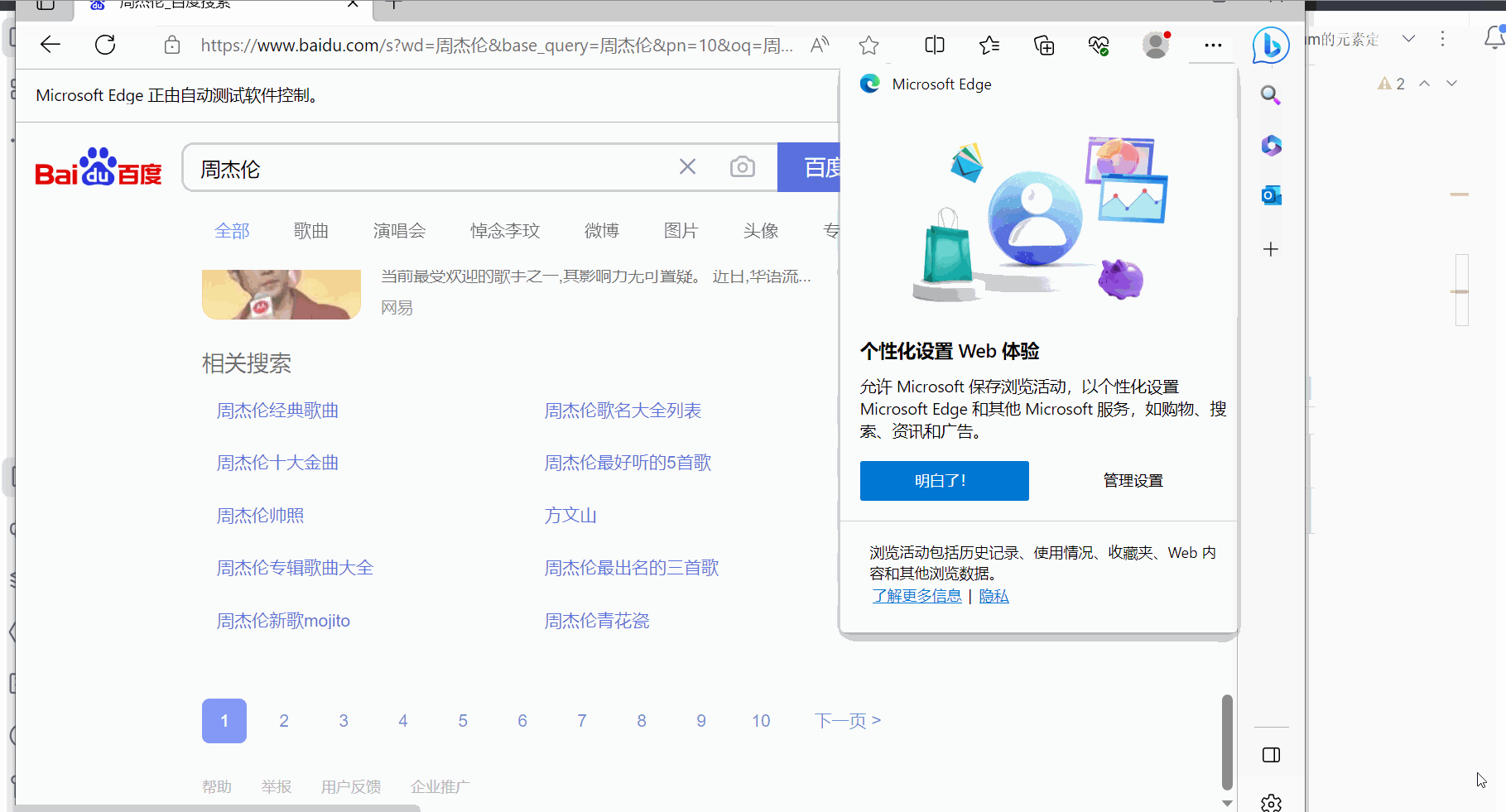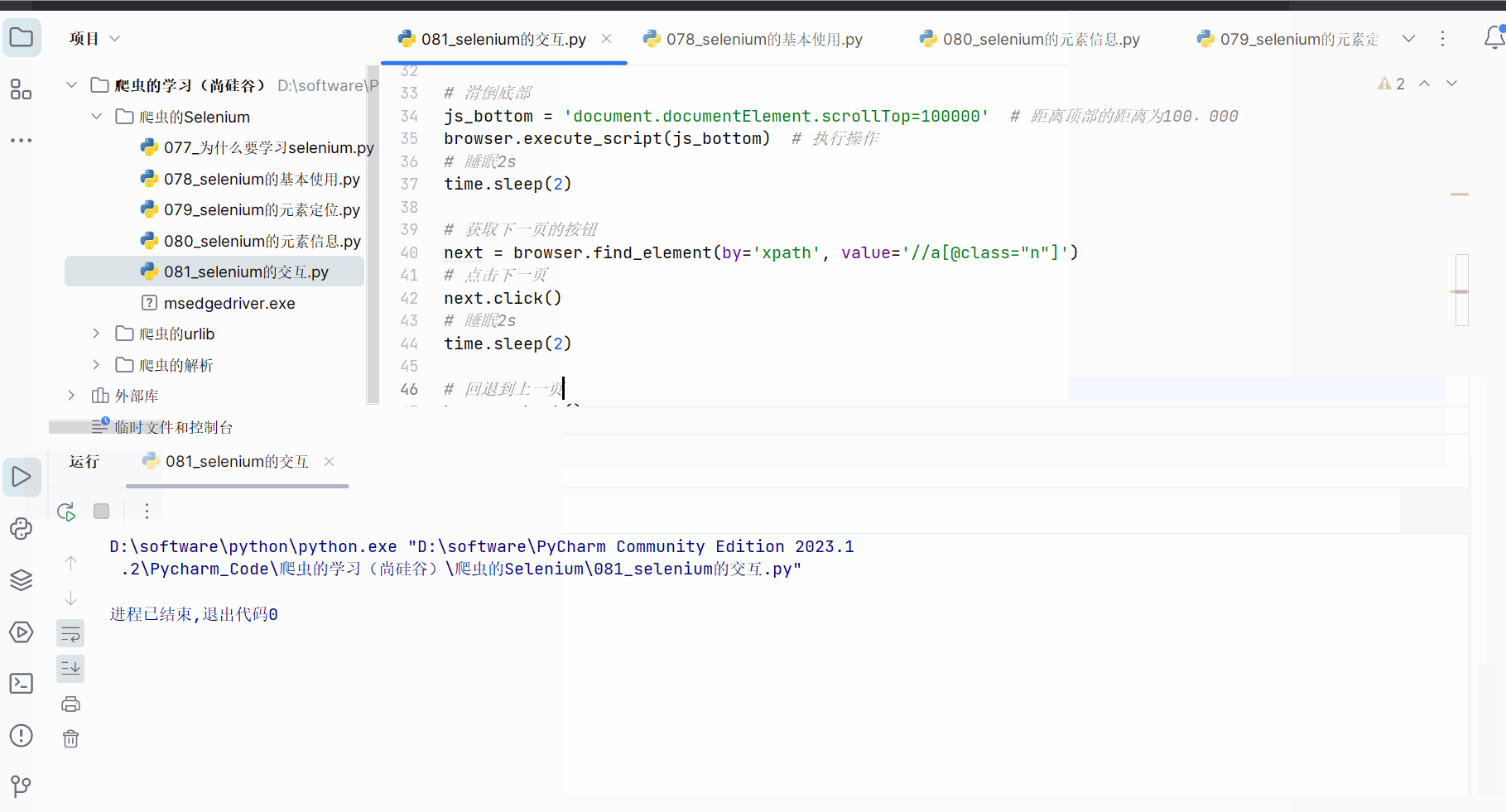
如下图,本次需要通过程序使浏览器使用百度搜索“周杰伦”,然后点到第2页,再使用一下后退、前进操作,然后再滚动到页末。
创建文件“081_selenium的交互.py”。
在编程时,需要知道百度搜索框的id为“kw”,“百度一下”的id为“su”,搜索后元素“下一页”含有class=“n”,当然,其他标签可能具有相同class的属性值,故可以打开xpath插件进行验证,然后在PyCharm中使用xpath路径定位到该元素。
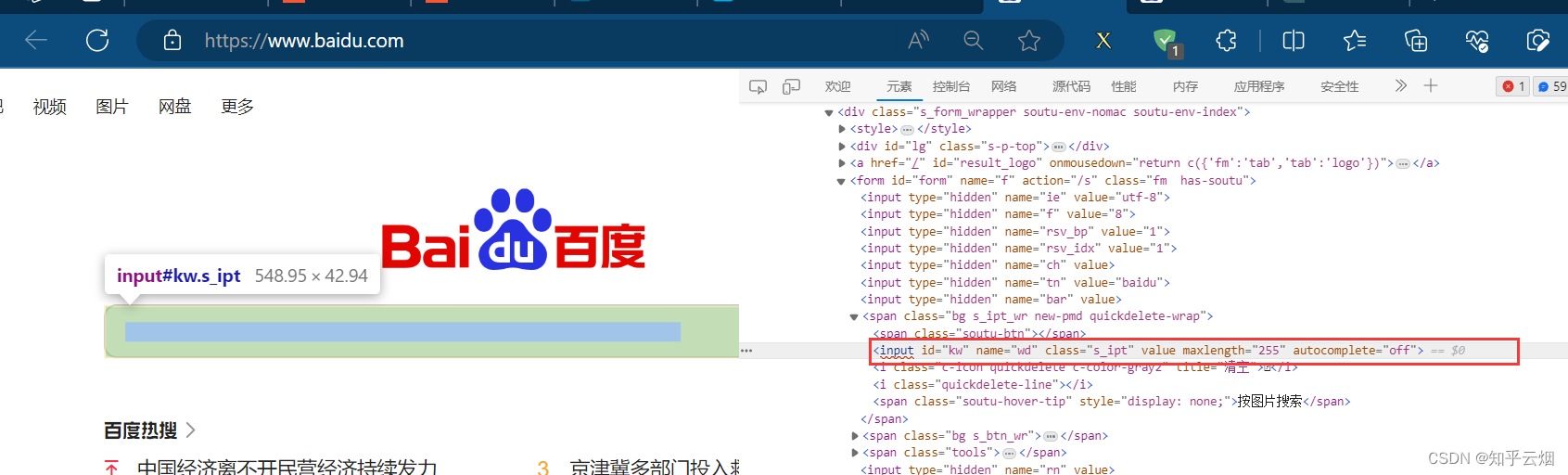
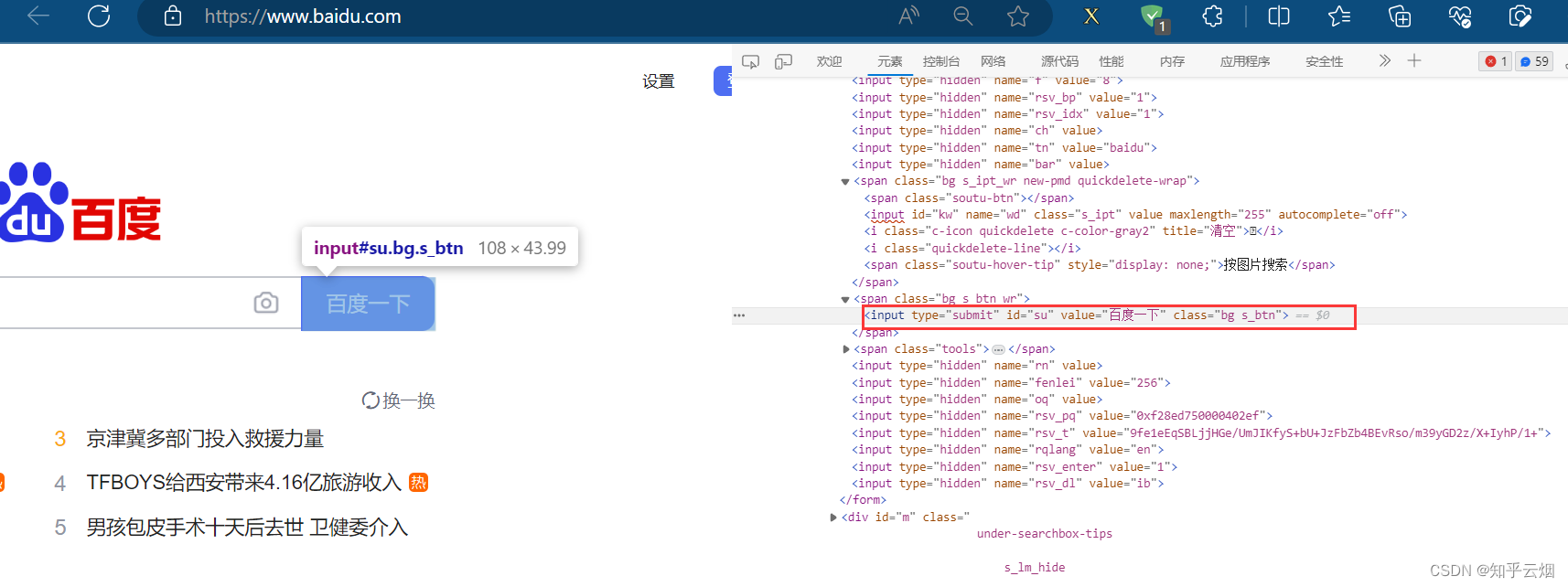
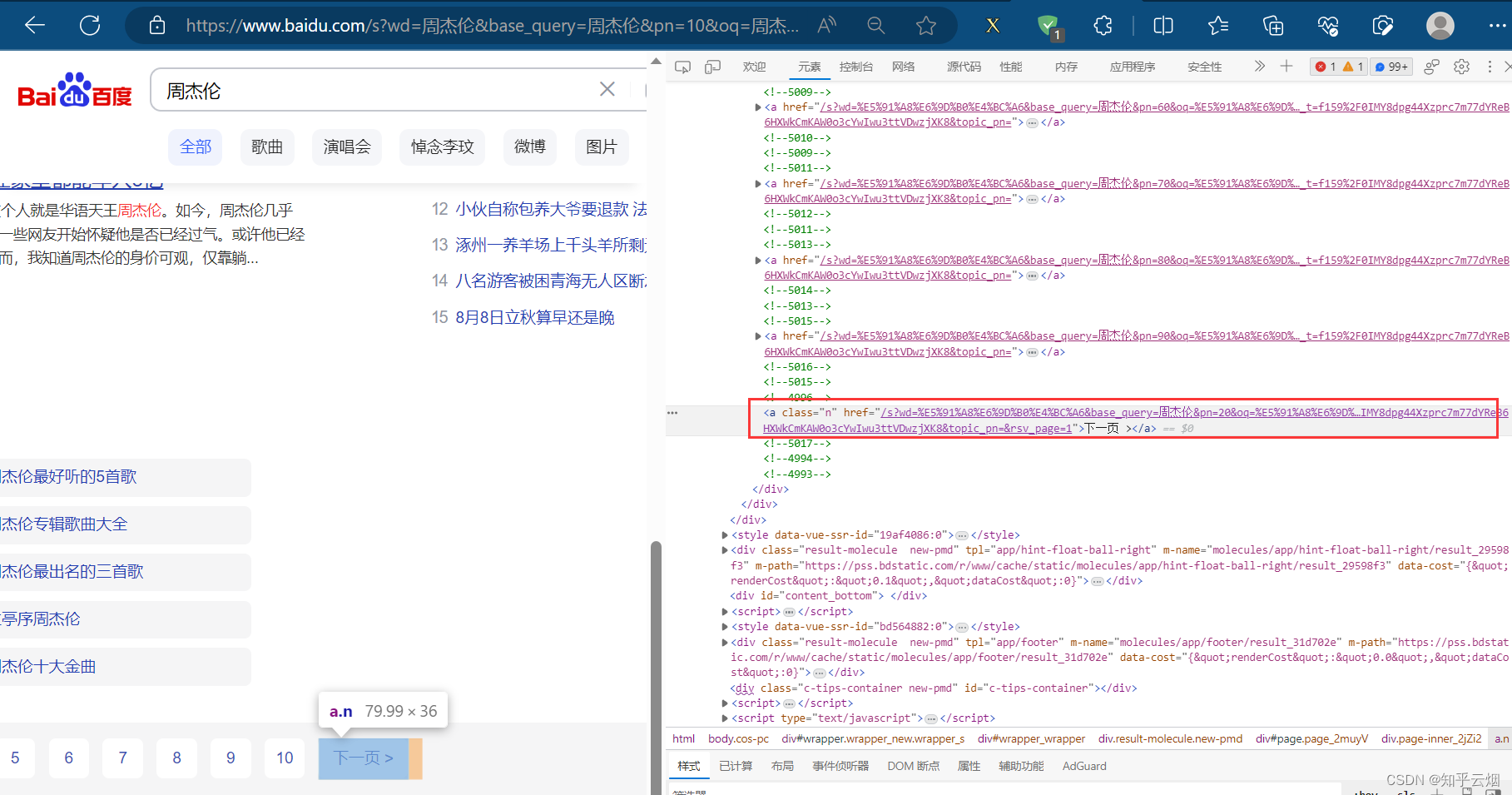
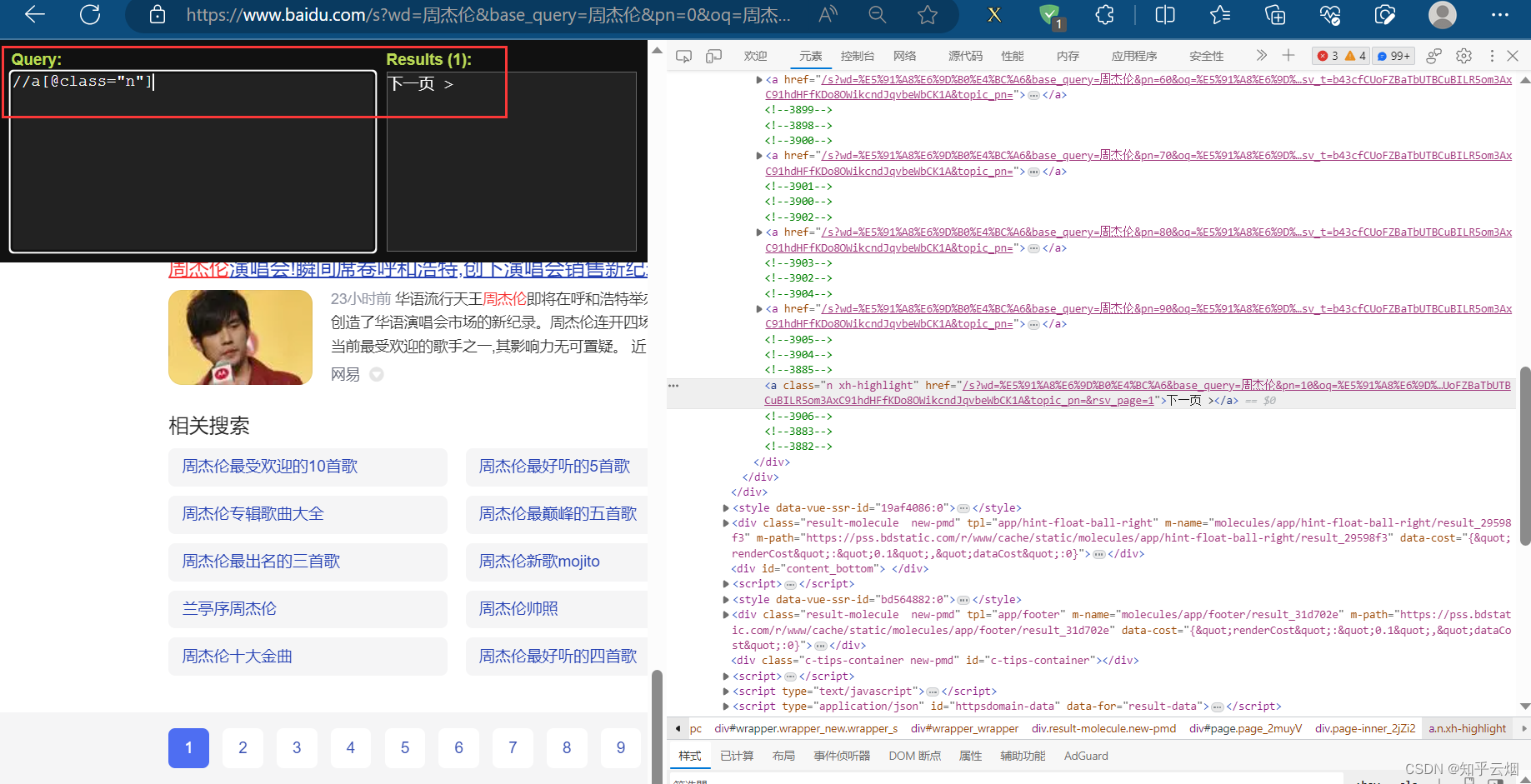
如下完成编程并运行。
"""
selenium的交互
"""
import time
from selenium import webdriver
# 创建浏览器对象
path = 'msedgedriver.exe'
browser = webdriver.Edge(path)
# 访问地址
url = 'https://www.baidu.com/'
# 打开地址
browser.get(url)
# 睡眠2s
time.sleep(2)
# 获取文本框对象
input = browser.find_element(by='id', value='kw')
# 在文本框中输入“周杰伦”
input.send_keys('周杰伦')
# 睡眠2s
time.sleep(2)
# 获取“百度一下”的按钮
button = browser.find_element(by='id', value='su')
# 点击“百度一下”的按钮
button.click()
# 睡眠2s
time.sleep(2)
# 滑倒底部
js_bottom = 'document.documentElement.scrollTop=100000' # 距离顶部的距离为100,000
browser.execute_script(js_bottom) # 执行操作
# 睡眠2s
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element(by='xpath', value='//a[@class="n"]')
# 点击下一页
next.click()
# 睡眠2s
time.sleep(2)
# 回退到上一页
browser.back()
# 睡眠2s
time.sleep(2)
# 前进
browser.forward()
# 睡眠2s
time.sleep(2)
# 退出浏览器
browser.quit()
二、Phantomjs
1. Phantomjs的基本使用
在前面的学习中,发现Selenium,每次执行过程中都需打开浏览器、关闭浏览器、中间还有一堆操作,这是因为它有页面,而页面里面会有js、css等等很多文件,因此打开页面会导致代码的性能很慢。因此提出Phantomjs、Chrome handless,目前Phantomjs已逐渐淘汰。
(1)什么是Phantomjs
(1)是一个无界面的浏览器
(2)支持页面元素查找,js的执行等
(3)由于不进行css和gui渲染,运行效率要比真实的浏览器要快很多
(2)如何使用Phantomjs
(1)获取Phantomjs.exe文件路径path
(2)browser= webdriver.PhantomJs(path)
(3)browser.get(url)
扩展:保存屏幕快照:browser.save_screenshot(‘baidu.png’)
具体步骤:①到网站中“https://phantomjs.org/download.html”下载文件“phantomjs.exe”。然后将该文件进行解压,再复制其中的文件“phantomjs.exe”,到文件夹“爬虫的Selenium”中进行粘贴。

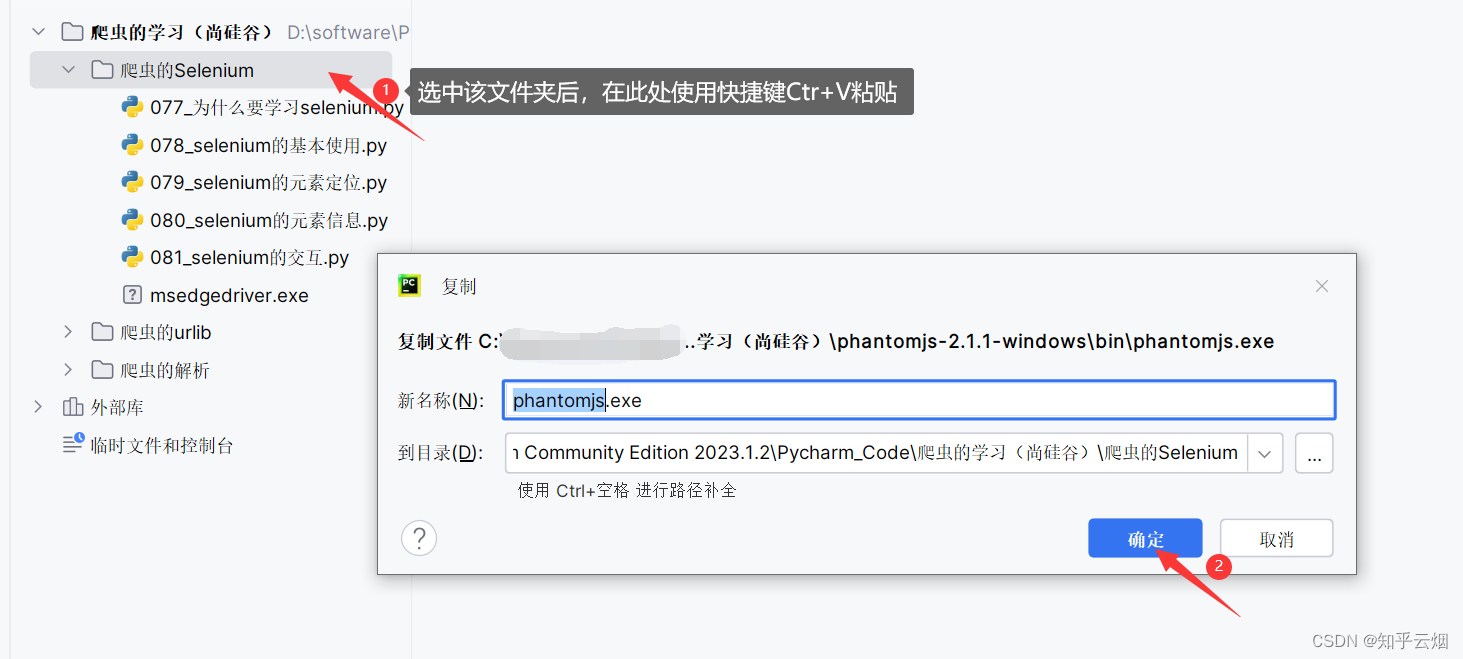

②然后就可以到PyCharm中去编写使用Phantomjs的代码了。
(3)代码演示
创建文件“082_phantomjs的基本使用.py”。
创建文件夹“082_phantomjs的基本使用”。
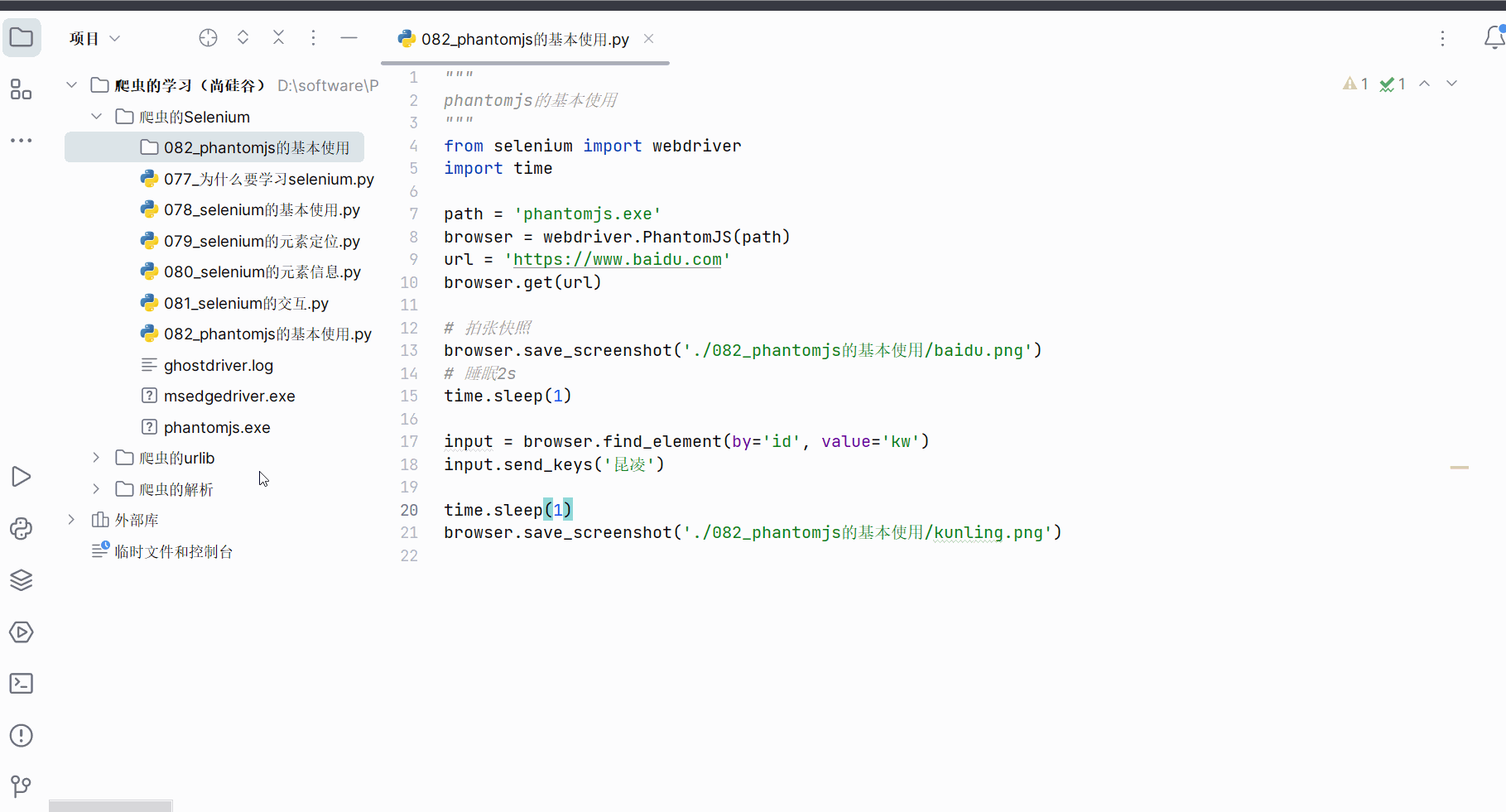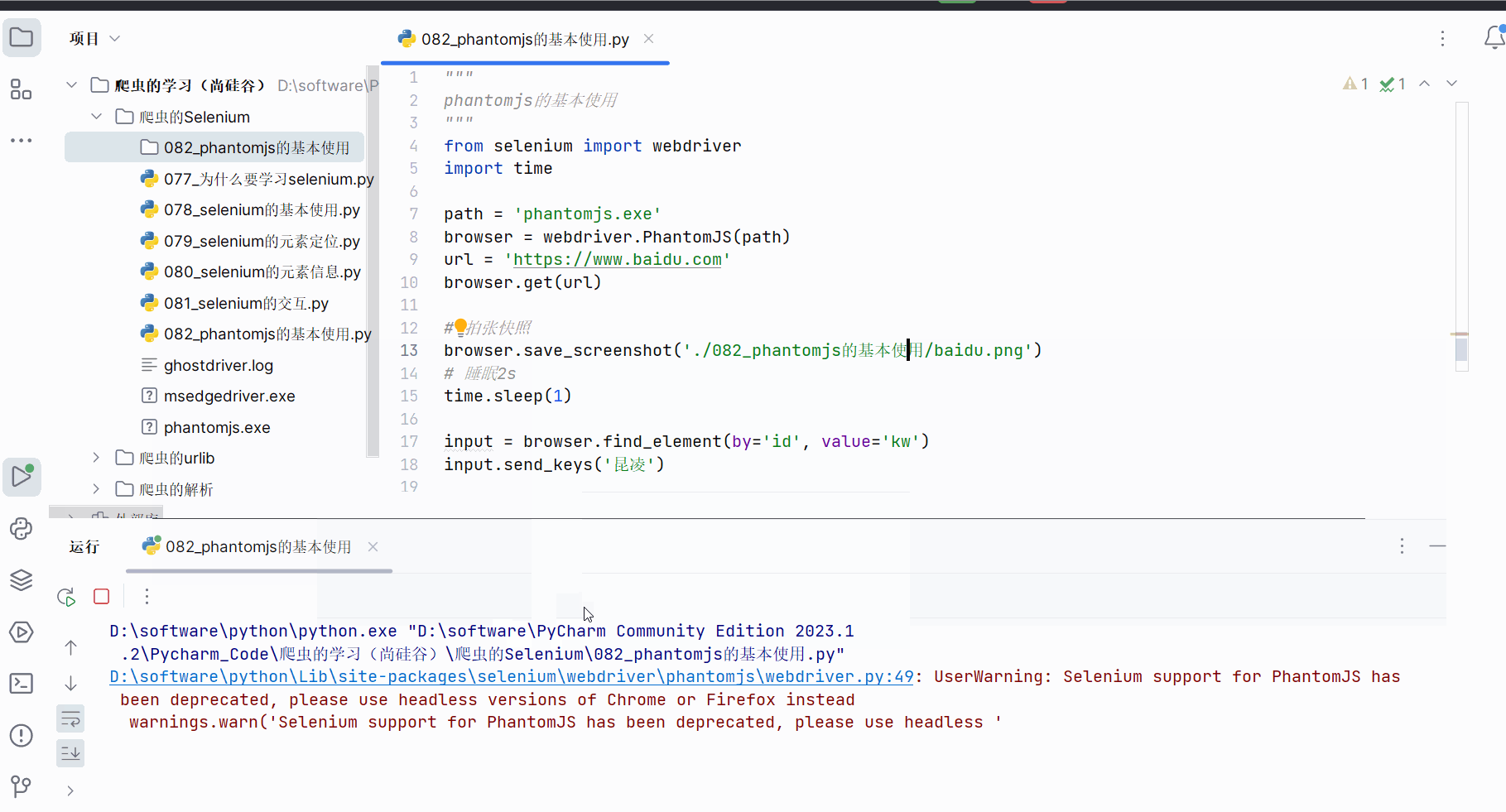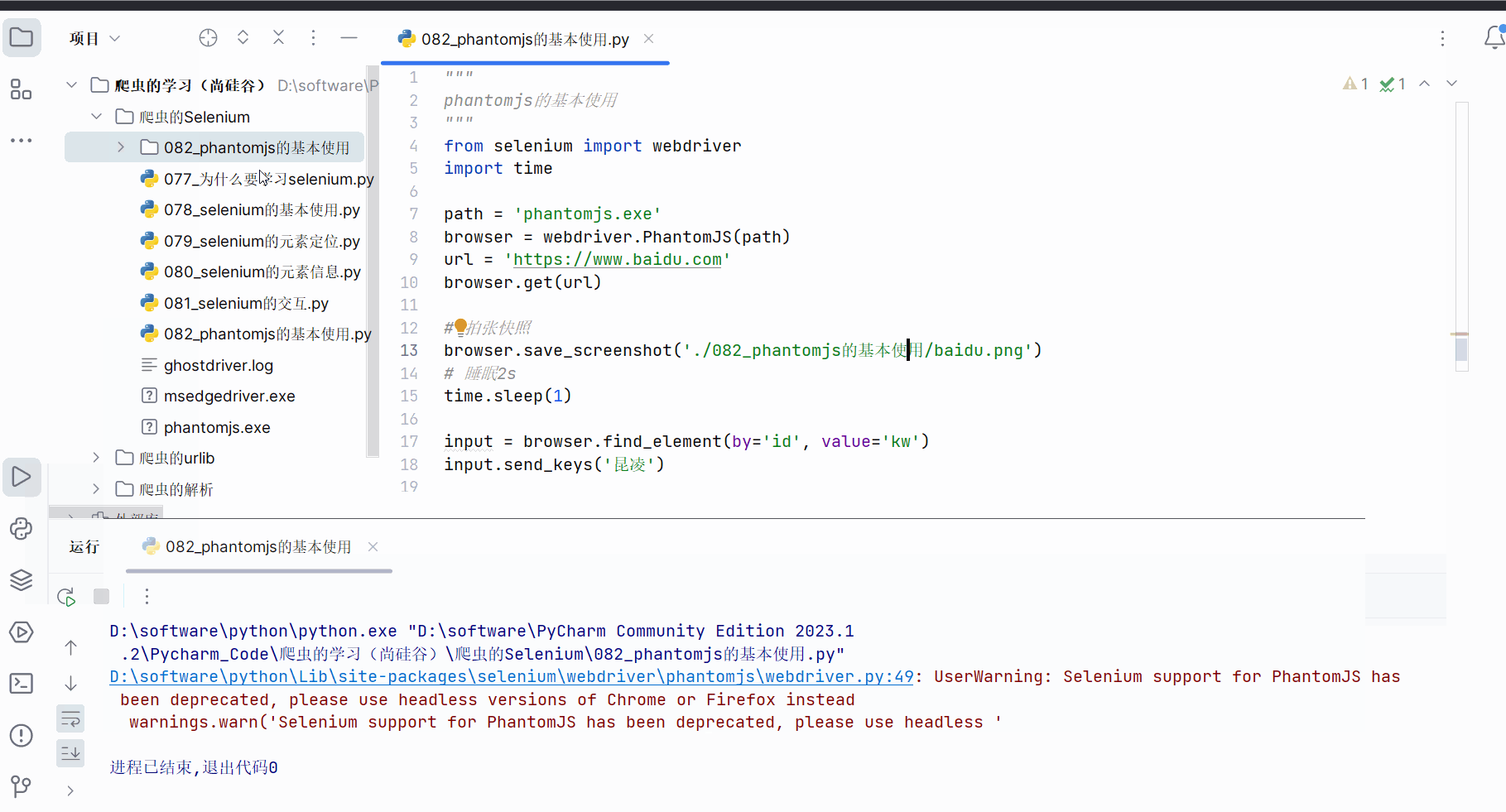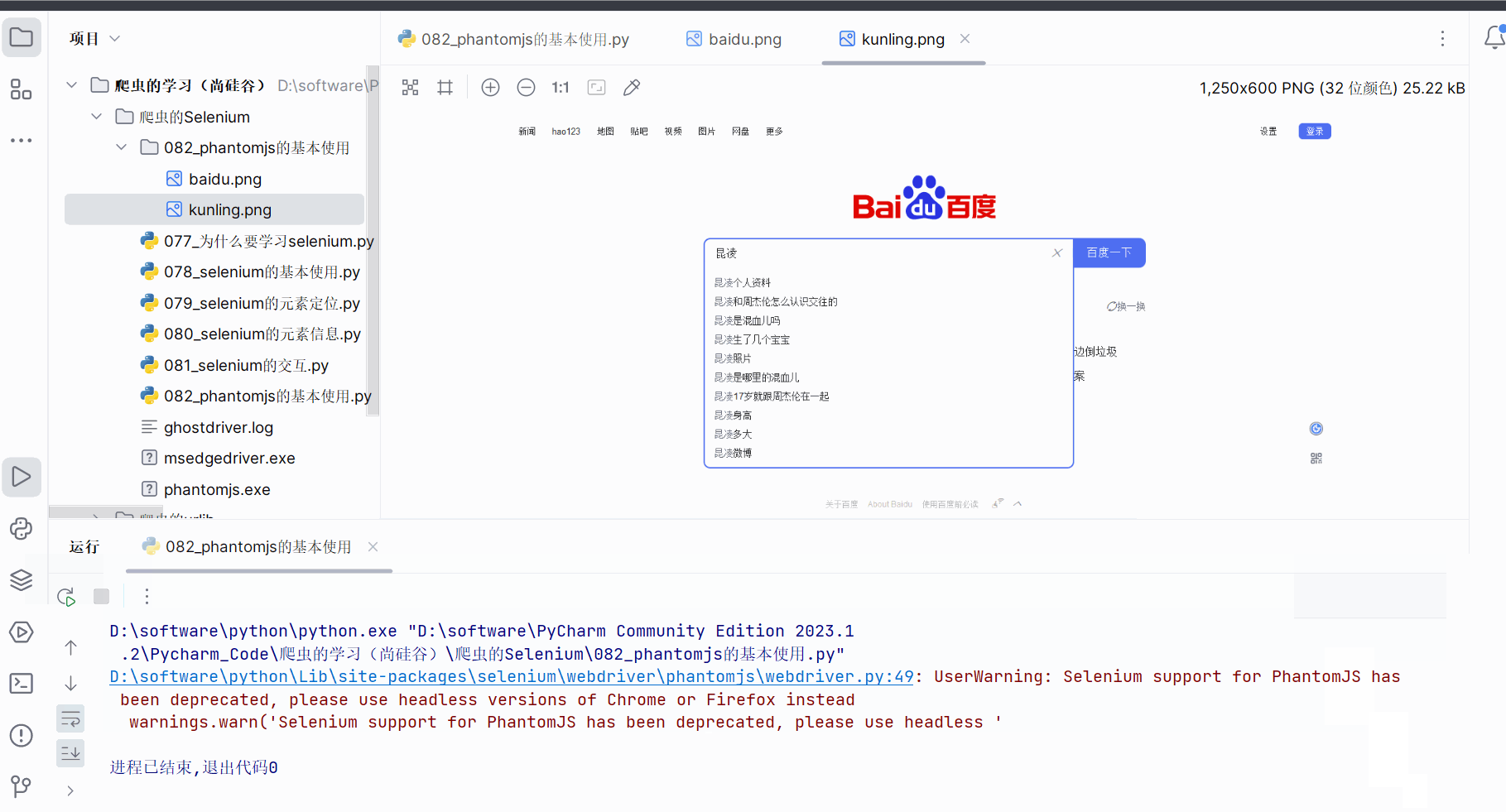
如下编程并运行。只是有红字警告,告诉我们Phantomjs已经停更。
"""
phantomjs的基本使用
"""
from selenium import webdriver
import time
path = 'phantomjs.exe'
browser = webdriver.PhantomJS(path)
url = 'https://www.baidu.com'
browser.get(url)
# 拍张快照
browser.save_screenshot('./082_phantomjs的基本使用/baidu.png')
# 睡眠2s
time.sleep(1)
input = browser.find_element(by='id', value='kw')
input.send_keys('昆凌')
time.sleep(1)
browser.save_screenshot('./082_phantomjs的基本使用/kunling.png')
三、Headless
1. Headless的基本使用
(1)什么是Headless
如下图,Edge也有 Headless,且与Chrome类似。
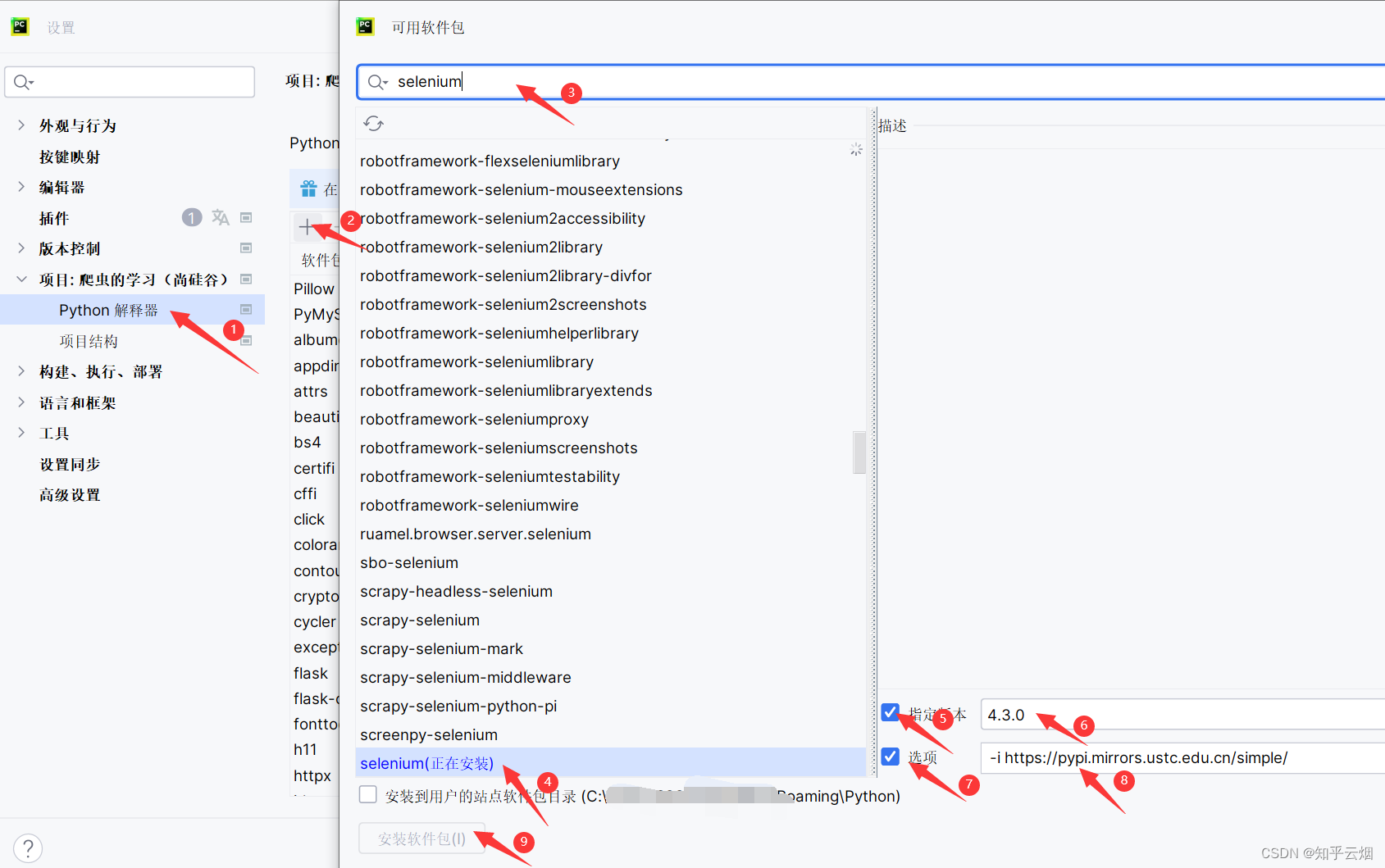
经过半天的尝试与搜索,终于发现Edge的无头浏览器的正确使用方法(“https://huaweicloud.csdn.net/63808b3ddacf622b8df8a37e.html”)。首先,需要如下图所示,将selenium的版本更新到4.3.0及以上(本人安装的4.3.0),3开头的版本是不支持无头的Edge浏览器的。它的配置与Chrome也不一样。需要说明的是,本节关于Chrome的截图使用的selenium版本为3.141.0。
(2)配置
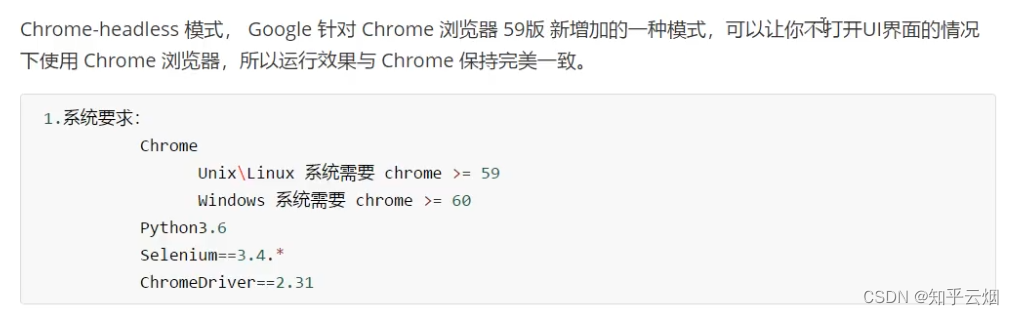
下图是无头的Chrome浏览器的配置,在使用时,将它复制到程序中,然后根据实际安装的Chrome浏览器的位置填写路径。之后再根据selenium的语法完成相应的功能。

Edge的配置与Chrome不一样,具体如下(不过使用方法相同):
from selenium import webdriver # 导入selenium库
from selenium.webdriver.edge.options import Options # 导入浏览器设置相关的类
# 无可视化界面设置
edge_options = Options()
# 使用无头模式
edge_options.add_argument('--headless')
# 禁用GPU,防止无头模式出现莫名的BUG
edge_options.add_argument('--disable-gpu')
# 将参数传给浏览器
browser = webdriver.Edge(options=edge_options)
(3)代码的演示
创建文件“083_无头浏览器的使用.py”。

如下编写代码,学会无头浏览器的使用。
"""
无头浏览器的使用
"""
from selenium import webdriver # 导入selenium库
from selenium.webdriver.edge.options import Options # 导入浏览器设置相关的类
# 封装的headless
def share_browser():
# 无可视化界面设置
edge_options = Options()
# 使用无头模式
edge_options.add_argument('--headless')
# 禁用GPU,防止无头模式出现莫名的BUG
edge_options.add_argument('--disable-gpu')
# 将参数传给浏览器
browser = webdriver.Edge(options=edge_options)
return browser
browser = share_browser()
# 启动浏览器
url = "https://baidu.com"
browser.get(url)
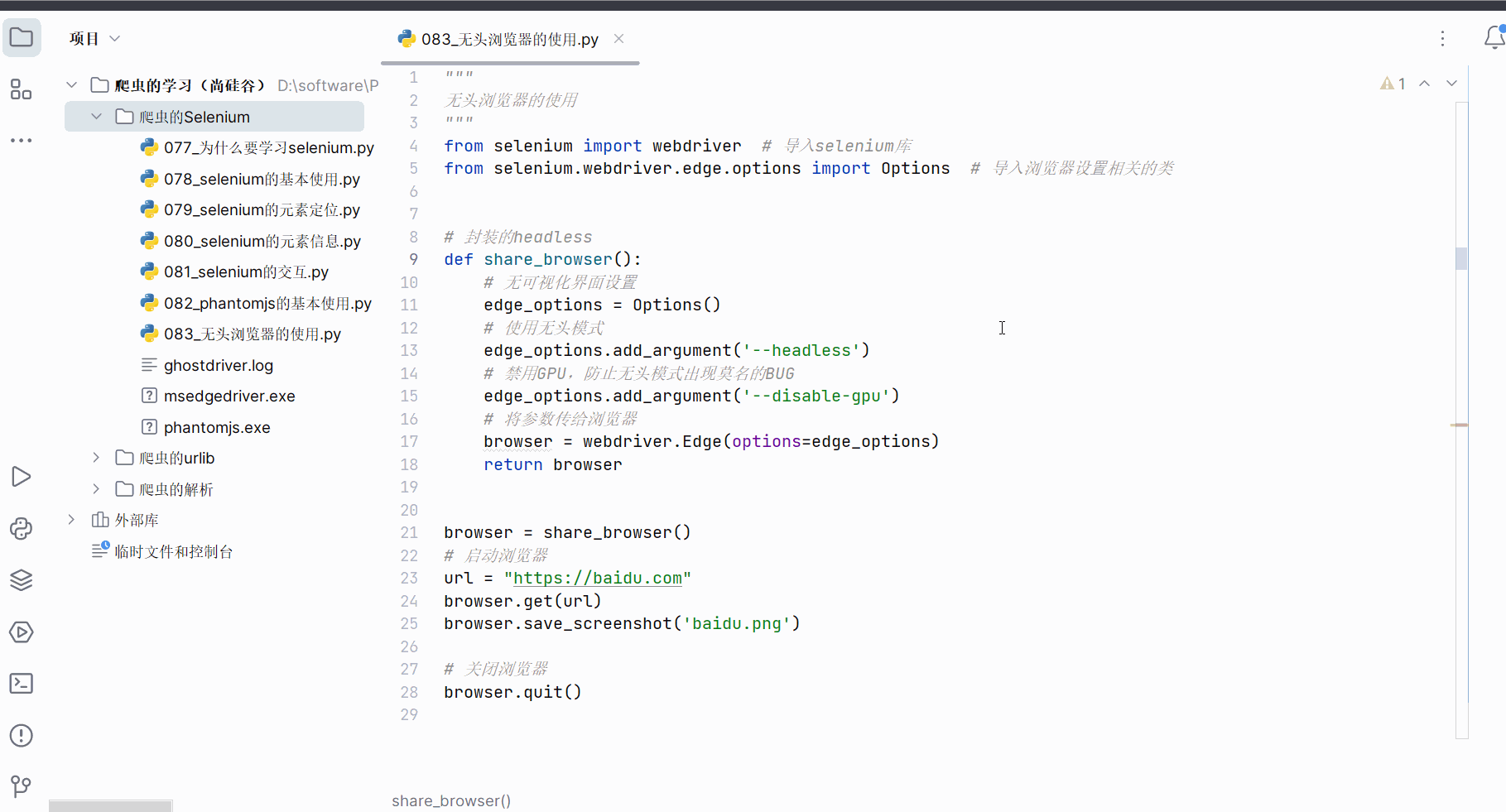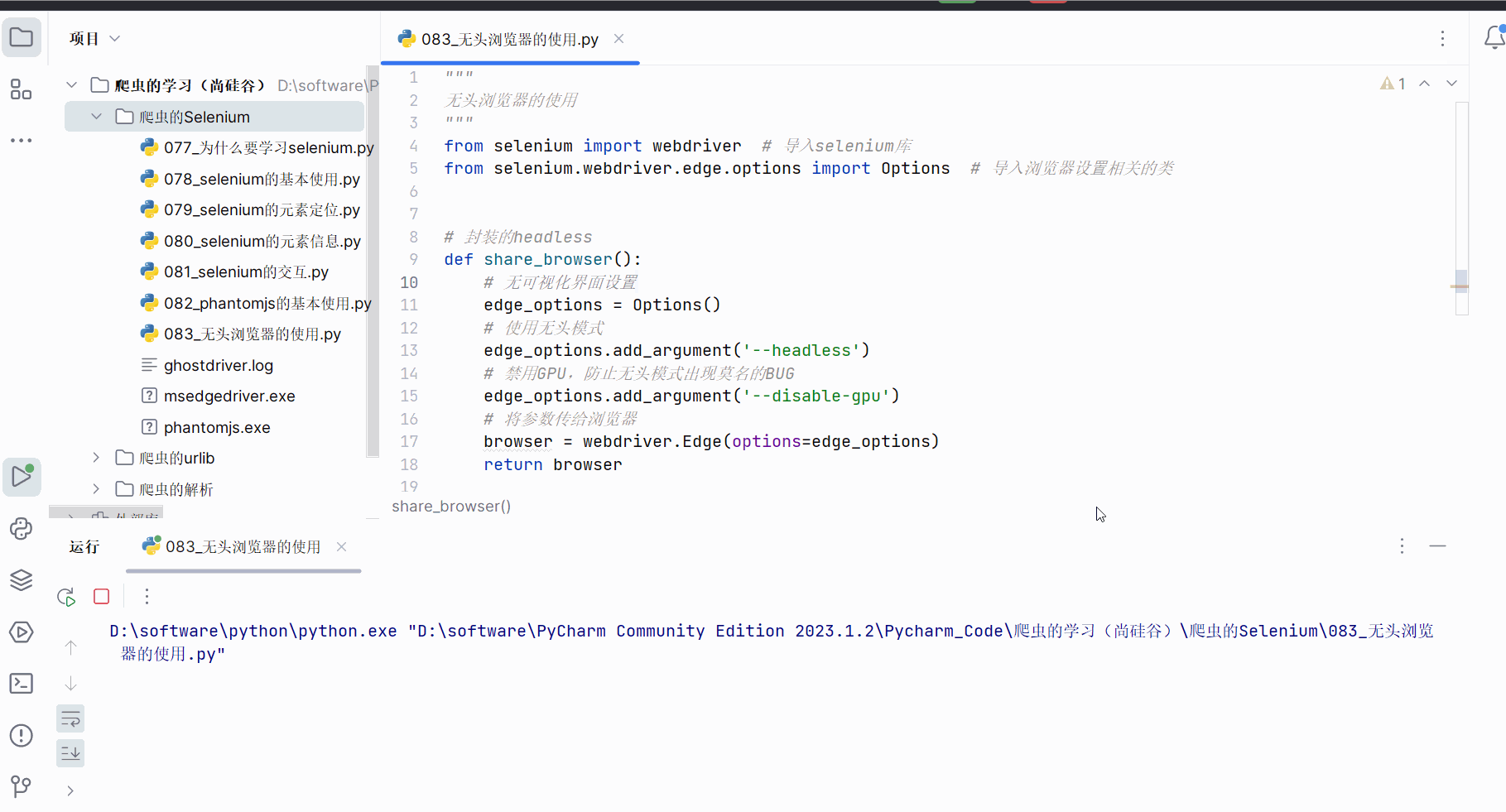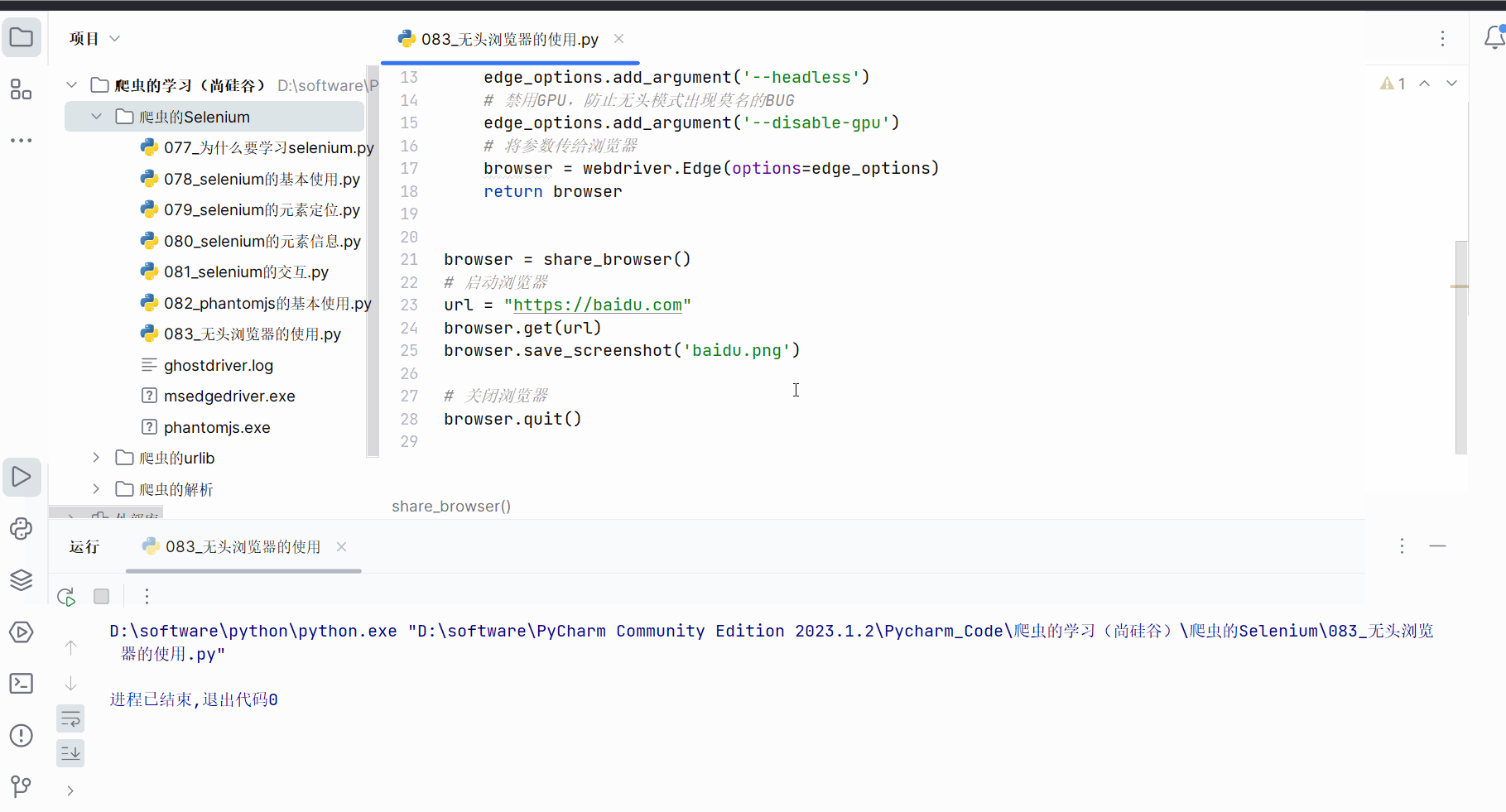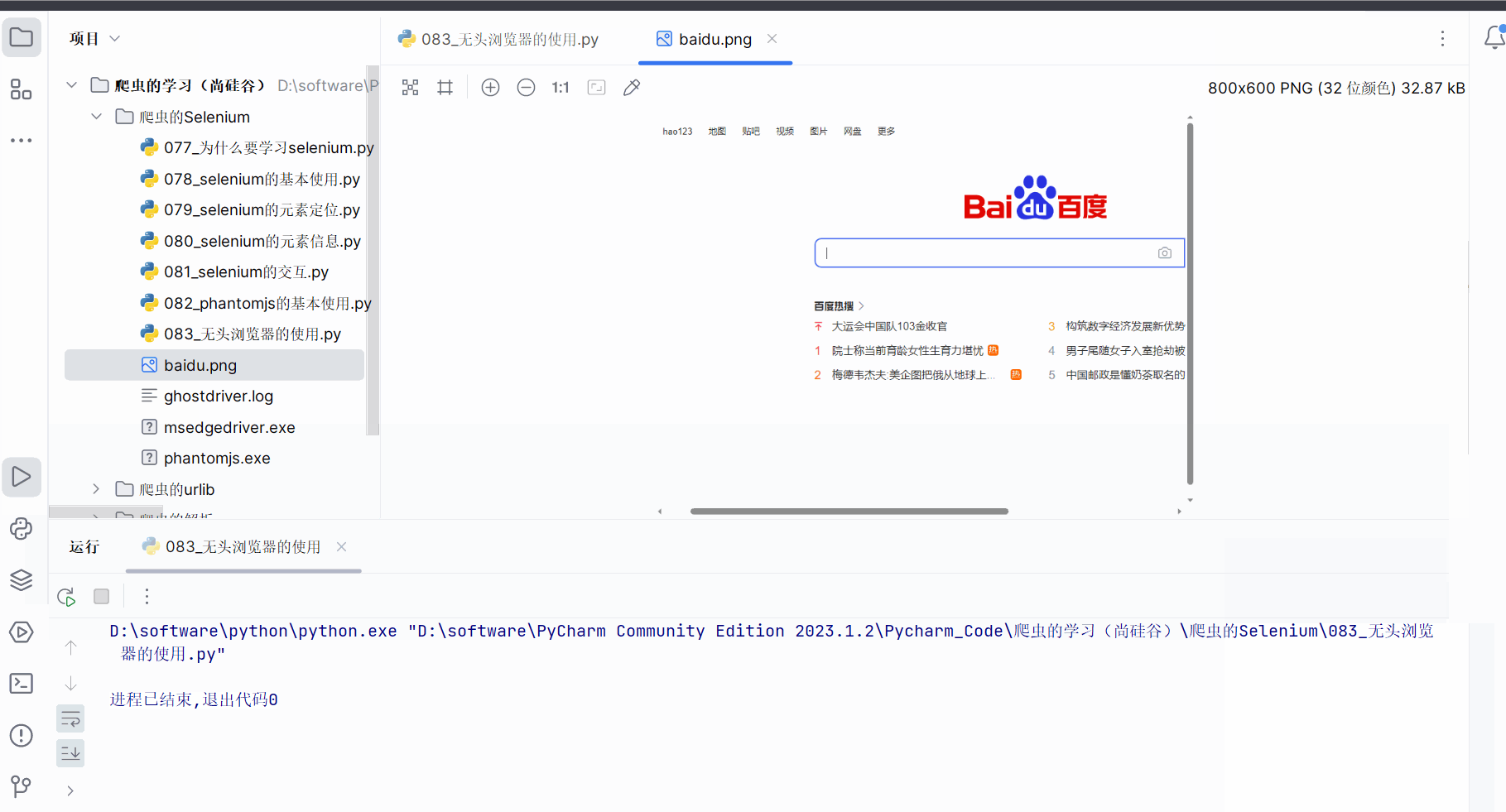
browser.save_screenshot('baidu.png')
# 关闭浏览器
browser.quit()
好了,本章的笔记到此结束,谢谢大家阅读。