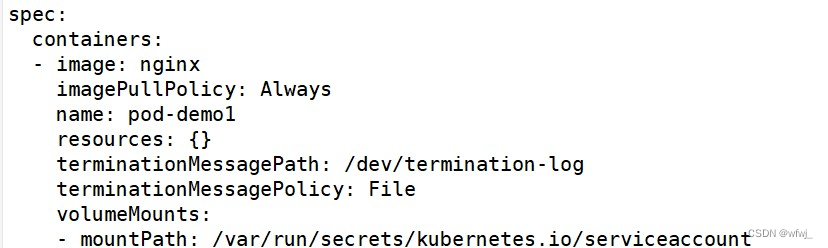
lz4算法
abcd efab cdeh
压缩过程:
以长度4为滑窗,1为步长,对abcd计算hash存入hash table,计算 bcde, cdef,defa,efab,fabc的 hash 分别加入 hash table,下一个滑窗 abcd 找到了匹配,于是扩大匹配,bcde 也有匹配,且start 位置是在abcd 之后1位,再扩大匹配,cdeh 没有匹配,所以匹配长度为5,向前偏移为6。
这时前面未出现匹配的abcedf就可以编码了,编码为0b01100000 (token) + abcdef,其中0110是未匹配字节的长度(6),如果未匹配长度为512,大于19(15 + 最小匹配长4),则token编码为0b11110000 0b11111111 0b 11101100(即 4 + 15(第一字节高4位) + 256 (第二字节)+ 237(第三字节)),前一部分编码为了token + abcdef。
后面匹配的abcde编码为0b00000110 (token) + 6(2byte),即0110(低4位表示匹配长度),后两个字节填充6。
编码的格式为

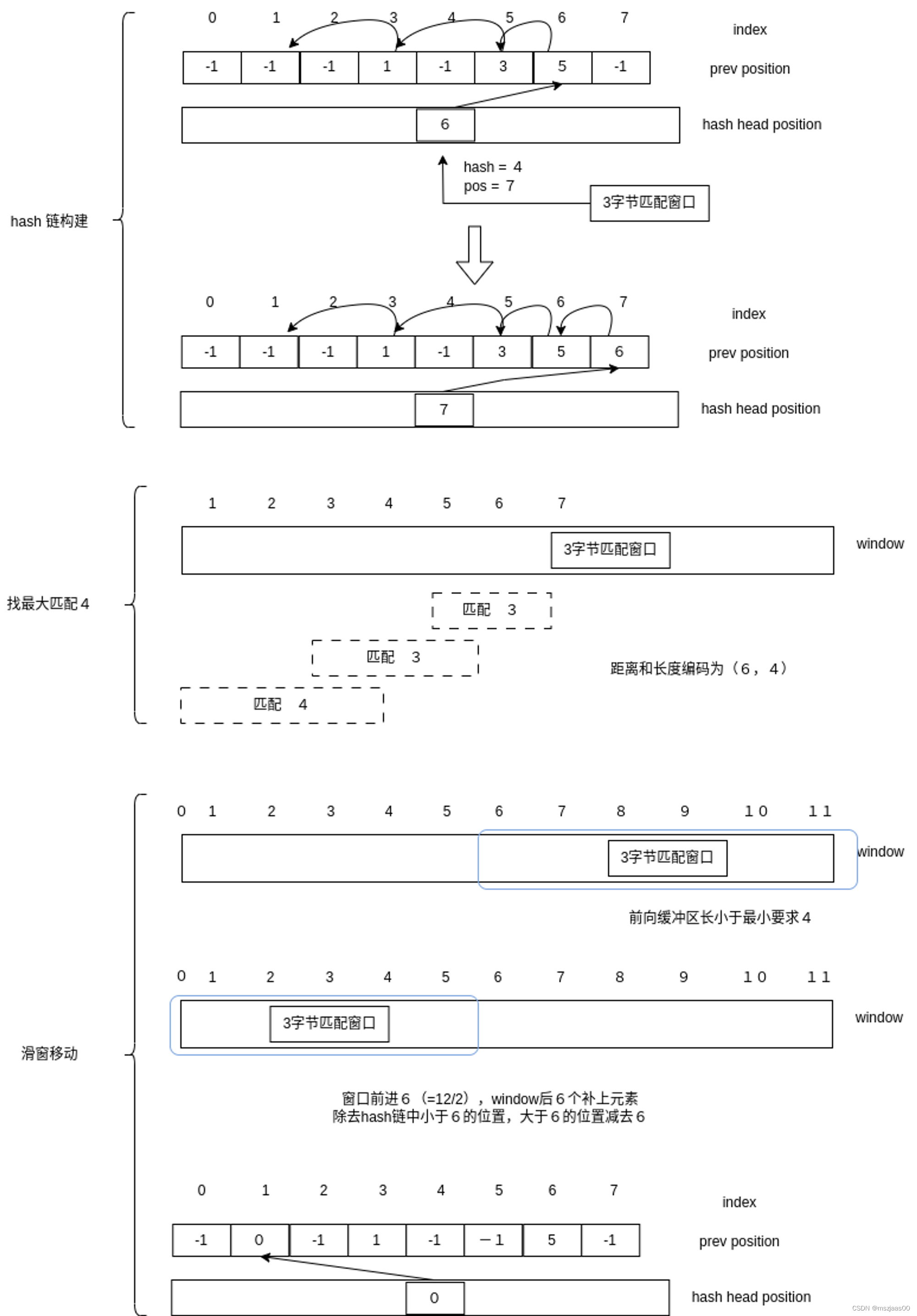
lz77 算法
在长度为2n窗口内,每3个字节求为一个hash值,以此来找在匹配的hash字符串链,hash表的字符串链中存的是当前窗口内字符串的位置。当滑窗中未读的部分长度小于阈值时,就把前一半丢掉,窗口向后移动一半长度。最后输出三个文件:
- 文件1:标记:0表示原字符,从文件2读1字节;1表示从文件3读距离,与这后面的长度组成一对,从前面解压的输出中去读。
- 文件2:原字符:(1字节)
- 文件3:距离:(两字节)