构建卷积神经网络
- 卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致
全连接层:batch784,各个像素点之间都是没有联系的。
卷积层:batch12828,各个像素点之间是有联系的。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
首先读取数据
- 分别构建训练集和测试集(验证集)
- DataLoader来迭代取数据
# 定义超参数
input_size = 28 #图像的总尺寸28*28
num_classes = 10 #标签的种类数
num_epochs = 3 #训练的总循环周期
batch_size = 64 #一个撮(批次)的大小,64张图片
# 训练集
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
# 测试集
test_dataset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# 构建batch数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
卷积网络模块构建
- 一般卷积层,relu层,池化层可以写成一个套餐
- 注意卷积最后结果还是一个特征图,需要把图转换成向量才能做分类或者回归任务
图像是二维卷积 conv2
视频是三维卷积 conv3
单向量是一维卷积 conv1
官网有关conv2d的输出宽度和长度的计算公式

class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)
nn.Conv2d(
in_channels=1, # 1:灰度图;3:RGB
out_channels=16, # 要得到几多少个特征图,即是卷积核的个数
kernel_size=5, # 卷积核大小
stride=1, # 步长
padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1
), # 输出的特征图为 (16, 28, 28)
nn.ReLU(), # relu层
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14)
)
self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)
nn.ReLU(), # relu层
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2), # 输出 (32, 7, 7)
)
self.conv3 = nn.Sequential( # 下一个套餐的输入 (32, 7, 7)
nn.Conv2d(32, 64, 5, 1, 2), # 输出 (64, 7, 7)
nn.ReLU(), # 输出 (64, 7, 7)
)
self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层得到的结果
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 64 * 7 * 7)
output = self.out(x)
return output
准确率作为评估标准
def accuracy(predictions, labels):
pred = torch.max(predictions.data, 1)[1]
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels)
训练网络模型
# 实例化
net = CNN()
#损失函数
criterion = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法
#开始训练循环
for epoch in range(num_epochs):
#当前epoch的结果保存下来
train_rights = []
for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环
net.train()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = accuracy(output, target)
train_rights.append(right)
if batch_idx % 100 == 0:
net.eval()
val_rights = []
for (data, target) in test_loader:
output = net(data)
right = accuracy(output, target)
val_rights.append(right)
#准确率计算
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
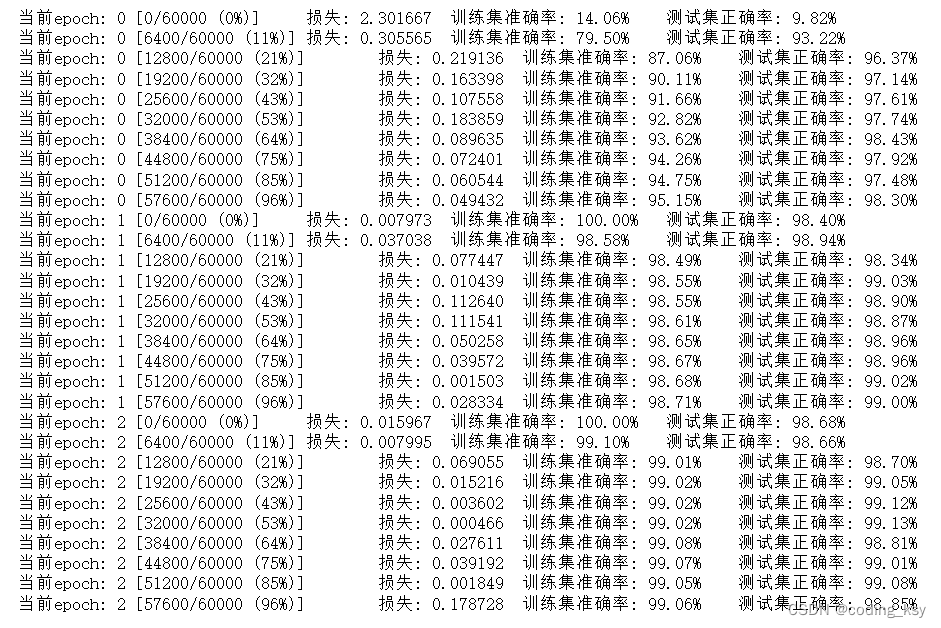
print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(
epoch, batch_idx * batch_size, len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.data,
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))
练习
- 再加入一层卷积,效果怎么样?
- 当前任务中为什么全连接层是3277 其中每一个数字代表什么含义