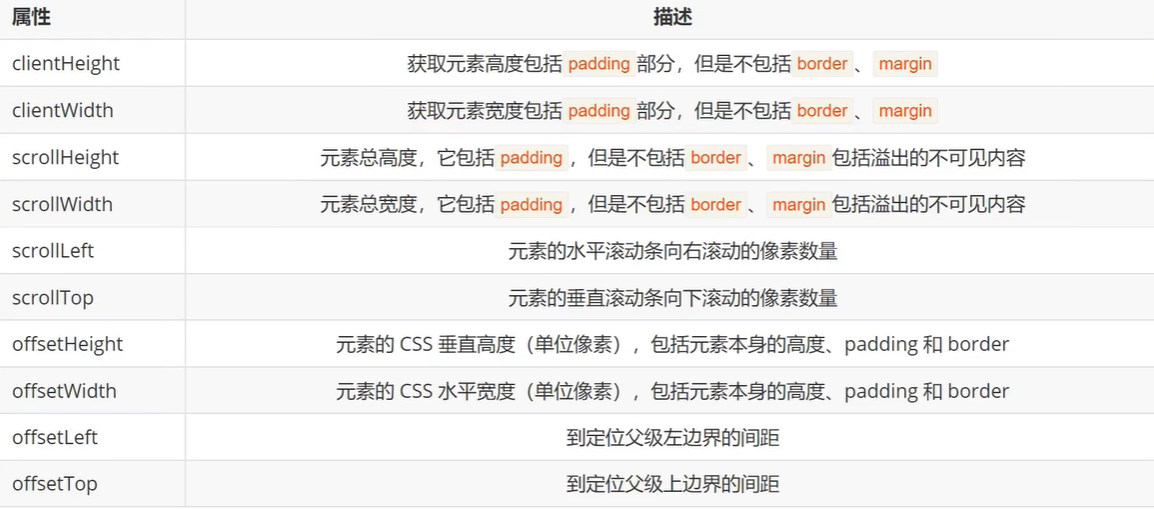
C-STS: Conditional Semantic Textual Similarity
语义文本相似度(STS):测量一对句子之间的相似程度。在本质上是一个模棱两可的任务,因为句子相似度取决于某一特定方面。
条件语义文本相似度(C-STS):测量在自然语言中阐明的一个方面(这里称为条件)的相似性。比STS的优点在于:1)减少了STS的主观性和模糊性;2)可以使用不同条件进行细粒度的相似性评估。
实例
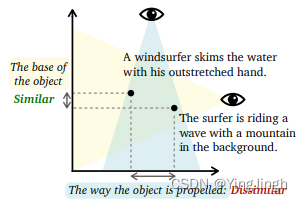
sentence 1 A windsurfer skims the water with his outstretched hand
sentence 2 The surfer is riding a wave with a mountain in the background.
根据 "物体的底座 "这一条件判断,这两个句子比较相似。(黄色),因为帆板运动和冲浪运动都使用类似的冲浪板,但从 "物体的推动方式 "这一条件来判断,这两个句子就不一样了。(蓝色),因为一个是由海浪推动,另一个是由风推动。
论文贡献
1 创建了C-STS-2023数据集,包含近20000个实力,其中包含句子对、条件和Likert scale上的标量相似性判断。
2 由于最前沿的模型在这个C-STS的任务上表现不佳,提出了新的tri-encoder模型和quadruplet training loss。该新的方法能够基于不同条件对同一句子对进行对比学习,并任务C-STS应该通过改进的架构和微调策略来解决。
3 定性分析表明,当对同一句子对的不同方面进行测试时,模型发现C-STS具有挑战性,而不是测试无条件和模糊的相似性概念。
语料库构建
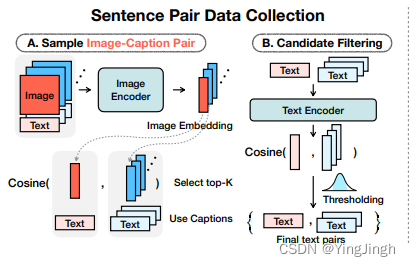
步骤 A:首先从数据集中抽取一对图像-标题(红色),然后将图像输入图像编码器,得到图像嵌入。将图像嵌入与数据集中的所有其他图像嵌入(蓝色)进行比较,找出前 K 个相似图像。然后将原始标题与前 K 张相似图片的相应标题配对,生成句子对。步骤 B:根据文本相似性过滤句子对。
条件相似度测评形式
a similarity assessment ({s1, s2, c,sim})
s1和s2是两个原始句子,c是condition,即条件,sim是相似度值。
损失函数
Quad损耗定义如下:
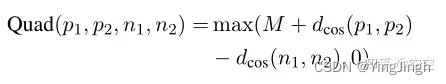
p1和p2是高相似度的句子对;n1和n2是低相似度的句子对。
我们使用均方误差(MSE), Quad以及Quad + MSE的线性组合来训练回归的所有任务
总结
不同方面去做相似度的评价,语料库的收集上是有一定技巧的,并不是完全从头开始。
损失函数构造上的思路,不是很理解,为什么没有设置为多任务形式而是将两个(high&low)的损失值放在一个损失函数里。
相似度也是评价角度之一,涉及到评价的,应该将结果单一值转向结果云的形式,其中论文中的条件,就是结果呈现的不同角度。