作者:Philipp Kahr

Elasticsearch Service 用户的重要注意事项:目前,本文中描述的 Kibana 设置更改仅限于 Cloud 控制台,如果没有我们支持团队的手动干预,则无法进行配置。 我们的工程团队正在努力消除对这些设置的限制,以便我们的所有用户都可以启用内部 APM。 本地部署不受此问题的影响。
对于任何使用 Elasticsearch 作为搜索引擎的人来说,识别查询并排除查询故障是一项需要掌握的关键技能。 无论是电子商务、可观察性还是面向工作场所的搜索解决方案,缓慢的 Elasticsearch 都会对用户体验产生负面影响。
要查明慢速 Elasticsearch 查询,你可以使用慢速日志,它捕获在特定阈值运行的查询。 正确设置慢日志阈值本身就是一个挑战。 例如,在满负载下花费 500 毫秒的查询可能是可接受的,但在低负载下相同的查询可能是不可接受的。 慢日志不区分并记录 500 毫秒以上的所有内容。 慢日志很好地完成了它的工作,你可以根据阈值捕获不同级别的粒度。 相反,跟踪可以查看所有查询,确定有多少查询在特定阈值内。
应用程序性能监控 (APM) 不再仅限于你的应用程序。 使用 Elasticsearch 中的检测,我们现在可以将 Elasticsearch 添加为成熟的服务,而不是对应用程序堆栈的依赖。 通过这种方式,我们可以获得比慢速日志更细致的性能视图。
对于以下示例,我们的数据语料库是 OpenWebText,它提供大约 40GB 的纯文本和大约 800 万个单独文档,这些文档在具有 32GB RAM 的 M1 Max Macbook 上本地运行。
让我们开始吧!
在 Elasticsearch 中激活跟踪是通过静态设置(在 elasticsearch.yml 中配置)和动态设置完成的,可以在运行时使用 PUT _cluster/settings 命令进行切换,其中动态设置之一是采样率。 某些设置(例如采样率)可以在运行时切换。 在 elasticsearch.yml 中我们要设置以下内容:
tracing.apm.enabled: true
tracing.apm.agent.server_url: "url of the APM server"秘密令牌(或 API 密钥)必须位于 Elasticsearch 密钥库中。 使用以下命令 elasticsearch-keystore add Tracing.apm.secret_token 或 Tracing.apm.api_key 应该可以在 <your elasticsearch install directory>/bin/elasticsearch-keystore 中找到密钥库工具。 之后,你需要重新启动 Elasticsearch。 有关跟踪的更多信息可以在我们的跟踪文档中找到。
一旦 APM 处于活动状态,我们就可以查看 Kibana 中的 APM 视图,并看到 Elasticsearch 自动捕获各种 REST API 端点。 在这里,我们主要关注 POST /{index}/_search 调用,看看我们能从中获得什么。

通过直接检查 GET /{index}/_search 框上的简单查询,我们看到以下瀑布细分。 其中包含内部跨度(span),可以更深入地了解 Elasticsearch 在幕后所做的事情。 我们看到这次搜索的总持续时间(86 毫秒)。
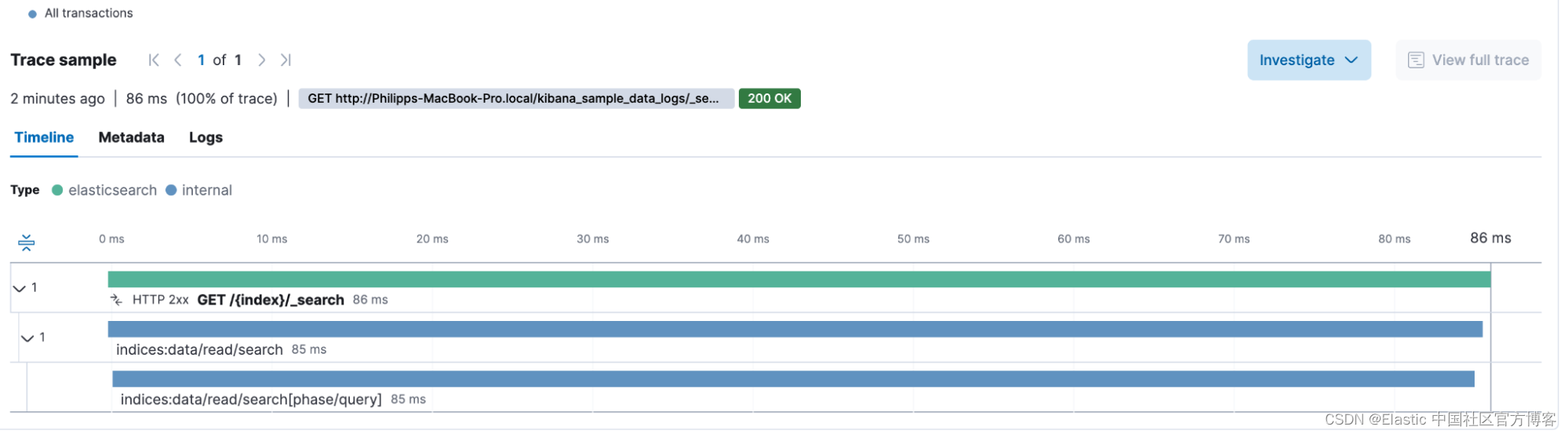
查询附带的元数据包括有关 HTTP 标头、用户代理、Elasticsearch 节点位置(云提供商元数据、主机名、容器信息)、一些系统信息和 URL 详细信息的大量信息。 使用一些基本的交易信息,我们可以创建一个透镜图,绘制平均交易持续时间,并允许我们查看是否存在上升或下降趋势。
我们的搜索应用程序
很高兴不再需要使用慢日志! 我可以确定交易持续时间并确定在任何阈值下回答了多少搜索。 然而,有一个挫折 —— Elasticsearch 不会捕获发送的查询(查询的具体内容是什么),因此我们知道查询花费了很长时间,但我们不知道查询是什么。
让我们测试一个示例搜索应用程序。 在本例中,我们将使用一个简单的 Flask 应用程序,其中包含两个路由:search_single 和 search_phrase,它们将表示 Elasticsearch 中的 match 和 match_phrase 查询。 例如,我们可以使用以下查询:
{
"query": {
"match": {
"content": "support"
}
}
}及
{
"query": {
"match_phrase": {
"content": "support protest"
}
}
}以下 Flask 代码实现了 search_single 路由。 search_phrase 非常相似,只是它使用 match_phrase 而不是 match。
@app.route("/search_single", methods=["GET"])
def search_single():
query = request.args.get("q", "")
if not query.strip():
return jsonify({"error": "No search query provided"}), 400
try:
result = es.search(
index=ES_INDEX, query={"match": {"content": query}}
)
hits = result["hits"]["hits"]
response = []
for hit in hits:
response.append(
{
"score": hit["_score"],
"content": hit["_source"]["content"],
}
)
return jsonify(response)准备就绪后,我现在可以调用 curl -XGET “http://localhost:5000/search_single?q='microphone'” 来搜索术语 “microphone”。
我们主要将 APM 添加到我们的搜索应用程序中进行观察,但我们的 APM 代理捕获传出请求并使用元数据信息丰富它们。 在我们的例子中,span.db.statement 包含 Elasticsearch 查询。 在下面这个例子中,有人搜索了 window.
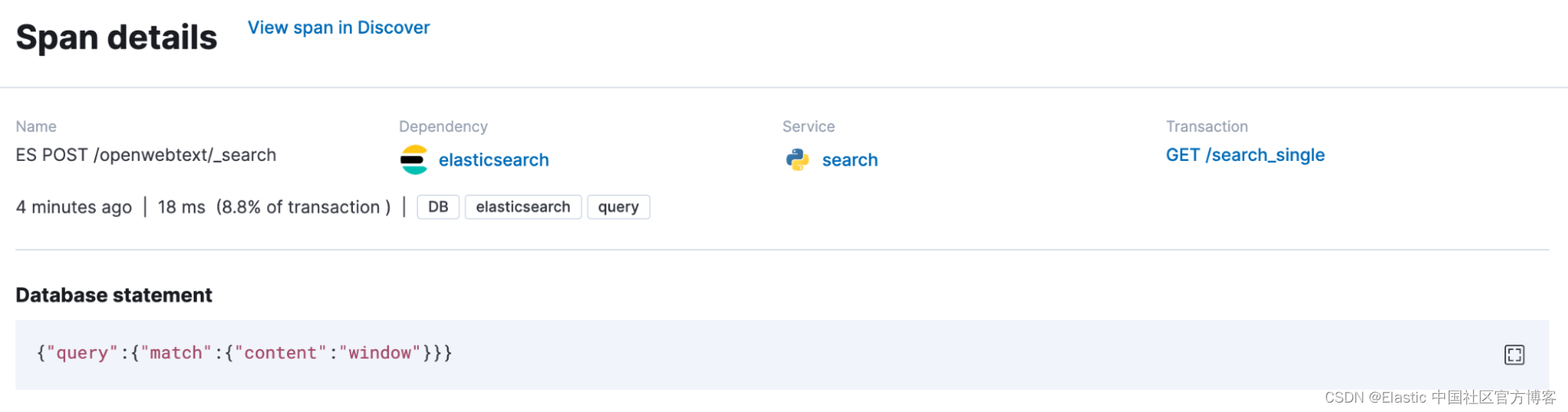
将它们拼凑在一起
在我的 Flask 服务中,我将查询大小设置为 5,000,这意味着 Elasticsearch 应在单个 JSON 响应中为我提供最多 5,000 个匹配文档。 这是一个很大的数字,并且大部分时间都花在从磁盘检索这么多文档上。 将其更改为前 100 个文档后,我可以通过比较快速识别仪表板中发生的情况。
在 APM 视图中查看 transaction 并激活关键路径的实验室功能会创建一个覆盖层,向我们显示应用程序将时间花在哪里。
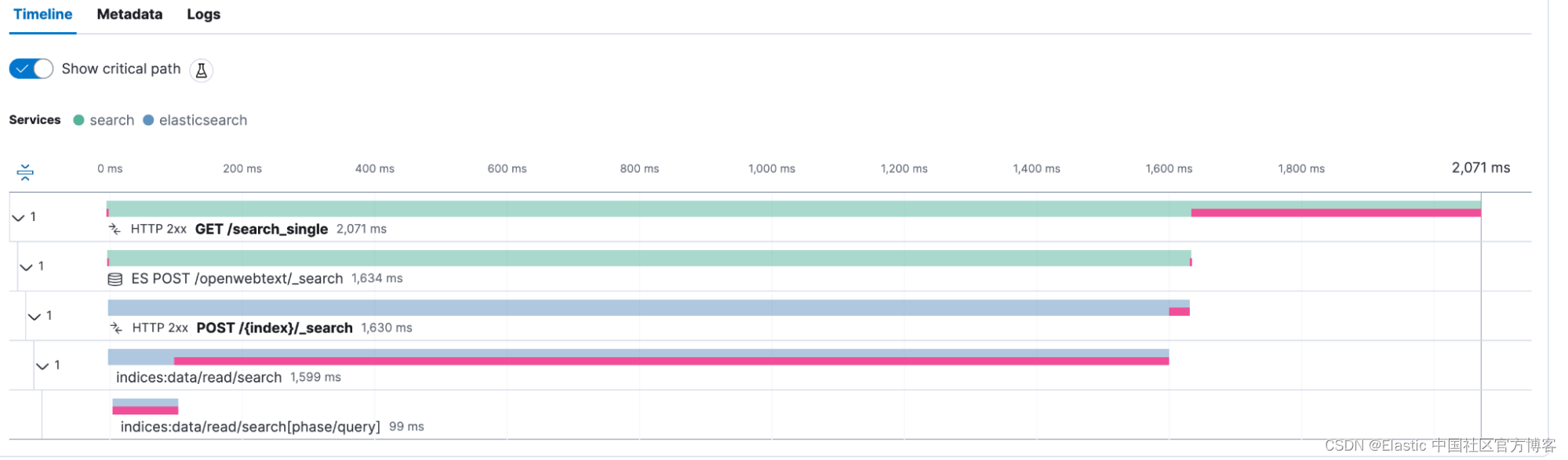
之后,我使用字段 transaction.duration.us、es_query_took、transaction.name 创建了一个仪表板。 一般 KQL 过滤器包含 service.name、processor.event: transaction、transaction.name: POST /{index}/_search。
附加提示:转到数据视图管理 > 选择包含 APM 数据流的数据视图 > 选择 transaction.duration.us 字段 > 并将格式更改为 duration。 现在它会自动以人类可读的输出而不是 microseconds 的形式呈现它。
利用 Lens 注释(annotation)功能,我们可以在中间 Lens 中看到,更改为 100 个文档使平均搜索 transaction 量下降了很多。 不仅如此,查看右上角的记录总数。 由于我们可以更快地搜索,因此我们有更高的吞吐量! 我真的很喜欢直方图,因此我在顶行的中间创建了一个直方图,其中 X 轴为交易持续时间,Y 轴为记录数。 此外,APM 还提供指标,因此我们可以随时确定发生了多少 CPU% 使用情况以及 JVM 堆、非堆使用情况、线程计数和更多有用信息。
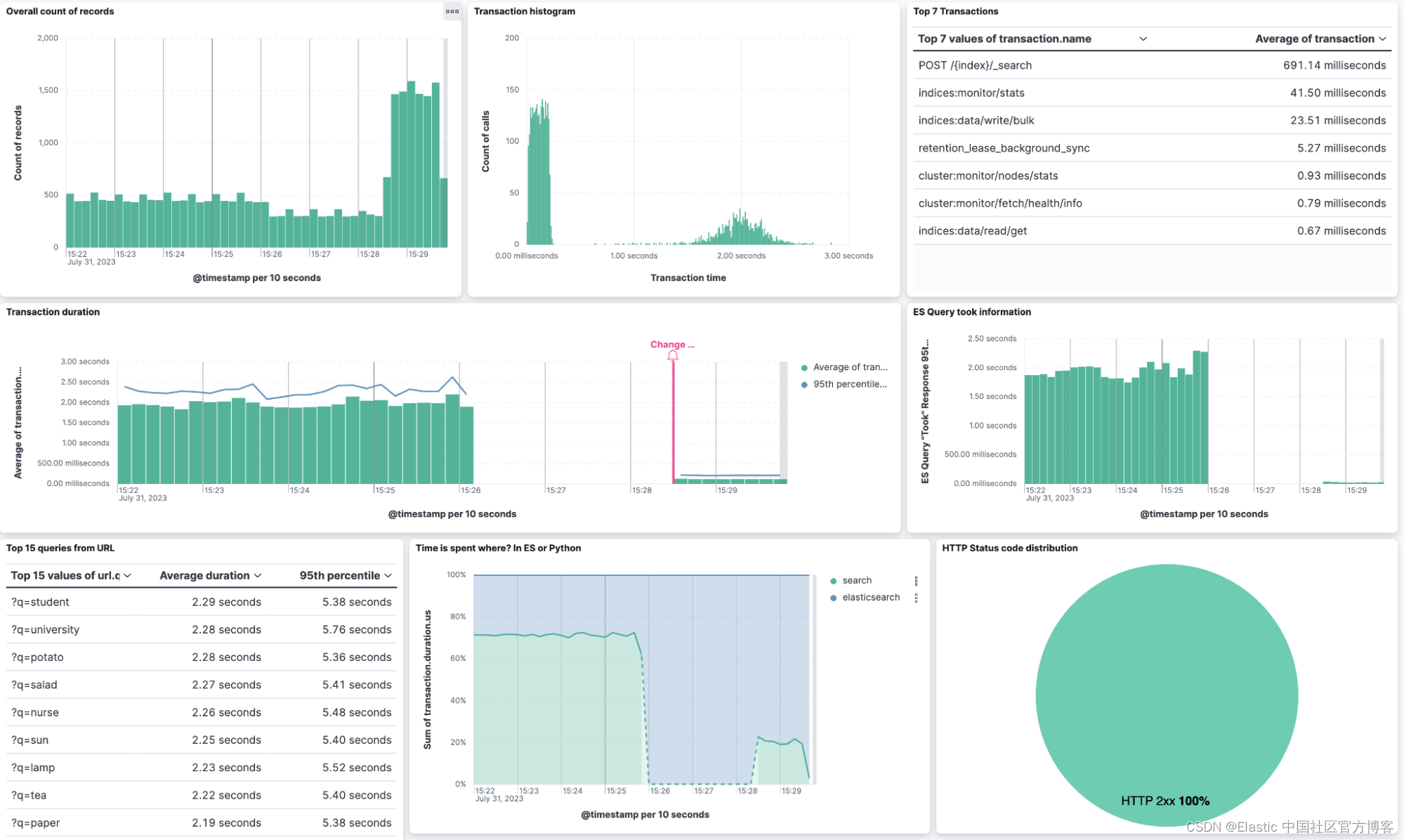
结论
这篇博文向您展示了将 Elasticsearch 作为仪表化应用程序并更轻松地识别瓶颈是多么重要。 此外,你还可以使用事务持续时间作为异常检测的指标,为你的应用程序进行 A/B 测试,并且再也不用怀疑 Elasticsearch 是否感觉更快,因为你现在有数据可以回答这个问题。 此外,从用户代理收集到查询的所有元数据都可以帮助你排除故障。
可以从此处导入仪表板和数据视图。
警告
Elasticsearch 内部的 transaction duration 存在问题。 此问题已在即将发布的 8.9.1 版本中修复。 在此之前,transaction 使用错误的时钟,这会扰乱整体持续时间。本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:How to troubleshoot slow Elasticsearch queries for better user experience | Elastic Blog