今天我们来复现一篇16分左右的使用了孟德尔随机化方法的文章,文章的题目是:A multivariable Mendelian randomization analysis investigating smoking and alcohol consumption in oral and oropharyngeal cancer(研究口腔癌和口咽癌吸烟和饮酒的多变量孟德尔随机化分析)

这是一篇老外的文章,咱们试着复现一下文章的数据和图表,和上一篇一样,作者和上一篇一样也是给咱们提供了详尽的数据和R的代码,我们可以跟着作者的思路进行一个复盘。
作者研究的是吸烟和喝酒对口腔癌症的影响,作者指出,吸烟和饮酒对头颈癌的独立影响尚不清楚。既往的观察性研究中报告的它们明显的协同效应也可能低估了独立效应。最后作者的结论是:吸烟和喝酒每一样都会增加口腔癌的风险。
作者有几个数据来源,分别是GSCAN、 GSCAN without UK Biobank、UK Biobank、UK Biobank。作者在文章中直接给出了数据,我在这里就直接使用了。
作者先是分别在这4个数据库中对吸烟和口腔癌,饮酒和口腔癌进行了分析。作者先做的是单变量的MR分析,我们先来演示单变量的。
我这里就演示GSCAN数据库了,其他数据库的做法完全一样。我们先看看作者给出的表格1
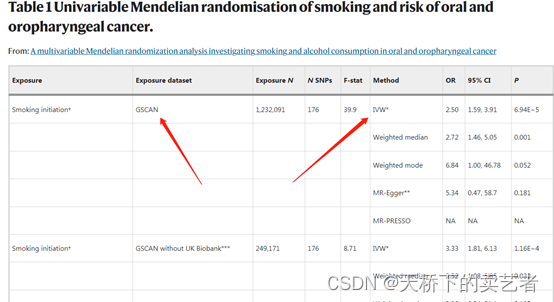
GSCAN数据库中吸烟对口腔癌的OR是2.5,我们来复现一下,先导入R包和数据,数据SI_exposure.csv对应的是GSCAN数据库。
library(TwoSampleMR)
library(MRInstruments)
library(MVMR)
library(MRPRESSO)
exposure_dat <-read_exposure_data("SI_exposure.csv", sep=",", samplesize_col = "N")
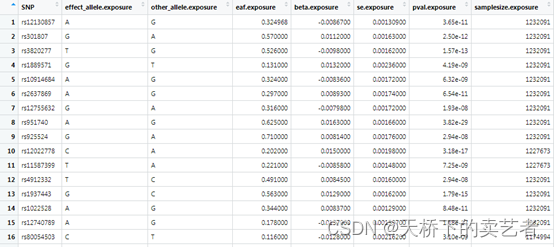
导入数据后需要使用clump_data函数处理一下,主要是挑选P值比较低的SNP,这和在线下载数据的步骤是一样的
exposure_dat <- clump_data(exposure_dat)
读入结局数据,也就是口腔癌的数据
outcome_dat <- read_outcome_data("smandalc_hnc.txt", sep="\t")
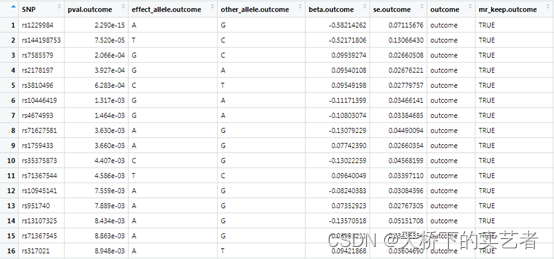
接下来效应等位与效应量保持统一,这一步是必须的,
dat <- harmonise_data(exposure_dat, outcome_dat)
添加两个列名
dat$exposure <- "smoking initiation"
dat$outcome <- "oral/oropharyngeal cancer"
使用mr_keep进行筛选,其实这步是多余的,因为进行MR分析的时候也是有这一步的
dat <- dat[dat$mr_keep=="TRUE",]
进行MR分析,并求出系数
mr_results <- mr(dat)
or_results <- generate_odds_ratios(mr_results)
or_results

我们可以看到上图的OR是2.5和作者的表格是一致的,其他结果也是一致的,所以咱们算是复原了这个结果。作者还做了个mr_presso多水平效应分析,代码是
dat <- dat[dat$mr_keep=="TRUE",]
mr_presso(BetaOutcome = "beta.outcome", BetaExposure = "beta.exposure", SdOutcome = "se.outcome", SdExposure = "se.exposure", data=dat, OUTLIERtest = TRUE, DISTORTIONtest = TRUE, NbDistribution = 10000, SignifThreshold = 0.05)
不过这个代码我没跑出来,我见作者也没跑出来。
刚才是吸烟的,下面我们来看看喝酒对口腔癌的影响。也是以GSCAN数据来复原
先导入数据,这里步骤和吸烟差不多的,我直接上代码了,喝酒这里的数据是DPW_exposure.csv数据,表格的结果见下图
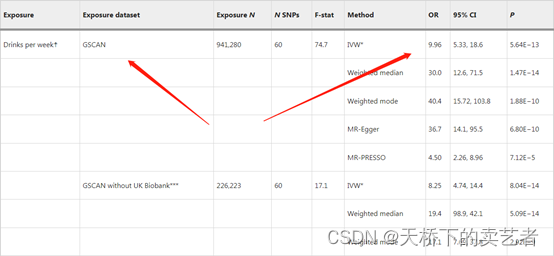
喝酒这部分的代码和吸烟的差不多
exposure_dat <-read_exposure_data("DPW_exposure.csv", sep=",", samplesize_col = "N")
exposure_dat <- clump_data(exposure_dat)
outcome_dat <- read_outcome_data("smandalc_hnc.txt", sep="\t")
dat <- harmonise_data(exposure_dat, outcome_dat)
dat <- dat[dat$mr_keep=="TRUE",]
dat$outcome <- "Head and neck cancer"
mr_results <- mr(dat)
or_results <- generate_odds_ratios(mr_results)

我们可以看到,结果是9.96,和作者列出的表格也是一样的。
作者还做了一个按癌症部位分层的比较图(下图)

我就拿吸烟来表示,这个图其实做起来思路很简单,把结果剔出来分析就可以了,就拿a图来说,我们把我们首先收集吸烟的暴露这部分SNP,把口腔癌和口咽癌的结果分别和它比较就行了,所以应该分两部进行。
口腔癌的,关键的代码是outcome_dat$SNP %in% exposure_dat$SNP这句,结果部分取了暴露部分的子集。
exposure_dat <-read_exposure_data("SI_exposure.csv", sep=",", samplesize_col = "N")
exposure_dat <- clump_data(exposure_dat)
outcome_dat <- read_outcome_data("smandalc_oc.txt", sep="\t")
outcome_dat <- outcome_dat[outcome_dat$SNP %in% exposure_dat$SNP,]
dat <- harmonise_data(exposure_dat, outcome_dat)
SI_SNPs <- as.character(dat$SNP[dat$mr_keep=="TRUE"])
dat$exposure <- "smoking initiation"
dat$outcome <- "oral cancer"
dat <- dat[dat$mr_keep=="TRUE",]
mr_results <- mr(dat)
mr_results
or_results <- generate_odds_ratios(mr_results)
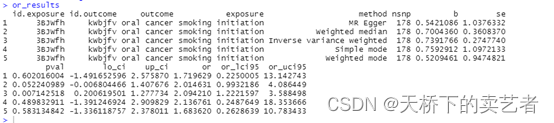
口咽癌的,可以看到smandalc_oc.txt和smandalc_opc.txt是两个不同的结局数据,其他部分的代码完全相同。
exposure_dat <-read_exposure_data("SI_exposure.csv", sep=",", samplesize_col = "N")
exposure_dat <- clump_data(exposure_dat)
outcome_dat <- read_outcome_data("smandalc_opc.txt", sep="\t")
outcome_dat <- outcome_dat[outcome_dat$SNP %in% exposure_dat$SNP,]
dat <- harmonise_data(exposure_dat, outcome_dat)
SI_SNPs <- as.character(dat$SNP[dat$mr_keep=="TRUE"])
dat$exposure <- "smoking initiation"
dat$outcome <- "oropharyngeal cancer"
dat <- dat[dat$mr_keep=="TRUE",]
mr_results <- mr(dat)
mr_results
or_results <- generate_odds_ratios(mr_results)

因为要汇总很多数据,工作量比较大,这个图我就不画了,汇总好数据后,画起来也是很简单的。
前面讲了单变量的MR分析,下面来介绍一下多变量的孟德尔随机化分析(MVMR)。我们先看一下作者的数据表格。
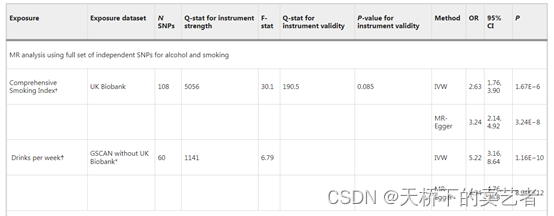
作者分析了两个指标,一个是吸烟指数、第二个是每周饮酒量,对这两个指标进行多变量分析,多变量孟德尔随机化考虑了两个变量的相互影响,简单来说可以把另外的当做混杂因素。作者文章中已经说明了怎么提取数据,我这里直接用了。
我们先把暴露变量导入看一下,数据有2个暴露因素,吸烟指数和每周饮酒
XGs <- read.csv("MVMR_dpwandcsi.csv")
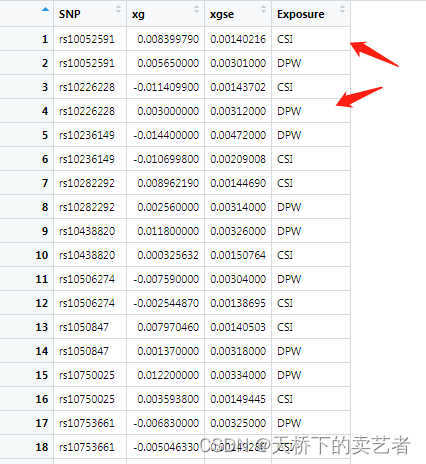
Y结局也导进来看一下
YG <- read.csv("MVMR_dpwandcsi_hnc.csv")

作者引用了一个综合吸烟指数 (CSI) 数据,把将 CSI 和 DPW 分别限制为 108 个 SNP 和 60 个 SNP。
CSI_DPW_SNPs <- read.csv("CSI_DPW_SNPs.csv")
XGs <- XGs[XGs$SNP %in% CSI_DPW_SNPs$SNP,]
YG <- YG[YG$SNP %in% CSI_DPW_SNPs$SNP,]
接下来要对暴露因素这里的数据处理一下,主要就是把长数据变成宽数据,效应值和可信区间都要处理,处理后的格式见下图
library(tidyr)
XGs_betas <- XGs[,c(1:2,4)]
XGs_betas <- spread(XGs_betas, Exposure, xg)
XGs_se <- XGs[,c(1,3:4)]
XGs_se <- spread(XGs_se, Exposure, xgse)
接下来是删掉数据中的缺失值
XGs_betas <- na.omit(XGs_betas)
XGs_se <- na.omit(XGs_se)
下面这一步主要的目前是取暴露和结局中相同的SNP,这样一来YG和XGs_betas的SNP就相等了
YG <- YG[YG$SNP %in% XGs_betas$SNP,]
XGs_betas <- XGs_betas[XGs_betas$SNP %in% YG$SNP,]
XGs_se <- XGs_se[XGs_se$SNP %in% YG$SNP,]

给它们进行排序
XGs_betas <- XGs_betas[order(XGs_betas$SNP),]
XGs_se <- XGs_se[order(XGs_se$SNP),]
YG <- YG[order(YG$SNP),]
分析前还要进行一个格式化
mvmr <- format_mvmr(XGs_betas[,c(2:3)], YG$yg, XGs_se[,c(2:3)], YG$ygse, XGs_betas$SNP)
最后进行分析
IVW分析
mr_mvivw <- mr_mvivw(mr_mvinput(bx = cbind(XGs_betas$DPW, XGs_betas$CSI), bxse = cbind(XGs_se$DPW, XGs_se$CSI), by = YG$yg, YG$ygse))
egger分析
mr_mvegger <- mr_mvegger(mr_mvinput(bx = cbind(XGs_betas$DPW, XGs_betas$CSI), bxse = cbind(XGs_se$DPW, XGs_se$CSI), by = YG$yg, YG$ygse), orientate = 1)
得出饮酒的结果
mvmr_results_DPW <- c(exp(mr_mvivw$Estimate[1]), exp(mr_mvivw$CILower[1]), exp(mr_mvivw$CIUpper[1]), mr_mvivw$Pvalue[1], exp(mr_mvegger$Estimate[1]), exp(mr_mvegger$CILower.Est[1]), exp(mr_mvegger$CIUpper.Est[1]), mr_mvegger$Pvalue.Est[1])
mvmr_results_DPW <- c(format(mvmr_results_DPW, scientific=F))
names(mvmr_results_DPW) <- c("IVW_OR", "IVW_CIL", "IVW_CIU", "IVW_P", "Egger_OR", "Egger_CIL", "Egger_CIU", "Egger_P")

得出吸烟的结果,在作者文中交代:要获得每个标准偏差增加的结果,请将β和se乘以0.6940093。至于为什么是0.694,我也不明白,有大佬能私信告诉我吗?
mvmr_results_CSI <- c(exp(mr_mvivw$Estimate[2]*0.6940093), exp(mr_mvivw$CILower[2]*0.6940093), exp(mr_mvivw$CIUpper[2]*0.6940093), mr_mvivw$Pvalue[2], exp(mr_mvegger$Estimate[2]*0.6940093), exp(mr_mvegger$CILower.Est[2]*0.6940093), exp(mr_mvegger$CIUpper.Est[2]*0.6940093), mr_mvegger$Pvalue.Est[2])
mvmr_results_CSI <- c(format(mvmr_results_CSI, scientific=F))
names(mvmr_results_CSI) <- c("IVW_OR", "IVW_CIL", "IVW_CIU", "IVW_P", "Egger_OR", "Egger_CIL", "Egger_CIU", "Egger_P")

因此,吸烟的OR是2.62,饮酒的OR是5.22.和作者的结果一样。
表示为控制饮酒后,吸烟会导致口腔癌发生率增加2.62倍,控制吸烟后,饮酒会导致口腔癌发生率增加5.22倍.
得出了OR和可信区间,画图就简单多了,我就不画了,写到这里已经很累了。还有一些孟德尔随机分析的图生成,可以看我既往的文章。
最后我个人总结一下自己的看法,孟德尔随机化分析要想发高分,主要还是在前期自己大量的数据收集和汇总,代码不是很难,一定要像文章中做多个数据库的,最好同时做单变量和多变量的。