索引上部分 -> Mysql进阶(上) -- 存储引擎,索引_千帐灯无此声的博客-CSDN博客
👂 爸爸妈妈 - 王蓉 - 单曲 - 网易云音乐
👈目录看左栏
目录
🌼索引
🐻性能分析 - show profiles
🐻性能分析 - explain
🍌使用规则 - 验证索引效率
🍌使用规则 - 最左前缀法则
🍌使用规则 - 索引失效情况1
🍌使用规则 - 索引失效情况2
🍌使用规则 - SQL提示
🍌使用规则 - 覆盖索引&回表查询
🍌使用规则 - 前缀索引
🍌使用规则 - 单列&联合索引
🍉设计原则
🍉小结
🌼索引
🐻性能分析 - show profiles
开关未开启👇
打开开关👇



突然,出现了BUG👇
为此我专门写了一篇文章 -> Finalshell连接Linux超时之Connection timed out: connect_千帐灯无此声的博客-CSDN博客

开关打开后,开始查询👇

查看每一条SQL语句的耗时👇
根据name查询比根据id查询慢很多👆
查询指定SQL语句👇
查询指定SQL语句CPU使用情况👇



🐻性能分析 - explain
Datagrip,创建3个表👇

use itcast;
create table student(
id int auto_increment comment '主键ID' primary key,
name varchar(10) null comment '姓名',
no varchar(10) null comment '学号'
)comment '学生表';
INSERT INTO student (name, no) VALUES ('黛绮丝', '2000100101');
INSERT INTO student (name, no) VALUES ('谢逊', '2000100102');
INSERT INTO student (name, no) VALUES ('殷天正', '2000100103');
INSERT INTO student (name, no) VALUES ('韦一笑', '2000100104');
create table course(
id int auto_increment comment '主键ID' primary key,
name varchar(10) null comment '课程名称'
)comment '课程表';
INSERT INTO course (name) VALUES ('Java');
INSERT INTO course (name) VALUES ('PHP');
INSERT INTO course (name) VALUES ('MySQL');
INSERT INTO course (name) VALUES ('Hadoop');
create table student_course(
id int auto_increment comment '主键' primary key,
studentid int not null comment '学生ID',
courseid int not null comment '课程ID',
constraint fk_courseid foreign key (courseid) references course (id),
constraint fk_studentid foreign key (studentid) references student (id)
)comment '学生课程中间表';
INSERT INTO student_course (studentid, courseid) VALUES (1, 1);
INSERT INTO student_course (studentid, courseid) VALUES (1, 2);
INSERT INTO student_course (studentid, courseid) VALUES (1, 3);
INSERT INTO student_course (studentid, courseid) VALUES (2, 2);
INSERT INTO student_course (studentid, courseid) VALUES (2, 3);
INSERT INTO student_course (studentid, courseid) VALUES (3, 4);Datagrip中,右键student_course,打开Diagram可视化👇
3张表联查,需要2个where来消除无效笛卡尔积👇
查询所有学生选修的课程👇
查询连接顺序👇
查询选修了Mysql的学生👇(1)分3步实现
(2)子查询1步实现👇





类似的,自己可以再写一个,查询韦一笑选修了什么课程👇
先逐步拆分👇
再子查询👇 -- 书写顺序是:先进入course表,再进入中间表,最后进入student表
(1)course
(2)student_course
(3)student



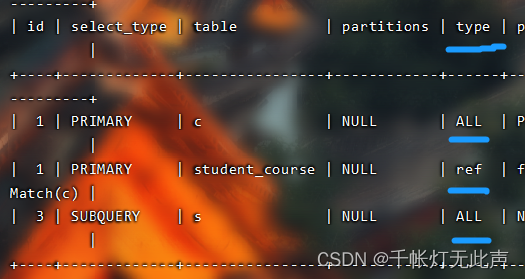
再用explain / desc看看执行顺序👇
但是执行顺序和书写顺序不同
执行顺序,先执行内层,也就是先student,再course,最后中间表
id越大,越先执行;id相同,按顺序执行

explain各字段含义👇
再讲下type👇
根据 主键 或 唯一索引 访问,才会出现const👇比如
唯一索引👇
所以select时,尽量防止出现all,all代表全表扫描,性能较低




再讲下possible_key
最后讲下👇





需要重点关注的字段👇
尤其是type,作为性能指标

🍌使用规则 - 验证索引效率
加个 \G ,查询字段以 row 的方式显示


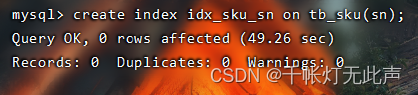
执行show index from tb_sku; 后,发现没有 sn 的索引,所以查询1条记录的时间相当于查询 * 的时间,下面我们需要创建 sn 的索引👇
创建耗时 49s ,因为创建索引,实际上是给 800万条数据,构造B+Tree的过程
再次查询👇
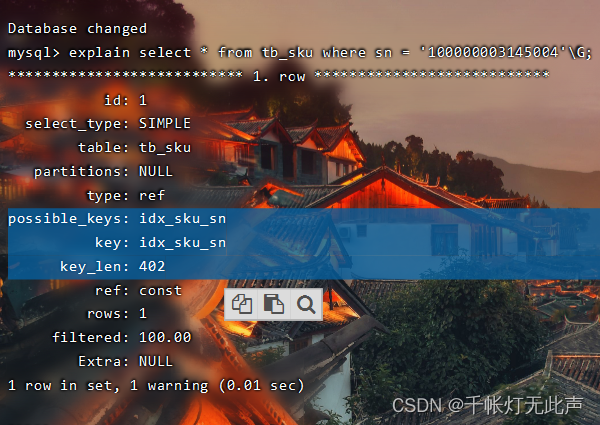
从 18s 提升到了 0.02s
接着explain查看索引👇
sn 这个字段使用了索引


🍌使用规则 - 最左前缀法则
不跳过索引中的列👆
show index👇可以看到3个索引的顺序
查询👇
去掉结尾 status 再次查询👇
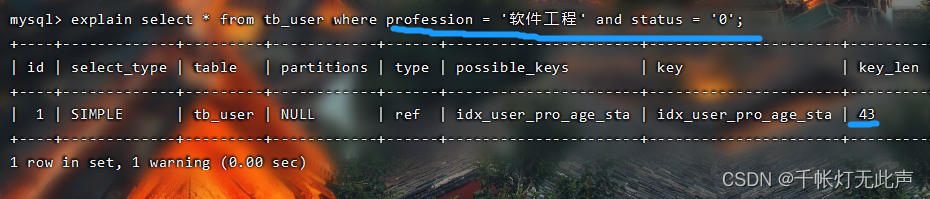
👆最左边的字段 profession 存在,并且没有跳过中间的列
继续查询
这次跳过 profession(索引最左边的列),索引全部失效👇
而且 type = all,全表扫描👆,因为不满足最左前缀法则






进行个对比
(1)
(2)
索引长度一样,说明(1)没有走 status 的索引,因为不满足最左前缀法则,中间跳过了 age 的索引,所以索引部分失效
possible_keys可能的索引,key实际使用的索引

当顺序改变时,索引长度不变,满足最左前缀法则👇

除了 最左前缀法则,还有 范围查询👇
(1)由索引长度,status 失效了
(2)当 > 改成 >= , status生效
所以,一般业务中,尽量使用 >=, <=,而不是 >



🍌使用规则 - 索引失效情况1
在索引列上进行 运算,索引列会失效,全表扫描👇
substring截取字串,第二个参数,下标从1开始

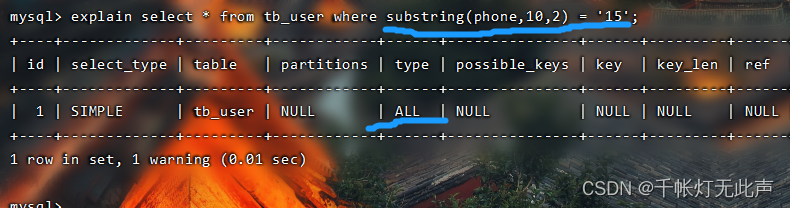
可能用到的索引,用了;但实际的 key,没用到,还是全表扫描


尾部模糊匹配
头部模糊匹配
总之前面不能加 % 和 _,大数据查询下,会全表扫描,大数据下性能较低

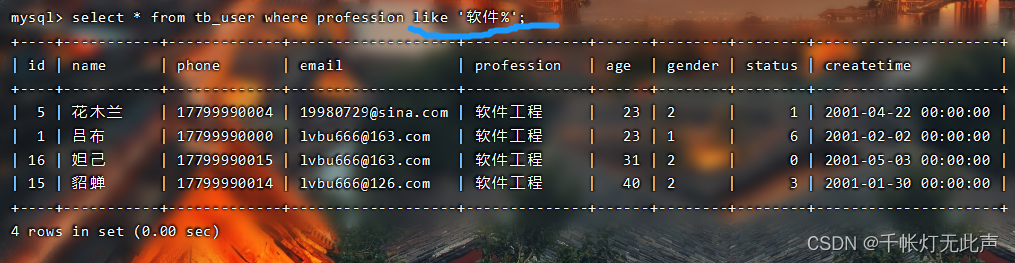

🍌使用规则 - 索引失效情况2
创建age索引👇
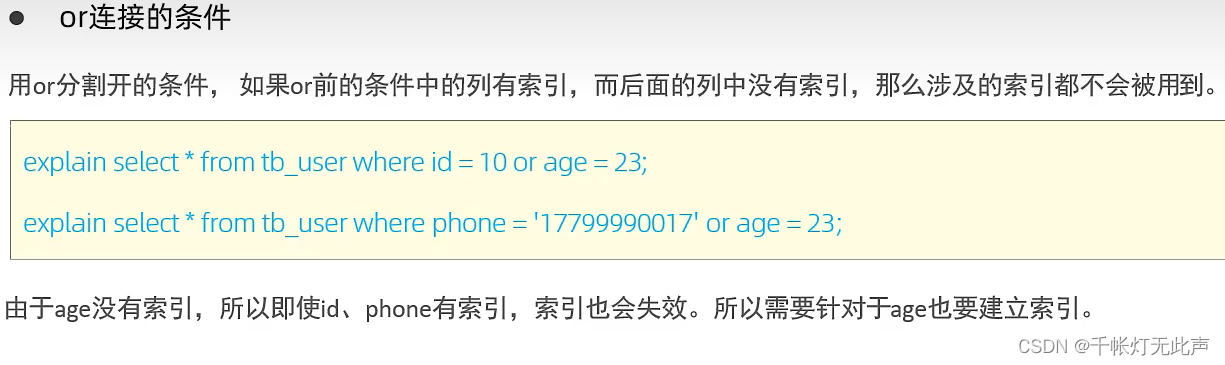





如果Mysql评估走索引比全表扫描慢,则不走索引
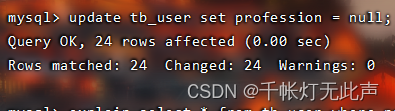
当profession置空,结果会反过来👇
走不走索引,主要看is null 或 is not null占少数还是多数,少数就会走索引
多数的话,Mysql默认不如全表扫描,会直接全表扫描,所以不走索引


🍌使用规则 - SQL提示
注意,为了恢复profession,不是删表再重新插入,而是清空再insert,否则之前创建的联合索引等,还得重新创建👇
create index idx_user_name on tb_user(name);
create unique index idx_user_phone on tb_user(phone);
create index idx_user_pro_age_sta on tb_user(profession,age,status);
create index idx_user_age on tb_user(age);
create index idx_user_email on tb_user(email);
给profession创建单列索引👇
一个单列,一个联合索引,Mysql选择了联合索引👇
提示Mysql到底用哪个索引👇
use用,ignore不用,force必须用,跟在表名后



🍌使用规则 - 覆盖索引&回表查询
一般using index condition对应select *
而using where; using index对应具体的select
(1)
(2)
(1)需要回表查询,效率较低,(2)不需要
因为pro, age, status的联合索引,属于二级索引,二级索引叶子节点挂的是id,此时(2)中直接查询二级索引,就得到了需要的数据
但是(1)中name字段,不在这个二级索引中,还要到id的聚集索引中查找



 关于聚集索引,二级索引和回表查询,可以看👇文章中,索引-分类这一部分
关于聚集索引,二级索引和回表查询,可以看👇文章中,索引-分类这一部分
Mysql进阶(上) -- 存储引擎,索引_千帐灯无此声的博客-CSDN博客
覆盖索引,通俗点讲,就是只需要查询一次,通过索引本身可以满足查询需求。
覆盖索引不需要回表查询。

至于上面提到的,覆盖索引时,避免使用 select *,是因为,容易发生回表查询,除非创建联合索引,而查询的列正好是联合索引包含的列和id
一道面试题👇
如何简历索引,建立怎样的索引,才能是最优方案呢👇
答:根据username, password两个字段,建立联合索引(二级索引),而二级索引叶子下挂的就是id,即覆盖索引,不需要回表查询

🍌使用规则 - 前缀索引
例如,计算email的选择性👇
记录总数24👇
不重复的email也是24👇

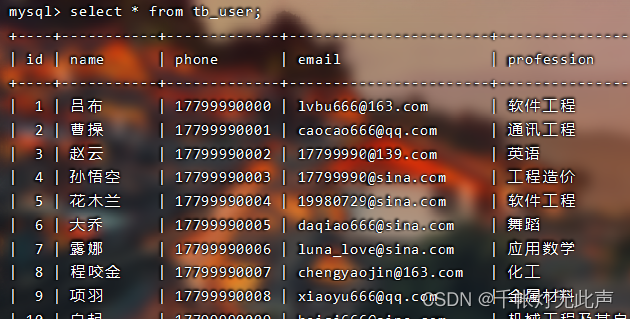


所以email的选择性 = 24 / 24 = 1👇

观察前缀索引,先截取前10个字符,节约索引空间👇
截取前9个👇
直到.....👇
截取到前5个,依然是9583



针对email建立前缀索引
两个5表示,对email取5个前缀
Sub_part表示截取字段
前缀索引使用👇
大文本或长字符串,采取前缀索引,降低索引体积,提高查询效率,避免对磁盘IO的浪费



前缀索引查询流程
首先,主键id会创建聚集索引,我们再创建前缀索引
截取前5个字符是因为,区分度已经足够高
👆逐个匹配,比如 lvbu6,l比d大,所以往右走,来到lvbu6.........
到了叶节点,拿到对应数据后,我们还得对整个email进行对比.....

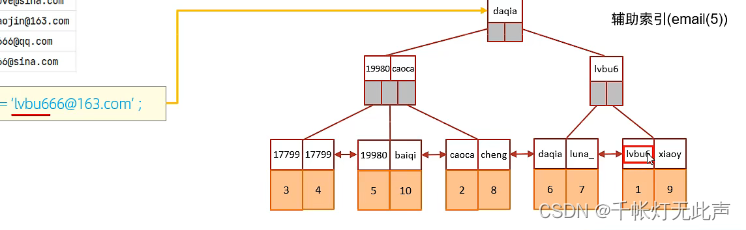
🍌使用规则 - 单列&联合索引
补充:键盘右上角,Home键定位命令行头,Ended键定位尾部。
下面解释为什么,多个联合条件时,推荐使用,联合索引👇

创建联合索引
执行下列语句
extra为Null,表示回表查询了👇因为单列索引和联合索引都存在时,默认单列
当我们建议Mysql使用联合索引👇
Using index表示覆盖索引,不需要回表查询




联合索引情况👇
注意,创建联合索引时,需要考虑字段顺序,根据最左前缀法则,最左边的列,必须非空,否则索引会失效
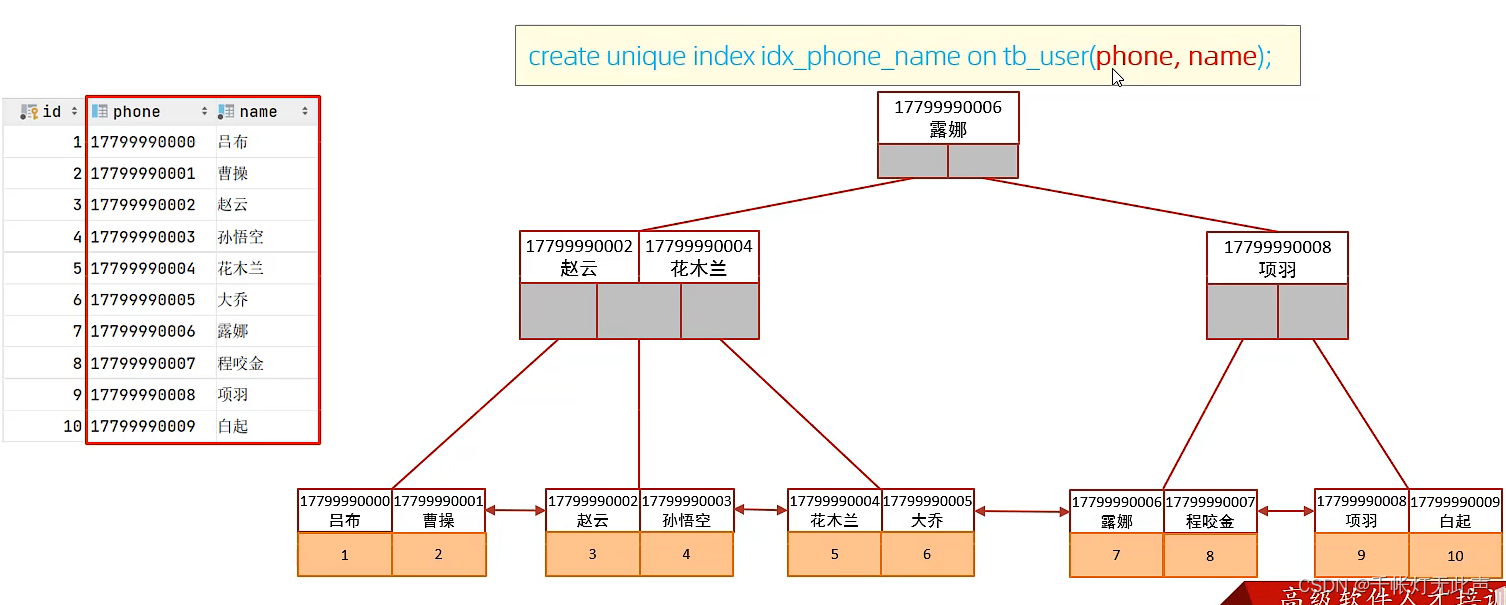
🍉设计原则
(1)比如,100万条数据,就需要建立索引,而几千几万条数据是不需要的
(3)区分度指的是,比如身份证,姓名,部门,区分度最高的是身份证
(4)大文本,长字符串,需要建立前缀索引(也需要考虑区分度)
(5)尽量使用联合索引,可以覆盖索引,避免回表
(6)只建立有必要的索引,降低维护成本

🍉小结
--




![ORA-48913: Writing into trace file failed, file size limit [50000000] reached](https://img-blog.csdnimg.cn/cfac92e0ae1a4994a660479178ddd924.png)




![[机器学习]线性回归模型](https://img-blog.csdnimg.cn/554e41c26f654a3c95a9bf05000715d5.png)