一、说明
二、可以抓取的数据类型
大多数抓取机器人都是为了抓取表格数据或列表而创建的。在标记方面,表和列表本质上是相同的。在容器中,它们保存带有填充值的单元格的行。因此,脚本的算法:
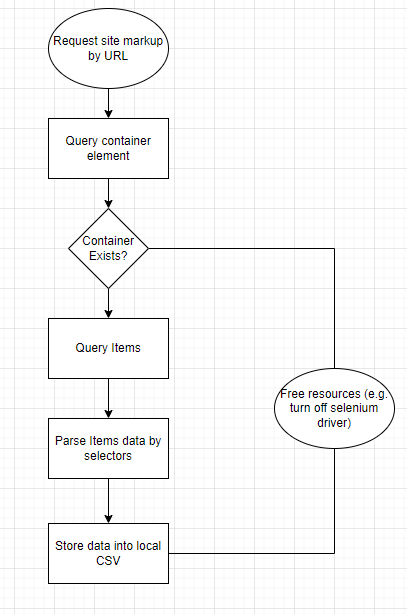
Flowchart of application
三、抓取网站的过程
为了扩展潜在的抓取目标列表,我决定使用python和Selenium的老式组合。虽然我确实喜欢使用 Scrapy 并且在创建自己的解析脚本时受到其可配置设计的高度影响,但它在解析具有分页的站点方面有一定的限制,所以我不得不选择已经提到的解决方案。
为了稳定起见,我还决定使用 dockerized 版本的 chromedriver。在本地Chrome更新期间,它为我节省了一些痛苦,并且始终在那里,为我准备好了,与您在操作系统上安装的版本不同,该版本可能会因系统更新或安装新软件而混乱。
假设您的机器上已经运行了 docker 服务,使用 chromedriver 启动一个新容器就像运行两个命令一样简单:
docker pull selenium/standalone-chrome$ docker run -d -p 4444:4444 -p 7900:7900 — shm-size=”2g” selenium/standalone-chrome
My python script for scraping websites 这篇文章的核心——代码共享段落。首先,我将向您介绍帮助程序方法:
from selenium import webdriver
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def get_local_safe_setup():
options = ChromeOptions()
options.add_argument("--disable-blink-features")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--disable-infobars")
options.add_argument("--disable-popup-blocking")
options.add_argument("--disable-notifications")
driver = Chrome(desired_capabilities = options.to_capabilities())
return driver
def get_safe_setup():
options = ChromeOptions()
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-blink-features")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--disable-infobars")
options.add_argument("--disable-popup-blocking")
options.add_argument("--disable-notifications")
driver = webdriver.Remote("http://127.0.0.1:4444/wd/hub", desired_capabilities = options.to_capabilities())
return driver当我需要在开发过程中调试某些内容时,这两个允许我在 Selenium 的 dockerized 版本和本地版本之间切换。
def get_text_by_selector(container, selector):
elem = container.find_elements_by_class_name(selector)
if len(elem) > 0:
return next(iter(elem)).text.replace('\n',' ').strip()
else:
print(f'Missing value for selector {selector}')
return ''还有一种简单的方法可以从我正在使用的HTML元素中提取文本。在不久的将来,我计划添加助手以自动提取链接和图像。如果对这个主题感兴趣,我可以分享脚本的更新版本。
这种硒基蜘蛛的本质在下面的要点中。请通读评论,如果对它的工作原理有任何疑问 - 请在评论中告诉我。
import os
import time
from tqdm import tqdm
import pandas as pd
import argparse
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from tools.helpers import get_text_by_selector
from tools.setups import get_safe_setup
from tools.loaders import load_config
class Spider:
def __init__(self, driver, config):
self.__driver = driver
self.__config = config
def parse(self, url: str) -> pd.DataFrame:
"""
Scrapes a website from url using predefined config, returns DataFrame
parameters:
url: string
returns:
pandas Dataframe
"""
self.__driver.get(url)
container_element = WebDriverWait(self.__driver, 5).until(
EC.presence_of_element_located((By.CLASS_NAME, self.__config['container_class']))
)
items = self.__driver.find_elements_by_class_name(self.__config['items_class'])
items_content = [
[get_text_by_selector(div, selector) for selector in self.__config['data_selectors']]
for div in items]
return pd.DataFrame(items_content, columns = self.__config['data_column_titles'])
def parse_pages(self, url: str):
"""
Scrapes a website with pagination from url using predefined config, yields list of pandas DataFrames
parameters:
url: string
"""
pagination_config = self.__config['pagination']
for i in tqdm(range(1, pagination_config['crawl_pages'] + 1)):
yield self.parse(url.replace("$p$", str(i)))
time.sleep(int(pagination_config['delay']/1000))
def scrape(args):
config = load_config(args.config)
pagination_config = config['pagination']
url = config['url']
driver = get_safe_setup()
spider = Spider(driver, config)
os.makedirs(os.path.dirname(args.output), exist_ok = True)
try:
if pagination_config['crawl_pages'] > 0:
data = spider.parse_pages(url)
df = pd.concat(list(data), axis = 0)
else:
df = spider.parse(url)
df.to_csv(args.output, index = False)
except Exception as e:
print(f'Parsing failed due to {str(e)}')
finally:
driver.quit()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-c', '--config', help='Configuration of spider learning')
parser.add_argument('-o', '--output', help='Output file path')
args = parser.parse_args()
scrape(args)四、如何使用脚本抓取网站
在这一部分中,我将演示如何使用此脚本。首先,您需要创建一个 YAML 配置文件,然后运行爬虫。例如,让我们刮擦旧的 quotes.toscrape.com。它的配置示例如下所示:
url: https://quotes.toscrape.com/page/$p$/
container_class: col-md-8
items_class: quote
data_selectors:
- text
- author
- keywords
data_column_titles:
- Text
- Author
- Keywords
pagination:
crawl_pages: 5
delay: 5000首先,请注意 $p$ 是未来页码的占位符。这是因为大多数网站提供的页面内容在 URL 中发生了明显变化。你的任务是确定它是如何从一个页面到另一个页面的变化,并用这个面具为你的蜘蛛配置它。
请注意,在data_selectors和data_column_titles中,顺序很重要。例如,引号的文本将从选择器“.text”(duh)解析。
准备好配置后,您可以使用以下命令执行它:
python -m spider -c “./configs/quotes.yaml” -o “./outputs/quotes/$(date +%Y-%m-%d).csv” 上面的 Bash 行从“./configs/quotes.yaml”文件中获取配置,并将 CSV 文件中的结果存储到 “./outputs/quotes/current_date.csv”
五、关于如何改进刮削过程的提示
- 使用代理
Selenium 允许您传递代理 IP 地址,就像向其构造函数添加参数一样简单。 在StackOverflow有一个完美的答案,所以我不会尝试发明轮子。
- 对要解析的网站保持温和
检查机器人.txt并遵守。使用特定超时运行请求以平滑负载。使用计划在晚上或您认为站点的传入流量较低时运行脚本。
六、结果
敏捷抓取机器人最好的事情之一是,您不必为要解析的每个站点编写新的机器人。您只需要一个可以针对每个站点或域进行调整的好脚本。回想一下你今年到目前为止的所有抓取项目——你想让我在我的脚本中添加什么?