目录
引言
1. 模型训练的重要性
2. 数据预处理
3. 特征工程
4. 模型选择与评估
5. 参数调优
6. 模型集成
7. 过拟合与欠拟合
8. 模型保存与加载
9. 分布式训练与加速
10. 最佳实践与常见问题
引言
模型训练是机器学习领域中至关重要的一步,它决定了模型的表现和性能。本文将介绍模型训练的基本概念、常用的技术和最佳实践,帮助读者了解如何有效地进行模型训练并取得优秀的结果。
1. 模型训练的重要性
模型训练是指根据给定的数据集,使用机器学习算法来调整模型的参数,使其能够对未知数据进行准确的预测或分类。一个好的模型训练过程可以提高模型的泛化能力,使其在实际应用中表现更好。
2. 数据预处理
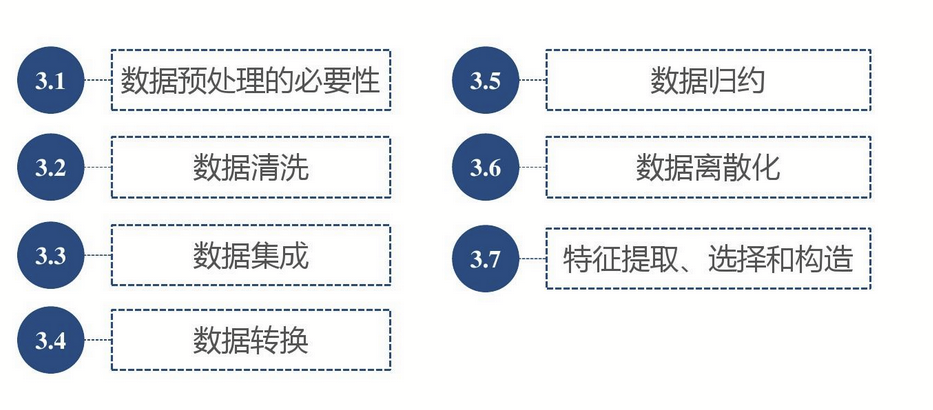
在进行模型训练之前,通常需要对原始数据进行预处理。预处理包括数据清洗、数据转换、特征选择等步骤。这些步骤旨在提高数据的质量和可用性,为后续的特征工程和模型训练做准备。
# 导入数据处理库
import pandas as pd
# 读取数据集
data = pd.read_csv('data.csv')
# 清洗数据:去除缺失值
data = data.dropna()
# 转换数据:将类别数据转换为数值
data['label'] = data['label'].map({'cat': 0, 'dog': 1})
# 特征选择:选择需要的特征列
selected_features = ['feature1', 'feature2']
X = data[selected_features]
y = data['label']3. 特征工程
特征工程是指根据原始数据构建合适的特征,以提高模型的表现。常见的特征工程技术包括特征选择、特征提取和特征变换等。通过有效的特征工程,可以更好地表达数据的内在规律,提高模型的预测能力。
4. 模型选择与评估

在模型训练过程中,需要选择适当的机器学习算法来构建模型。模型选择的关键是结合实际问题和数据特点,选取合适的算法,并使用评估指标对模型进行评估。常用的评估指标包括准确率、精确率、召回率和F1值等。
# 导入模型库和评估指标库
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化模型
model = SVC()
# 拟合模型
model.fit(X_train, y_train)
# 预测结果
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print('Accuracy:', accuracy)
print('Precision:', precision)
print('Recall:', recall)
print('F1 Score:', f1)
5. 参数调优
模型的性能往往受到参数的影响,因此参数调优是模型训练中的重要环节。通过网格搜索、随机搜索或贝叶斯优化等方法,可以找到最佳的参数组合,提高模型的性能。
# 导入网格搜索库
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
# 初始化网格搜索
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, scoring='accuracy', cv=5)
# 进行网格搜索
grid_search.fit(X_train, y_train)
# 获取最佳参数和最佳得分
best_params = grid_search.best_params_
best_score = grid_search.best_score_
print('Best Parameters:', best_params)
print('Best Score:', best_score)6. 模型集成
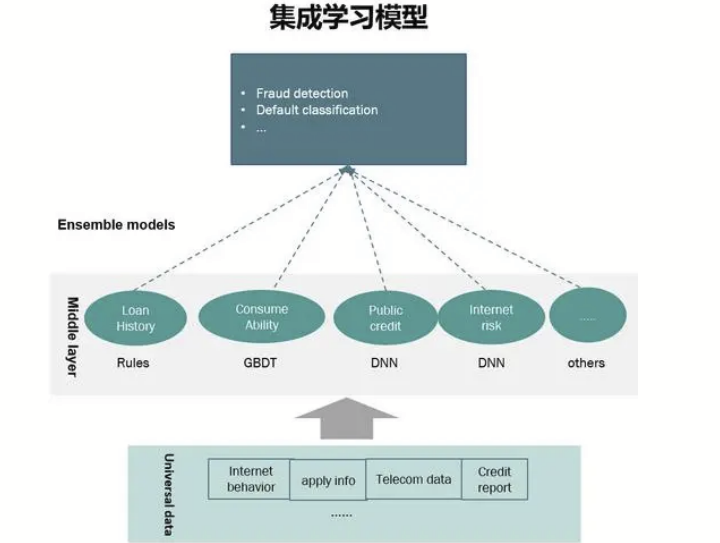
模型集成是指将多个模型组合在一起,以提高预测的准确性和鲁棒性。常用的模型集成技术包括投票法、堆叠法和提升法等。通过合理地选择和组合不同的模型,可以进一步提升模型的性能。
# 导入集成模型库
from sklearn.ensemble import VotingClassifier
# 定义模型1
model1 = SVC()
# 定义模型2
model2 = RandomForestClassifier()
# 定义模型3
model3 = GradientBoostingClassifier()
# 定义投票法集成模型
ensemble_model = VotingClassifier(estimators=[('svm', model1), ('rf', model2), ('gb', model3)], voting='hard')
# 拟合集成模型
ensemble_model.fit(X_train, y_train)
# 预测结果
y_pred = ensemble_model.predict(X_test)7. 过拟合与欠拟合
过拟合和欠拟合是模型训练中常见的问题。过拟合指模型在训练集上表现良好,但在测试集或实际应用中表现较差;而欠拟合则指模型无法很好地拟合数据,导致预测精度低。了解并解决过拟合和欠拟合问题是模型训练的关键。

# 导入模型库和学习曲线库
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import learning_curve
# 初始化线性回归模型
model = LinearRegression()
# 绘制学习曲线
train_sizes, train_scores, test_scores = learning_curve(model, X, y)
# 计算平均分数
train_scores_mean = np.mean(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
# 绘制学习曲线图
plt.plot(train_sizes, train_scores_mean, label='Train')
plt.plot(train_sizes, test_scores_mean, label='Test')
plt.xlabel('Training Size')
plt.ylabel('Score')
plt.legend()
plt.show()8. 模型保存与加载
在模型训练完成后,需要将模型保存到磁盘,并在需要时加载模型进行预测。通常,模型保存格式包括二进制格式、JSON格式和ONNX格式等。正确地保存和加载模型可以提高模型的可用性和效率。

# 使用joblib保存模型
import joblib
# 保存模型
joblib.dump(model, 'model.pkl')
# 加载模型
loaded_model = joblib.load('model.pkl')
# 使用加载的模型进行预测
y_pred = loaded_model.predict(X_test)9. 分布式训练与加速
对于大规模数据和复杂模型,通常需要使用分布式训练和加速技术来提高训练效率和性能。常见的分布式训练和加速技术包括并行计算、GPU加速和深度学习框架的优化等。
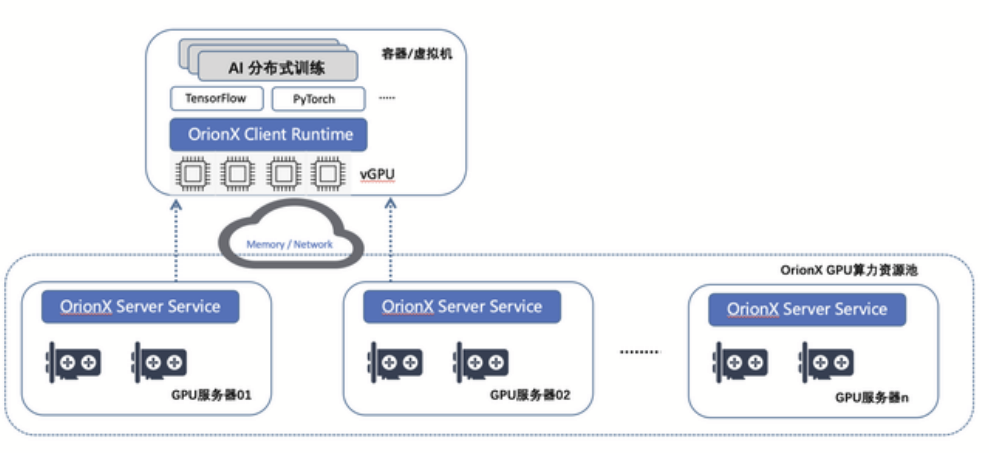
# 使用并行计算库进行分布式训练
from joblib import Parallel, delayed
# 并行计算示例
results = Parallel(n_jobs=-1)(delayed(model.fit)(X_train_batch, y_train_batch) for X_train_batch, y_train_batch in zip(X_train_batches, y_train_batches))10. 最佳实践与常见问题
在模型训练过程中,遵循最佳实践可以提高工作效率和模型表现。此外,了解常见问题和解决方法也是不可或缺的。本节将介绍一些最佳实践和常见问题,并给出相应的解决方案。
最佳实践:
数据预处理:清洗数据、处理缺失值、特征缩放等。
特征工程:选择合适的特征、进行特征变换和特征交互等。
参数调优:使用网格搜索或贝叶斯优化等方法寻找最佳参数。
模型评估:使用交叉验证和多个评估指标来评估模型性能。
常见问题与解决方案:
过拟合:增加训练数据、使用正则化技术、简化模型等。
欠拟合:增加模型复杂度、改进特征工程等。
训练时间过长:使用分布式训练、优化模型和数据等。
文末送书

明日科技编著的《Java从入门到精通》以初、中级程序员为对象,先从Java语言基础学起,再学习Java的核心技术,然后学习Swing的高级应用,最后学习开发一个完整项目。
包括初识Java,熟悉Eclipse开发工具,Java语言基础,流程控制,字符串,数组,类和对象,包装类,数字处理类,接口、继承与多态,类的高级特性,异常处理,Swing程序设计,集合类,I/O(输入/输出),反射,枚举类型与泛型,多线程,网络通信,数据库操作,Swing表格组件,Swing树组件,Swing其他高级组件,高级布局管理器,高级事件处理,AWT绘图与音频播放,打印技术等。
书中所有知识都结合具体实例进行介绍,涉及的程序代码给出了详细的注释,可以使读者轻松领会Java程序开发的精髓,快速提高开发技能。