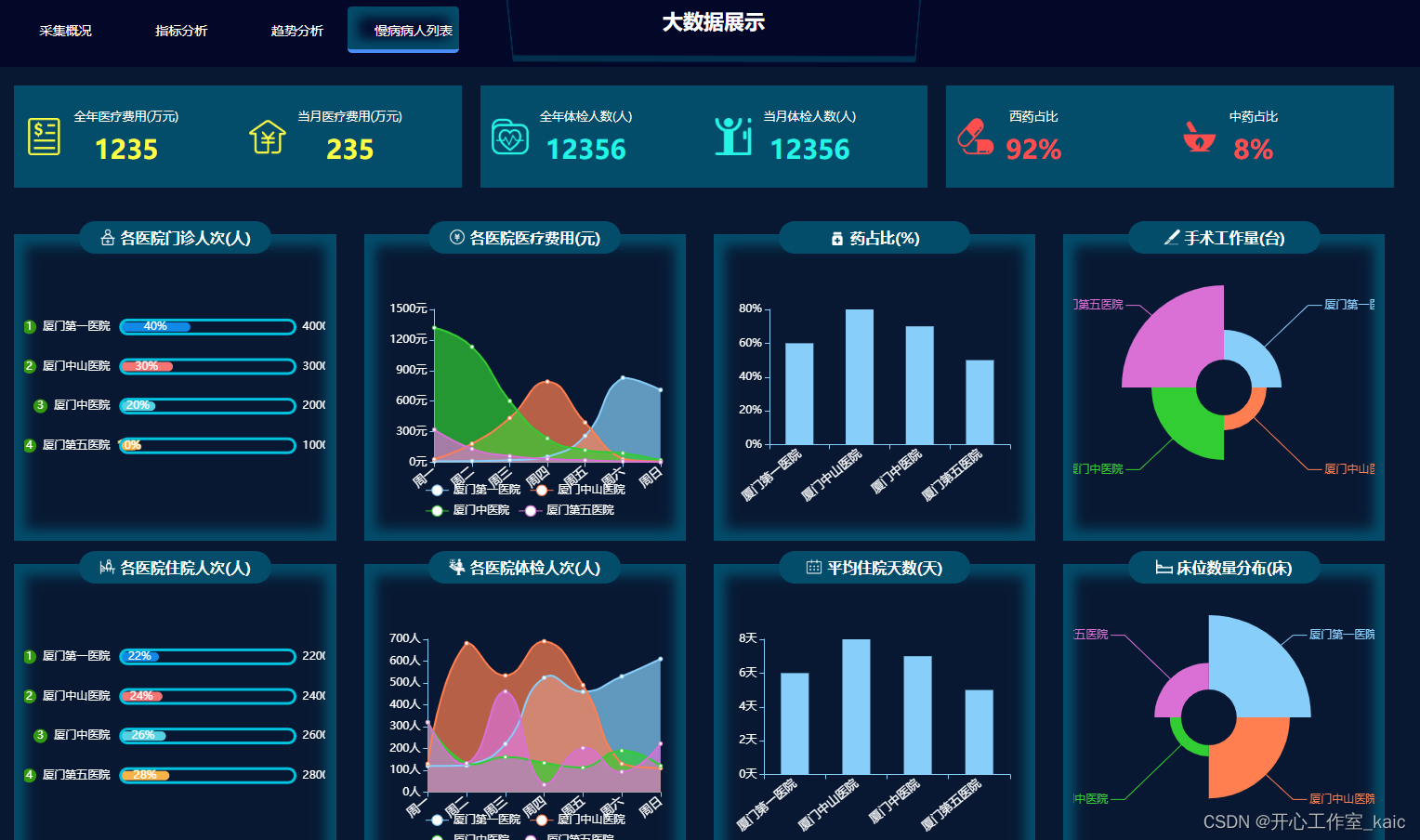
Fast-SCNN: Fast Semantic Segmentation Network - 快速语义分割网络(arXiv 2019)
- 摘要
- 1. 引言
- 2. 相关工作
- 2.1 语义分割的基础
- 2.2 DCNN的效率
- 2.3 辅助任务预训练
- 3. 提议的Fast-SCNN
- 3.1 动机
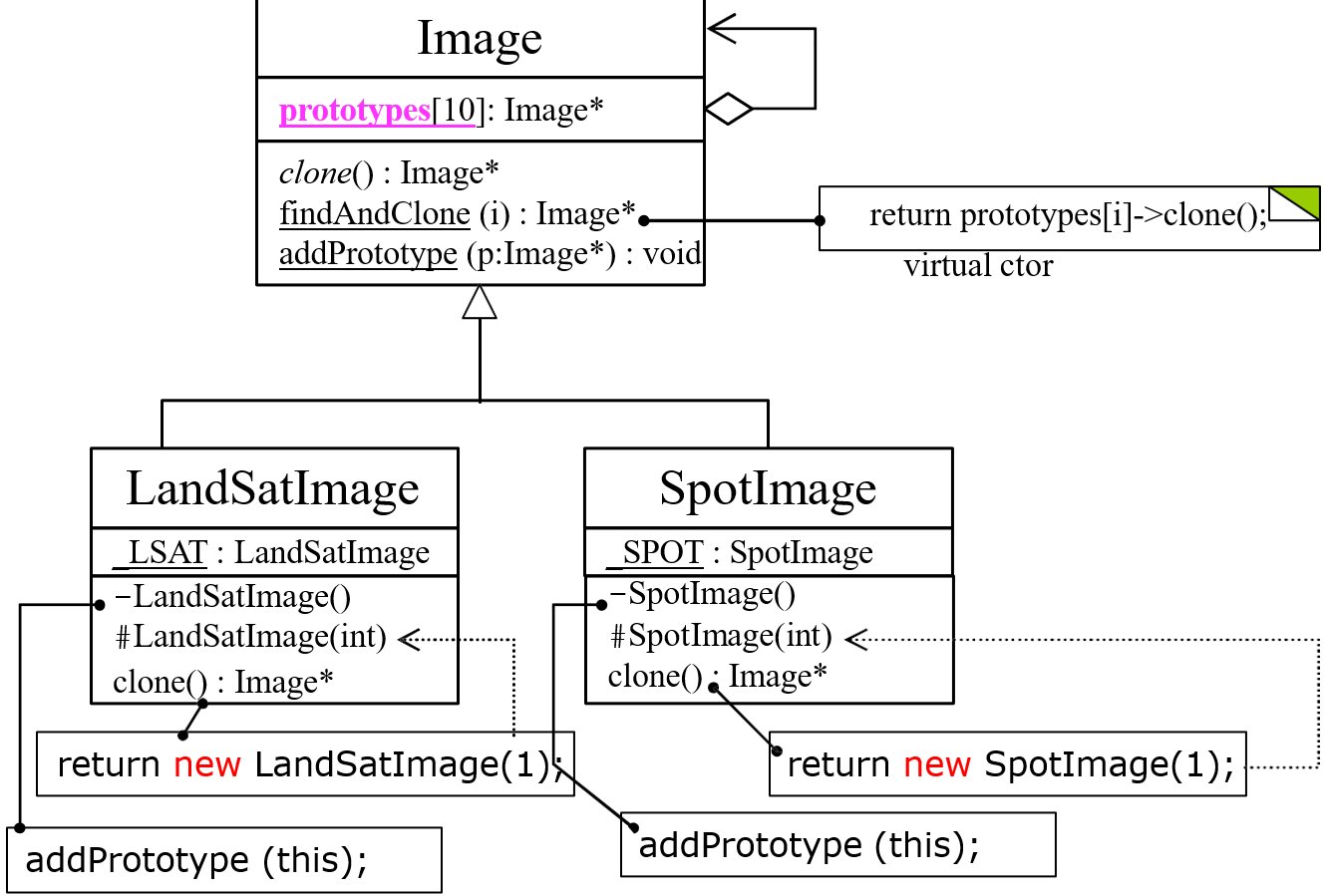
- 3.2 网络架构
- 3.2.1 学习下采样
- 3.2.2 全局特征提取器
- 3.2.3 特征融合模块
- 3.2.4 分类器
- 3.3 与现有技术的比较
- 3.3.1 与两个分支模型的关系
- 3.3.2 与编码器-解码器模型的关系
- 4. 实验
- 4.1 实施细节
- 4.2 Cityscapes评价
- 4.3 预训练和弱标记数据
- 4.4 更低的输入分辨率
- 5. 结论
- References
声明:此翻译仅为个人学习记录
文章信息
- 标题:Fast-SCNN: Fast Semantic Segmentation Network (arXiv 2019)
- 作者:Rudra PK Poudel, Stephan Liwicki and Roberto Cipolla
- 文章链接:https://arxiv.org/pdf/1902.04502.pdf
- 文章代码:https://github.com/Tramac/Fast-SCNN-pytorch
(推荐:亦可参考 图像 处理 - 开源算法集合)
摘要
编码器-解码器框架是用于离线语义图像分割的最先进的框架。随着自主系统的兴起,实时计算越来越受欢迎。在本文中,我们介绍了快速分割卷积神经网络(Fast-SCNN),这是一种针对高分辨率图像数据(1024×2048px)的实时语义分割模型,适用于低内存嵌入式设备上的高效计算。在现有的两种快速分割分支方法的基础上,我们引入了我们的“学习下采样”模块,该模块同时计算多个分辨率分支的低级特征。我们的网络将高分辨率的空间细节与低分辨率提取的深层特征相结合,在Cityscapes上以每秒123.5帧的速度产生68.0%的平均交并比精度。我们还表明,大规模的预先训练是不必要的。我们在ImageNet预训练和Cityscapes的粗略标记数据的实验中彻底验证了我们的度量。最后,我们展示了在没有任何网络修改的情况下,在子采样输入上具有竞争性结果的更快的计算。
1. 引言
快速语义分割在实时应用程序中尤为重要,在实时应用中,要快速解析输入以促进与环境的响应交互。由于人们对自主系统和机器人技术越来越感兴趣,因此很明显,实时语义分割的研究最近受到了极大的欢迎[21,34,17,25,36,20]。我们强调,事实上,比实时性能更快的性能往往是必要的,因为语义标记通常只作为其他时间关键任务的预处理步骤。此外,嵌入式设备上的实时语义分割(无需访问强大的GPU)可以实现许多额外的应用,例如可穿戴设备的增强现实。我们观察到,在文献中,语义分割通常由具有编码器-解码器框架的深度卷积神经网络(DCNN)来解决[29,2],而许多运行时高效的实现采用两分支或多分支架构[21,34,17]。通常情况下
-
更大的感受野对于学习目标类之间的复杂相关性(即全局上下文)很重要,
-
图像中的空间细节对于保留目标边界是必要的,以及
-
需要特定的设计来平衡速度和准确性(而不是重新定位分类DCNN)。
具体而言,在两个分支网络中,较深的分支以低分辨率被用于捕获全局上下文,而较浅的分支被设置用于以全输入分辨率学习空间细节。然后通过合并两者来提供最终的语义分割结果。重要的是,由于较深网络的计算成本可以通过较小的输入大小来克服,并且全分辨率执行仅用于少数层,因此在现代GPU上可以实现实时性能。与编码器-解码器框架相比,在两分支方法中,不同分辨率的初始卷积是不共享的。这里值得注意的是,引导上采样网络(GUN)[17]和图像级联网络(ICNet)[36]仅共享前几层之间的权重,而不共享计算。
在这项工作中,我们提出了快速分割卷积神经网络Fast-SCNN,这是一种将现有技术[21,34,17,36]的两个分支设置与经典编码器-解码器框架[29,2]相结合的实时语义分割算法(图1)。基于对初始DCNN层提取低级特征的观察[35,19],我们共享两分支方法中初始层的计算。我们称这种技术为向下采样学习。其效果类似于编码器-解码器模型中的跳过连接,但跳过仅使用一次以保持运行时效率,并且模块保持较浅以确保特征共享的有效性。最后,我们的Fast-SCNN采用了有效的深度可分离卷积[30,10]和逆残差块[28]。

图1. Fast-SCNN在两个分支(编码器)之间共享计算,以构建一个以上实时的语义分割网络。
应用于Cityscapes[6],Fast SCNN在使用全分辨率(1024×2048px)的现代GPU(Nvidia Titan Xp(Pascal))上以每秒123.5帧(fps)的速度产生68.0%的平均交并比(mIoU),其速度是现有技术即BiSeNet(71.4%mIoU)[34]的两倍。
虽然我们使用了111万个参数,但大多数离线分割方法(例如DeepLab[4]和PSPNet[37])和一些实时算法(例如GUN[17]和ICNet[36])需要的远不止这些。Fast-SCNN的模型容量特别低。原因有两个:(i)较低的内存可以在嵌入式设备上执行,(ii)预期会有更好的通用性。特别是,经常建议在ImageNet[27]上进行预训练,以提高准确性和通用性[37]。在我们的工作中,我们研究了预训练对低容量快速SCNN的影响。与高容量网络的趋势相矛盾的是,我们发现,预训练或额外的粗略标记训练数据(Cityscapes[6]上+0.5%mIoU)只会对结果产生不显著的改善。总之,我们的贡献是:
-
我们提出了Fast-SCNN,这是一种具有竞争力的(68.0%)及以上实时语义分割算法(123.5fps),用于高分辨率图像(1024×2048px)。
-
我们调整了离线DCNN中流行的跳过连接,并提出了一个浅层学习下采样模块,用于快速高效的多分支低级特征提取。
-
我们专门将Fast SCNN设计为低容量的,并且我们从经验上验证了运行更多时期的训练与在我们的小容量网络中使用ImageNet预训练或使用额外的粗略数据进行训练同等成功。
此外,我们使用Fast-SCNN对输入数据进行二次采样,在不需要重新设计网络的情况下实现了最先进的性能。
2. 相关工作
我们讨论并比较了语义图像分割框架,特别关注低能量和内存需求的实时执行[2,20,21,36,34,17,25,18]。
2.1 语义分割的基础
最先进的语义分割DCNN结合了两个独立的模块:编码器和解码器。编码器模块使用卷积和池化操作的组合来提取DCNN特征。解码器模块从亚分辨率特征中恢复空间细节,并预测目标标签(即语义分割)[29,2]。最常见的是,编码器适用于简单的分类DCNN方法,如VGG[31]或ResNet[9]。在语义分割中,完全连接的层被去除。
开创性的全卷积网络(FCN)[29]为大多数现代分割架构奠定了基础。具体而言,FCN采用VGG[31]作为编码器,并结合来自较低层的跳跃连接进行双线性上采样,以恢复空间细节。U-Net[26]使用密集跳跃连接进一步利用了空间细节。
后来,受DCNN[13,16]之前的全局图像级上下文的启发,PSPNet[37]的金字塔池模块和DeepLab[4]的萎缩空间金字塔池(ASPP)被用于编码和利用全局上下文。
其他竞争性基本分割架构使用条件随机场(CRF)[38,3]或递归神经网络[32,38]。然而,它们都不是实时运行的。
与目标检测[23,24,15]类似,速度成为图像分割系统设计中的一个重要因素[21,34,17,25,36,20]。SegNet[2]在FCN的基础上引入了编码器-解码器联合模型,成为最早的高效分割模型之一。继SegNet之后,ENet[20]还设计了一种层数较少的编码器-解码器,以降低计算成本。
最近,引入了两个分支和多个分支系统。ICNet[36]、ContextNet[21]、BiSeNet[34]和GUN[17]在深分支中以降低的分辨率输入学习全局上下文,而在浅分支中以全分辨率学习边界。
然而,最先进的实时语义分割仍然具有挑战性,并且通常需要高端GPU。受两种分支方法的启发,Fast-SCNN结合了一个共享的浅层网络路径来编码细节,同时在低分辨率下有效地学习上下文(图2)。
2.2 DCNN的效率
高效DCNN的常见技术可分为四类:
深度可分离卷积:MobileNet[10]将标准卷积分解为深度卷积和1×1点卷积,统称为深度可分离卷。这种因子分解减少了浮点运算和卷积参数,因此降低了模型的计算成本和内存需求。
DCNN的有效重新设计:Chollet[5]使用有效的深度可分离卷积设计了Xception网络。MobleNet-V2提出了反向瓶颈残差块[28],以构建用于分类任务的高效DCNN。ContextNet[21]使用反向瓶颈残差块来设计用于高效实时语义分割的双分支网络。类似地,[34,17,36]提出了多分支分割网络来实现实时性能。
网络量化:由于浮点乘法与整数或二进制运算相比代价高昂,因此可以使用DCNN滤波器和激活值的量化技术进一步减少运行时间[11,22,33]。
网络压缩:修剪用于减少预先训练的网络的大小,从而实现更快的运行时间、更小的参数集和更小的内存占用[21,8,14]。
Fast-SCNN在很大程度上依赖于深度可分离卷积和残差瓶颈块[28]。此外,我们引入了一个双分支模型,该模型包含了我们的学习到下采样模块,允许在多个分辨率级别上进行共享特征提取(图2)。注意,尽管多个分支的初始层提取了相似的特征[35,19],但常见的两个分支方法并没有利用这一点。网络量化和网络压缩可以正交应用,并留给未来的工作。

图2: Fast-SCNN与编码器-解码器和两种分支架构的示意图比较。编码器-解码器在许多分辨率下采用多个跳跃连接,通常由深度卷积块产生。两种分支方法利用低分辨率的全局特征和浅空间细节。Fast-SCNN在我们的学习中同时对全局上下文的空间细节和初始层进行编码,以降采样模块。
2.3 辅助任务预训练
人们普遍认为,辅助任务的预训练可以提高系统的准确性。早期关于目标检测[7]和语义分割[4,37]的工作已经在ImageNet[27]上的预训练中表明了这一点。遵循这一趋势,其他实时高效的语义分割方法也在ImageNet上进行了预训练[36,34,17]。然而,尚不清楚在低容量网络上是否有必要进行预训练。Fast-SCNN是专门为低容量设计的。在我们的实验中,我们表明小型网络并没有从预训练中获得显著的好处。相反,积极的数据增强和更多的时期提供了类似的结果。
3. 提议的Fast-SCNN
Fast-SCNN的灵感来自两个分支架构[21,34,17]和具有跳过连接的编码器-解码器网络[29,26]。注意到早期层通常提取低级特征。我们将跳过连接重新解释为一个向下采样的学习模块,使我们能够合并两个框架的关键思想,并使我们能够构建一个快速的语义分割模型。图1和表1显示了Fast-SCNN的布局。在下文中,我们将讨论我们的动机,并更详细地描述我们的构建块。

表1. Fast-SCNN使用标准卷积(Conv2D)、深度可分离卷积(DSConv)、反向残差瓶颈块(bottleneck)、金字塔池模块(PPM)和特征融合模块(FFM)块。参数t、c、n和s表示瓶颈块的扩展因子、输出通道的数量、块被重复的次数以及应用于重复块的第一序列的步长参数。水平线将模块分开:学习下采样、全局特征提取器、特征融合和分类器(从上到下)。
3.1 动机
当前最先进的实时运行的语义分割方法基于具有两个分支的网络,每个分支在不同的分辨率级别上运行[21,34,17]。他们从输入图像的低分辨率版本中学习全局信息,并采用全输入分辨率的浅层网络来提高分割结果的精度。由于输入分辨率和网络深度是运行时的主要因素,这两种分支方法允许实时计算。
众所周知,DCNN的前几层提取低级特征,如边缘和拐角[35,19]。因此,我们不是采用具有单独计算的两分支方法,而是将学习引入下采样,它在浅层网络块中的低分支和高级分支之间共享特征计算。
3.2 网络架构
我们的Fast-SCNN使用学习下采样模块、粗略全局特征提取器、特征融合模块和标准分类器。所有模块都是使用深度可分离卷积构建的,这已成为许多高效DCNN架构的关键构建块[5,10,21]。

表2. 瓶颈残差块以扩展因子t将输入从c通道传输到c’通道。注意,最后一次逐点卷积不使用非线性f。输入的高度为h,宽度为w,x/s表示层的内核大小和步长。
3.2.1 学习下采样
在我们的学习下采样模块中,我们使用了三层。只采用了三层来确保低级别特征共享是有效的,并有效地实现。第一层是标准卷积层(Conv2D),其余两层是深度可分离卷积层(DSConv)。在这里,我们强调,尽管DSConv在计算上更高效,但我们使用Conv2D,因为输入图像只有三个通道,这使得DSConv的计算优势在现阶段微不足道。
我们的学习下采样模块中的所有三个层都使用步长2,然后是批量归一化[12]和ReLU。卷积层和深度层的空间核大小为3×3。在[5,28,21]之后,我们省略了深度卷积和逐点卷积之间的非线性。
3.2.2 全局特征提取器
全局特征提取器模块旨在捕获用于图像分割的全局上下文。与在输入图像的低分辨率版本上操作的常见两分支方法不同,我们的模块直接将学习的输出取为下采样模块(其分辨率为原始输入的 1 8 \frac{1}{8} 81)。该模块的详细结构如表1所示。我们使用MobileNet-V2[28]引入的有效瓶颈残差块(表2)。特别地,当输入和输出大小相同时,我们对瓶颈残差块使用残差连接。我们的瓶颈块使用了一种有效的深度可分离卷积,从而减少了参数和浮点运算的数量。此外,在末尾添加了金字塔池模块(PPM)[37],以聚合基于不同区域的上下文信息。
3.2.3 特征融合模块
与ICNet[36]和ContextNet[21]类似,我们更喜欢简单地添加功能以确保效率。或者,可以以运行时性能为代价,采用更复杂的特征融合模块(例如[34]),以达到更好的精度。特征融合模块的细节如表3所示。

表3. Fast-SCNN的特征融合模块(FFM)。注意,逐点卷积具有所需的输出,并且不使用非线性f。在添加特征之后,使用了非线性f。
3.2.4 分类器
在分类器中,我们使用了两个深度可分离卷积(DSConv)和一个逐点卷积(Conv2D)。我们发现,在特征融合模块之后添加几层可以提高准确性。分类器模块的详细信息如表1所示。
Softmax在训练过程中使用,因为它采用了渐变体面。在推理过程中,我们可以用argmax代替代价高昂的softmax计算,因为这两个函数都是单调递增的。我们将此选项表示为Fast-SCNN cls(分类)。另一方面,如果需要基于标准DCNN的概率模型,则使用softmax,表示为Fast-SCNN prob(概率)。
3.3 与现有技术的比较
我们的模型受到两个分支框架的启发,并结合了编码器-去编码器方法的思想(图2)。
3.3.1 与两个分支模型的关系
最先进的实时模型(ContextNet[21]、BiSeNet[34]和GUN[17])使用两个分支网络。我们的下采样学习模块相当于它们的空间路径,因为它是浅的,从全分辨率学习,并用于特征融合模块(图1)。
我们的全局特征提取器模块相当于这种方法的更深层次的低分辨率分支。相反,我们的全局特征提取器与学习下采样模块共享其对前几层的计算。通过共享层,我们不仅降低了特征提取的计算复杂性,而且还降低了所需的输入大小,因为Fast-SCNN使用 1 8 \frac{1}{8} 81分辨率而不是 1 4 \frac{1}{4} 41分辨率进行全局特征提取。
3.3.2 与编码器-解码器模型的关系
所提出的Fast-SCNN可以被视为编码器-解码器框架的特殊情况,如FCN[29]或U-Net[26]。然而,与FCN中的多个跳过连接和U-Net中的密集跳过连接不同,Fast-SCNN只使用单个跳过连接来减少计算和内存。
与[35]一致,[35]主张仅在DCNN的早期层共享功能,我们将跳过连接定位在网络的早期。相反,在应用跳过连接之前,现有技术通常在每个分辨率下采用更深的模块。
4. 实验
我们在Cityscapes数据集[6]的验证集上评估了我们提出的快速分割卷积神经网络(Fast-SCNN),并在Cityscapes测试集(即Cityscabes基准服务器)上报告了其性能。
4.1 实施细节
当涉及到高效的DCNN时,实现细节与理论一样重要。因此,我们在这里仔细描述了我们的设置。我们使用Python在TensorFlow机器学习平台上进行了实验。我们的实验在带有Nvidia Titan X(Maxwell)或Nvidia Titan Xp(Pascal)GPU、CUDA 9.0和CuDNN v7的工作站上执行。在单个CPU线程和一个GPU中执行运行时评估,以测量正向推理时间。我们使用100帧进行烧录,并报告每秒帧数(fps)测量的平均值为100帧。
我们使用动量为0.9、批量大小为12的随机梯度下降(SGD)。受[4,37,10]的启发,我们使用“poly”学习率,基本学习率为0.045,幂为0.9。类似于MobileNet-V2,我们发现 ℓ 2 \ell2 ℓ2正则化在深度卷积上是不必要的,对于其他层 ℓ 2 \ell2 ℓ2是0.00004。由于用于语义分割的训练数据是有限的,我们应用了各种数据增强技术:0.5到2之间的随机调整大小、平移/裁剪、水平翻转、颜色通道噪声和亮度。我们的模型是用交叉熵损失训练的。我们发现,学习到下采样结束时的辅助损失和权重为0.4的全局特征提取模块是有益的。
在每个非线性函数之前使用批量归一化[12]。Dropout仅在softmax层之前的最后一层上使用。与MobileNet[10]和ContextNet[21]相反,我们发现,即使使用我们在整个模型中使用的深度可分离卷积,Fast-SCNN使用ReLU训练得更快,精度也略高于ReLU6。
我们发现,DCNN的性能可以通过训练更高次数的迭代来提高,因此,除非另有说明,否则我们使用Cityescapes数据集训练我们的模型1000个时期[6]。这里值得注意的是,Fast-SCNN的容量故意非常低,因为我们使用了111万个参数。稍后我们展示了激进的数据增强技术使过拟合变得不太可能。

表4. 在Cityscapes测试集上,与其他最先进的语义分割方法相比,所提出的Fast-SCNN的类和类别mIoU。参数的数量以百万计。

表5. TensorFlow在Nvidia Titan X(Maxwell,3072个CUDA核心)上的运行时(fps)[1]。带“*”的方法表示在Nvidia Titan Xp(Pascal,3840个CUDA核心)上的结果。显示了两个版本的Fast-SCNN:softmax输出(我们的prob)和目标标签输出(我们的cls)。
4.2 Cityscapes评价
我们在Cityscapes上评估了我们提出的Fast-SCNN,这是城市道路上最大的公开数据集[6]。该数据集包含从欧洲50个不同城市拍摄的一组不同的高分辨率图像(1024×2048px)。它有5000张高标签质量的图像:2975张训练集、500张验证集和1525张测试集。训练集和验证集的标签是可用的,测试结果可以在评估服务器上进行评估。此外,20000个弱注释图像(粗略标签)可用于训练。我们报告了两者的结果,仅精细和精细标记的粗略数据。Cityscapes提供了30个类别标签,而只有19个类别用于评估。交并比的平均值(mIoU)和网络推理时间报告如下。
我们评估了Cityscapes[6]的保留测试集的总体性能。所提出的Fast-SCNN与其他最先进的实时语义分割方法(ContextNet[21]、BiSeNet[34]、GUN[17]、ENet[20]和ICNet[36])和离线方法(PSPNet[37]和DeepLab-V2[4])之间的比较如表4所示。Fast-SCNN实现了68.0%的mIoU,略低于BiSeNet(71.5%)和GUN(70.4%)。ContextNet仅实现了66.1%。
表5比较了不同分辨率下的运行时间。这里,BiSeNet(57.3 fps)和GUN(33.3 fps)明显慢于Fast-SCNN(123.5 fps)。与ContextNet(41.9 fps)相比,Fast-SCNN在Nvidia Titan X(Maxwell)上的速度也明显更快。因此,我们得出结论,Fast-SCNN在精度损失较小的情况下,显著提高了最先进的运行时间。在这一点上,我们强调,我们的模型是为低内存嵌入式设备设计的。Fast-SCNN使用了111万个参数,比竞争对手BiSeNet 580万个参数少了五倍。
最后,我们将跳过连接的贡献归零,并测量Fast-SCNN的性能。验证集的mIoU从69.22%降低到64.30%。定性结果如图3所示。正如预期的那样,Fast-SCNN受益于跳过连接,尤其是在边界和小尺寸目标周围。

表6. 在Cityscapes验证集上对不同Fast-SCNN设置的类别mIoU。
4.3 预训练和弱标记数据
高容量DCNN,如R-CNN[7]和PSPNet[37],已经表明通过不同的辅助任务进行预训练可以提高性能。由于我们专门将Fast-SCNN设计为具有低容量,因此我们现在希望在有和没有预训练的情况下,以及在有和无额外弱标记数据的情况下测试性能。据我们所知,低容量DCNN上的预训练和附加弱标记数据的重要性以前没有研究过。结果如表6所示。
我们在ImageNet[27]上通过用平均池替换特征融合模块来预训练Fast-SCNN,并且分类模块现在只有softmax层。Fast-SCNN在ImageNet验证集上实现了60.71%的top-1和83.0%的top-5准确率。这一结果表明,Fast-SCNN的容量不足以达到与ImageNet上的大多数标准DCNN相当的性能(>70% top-1)[10,28]。在Cityscapes的验证集上,具有ImageNet预训练的Fast-SCNN的准确性产生了69.15%的mIoU,仅比没有预训练的Fast-SCNN提高了0.53%。因此,我们得出结论,在Fast-SCNN中,ImageNet预训练无法实现显著的提升。

图3. Fast-SCNN分割结果的可视化。第一列:输入RGB图像;第二列:Fast-SCNN的输出;最后一列:将跳过连接的贡献清零后Fast-SCNN的输出。在所有结果中,Fast-SCNN受益于跳过连接,尤其是在边界和小尺寸目标处。
由于Cityscapes的城市道路和ImageNet的分类任务之间的重叠是有限的,因此可以合理地假设,由于两个领域的容量有限,Fast-SCNN可能不会受益。因此,我们现在合并了Cityscapes提供的20000张粗略标记的额外图像,因为这些图像来自类似的领域。然而,使用粗略训练数据(使用或不使用ImageNet)训练的Fast-SCNN表现相似,并且在没有预训练的情况下仅比原始Fast-SCNN略有改进。请注意,小的变化是微不足道的,并且是由于DCNN的随机初始化。
这里值得注意的是,处理辅助任务并非易事,因为它需要对网络中的体系结构进行修改。此外,许可证的限制和资源的缺乏进一步限制了这种设置。这些成本是可以节省的,因为我们表明,ImageNet预训练和弱标记数据对我们的低容量DCNN都没有显著的好处。图4显示了训练曲线。由于标签质量较弱,具有粗略数据训练的Fast-SCNN在迭代方面较慢。两个ImageNet预训练版本在早期时期表现更好(仅训练集就有多达400个时期,使用额外的粗略标记数据训练时有100个时期)。这意味着,当我们从头开始训练模型时,我们只需要训练模型更长的时间就可以达到类似的精度。

图4. Cityscapes上的训练曲线。显示了迭代的准确性(顶部)和时期的准确性(底部)。虚线表示Fast-SCNN的ImageNet预训练。
4.4 更低的输入分辨率
由于我们对可能没有全分辨率输入或无法访问强大GPU的嵌入式设备感兴趣,我们通过研究一半和四分之一输入分辨率的性能来结束我们的评估(表7)。
在四分之一分辨率下,Fast-SCNN在485.4帧/秒的速度下实现了51.9%的准确率,这显著提高了在(匿名)MiniNet上40.7%的mIoU在250帧/秒[6]。在半分辨率下,可以达到285.8帧/秒的62.8%mIoU。我们强调,在没有修改的情况下,Fast-SCNN直接适用于较低的输入分辨率,使其非常适合嵌入式设备。

图5. Fast-SCNN在Cityscapes[6]验证集上的定性结果。第一列:输入RGB图像;第二栏:真值标签;最后一列:Fast-SCNN输出。Fast-SCNN获得了68.0%的类级mIoU和84.7%的类别级mIoU。

表7. Fast-SCNN在Cityscapes测试集上不同输入分辨率下的运行时间和准确性[6]。
5. 结论
我们提出了一种用于上述实时场景理解的快速分割网络。共享多分支网络的计算成本产生运行时效率。在实验中,我们的跳跃连接被证明有利于恢复空间细节。我们还证明,如果训练足够长的时间,那么对于低容量网络来说,就不需要对模型进行额外辅助任务的大规模预训练。
References
[1] M. Abadi and et. al. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. 6
[2] V. Badrinarayanan, A. Kendall, and R. Cipolla. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. TPAMI, 2017. 1, 2, 6
[3] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs, 2014. 2
[4] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv:1606.00915 [cs], 2016. 2, 3, 5, 6
[5] F. Chollet. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv:1610.02357 [cs], 2016. 3, 4
[6] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 2, 5, 6, 8
[7] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation, 2013. 3, 6
[8] S. Han, H. Mao, and W. J. Dally. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. In ICLR, 2016. 3
[9] K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. arXiv:1512.03385 [cs], 2015. 2
[10] A. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv:1704.04861 [cs], 2017. 2, 3, 4, 5, 6
[11] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio. Binarized Neural Networks. In NIPS. 2016. 3
[12] S. Ioffe and C. Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv:1502.03167 [cs], 2015. 4, 5
[13] S. Lazebnik, C. Schmid, and J. Ponce. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In CVPR, volume 2, pages 2169–2178, 2006. 2
[14] H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf.Pruning Filters for Efficient ConvNets. In ICLR, 2017. 3
[15] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. 2015. 2
[16] A. Lucchi, Y. Li, X. B. Bosch, K. Smith, and P. Fua. Are spatial and global constraints really necessary for segmentation? In ICCV, 2011. 2
[17] D. Mazzini. Guided Upsampling Network for Real-Time Semantic Segmentation. In BMVC, 2018. 1, 2, 3, 4, 5, 6
[18] S. Mehta, M. Rastegari, A. Caspi, L. Shapiro, and H. Hajishirzi. ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. arXiv:1803.06815 [cs], 2018. 2
[19] C. Olah, A. Mordvintsev, and L. Schubert. Feature visualization. Distill, 2017. 1, 3, 4
[20] A. Paszke, A. Chaurasia, S. Kim, and E. Culurciello. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv:1606.02147 [cs], 2016. 1, 2, 3, 6
[21] R. Poudel, U. Bonde, S. Liwicki, and S. Zach. Contextnet: Exploring context and detail for semantic segmentation in real-time. In BMVC, 2018. 1, 2, 3, 4, 5, 6
[22] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In ECCV, 2016. 3
[23] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016. 2
[24] J. Redmon and A. Farhadi. Yolo9000: Better, faster, stronger, 2016. 2
[25] E. Romera, J. M. ´Alvarez, L. M. Bergasa, and R. Arroyo. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Transactions on Intelligent Transportation Systems, 2018. 1, 2, 6
[26] O. Ronneberger, P. Fischer, and T. Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation. In MICCAI, 2015. 2, 3, 5
[27] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 2015. 2, 3, 6
[28] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. arXiv:1801.04381 [cs], 2018. 2, 3, 4, 6
[29] E. Shelhamer, J. Long, and T. Darrell. Fully convolutional networks for semantic segmentation. PAMI, 2016. 1, 2, 3, 5
[30] L. Sifre. Rigid-motion scattering for image classification. PhD thesis, 2014. 2
[31] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014. 2
[32] F. Visin, M. Ciccone, A. Romero, K. Kastner, K. Cho, Y. Bengio, M. Matteucci, and A. Courville. Reseg: A recurrent neural network-based model for semantic segmentation, 2015. 2
[33] S. Wu, G. Li, F. Chen, and L. Shi. Training and Inference with Integers in Deep Neural Networks. In ICLR, 2018. 3
[34] C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, and N. Sang. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In ECCV, 2018. 1, 2, 3, 4, 5, 6
[35] M. D. Zeiler and R. Fergus. Visualizing and Understanding Convolutional Networks. In ECCV, 2014. 1, 3, 4, 5
[36] H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In ECCV, 2018. 1, 2, 3, 4, 6
[37] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid Scene Parsing Network. In CVPR, 2017. 2, 3, 4, 5, 6
[38] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. S. Torr. Conditional random fields as recurrent neural networks. In ICCV, December 2015. 2