拥有青春的时候
你就要感受它
不要浪费你的黄金时代
把宝贵的内在生命活出来
什么都别错过
一、项目介绍与环境配置
github地址
选择5.0版本的tag,并下载源码
使用Pycharm打开代码
选择解释器,我选择的是之前conda创建的pytorch环境
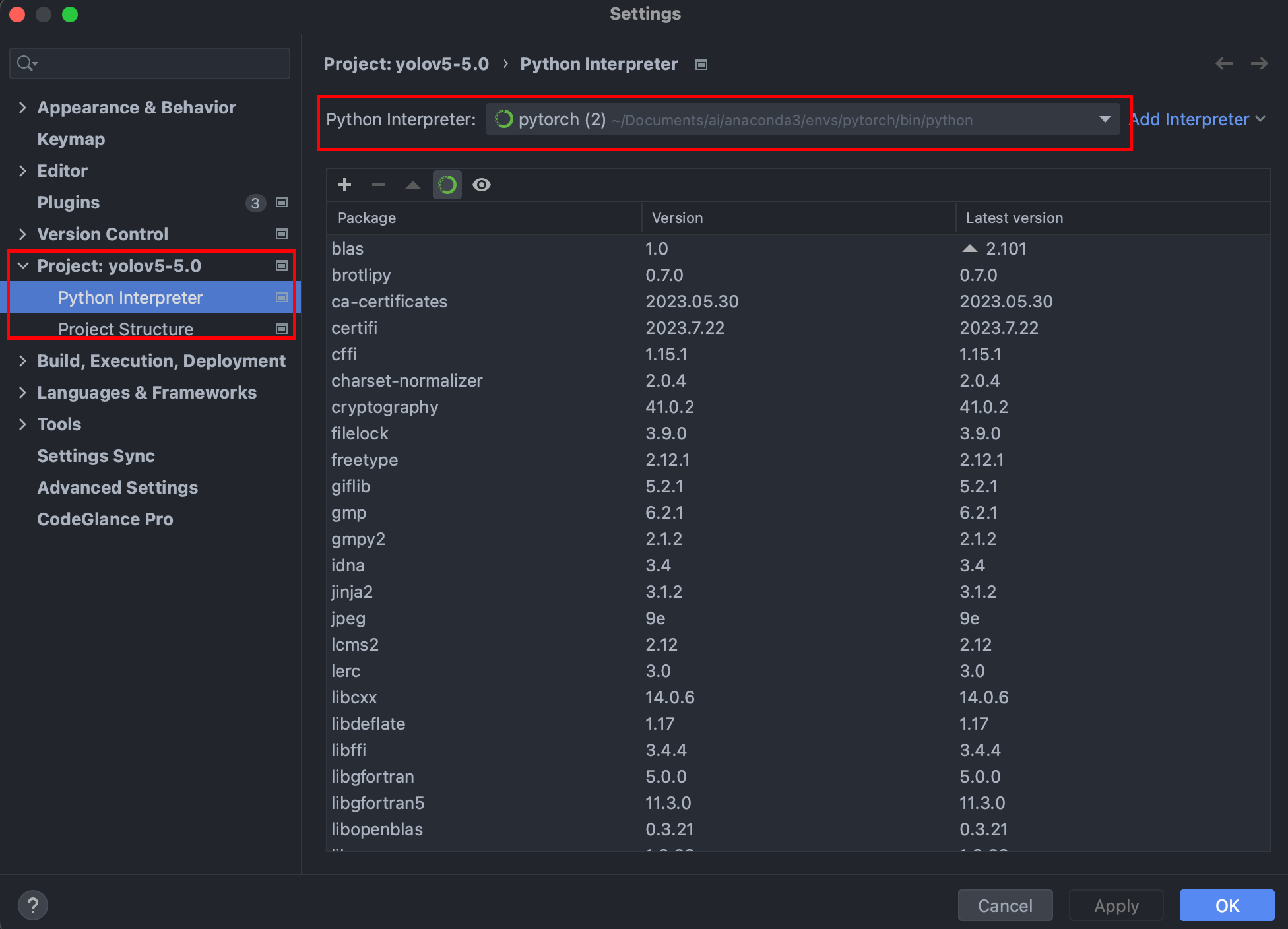
安装项目所需要用到的包
打开项目的requirements.txt文件,里面有运行项目所需要的包,这是一个好的编码习惯,自己写的代码也可以这样做。
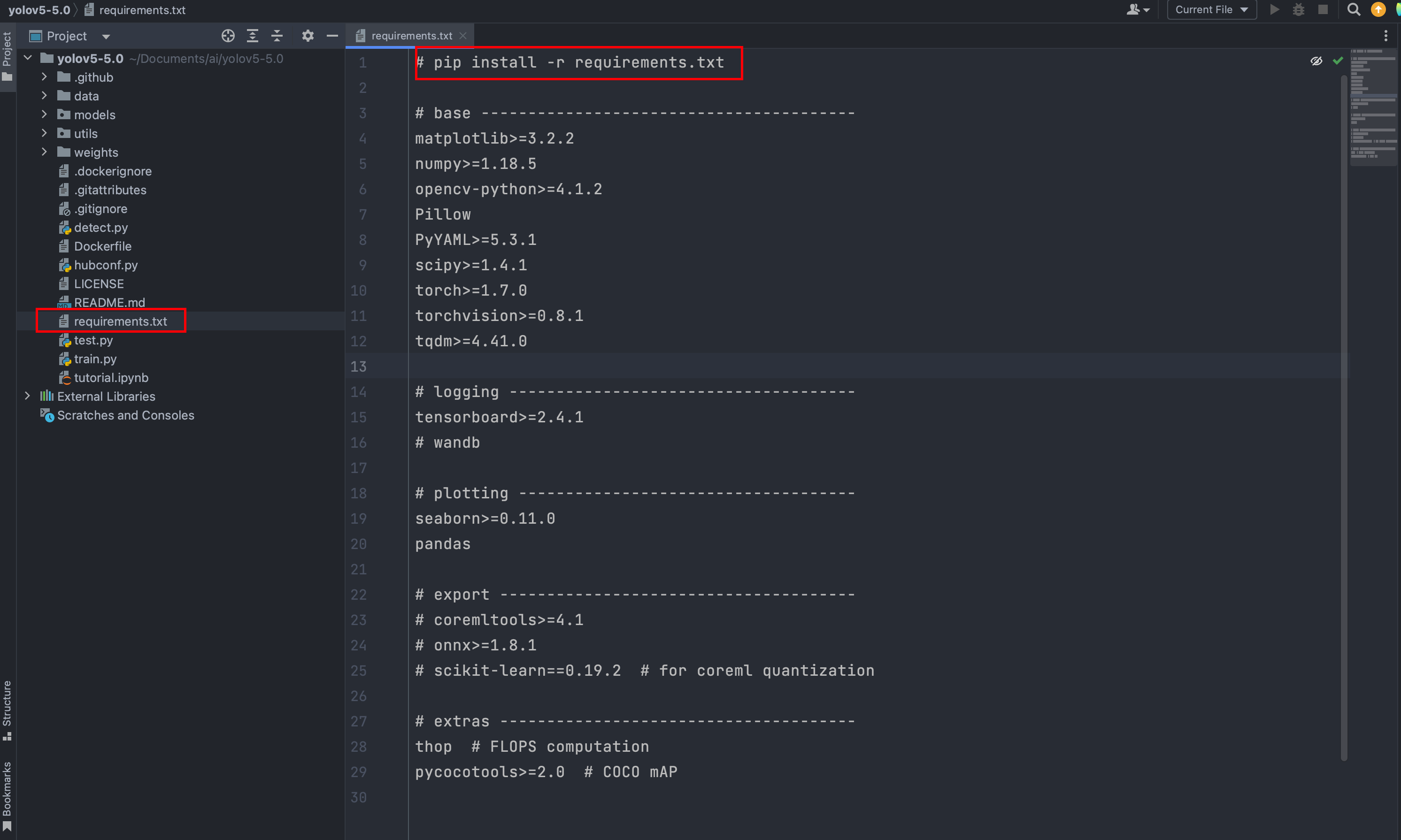
然后在终端运行下载代码
二、利用YOLOv5进行预测
找到detect.py文件,运行代码
可能出现的错误1:
AttributeError: Can't get attribute 'SPPF' on <module 'models.common' from '
解决方案:
1. 自己在官网下载对应的yolov5s.pt模型,然后放到项目里去(推荐)。
2. 按下面方式修改项目代码

增加代码
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))可能出现的错误2:
File "/Users/lihui/Documents/ai/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/upsampling.py", line 157, in forward
recompute_scale_factor=self.recompute_scale_factor)
File "/Users/lihui/Documents/ai/anaconda3/envs/pytorch/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1614, in __getattr__
raise AttributeError("'{}' object has no attribute '{}'".format(
AttributeError: 'Upsample' object has no attribute 'recompute_scale_factor'
随着路径找到对应的文件

找到出问题的代码,删掉
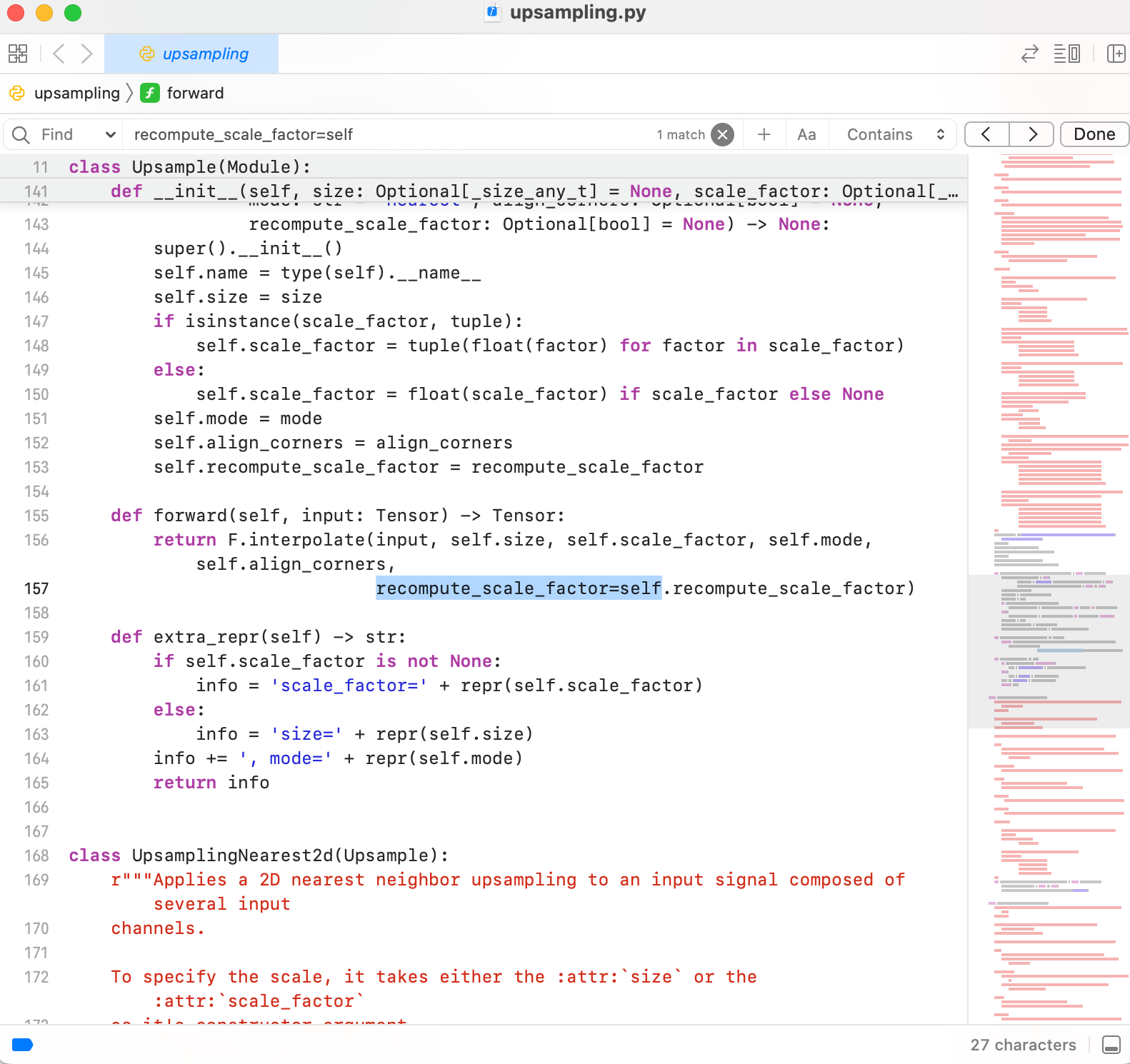
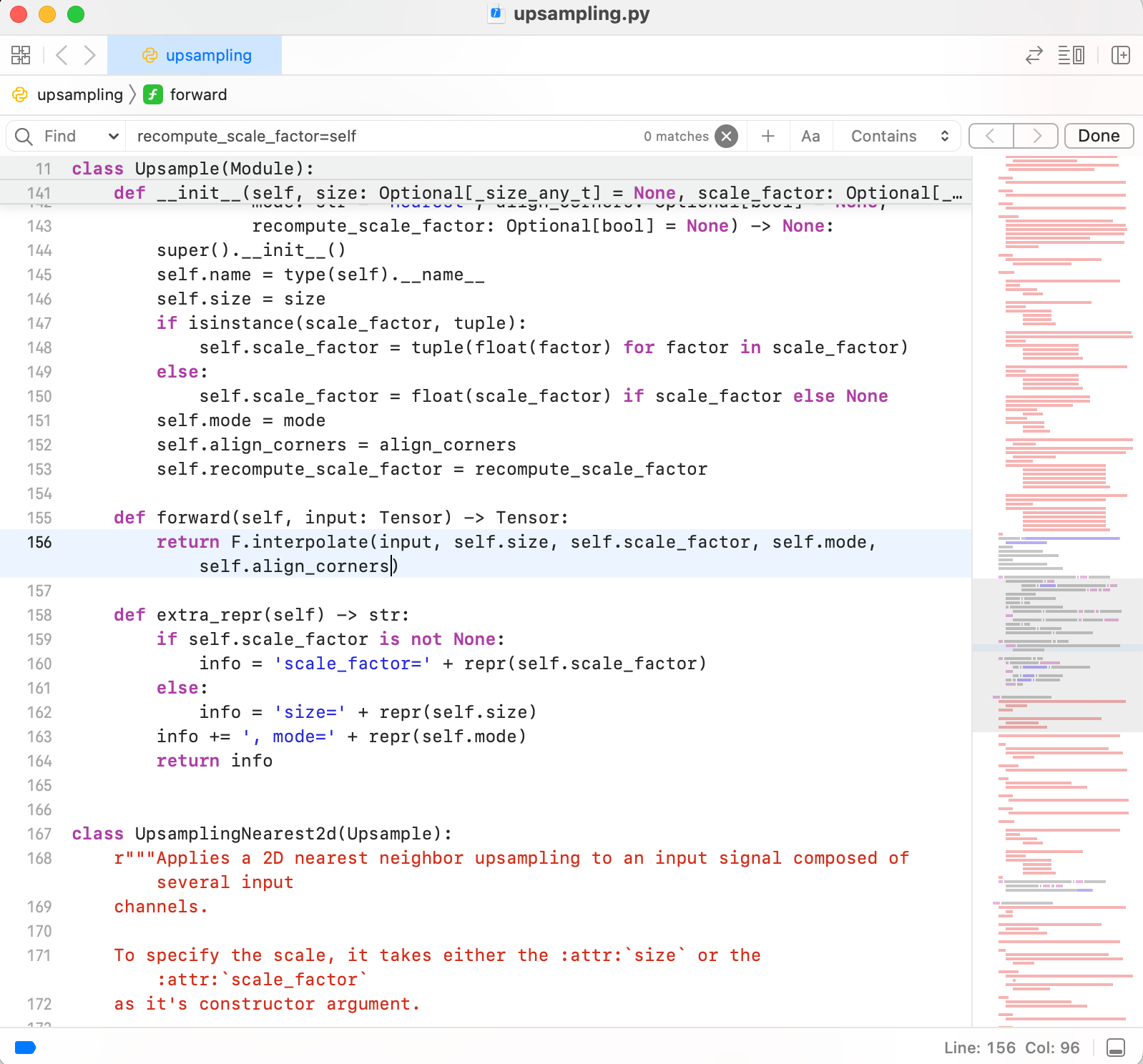
应该是python版本导致的问题。
修改完报错之后,再次运行代码

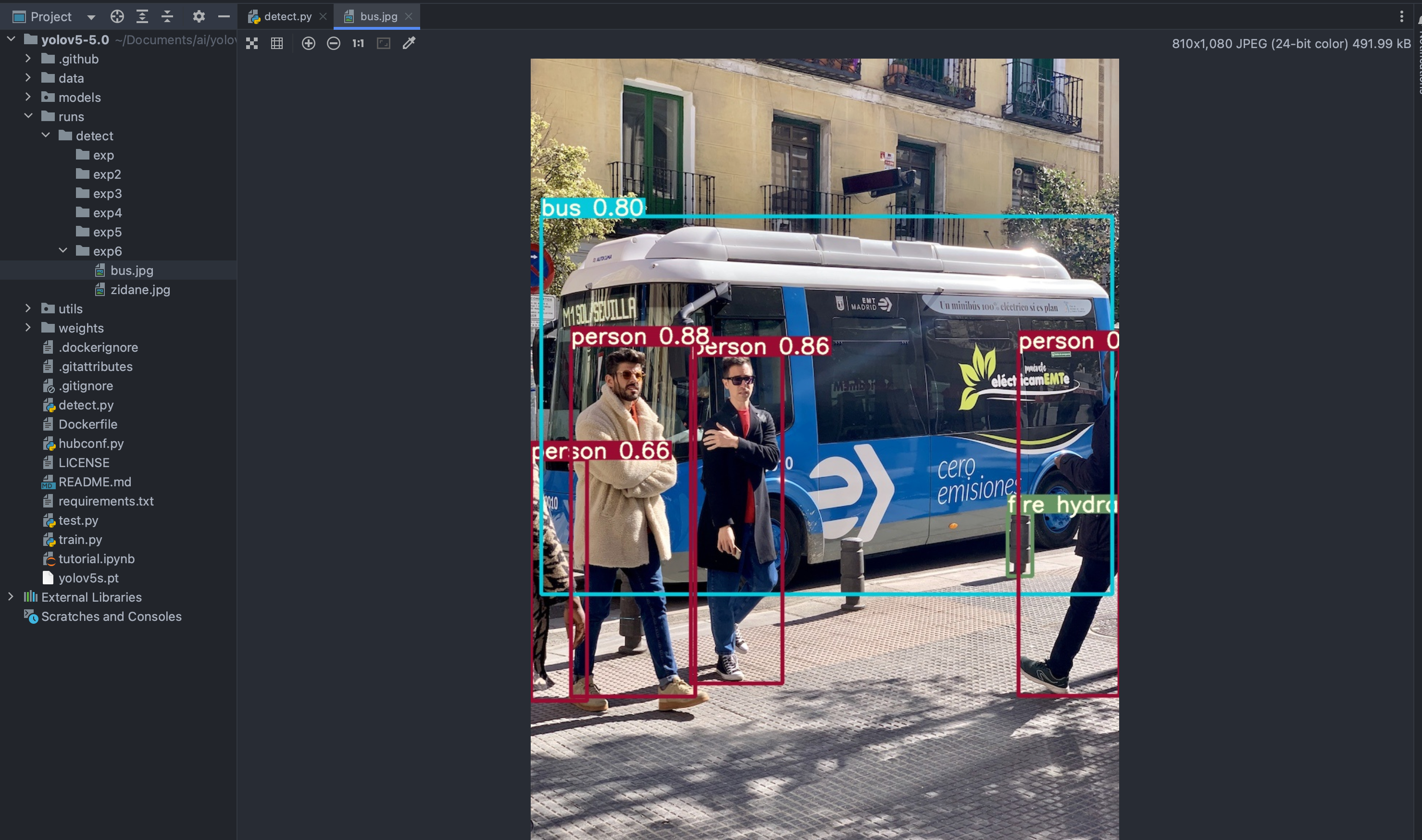

使用不同的模型进行训练,得出的效果不一样。
如我下载下面四个模型,进行测试
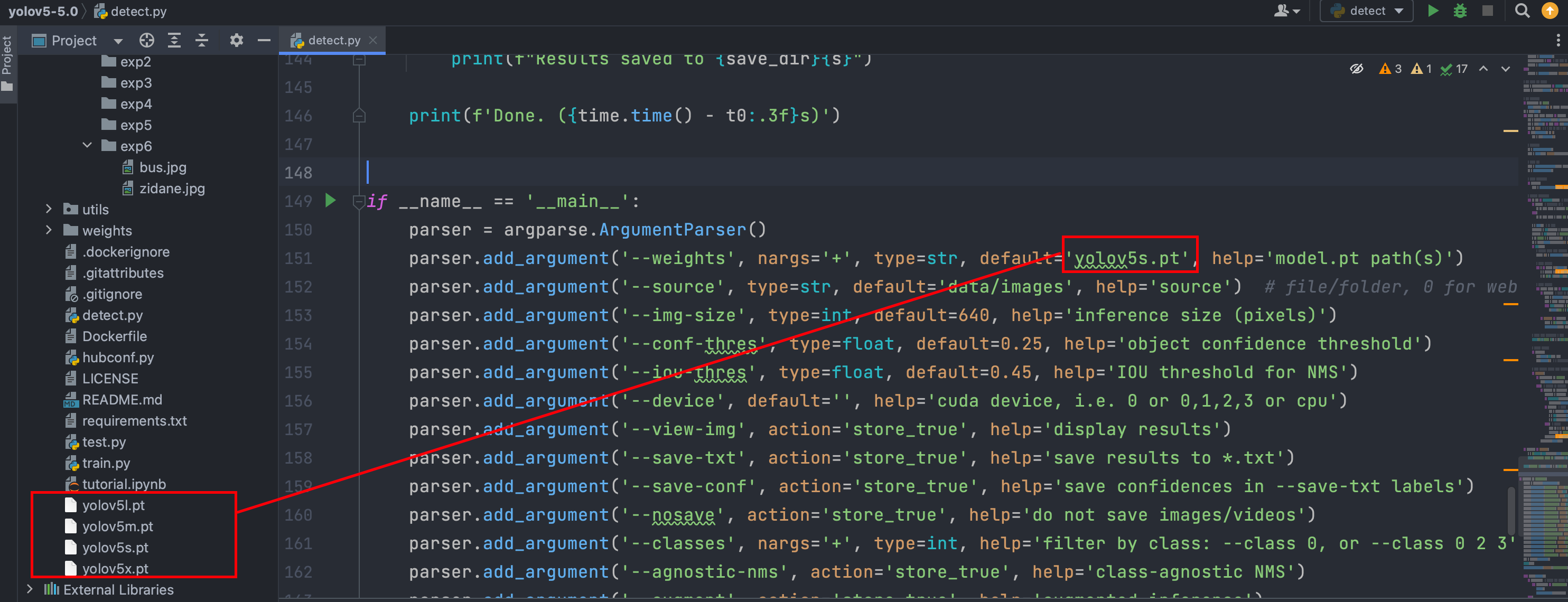
训练顺序依次为5s、5m、5l、5x


可以看出选择复杂度更高的模型,训练时间更久,但是效果更好。
检测视频
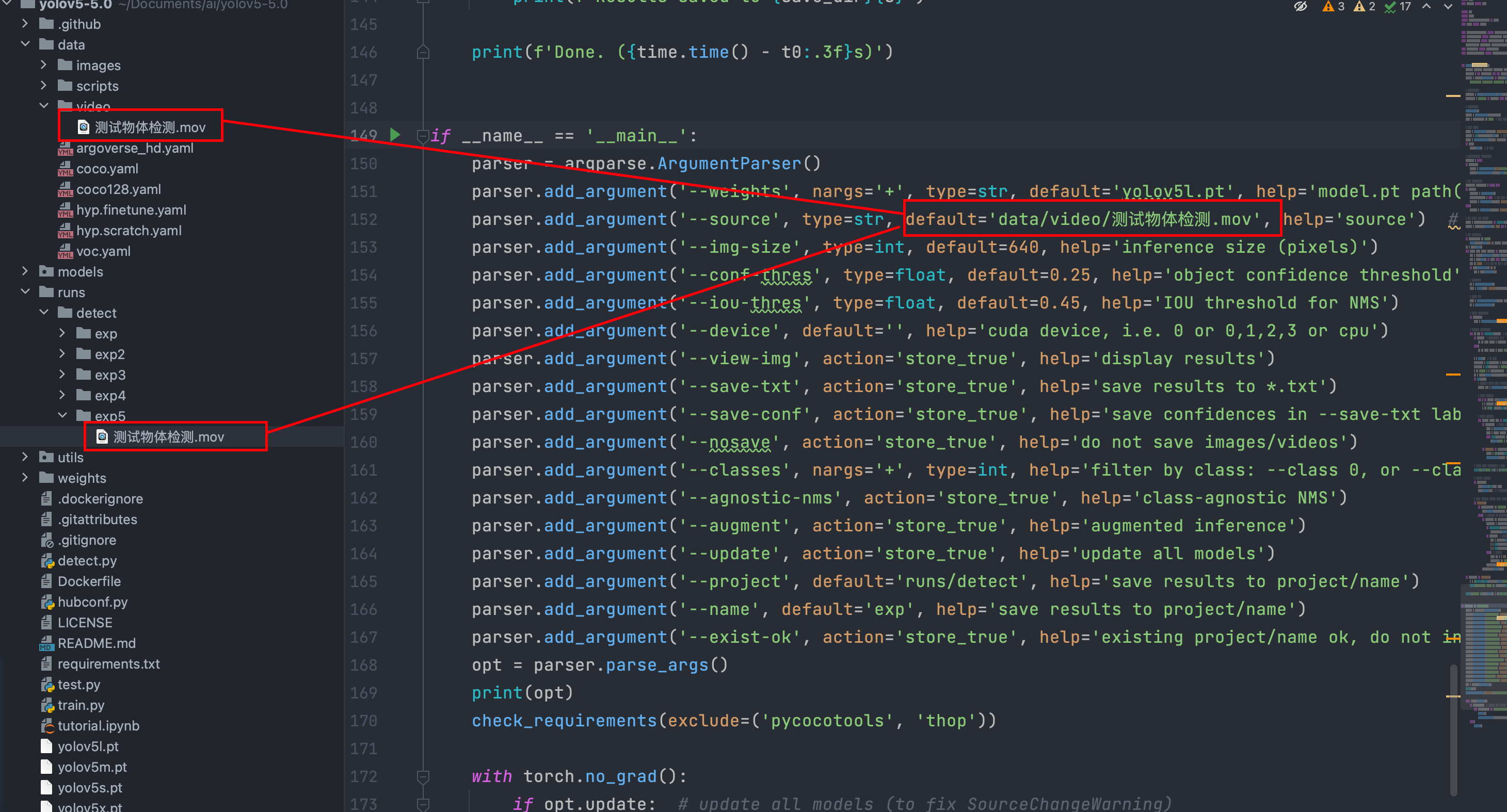
检测模型会将视频一帧一帧地进行检测,最后将结果输出出来。
进阶玩法
手机下载APP ip摄像头
然后让服务和手机在同一个局域网下,代码的路径改为
http://admin:admin@手机上打开之后显示的IP地址,就能通过手机进行实时的物体检测。
同样,如果要实时检测摄像头拍摄的物体,可以将路径改为摄像头推过来的RTSP流。
参数解释
--weights:模型权重文件的路径。就是使用什么模型来跑,可以指定一个或多个路径,用空格分隔。
--source:数据源的路径或URL。可以是文件夹路径、视频文件路径或者网络摄像头的URL。
--img-size:推理时输入图像的大小(像素)。默认为640。
--conf-thres:目标置信度阈值。检测到的目标的置信度必须大于此阈值才会被接受。比如你检测人的置信度设置为0.8,那么在检测中只有大于0.8概率的才会被检测框框出来。
--iou-thres:非最大值抑制(NMS)的IOU阈值。交并集,取检测最接近的一个检测框。
--device:设备选择,可以是CUDA设备的索引(如0)或者多个设备的索引(如0,1,2,3),也可以是cpu。默认为空字符串,表示使用默认设备。
--view-img:显示结果图像。如果设置了该参数,在跑代码的时候会实时显示检测结果的图像。
--save-txt:保存结果到.txt文件。如果设置了该参数,则会将检测结果保存为文本文件。
--save-conf:在保存的.txt标签中保存置信度。如果设置了该参数,则会在保存的文本标签中包含目标的置信度。
--nosave:不保存图像/视频。如果设置了该参数,则不会保存检测结果的图像或视频。
--classes:按类别过滤。可以指定一个或多个类别的索引,用空格分隔。例如,--classes 0表示只保留类别索引为0的目标。每一个类别的值,比如人的类别是0,如果你设置了classes 0,那么只会检测人。
--agnostic-nms:类别不可知的NMS。如果设置了该参数,则使用类别不可知的非最大值抑制。
--augment:增强推理。如果设置了该参数,则在推理过程中使用数据增强技术,更准确。
--update:更新所有模型。如果设置了该参数,则会更新所有模型。没啥用。
--project:结果保存的项目路径。默认为runs/detect。
--name:结果保存的名称。默认为exp。
--exist-ok:允许覆盖现有的项目/名称。如果设置了该参数,则不会增加项目/名称的后缀。参数设置tips:

在这里设置你需要的参数,这样每次跑项目你就不用每次在命令行手敲了。
三、训练YOLOv5神经网络
打开train.py训练文件
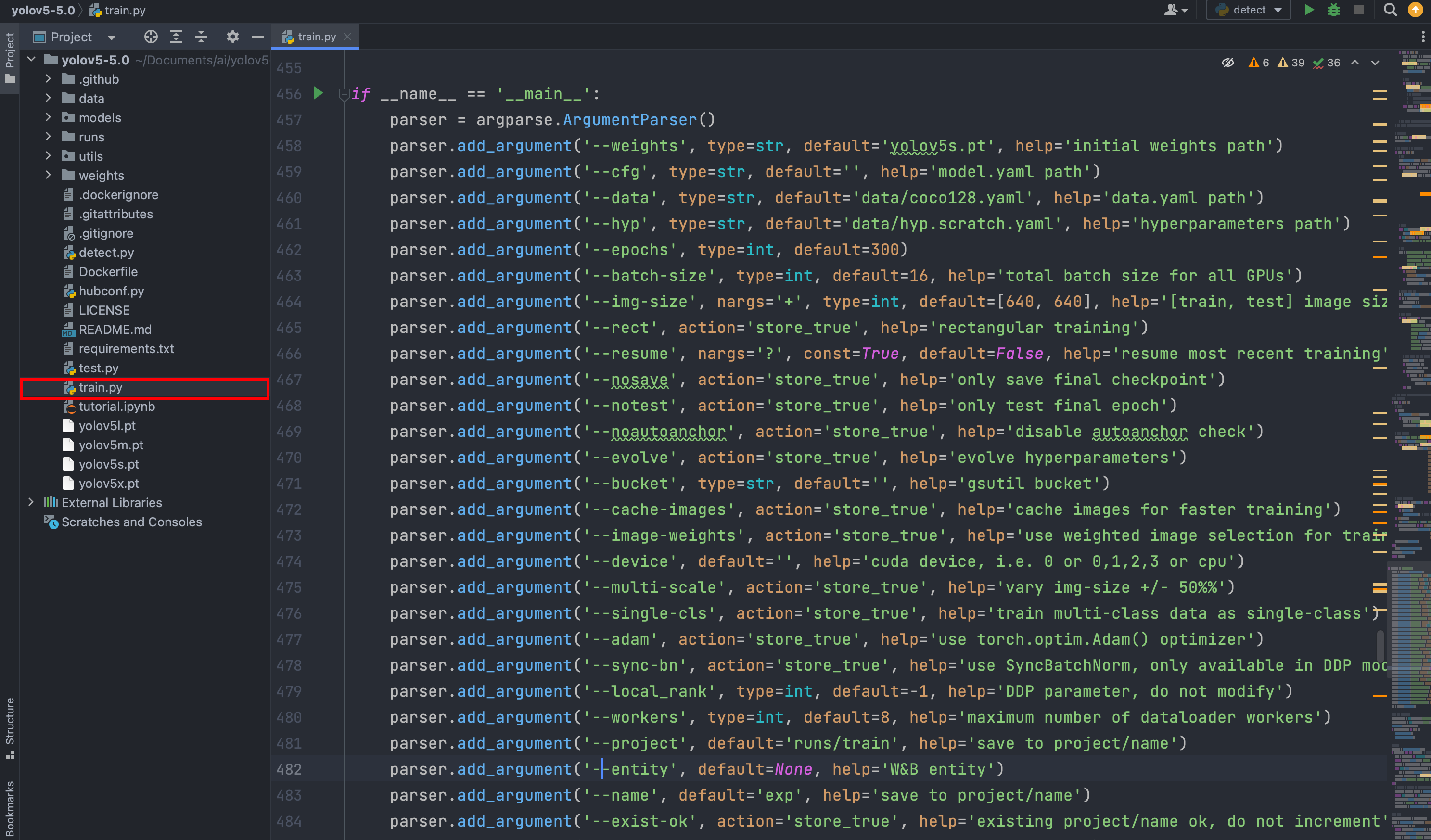
参数解释
- `--weights`:初始权重文件的路径。选择训练模型,默认为`yolov5s.pt`。
- `--cfg`:模型配置文件(`model.yaml`)的路径。
- `--data`:数据集配置文件(`data.yaml`)的路径。默认为`data/coco128.yaml`。
- `--hyp`:超参数文件的路径。默认为`data/hyp.scratch.yaml`。
- `--epochs`:训练的总轮数,默认为300。
- `--batch-size`:每个批次的样本数。默认为16。
- `--img-size`:训练和测试图像的尺寸。可以指定一个或两个整数值作为列表,例如`--img-size 640 640`。默认为`[640, 640]`。
- `--rect`:使用矩形训练。如果设置了该参数,则训练过程中使用矩形图像而不是正方形图像。不是矩阵的会自动进行填充。
- `--resume`:恢复最近的训练。如果设置了该参数,则会恢复最近一次的训练。
- `--nosave`:只保存最终的检查点。如果设置了该参数,则只保存最后一个轮次的模型检查点。
- `--notest`:只测试最终的轮次。如果设置了该参数,则只在最后一个轮次进行测试。
- `--noautoanchor`:禁用自动锚框检查。
- `--evolve`:演化超参数。如果设置了该参数,则会根据训练过程中的结果自动调整超参数。
- `--bucket`:Google Cloud Storage(GCS)存储桶的路径。
- `--cache-images`:缓存图像以加快训练速度。
- `--image-weights`:使用加权的图像选择进行训练。
- `--device`:设备选择,可以是CUDA设备的索引(如`0`)或者多个设备的索引(如`0,1,2,3`),也可以是`cpu`。
- `--multi-scale`:变化的图像尺寸。如果设置了该参数,则训练过程中会随机调整图像尺寸的大小。
- `--single-cls`:将多类别数据作为单一类别进行训练。
- `--adam`:使用`torch.optim.Adam()`优化器。
- `--sync-bn`:使用`SyncBatchNorm`,只在DDP模式下可用。
- `--local_rank`:DDP参数,不要修改。
- `--workers`:最大数据加载器的工作进程数。
- `--project`:保存结果的项目路径。默认为`runs/train`。
- `--entity`:W&B实体。
- `--name`:保存结果的名称。默认为`exp`。
- `--exist-ok`:允许覆盖现有的项目/名称。
- `--quad`:使用四分之一的数据加载器。
- `--linear-lr`:使用线性学习率。
- `--label-smoothing`:标签平滑的ε值。
- `--upload_dataset`:将数据集上传为W&B的artifact表格。
- `--bbox_interval`:设置W&B的边界框图像日志记录间隔。
- `--save_period`:每隔多少轮保存一次模型。
- `--artifact_alias`:数据集artifact的版本别名。
云端GPU训练模型
谷歌提供的免费网站
官网地址
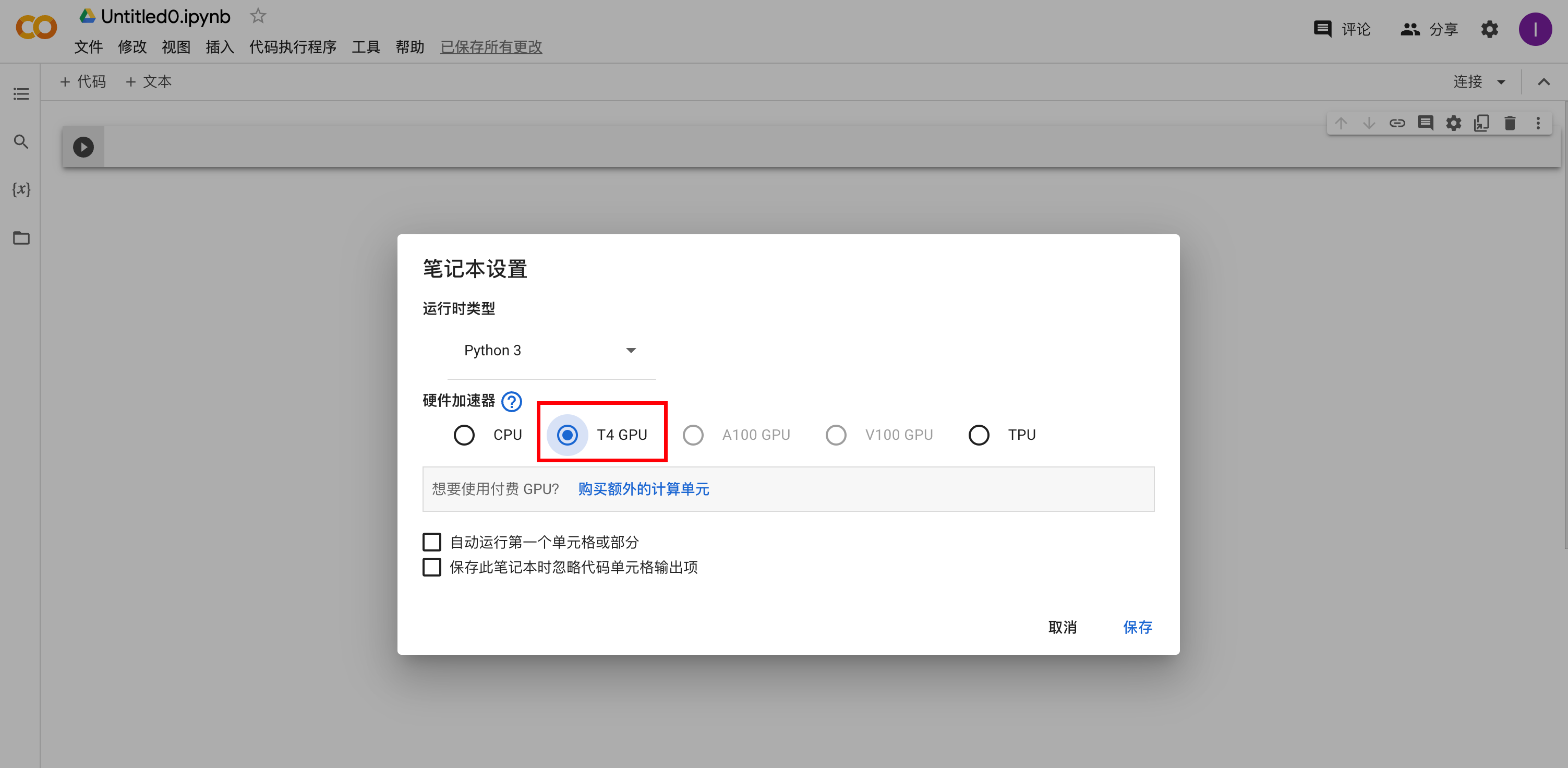
将项目打包上传(把不需要的模型与视频删了再打包)
解压缩命令
!unzip /content/yolov5-5.0.zip
删除文件命令
!rm -rf /content/__MACOSX

安装运行代码所需要的环境
%cd /content/yolov5-5.0
!pip install -r requirements.txt
使用tensorboard实时查看运行情况
%load_ext tensorboard
%tensorboard --logdir=runs/train
运行训练代码
!python train.py --rect
训练完之后可以将模型进行导出 best.pt
四、制作和训练自己的数据集
查看下面这篇文章
最后只需要将自己标注好的数据集放到指定的路径,随后在yaml文件中修改需要训练的路径位置即可。



![[Flask]SSTI1](https://img-blog.csdnimg.cn/66adca4e15724872b6c2185a4acbc41e.png)





![P1049 [NOIP2001 普及组] 装箱问题(背包)(内附封面)](https://img-blog.csdnimg.cn/648c53ec579c42c89934a48d3c91760b.png)