今天需要读入xml文件进行处理,结果读入一个带中文的文件时,出错了。当然程序还能运行,但编译器一直报错,而且XML解析也不正确
单步调试发现读入的内容出现乱码,具体逻辑:
String FileAccess::get_as_text(bool p_skip_cr) const {
uint64_t original_pos = get_position();
const_cast<FileAccess *>(this)->seek(0);
String text = get_as_utf8_string(p_skip_cr);
const_cast<FileAccess *>(this)->seek(original_pos);
return text;
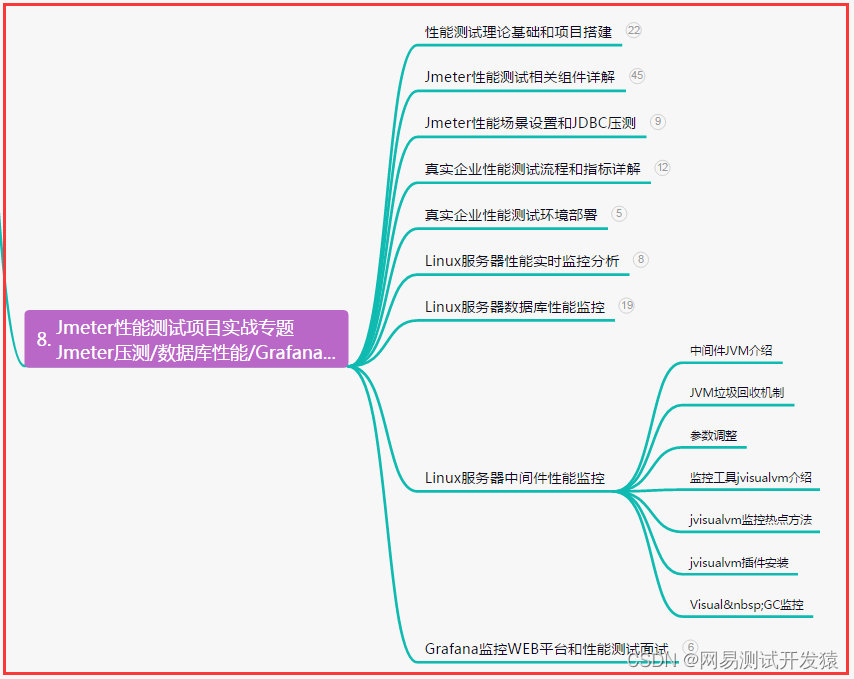
}
String FileAccess::get_as_utf8_string(bool p_skip_cr, String encoding) const {
encoding = encoding.to_lower();
Vector<uint8_t> sourcef;
uint64_t len = get_length();
sourcef.resize(len + 1);
uint8_t *w = sourcef.ptrw();
uint64_t r = get_buffer(w, len);
ERR_FAIL_COND_V(r != len, String());
w[len] = 0;
String s((const char *)w);
s.parse_utf8((const char *)w, -1, p_skip_cr);
return s;
}
Error String::parse_utf8(const char *p_utf8, int p_len, bool p_skip_cr) {
if (!p_utf8) {
return ERR_INVALID_DATA;
}
String aux;
int cstr_size = 0;
int str_size = 0;
/* HANDLE BOM (Byte Order Mark) */
if (p_len < 0 || p_len >= 3) {
bool has_bom = uint8_t(p_utf8[0]) == 0xef && uint8_t(p_utf8[1]) == 0xbb && uint8_t(p_utf8[2]) == 0xbf;
if (has_bom) {
//8-bit encoding, byte order has no meaning in UTF-8, just skip it
if (p_len >= 0) {
p_len -= 3;
}
p_utf8 += 3;
}
}
bool decode_error = false;
bool decode_failed = false;
{
const char *ptrtmp = p_utf8;
const char *ptrtmp_limit = &p_utf8[p_len];
int skip = 0;
uint8_t c_start = 0;
while (ptrtmp != ptrtmp_limit && *ptrtmp) {
uint8_t c = *ptrtmp >= 0 ? *ptrtmp : uint8_t(256 + *ptrtmp);
if (skip == 0) {
if (p_skip_cr && c == '\r') {
ptrtmp++;
continue;
}
/* Determine the number of characters in sequence */
if ((c & 0x80) == 0) {
skip = 0;
} else if ((c & 0xe0) == 0xc0) {
skip = 1;
} else if ((c & 0xf0) == 0xe0) {
skip = 2;
} else if ((c & 0xf8) == 0xf0) {
skip = 3;
} else if ((c & 0xfc) == 0xf8) {
skip = 4;
} else if ((c & 0xfe) == 0xfc) {
skip = 5;
} else {
skip = 0;
print_unicode_error(vformat("Invalid UTF-8 leading byte (%x)", c), true);
decode_failed = true;
}
c_start = c;
if (skip == 1 && (c & 0x1e) == 0) {
print_unicode_error(vformat("Overlong encoding (%x ...)", c));
decode_error = true;
}
str_size++;
} else {
if ((c_start == 0xe0 && skip == 2 && c < 0xa0) || (c_start == 0xf0 && skip == 3 && c < 0x90) || (c_start == 0xf8 && skip == 4 && c < 0x88) || (c_start == 0xfc && skip == 5 && c < 0x84)) {
print_unicode_error(vformat("Overlong encoding (%x %x ...)", c_start, c));
decode_error = true;
}
if (c < 0x80 || c > 0xbf) {
print_unicode_error(vformat("Invalid UTF-8 continuation byte (%x ... %x ...)", c_start, c), true);
decode_failed = true;
skip = 0;
} else {
--skip;
}
}
cstr_size++;
ptrtmp++;
}
if (skip) {
print_unicode_error(vformat("Missing %d UTF-8 continuation byte(s)", skip), true);
decode_failed = true;
}
}
if (str_size == 0) {
clear();
return OK; // empty string
}
resize(str_size + 1);
char32_t *dst = ptrw();
dst[str_size] = 0;
int skip = 0;
uint32_t unichar = 0;
while (cstr_size) {
uint8_t c = *p_utf8 >= 0 ? *p_utf8 : uint8_t(256 + *p_utf8);
if (skip == 0) {
if (p_skip_cr && c == '\r') {
p_utf8++;
continue;
}
/* Determine the number of characters in sequence */
if ((c & 0x80) == 0) {
*(dst++) = c;
unichar = 0;
skip = 0;
} else if ((c & 0xe0) == 0xc0) {
unichar = (0xff >> 3) & c;
skip = 1;
} else if ((c & 0xf0) == 0xe0) {
unichar = (0xff >> 4) & c;
skip = 2;
} else if ((c & 0xf8) == 0xf0) {
unichar = (0xff >> 5) & c;
skip = 3;
} else if ((c & 0xfc) == 0xf8) {
unichar = (0xff >> 6) & c;
skip = 4;
} else if ((c & 0xfe) == 0xfc) {
unichar = (0xff >> 7) & c;
skip = 5;
} else {
*(dst++) = 0x20;
unichar = 0;
skip = 0;
}
} else {
if (c < 0x80 || c > 0xbf) {
*(dst++) = 0x20;
skip = 0;
} else {
unichar = (unichar << 6) | (c & 0x3f);
--skip;
if (skip == 0) {
if (unichar == 0) {
print_unicode_error("NUL character", true);
decode_failed = true;
unichar = 0x20;
}
if ((unichar & 0xfffff800) == 0xd800) {
print_unicode_error(vformat("Unpaired surrogate (%x)", unichar));
decode_error = true;
}
if (unichar > 0x10ffff) {
print_unicode_error(vformat("Invalid unicode codepoint (%x)", unichar));
decode_error = true;
}
*(dst++) = unichar;
}
}
}
cstr_size--;
p_utf8++;
}
if (skip) {
*(dst++) = 0x20;
}
if (decode_failed) {
return ERR_INVALID_DATA;
} else if (decode_error) {
return ERR_PARSE_ERROR;
} else {
return OK;
}
}
其实已经读入到w里,但String::parse_utf8出错。
回头看了一下,原目标文件为GB2312编码。而Godot的FileAccess不支持别的编码。
那就加上,在不影响原有逻辑的基础上,小动一下:
ClassDB::bind_method(D_METHOD("get_as_text", "skip_cr", "encoding"), &FileAccess::get_as_text, DEFVAL(false), DEFVAL("utf-8"));
String FileAccess::get_as_text(bool p_skip_cr, String encoding) const {
uint64_t original_pos = get_position();
const_cast<FileAccess *>(this)->seek(0);
String text = get_as_utf8_string(p_skip_cr, encoding);
const_cast<FileAccess *>(this)->seek(original_pos);
return text;
}
String FileAccess::get_as_utf8_string(bool p_skip_cr, String encoding) const {
encoding = encoding.to_lower();
Vector<uint8_t> sourcef;
uint64_t len = get_length();
sourcef.resize(len + 1);
uint8_t *w = sourcef.ptrw();
uint64_t r = get_buffer(w, len);
ERR_FAIL_COND_V(r != len, String());
w[len] = 0;
if (encoding == "gb2312") {
std::string str((const char *)w);
String s(str);
return s;
}
String s((const char *)w);
s.parse_utf8((const char *)w, -1, p_skip_cr);
return s;
}
GDScript中调用:
var xml : Xml = Xml.new("D:\\ExenObj\\Exe\\DrGraph\\Files\\Demo.sch")
xml.Read("gb2312");
class Xml:
var RootNode: XmlNode = null
var FileName: String = ""
func _init(fileName: String) -> void:
FileName = fileName
func Read(encoding: String = "utf-8") -> void:
if FileAccess.file_exists(FileName):
var fs = FileAccess.open(FileName, FileAccess.READ)
var text = fs.get_as_text(false, encoding)
var textStart = Helper.RegMatchAt(text, "<[^!?]")
var pos = 0;
if textStart.length() > 0:
pos = text.find(textStart)
if pos > 0:
var header = text.substr(0, pos - 1)
text = text.substr(pos)
var from = 0
while pos > 0:
pos = header.find("<!", from)
if pos == -1:
break
from = pos + 1
pos = header.find("\n", from)
var str = header.substr(from, pos - from)
var entityName = Helper.RegMatchAt(str, "Cbw.*?(?= )")
var value = Helper.RegMatchAt(str, "(?<=').*?(?=')")
if entityName.length() > 0 and value.length() > 0:
print(entityName, " = ", value)
RootNode = XmlNode.new("root");
RootNode.xml = self;
RootNode.from_string(text)
fs.close()
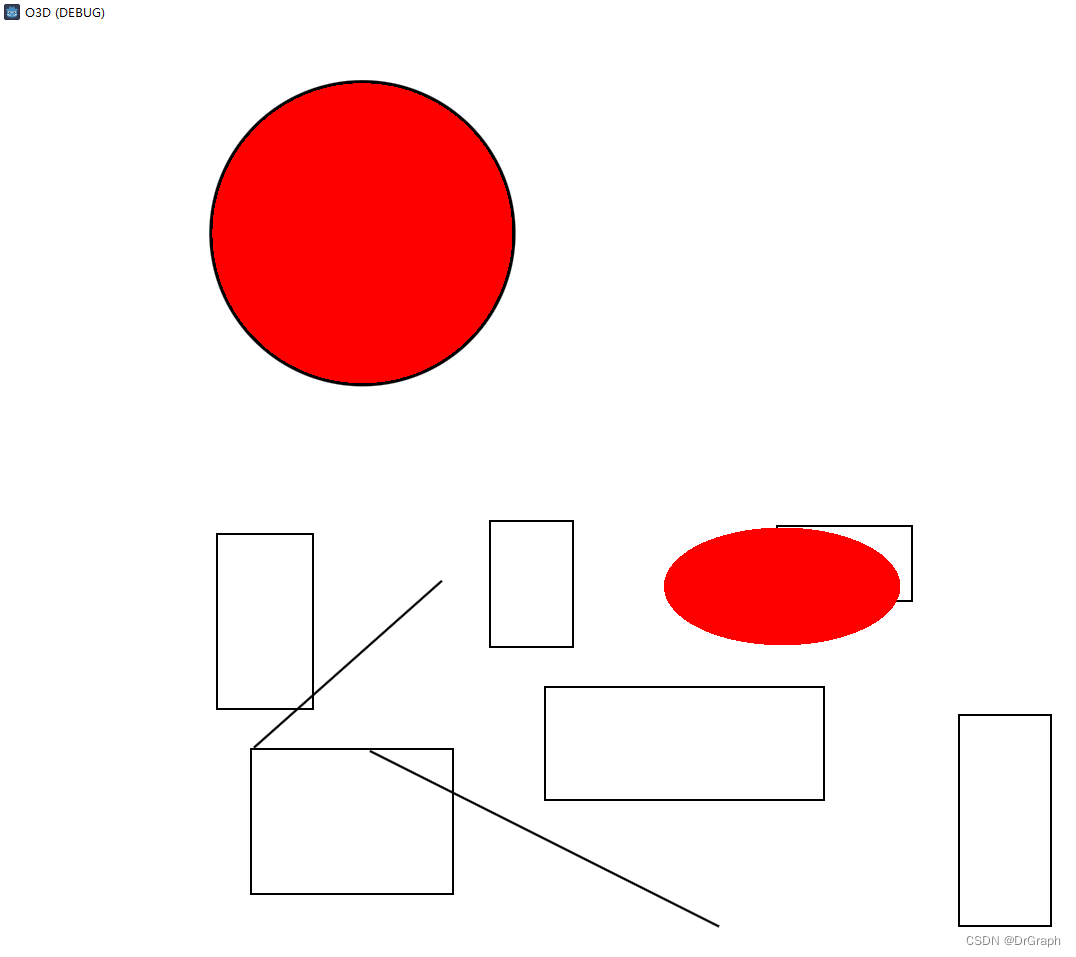
如此,恢复正常。XML文本内容解析为图形效果
<CbwObjects>
<TLine name="Line967">
<Points>
<Point x="258" y="868"/>
<Point x="606" y="1043"/>
</Points>
</TLine>
<TLine name="Line968">
<Points>
<Point x="329" y="698"/>
<Point x="142" y="864"/>
</Points>
</TLine>
<TRectangle name="Rect147">
<Points>
<Point x="433" y="804"/>
<Point x="712" y="917"/>
</Points>
</TRectangle>
<TRectangle name="Rect148">
<Points>
<Point x="378" y="638"/>
<Point x="461" y="764"/>
</Points>
</TRectangle>
<TRectangle name="Rect149">
<Points>
<Point x="105" y="651"/>
<Point x="201" y="826"/>
</Points>
</TRectangle>
<TRectangle name="Rect150">
<Points>
<Point x="139" y="1011"/>
<Point x="341" y="866"/>
</Points>
</TRectangle>
<TRectangle name="Rect151">
<Points>
<Point x="847" y="832"/>
<Point x="939" y="1043"/>
</Points>
</TRectangle>
<TRectangle name="Rect152">
<Points>
<Point x="850" y="635"/>
<Point x="985" y="710"/>
</Points>
</TRectangle>
<TEllipse name="Ellipse74">
<Points>
<Point x="551.451219512195" y="644.367464840815"/>
<Point x="788" y="762"/>
</Points>
</TEllipse>
<TLine name="Line799" pen="&CbwPen0;">
<Points>
<Point x="230" y="46"/>
<Point x="417" y="284"/>
</Points>
</TLine>
</CbwObjects>