ABAP程序基本上都需要从数据库里面抓数,所以性能很重要,同时有一些基本的,和优秀的写法是我们必须要掌握的,不然就会造成程序性能很差。下面给予总结(这里包括有很基本的,也包括有比较少用到的),顺便推荐一个好的SAP标准文档 ABAP_PERFORMANCE_DOS_AND_DONTS :
一、基本的几条需要避免的规则(具体的一些怎么替换,可以看三和五):
1、不使用select....endselect,估计月球人都知道这个事实了。
2、基本不使用select * ,跟多人喜欢直接用这个,因为方便,但是在数据量比较大的时候,应该使用select 字段,这样可以避免抓取无用数据。
3、LOOP 里面不用sort ,在loop外面排序完再进入LOOP。
4、尽量避免LOOP 里面嵌套select,这样多次访问数据库也会造成性能问题,但是有些时候避免不了也难免。改为外面select,LOOP里面read table。
5、大数据的read table,使用二分法 BINARY SEARCH,用之前要按关键字排序。
6、尽量避免LOOP里面嵌套LOOP,特别是当两个内表数据量都很大的时候,如果实在要嵌套LOOP可以参考三和五里面的解决办法。
7、尽量避免LOOP里面不用delete,append等语句。改成批量处理。
二、index和buffer的合理使用:
1、index的使用,在使用现有的index的时候注意,where条件里面的字段的顺序要跟index一致,而且可以可以适当的去匹配index,创建一些空的字段或者是index后面再加字段,或者是使用index抓出数据后,再去做其它条件的处理。
2、index里面最好只有'=' AND 或者是‘IN’。有其它逻辑条件,会影响index的使用。
3、 如果表是有buffer,可以考虑使用buffer,这样性能也可以有很好的提升,不过首先要去表看看这个是否有buffer:
SELECT SINGLE * FROM T100 INTO T100_WA
BYPASSING BUFFER
WHERE SPRSL = 'D'.
4、大部分表都有buffer,而且这个我们很难控制,但是我们写出来的语句要经可能的避免“不读buffer”:

5、一般程序到表抓数的时候,会在应用服务层有数据缓存,所以同一个程序,在不同时间先后跑,后面的通常会比较快,因为可以到数据缓存读数。
6、NOT,只能全表扫描,不要用not,换成反面。建议between 换成IN。不建议使用LIKE OR
三、使用一些简单的语句代替复杂的嵌套LOOP:
1、用批量处理的BAPI替换,LOOP 里面call BAPI,例如用BAPI_MATERIAL_SAVEREPLICA 替代 BAPI_MATERIAL_SAVEDATA
2、LOOP 里面delete,可以改成,给内表加一个flag的字段,然后需要删除的打上X,然后用Delete it_1 where delete = ‘X’.
3、LOOP AT 搭INSERT或者是APPEND,可以改成: INSERT SBOOK FROM TABLE itab。 APPEND LINES
4、如果是两个内表都很多数据,但是逻辑要进行嵌套LOOP,可以如下处理,会提升一些性能:
方法一:
sort itab2 by aa. 这个地方看上去像是两个LOOP,其实是只有一个。
loop itab1
read itab2 aa = itab-11 binary search.
loop itab2 from sy-taibx.
endloop.
endloop.方法二:

方法三:

5、LOOP 后面用assigning 指针的方式,这样也可以节省空间和时间:可以省去了append,modify等操作,在嵌套LOOP没法像上面那样解决的话,也建议使用指针。
FIELD-SYMBOLS : <fs> TYPE VBAK.
LOOP AT gt_vbak ASSIGNING <fs> Where lifsk = '01'.
<fs>-space = '02'.
ENDLOOP.四、有一些标准的FM,如果在LOOP里面使用可以考虑换成使用自己开发,把抓数放出来,然后read(read_text):
1、有很多程序要调用FM read_text,但是当用到LOOP里面调用这个read_text,会比较慢其中到STXH表抓数就会占用很多时间,我们可以考虑对read_text进行优化,把read_text分成两个FM,一个是集中读取STXH,然后另一个是和read_text一样的功能,只是把抓数换成read table。占用性能就会提高很多。
五、一些优秀的良好的ABAP 程序书写习惯:
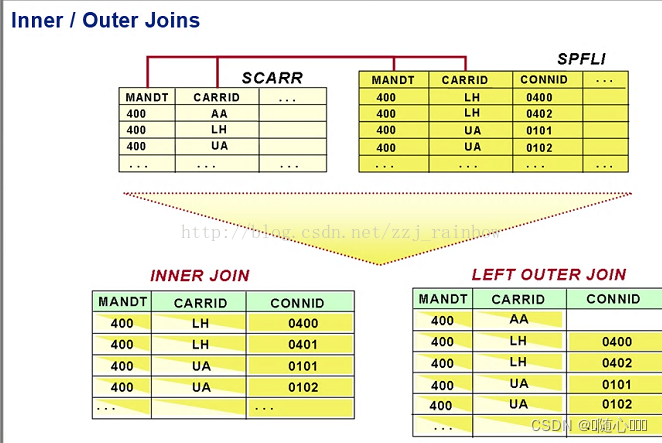
1、select 数据的时候,如果可以使用join进行内联,尽量2-3个表内联即可。下面这个图可以理解下join的用法:
有时,join太多了,也可以考虑使用创建视图,然后从视图里抓数,例如vbak_kan1。
2、如果要select 数据出来,更改一些字段的值,再进行updata,可以考虑直接使用updata set,省去到表里面抓数:
SELECT * FROM sbook
INTO xbook
WHERE carrid = 'LH' AND connid = '0400' AND fldate >= '20110101'.
xbook-connid = '0500'.
UPDATE sbook FROM xbook.
ENDSELECT.
UPDATE sbook
SET connid = '0500' WHERE carrid = 'LH' AND connid = '0400' AND fldate >= '20110101'.
3、读取HASHED表会比其他两种类型更快,同时read table 也可以通过transporting 某些字段到work area,不用全部字段都用上。
4、有些表的数据,是很固定的,例如KNA1或者是T001等,可以抓大部分数据放到内表里,然后去读取,如果读取不到,在抓,不用每次都抓。
5、强制使用索引:(但是如果更改数据库了,就会失效了) %_HINTS DB6 (这个不太建议使用,但是当ST05分析之后,是可以使用某个索引,但系统没有使用,就可以使用这个语句强制使用索引。)
6、当一个report在ALV显示完之后,在end-of-selection里面把不用的内表的清空掉,防止有些后台job一次跑两个变量的时候会重复,同时释放内表也是减少内存压力。
7、field-groups的使用,对于多层次的排序和显示非常有用。