随着信息技术的快速发展,数据量越来越大,海量的表查询操作需要消耗大量的时间,成为影响数据库访问性能提高的主要因素。为了提升数据库操作的查询效率和用户体验,在关系型数据库管理系统(MySQL)中通过 range 分区和 Merge 存储,提出优化的分区分表算法。实验证明,优化后的算法在实现大数据量的表查询操作中,工作效率明显提高。
目录
4 使用 Merge 存储引擎实现 MySQL 分表设计
4.1 创建测试表
4.2 插入记录
4.3 拆分子表实现分表
5 结论
4 使用 Merge 存储引擎实现 MySQL 分表设计
对于数据表中有自增字段,为避免数据重复,在系统设计表时利用触发器完成。Merge 查询经过分表设计后,查询速度比一张大表查询要快很多,大大提高了数据查询效率。
4.1 创建测试表
首先创建三个测试表 payment_2021、payment_2022 和 payment_all,其中 payment_all 是前两个表的merge 表(主表) :
create table payment_2021
(id smallint auto_increment primary key,payment_date datetime,amount decimal(13,2))engine = myisam character set gbk;
create table payment_all
(id smallint AUTO_INCREMENT PRIMARYKEY primary key,payment_date datetime,amount decimal(13,2)) engine = merge union = (payment_2021,
payment_2022) insert_method = last;
4.2 插入记录
分别向 payment_2021 和 payment_2022 表中添加测试数据:
insert into payment_2021(payment_date,amount)values('2021 -01 - 30',200 000),(2,'2021 - 06 -30',230 000),(3,'2021 -11 -20',260 000);
insert into payment_2022(payment_date,amount)values('2022 -02 -15',160 000),('2022 -06 -28',210 000),('2022 -12 -20',220 000. 5);
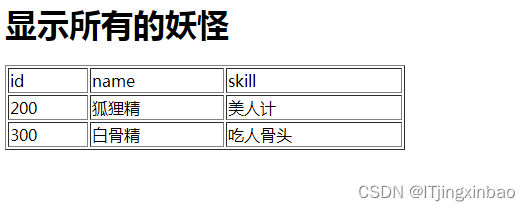
查看 payment_all 表记录,如图 4 所示。

在插入记录过程中出现了 id 重复,造成删除和修改异常,解决办法是给 payment_all 的 id 赋唯一
值,插入一条初始数据,删除 payment _2021 和payment_2022 中的数据。
sql 过程如下:
create table payment_id(id smallint);
insert into payment_id values(1);
delete from payment_2021;
delete from payment_2022;
在 payment_2021 和 payment_2022 表中建立一个触发器,触发器的功能是当在 payment_2021 或者 payment _ 2022 表 中 增 加 一 条 记 录 时,取 出payment _ id 中 的 id 值,赋 给 payment _ 2021 和payment_2022,然后将 tb_ids 的 id 值加 1。
创建触发器语句如下:
create trigger tr_seq1
before insert on payment_2021 for each row begin
select id into @ tb_ids from payment_id limit 1;
update payment_id set id = @ tb_ids +1;
set new. id = @ tb_ids;
end
create trigger tr_seq2
before insert on payment_2022 for each row begin
select id into @ tb_ids from payment_id limit 1;
update payment_id set id = @ tb_ids +1;
set new. id = @ tb_ids;
end
在 payment_2021 和 payment_2022 表中分别增加一条记录:
insert into payment_2021(payment_date,amount)values('2021 -02 -10',280 000);
insert into payment_2022(payment_date,amount)values('2022 -06 -15',230 000);
图 5 所示为添加触发器后 payment_all 表记录。

再次分别在 payment_2021 和 payment_2022 表中各增加三条记录:
insert into payment_2021(payment_date,amount)values('2021 - 01 - 01',160 000),('2021 - 05-30',190 000),('2021 -12 -20',260 000);
insert into payment_2022(payment_date,amount)values('2022 - 02 - 01',150 000),('2022 - 06-01',290 000),('2022 -12 -25',220 000);
经验证查询,id 没有重复,触发器创建成功。
4.3 拆分子表实现分表
在系统设计过程中,随着业务量的增加,数据表中数据量急剧增加。为快速查询到所需数据,通过
拆分子表来减少数据的装载量,获得较高的查询效率。
sql 过程如下:
1) 创建员工表
create table member(member_id bigint auto_increment primary key,member_name varchar(20),member_sex tinyint not null default 0) engine = myisam default charset = utf8 auto _increment =1;
2)创建存储过程添加 500 万条记录
create definer = `root `@ `localhost ` procedure `member_insert`()
begin declare i int default 0;
while i <5 000 000 do
insert into member(member_name,member_sex)values
(concat('工号',i),0);
set i = i +1;
end while ;
set autocommit =1;
end;
3)查询员工表记录
select count(* ) from member;
4)创建员工 1 表
create table member1(member_id bigint auto_increment primary key,member_name varchar(20),member_sex tinyint not null default 0) engine = myisam default charset = utf8 auto _increment =1;
同理,创建员工 2 表。
5)把员工表拆分两张表
通过 id 的奇偶号把员工表拆分成员工 1 表和员工 2 表。
insert into member1(member_id,member_name,member_ sex) select member _ id,member _ name,member_sex from member where member_id%2 =0;
insert into member2(member_id ,member_name,member_ sex) select member _ id,member _ name,member_sex from member where member_id%2 =1;
6)查询员工 1 表的前 10 万条记录
select * from member1 limit 100 000;
通过执行上述查询语句,结果证实分表成功。
5 结论
为了提高数据库中大数据查询效率,实现MySQL 查询的可靠性和稳定性,通过分析海量数据查询过程中的分区特点,找出传统表设计方法的不足,并在此基础上提出两种分区分表算法。通过range 分区和 Merge 存储设计进行快速分区分表,有效避免了查询速度缓慢的操作,提高了查询效率。
实验结果表明,提出优化的分区分表设计算法行之有效,优化了分布式部署,数据量控制更精细,数据维护更容易。随着业务量的增加,分表设计还需要进行复杂的设计和集群管理,分区分表设计算法还需要进一步细化。