本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处
标题:PP-GAN : Style Transfer from Korean Portraits to ID Photos Using Landmark Extractor with GAN
链接:[2306.13418] PP-GAN : Style Transfer from Korean Portraits to ID Photos Using Landmark Extractor with GAN (arxiv.org)
摘要
风格转换的目标是在保持图像内容的同时,转移另一图像的风格。
- 然而,传统的风格转换研究在保持面部标志,如眼睛、鼻子和嘴巴,这些对保持图像身份至关重要的特征时存在重大局限性。
- 在韩国肖像中,大多数人都戴着"蓬帽(Gat)",这是一种仅由男性佩戴的头饰。由于其与身份证照片中的头发有着明显的特征差异,转移"Gat"是具有挑战性的。
为解决这个问题,本研究提出了一种保持面部身份的同时保留"Gat"的风格转移深度学习网络。
与现有的风格转移方法不同,该方法旨在保留风格图像上的纹理、服装和"Gat"。生成对抗网络构成了提议网络的骨干。
- 根据预训练的VGG-16的每个块和层的特征,颜色、纹理和强度被不同地提取出来,通过使用面部关键点遮罩(facial landmark mask),只保留了训练期间所需的元素。
- 使用眉毛区域呈现头部区域以转移"Gat"。
- 此外,保留了面部的身份,并根据Gram矩阵考虑了风格相关性。
与以往的研究相比,所提出的方法展示了更优的转移和保留性能。
1 介绍
随着现代技术如摄影的兴起,捕捉人们的外貌变得毫不费力。然而,在这些技术还未发展起来的时候,艺术家们会画出个人肖像。这样的画作被称为肖像画,而由于摄影的发明,现代肖像已经成为艺术的新领域。然而,所有的历史名人都是通过图画传下来的。画作的主要目的是描绘政治上的名人,但在现代,其目的已经扩展到了普通大众。
尽管各时期和国家的肖像特征都非常不同,但除非是超现实主义作品,大多数都与人物的实际外貌有很大的区别。韩国肖像画根据时间和地区的不同有很大的差异。图1(a)展示了高丽王朝肖像的代表作。这幅作品是对高丽中期的新儒家学者安详的肖像。图1(b)是朝鲜王朝晚期的肖像,表明保护条件和绘画技巧之间存在很大的差异。尤其是在图1(b)中,头上的"Gat"清晰可见。
图1:左图(a)是高丽中期的安详(1243-1306)的肖像,右图(b)是朝鲜朝晚期的蔡理(1411-1493)的肖像。

在三国时期之前,韩国的肖像画记录几乎不存在,而在高丽王朝期间,仅保存了有限数量的肖像画[1]。相比之下,朝鲜王朝产生了大量肖像画,根据他们的社会地位有不同的类型。此外,朝鲜时期的作品展示出超凡的绘画水平,其中的面部特征比早期时期渲染得更为详细。
肖像画在人的物理外观上有轻微的变化,但它像蒙太奇一样独特地区分了个体。现代身份证明照片起到了类似的作用,被用作驾驶执照和居民登记卡等身份证件。老式肖像可能会引发人们对自己在这样的艺术作品中是如何出现的兴趣,对此可以使用风格转换技术。韩国肖像可能会被用来提供身份证照片的风格;然而,戴“Gat”头饰的习俗使得使用以前的技术将韩国肖像的风格转移到身份证照片上变得具有挑战性。
虽然早期的研究已经采用全局风格或部分风格转移到内容图像上,但对于韩国肖像,必须同时考虑纹理、服装和“Gat”的独特风格。通过从风格图像中独立提取几种风格,可以将肖像中的人的年龄、发型和服装转移到身份证照片上。
图2描绘了使用CycleGAN(一种常见的风格转换方法)进行风格转换的结果,揭示了当涉及到多种风格时实现足够的风格转换的困难。
图2:使用CycleGAN将韩国肖像风格转移到身份证照片的结果

在这项研究中,我们介绍了一种高质量的韩国肖像风格转换方法,该方法克服了以前研究的局限,能够准确地保留面部关键点并产生真实的结果。
风格转换技术,如GAN,通常基于面部数据集使用,但保持人的身份对于获得高质量结果至关重要。现有的基于面部的风格转换研究只在将风格转移到内容图像时考虑面部组件,如眼睛、鼻子、嘴巴和头发。相比之下,这项研究旨在同时转移多种风格,包括Gat和服装。
为了实现这一点,我们提出了一种增强的基于GAN的风格转换网络,该网络使用关键点生成面具,并定义了一个新的损失函数来基于面部数据进行风格转换。我们将所提出的方法,"使用GAN的关键点提取器将韩国肖像风格转移到身份证照片"定义为PP-GAN。
本研究的主要贡献是开发了一种新的风格转换方法,该方法考虑了多种风格并保持了人的身份。
- 已经展示了使用小数据集训练的网络,(使结果)独立地在任意风格之间转换的可能性。
- 这项研究是韩国肖像画中第一次尝试任意风格转换,通过引入新的损失函数组合实现了这一点。
- 生成的关键点面具改善了身份保留的性能,并超过了先前的方法[2]。
- 为本研究收集了新的上半身韩国肖像和身份证照片的数据。
2 相关工作
风格转换的研究可以分为两个主要类别:基于卷积神经网络的[4-6],[8-13]和基于生成对抗网络的[3],[14-23]。
2.1 基于CNN的风格转移
- AdaIN[4]提出了一种使用内容和样式图像的特征图中的统计信息进行高速风格转移的方法。这是关于风格转移的早期研究之一。
- S.Huang等人[5]使用了内容特征图和样式特征图的缩放信息之间的相关性来实现内容和样式的融合。此外,一种名为“样式投影”的顺序统计方法,展示了快速训练速度的优点和结果。
- Zhu等人[6]通过提出一个可以保留细节的风格转移网络,保持了结构失真和内容。
- 此外,通过提出修正了VGG-16[7]的精炼网络,通过层级结构的空间匹配保留了样式模式。
- Elad等人[8]提出了一种新的风格转移算法,扩展了纹理合成工作。它的目标是创建类似质量的图像,并强调在保持所选区域的内容不变的同时,创建丰富样式的一致方式。此外,它能快速灵活地处理任何一对内容和风格图像。
- S.Li等人[9]提出了一种对低级特征进行风格转移的方法,以在CNN中表示内容图像。低级特征控制新图像的详细结构。使用拉普拉斯矩阵来检测边缘和轮廓。它展示了一个更好的风格化图像,可以保留内容图像的细节并去除伪影。
- Chen等人[10]提出了一种基于深度神经网络的逐步方法来合成面部素描。通过提出一个金字塔列特征来丰富部分,通过添加纹理和阴影,它表现出了更好的性能。
- FastArt-CNN[11]是一个在前馈模式下进行快速风格转移性能的结构,同时最小化图像质量的恶化。它可以作为训练去卷积神经网络将特定样式应用于内容图像的方法在实时环境中使用。
- X.Lio等人[12]提出了一种在风格转移中包含几何元素的架构。这种新架构可以将纹理转移到扭曲的图像中。此外,因为可以选择输入三重的内容/纹理-样式/几何样式,所以它为输出提供了更大的灵活性。
- P.Kaur等人[13]提出了一个框架,0解决了将样式图像的面部纹理真实地转移到内容图像上,而不改变原始内容图像的身份的问题。围绕关键点的变化被轻轻地抑制,以保留面部结构,使其可以在不改变面部身份的情况下进行转移。
2.2 基于GAN的风格转换
- APDrawingGAN[14]通过结合全局和局部网络来提升性能。通过测量距离变换和艺术家绘图之间的相似性,生成了高质量的结果。
- Zheng Xu等人[15]使用生成器和鉴别器作为条件网络。
- 接下来,用于风格调整的掩蔽模块和用于风格转移的AdaIN[4]的性能优于现有的GAN。
- S3-GAN[16]在潜在向量空间中引入了风格分离方法,以分离风格和内容。通过组合分离的潜在向量,创建了一个风格转换的向量空间。
- CycleGAN[3]提出了一种不需要成对域的图像转换风格的方法。在训练将X→Y的生成器映射时,进行Y→X的反向映射。此外,周期一致性损失被设计为使输入图像和通过反向映射移除转移风格的重构图像可以相同。
- 在SLGAN[17]中,通过生成器创建了一个风格不变的解码器,以保留内容图像的身份,并引入了一种新的感知化妆损失,从而得到了高质量的转换。
在面向化妆[18-20]或衰老[21-22]的风格转换研究中,也有一些尝试保持面部关键点。
- BeautyGAN[18]定义了实例和感知损失,以在保持脸部身份的同时改变化妆风格,从而生成高质量的图像并保持身份。
- Paired-CycleGAN[19]同时训练两个生成器,从肖像照片转换其他人的化妆风格。阶段1被用作通过图像类比的一对电源,作为阶段2的输入,它通过计算阶段1电源的身份保留和风格一致性,显示出优秀的结果。
- Landmark-CycleGAN[20]在将脸部图像转换为卡通图像时,由于几何结构的扭曲,显示出不正确的结果。为了解决这个问题,提出了使用关键点的局部鉴别器来提高性能。
- Palsson等人[21]提出了Group-GAN,由多个CycleGAN[3]的模型组成,用于集成预训练的年龄预测模型并解决脸部衰老问题。
- Wang等人[22]提出了一种将边缘图互相转换为基于CycleGAN的E2E-CycleGAN网络的方法进行衰老。使用身份特征图和使用E2F-pixelHD网络转换边缘图的结果生成了老脸。
- Yi等人[23]提出了一种新的不对称周期映射,强制要显示重构信息,并只包含在可选的脸部区域。同时引入了关键点和风格分类器的本地化鉴别器,生成了肖像图像。考虑到风格向量,使用单一网络生成了多种风格的肖像。他们尝试将肖像的风格进行类似的转换,这与我们研究的目的类似。然而,在这项研究中,不仅转换了肖像画的风格,还同时转换了韩国传统帽子“Gat”和服装。
3 背景
3.1 VGG-16
VGG-16[7]网络是一个知名的计算机视觉模型,在ImageNet挑战赛中获得了92.7%的Top-5准确度,该模型接收尺寸为224×224的RGB图像作为输入,包含13个卷积层和三个全连接层的16层配置。卷积滤波器的尺寸为3×3像素,并且步幅和填充始终保持为1。该网络使用的激活函数是ReLU,池化层是最大池化,设置为2×2上的固定步幅2。它离输入层越近,特征图包含的低级信息越多,如图像的颜色和纹理,而离输出层越近,则提供更高级的信息,如形状。
本研究中使用了预训练的VGG-16[7],以有效地保留面部和上半身的内容并转移风格。
3.2 Gram矩阵(Gram matrix)
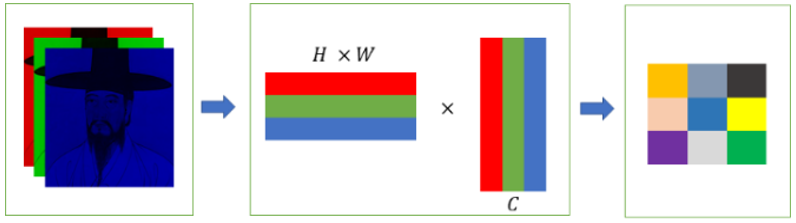
Gram矩阵是表示图像颜色分布的有价值的工具。这使得可以计算两个图像之间的整体颜色和纹理相关性。
Leon等人[24]证明,使用各种层的特征图上的Gram矩阵可以提高风格转移性能。
图3展示了计算Gram矩阵的过程,其中包括将彩色图像的每个通道转换为1D向量,然后通过将H×W矩阵与其转置相乘来获取该矩阵。Gram矩阵是一个方阵,其维度为通道大小。当两个图像的Gram矩阵中的对应值越相似,图像的颜色分布也就越相似。
图3:计算韩国肖像的Gram矩阵的过程
3.3 面部关键点(Face Landmark)
面部关键点,如眼睛、鼻子和嘴巴,在识别和分析面部结构中起着至关重要的作用。为了检测这些关键点,本研究采用了68个面部关键点的形状预测器[25],它生成了包括下巴、眼睛、眉毛、鼻子和嘴巴在内的关键面部部分的68个x和y坐标,还提供了面部的位置。然后,从预测器获取的坐标用于创建眼睛、鼻子和嘴巴的面具,如图4所示。
图4:使用Shape Predictor 68 Face Landmarks返回的坐标创建的眼睛、鼻子和嘴巴的面具

3.4 图像锐化(Image Sharpening)
图像锐化被认为是一种强调高频的滤波技术,用于增强图像细节。高频是由亮度或颜色在局部发生变化的特性,它在识别关键点时很有用。图像锐化可以通过高提升滤波来实现。这包括通过从输入图像中减去一个低通图像来生成一个高通图像,如公式(1)所示。在这个过程中,通过将输入图像乘以一个常数,得到一个强调高频的图像。
g
(
x
,
y
)
=
A
f
(
x
,
y
)
−
f
L
(
x
,
y
)
(1)
g(x,y)=Af(x,y)−f_L(x,y)\tag{1}
g(x,y)=Af(x,y)−fL(x,y)(1)
均值滤波是一种低通滤波技术,滤波器的系数可以用公式(2)确定。
A
[
0
0
0
0
1
0
0
0
0
]
−
1
/
9
[
1
1
1
1
1
1
1
1
1
]
=
1
/
9
[
−
1
−
1
−
1
−
1
9
A
−
1
−
1
−
1
−
1
−
1
]
→
[
−
1
−
1
−
1
−
1
α
−
1
−
1
−
1
−
1
]
(2)
A\left[\begin{matrix}0&0&0\\0&1&0\\0&0&0\end{matrix}\right]-1/9\left[\begin{matrix}1&1&1\\1&1&1\\1&1&1\end{matrix}\right]=1/9\left[\begin{matrix}-1&-1&-1\\-1&9A-1&-1\\-1&-1&-1\end{matrix}\right]\rightarrow\left[\begin{matrix}-1&-1&-1\\-1&\alpha&-1\\-1&-1&-1\end{matrix}\right]\tag{2}
A
000010000
−1/9
111111111
=1/9
−1−1−1−19A−1−1−1−1−1
→
−1−1−1−1α−1−1−1−1
(2)
输入图像的锐化强度由
α
\alpha
α的值控制,其中
9
A
−
1
9A-1
9A−1被设置为
α
\alpha
α。
α
\alpha
α值较高会导致锐度水平降低,原因是**原图像对输出的比例较高。**相反,
α
\alpha
α值较小会导致对比度降低,因为去除了大量的低频分量。
为了使肖像图像和身份证照片之间的结构相似,肖像图像被裁剪在面部周围,因为面部占据的面积相对较小。相反,身份证照片被调整大小,使它们在水平和垂直方向上具有相同的大小,而不是被裁剪。
然而,这种调整大小可能会使提取关键点变得困难。因此,本研究进行了图像锐化。这个过程是必要的,以确保从身份证照片中很好地提取出关键点,如图5所示,该图说明了有无图像锐化对关键点提取的差异。
图5:根据高提升滤波使用情况生成关键点遮罩的结果(第一列和第三列分别是原图和高提升滤波后的图像,第二列和第四列显示了每个对应图像检测到的关键点的遮罩)

4 提出的方法
4.1 网络
我们提出的方法其主要目标是实现身份证照片与韩国肖像之间的风格转移。让 X X X和 Y Y Y分别表示三维彩色图像(身份证照片)和韩国肖像的域(domains)。这些域是 X ⊆ R H × W × C X\subseteq{\mathbb{R}^{H×W×C}} X⊆RH×W×C和 Y ⊆ R H × W × C Y\subseteq{\mathbb{R}^{H×W×C}} Y⊆RH×W×C的子集,并具有集合关系,即 x ∈ X x\in{X} x∈X和 y ∈ Y y\in{Y} y∈Y。
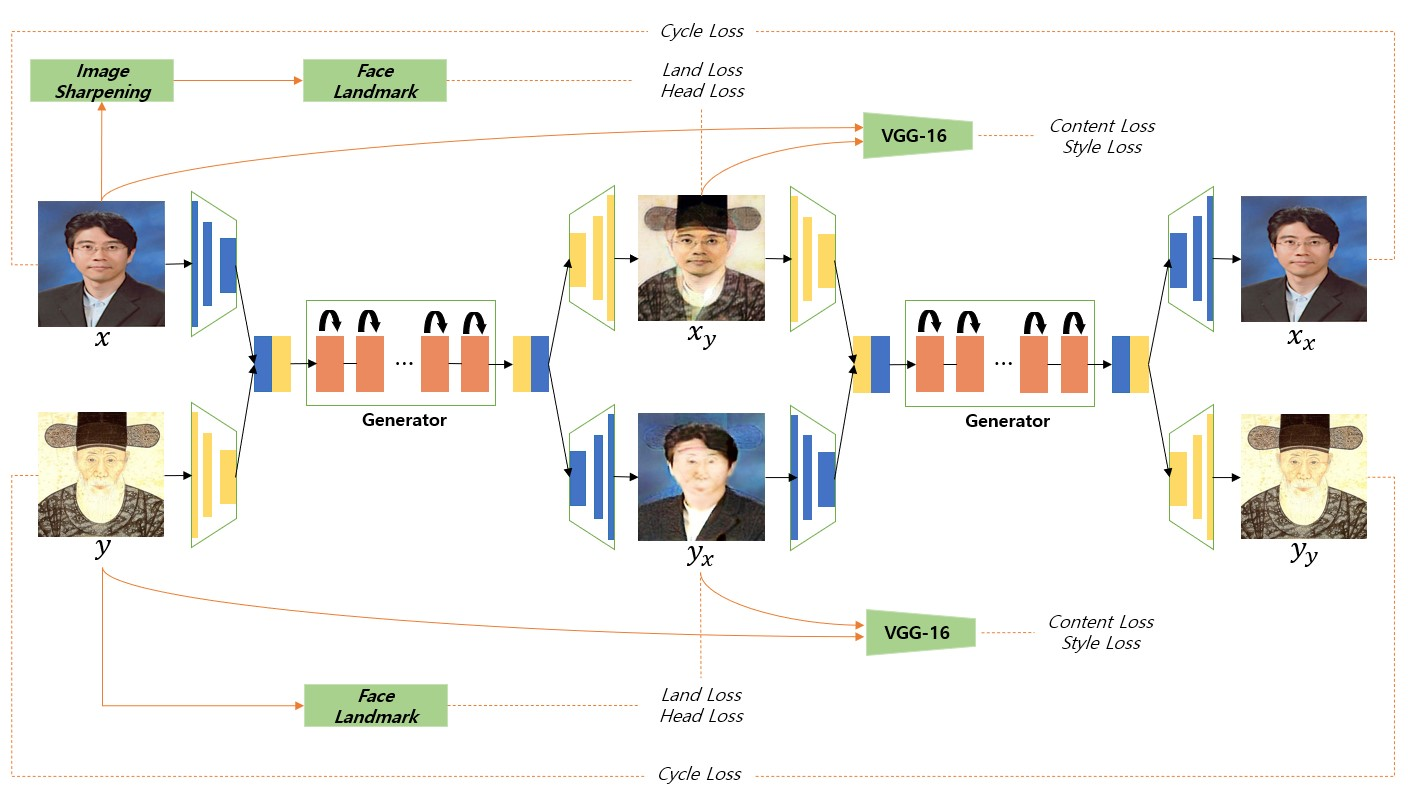
CycleGAN[3]网络由于在整个域上进行训练,其进行风格转移的能力有限。因此,提议的方法采用了BeautyGAN[18]的双输入/输出生成器(Dual I/O generator),该生成器具有稳定的鉴别器,**使两个域之间的映射训练和风格转移成为可能。**此外,提议的方法还结合了VGG-16,gram矩阵和关键点提取器来提高性能。
图6描述了提出方法的整体结构。
图6:本研究提出的系统的整体结构
4.1.1 生成器(Generator)
生成器被训练来进行 ( X , Y ) → ( Y , X ) (X,Y)\rightarrow(Y,X) (X,Y)→(Y,X)的映射,生成兼具 X X X的内容(content)和 Y Y Y的风格(style)的虚假图像 G ( x , y ) = ( x y , y x ) G(x,y)=(x_y,y_x) G(x,y)=(xy,yx),这在本研究中用作评估。
译者注:"(X, Y) → (Y, X)"表示生成器的任务是将输入的图像从域X转换到域Y,并同时将其从域Y转换回域X。具体而言,生成器接收一个身份证照片(属于域X)作为输入,并生成一个具有韩国肖像风格的伪造图像(属于域Y),同时也能将这个伪造图像转换回原始的身份证照片风格(属于域X)。这种双向的映射关系允许生成器在两个域之间进行转换,以实现身份证照片向韩国肖像风格的风格转换,并且还可以在需要时将其还原回原始风格。
Y Y Y的内容和 X X X(的风格)还被用于生成另一个假图像 y x y_x yx。虽然网络结构可以在两个方向上生成结果,但本研究只关注 x y x_y xy结果。
由用于执行风格转移的双输入/输出生成器所还原(recovered)的图像和输入图像必须相同(identical)。
-
输入大小为(256,256,32)
-
x x x和 y y y分别通过三个卷积层(后输出),结果为(64,64,128)的大小
-
x x x和 y y y的结果进行拼接,产生一个尺寸为(64,64,256)的结果
-
通过反卷积层将其恢复到原始尺寸
-
通过九个残差块进行样式转移
这个结果代表了一个样式转换的虚假图像,并代表了提出的方法的结果。因此,生成器通过生成看起来真实的虚假图像来欺骗判别器,从而得到更自然、更高性能的结果。
4.1.2 判别器(Discriminator)
网络结构包括两个判别器,它们被训练用于分类生成器生成的假图像和真实图像的样式。判别器由五个卷积层组成,旨在区分样式。
- 输入图像大小为(256,256,3)
- 网络结果大小为(30,30,1)。
- 除了最后一层的前四个卷积层执行谱归一化(Spectral Normalization)[26]以提高性能并在高维空间中保持判别器的稳定分布。
判别器定义如下:
-
D x D_x Dx将 x y x_y xy分类为假,将 y y y分类为真,而 D y D_y Dy将 y x y_x yx分类为假,将 x x x分类为真。
-
最后,应用PatchGAN[27]生成判别器输出,这是判别器对输入图像的最终判断结果。
4.2 损失函数
在本研究中,我们提出了一种用于将身份证照片转换为任意韩国肖像风格的损失函数。
我们使用了六种损失函数,其中包括新方法的损失函数,以生成良好的结果。
CycleGAN引入了通过循环结构将结果再次设为生成器输入的概念,理论上应产生与原始图像相同的输出。因此,在本研究中,我们将被还原的结果(recovered result)定义为循环损失(cycle loss),这由一个旨在减小输入和输出图像之间差异的损失函数组成。
特别地,它可以表示为
x
≈
G
(
G
(
x
,
y
)
)
=
G
(
x
y
,
y
x
)
=
x
x
x\approx{G(G(x,y))}=G(x_y,y_x)=x_x
x≈G(G(x,y))=G(xy,yx)=xx和
y
≈
G
(
G
(
y
,
x
)
)
=
G
(
y
x
,
x
y
)
=
y
y
y\approx{G(G(y,x))}=G(y_x,x_y)=y_y
y≈G(G(y,x))=G(yx,xy)=yy。这可以用公式(3)表示。
L
c
y
=
E
x
∼
P
(
X
)
∥
x
x
−
x
∥
+
E
y
∼
P
(
Y
)
∥
y
y
−
y
∥
(3)
L_{cy}=\mathbb{E}_{x\sim{P(X)}}\lVert{x_x}-x\rVert+\mathbb{E}_{y\sim{P(Y)}}\lVert{y_y}-y\rVert\tag{3}
Lcy=Ex∼P(X)∥xx−x∥+Ey∼P(Y)∥yy−y∥(3)
现有的风格转移方法会从几何上扭曲脸部的形状,导致难以识别面部形状。为了保持角色的身份,需要一个新的条件。因此,本研究基于面部关键点遮罩定义了地块损失(land loss),这有助于在增强风格转移的性能时保留眼睛、鼻子和嘴巴。在这项研究中,地块损失由数学表达式公式(4)定义。
L
l
=
L
l
e
y
e
+
L
l
n
o
s
e
+
L
l
l
i
p
(4)
L_l=L_{l_{eye}}+L_{l_{nose}}+L_{l_{lip}}\tag{4}
Ll=Lleye+Llnose+Lllip(4)
地块损失是一个旨在保持由生成器生成的输入和输出图像的关键点特征的函数。
-
图像对 ( x y , x ) (x_y,x) (xy,x)和 ( y x , y ) (y_x,y) (yx,y)包含具有不同风格的相同内容,并且关键点形状相同。
-
如第3节所述,用于眼睛、鼻子和嘴巴区域的遮罩 M f X M_{fX} MfX和 M f Y M_{fY} MfY用于计算面积。
-
通过逐像素操作,使用面部关键点遮罩处理眼睛、鼻子和嘴巴的每个区域,并定义一个损失函数来最小化像素值之间的差异。
这个过程在等式(5)中表示。每个关键点的差异基于L1损失。
L
f
=
E
x
∼
P
(
X
)
∥
x
y
⊙
M
f
X
−
x
⊙
M
f
X
∥
1
+
E
y
∼
P
(
Y
)
∥
y
x
⊙
M
f
Y
−
y
⊙
M
f
Y
∥
1
,
f
=
{
l
e
y
e
,
l
n
o
s
e
,
l
l
i
p
}
(5)
L_f=\mathbb{E}_{x\sim{P(X)}}\lVert{x_y}\odot{M_{fX}}-x\odot{M_{fX}}\rVert_1+\mathbb{E}_{y\sim{P(Y)}}\lVert{y_x}\odot{M_{fY}}-y\odot{M_{fY}}\rVert_1,{\quad}f=\{l_{eye},l_{nose},l_{lip}\}\tag{5}
Lf=Ex∼P(X)∥xy⊙MfX−x⊙MfX∥1+Ey∼P(Y)∥yx⊙MfY−y⊙MfY∥1,f={leye,lnose,llip}(5)
译者注:
以上等式表示了地块损失的数学形式。这里的 L f L_f Lf表示地块损失,它计算了生成的伪造图像与原始图像之间眼睛、鼻子和嘴巴区域的差异。
- E x ∼ P ( X ) \mathbb{E}_{x\sim{P(X)}} Ex∼P(X)和 E y ∼ P ( Y ) \mathbb{E}_{y\sim{P(Y)}} Ey∼P(Y)分别是来自域X和域Y的期望值。
- ⊙ \odot ⊙表示哈达玛积(逐元素乘积)。
- M f X M_{fX} MfX和 M f Y M_{fY} MfY分别是用于X和Y的面部地块掩码,用于突出眼睛、鼻子和嘴唇的区域。
- f = { l e y e , l n o s e , l l i p } f=\{l_{eye},l_{nose},l_{lip}\} f={leye,lnose,llip}指示眼睛、鼻子和嘴唇的地块。
整个等式计算了通过与地块掩码相乘以突出重要区域后,伪造图像与原始图像之间的L1损失。通过最小化这个损失,模型被鼓励在风格转换过程中保留这些关键面部特征的准确表示。
本研究提出的方法与以前的风格转换研究有着巨大的不同,特别是针对韩国肖像,除了考虑图像质量、背景和整体颜色外,还必须考虑Gat(一种传统的韩国帽子)和衣服的风格。然而,“Gat”的形状各异,由于佩戴位置的差异,这使得其难以检测,同时韩国肖像和身份证照片的头发形状也完全不同。
为了解决这个问题,提出了一种头部损失(head loss),以最小化结果和风格图像(韩国肖像)的头部区域之间的差异,头部区域被分为Gat和头发区域,由掩码
M
h
t
M_{ht}
Mht和
M
h
r
M_{hr}
Mhr表示。头部损失利用Gat不覆盖眉毛的事实;因此,使用眉毛上方的坐标对应的特征点来定义头部区域,然后将相应的风格转移到结果图像上。这一点可以通过等式(6)来表示。
L
h
=
E
x
∼
P
(
X
)
∥
x
y
⊙
M
h
t
−
y
⊙
M
h
t
∥
1
+
E
y
∼
P
(
Y
)
∥
y
x
⊙
M
h
r
−
x
⊙
M
h
r
∥
1
(6)
L_h=\mathbb{E}_{x\sim{P(X)}}\lVert{x_y}\odot{M_{ht}}-y\odot{M_{ht}}\rVert_1+\mathbb{E}_{y\sim{P(Y)}}\lVert{y_x}\odot{M_{hr}}-x\odot{M_{hr}}\rVert_1\tag{6}
Lh=Ex∼P(X)∥xy⊙Mht−y⊙Mht∥1+Ey∼P(Y)∥yx⊙Mhr−x⊙Mhr∥1(6)
为了保留角色的整体形状并提高风格转换的性能,在本研究中,我们使用VGG-16的特定层来定义内容损失(content loss)和风格损失(style loss)。
预训练的网络包含低级和高级信息,例如颜色和形状,这些信息根据层的位置呈现不同。低级信息与风格有关,高级信息与内容有关。
反过来,高级层代表图像特征。
译者注:上一句看上去好多余
因此,内容和风格损失是基于层特征进行配置的。风格损失使用gram矩阵来定义,该矩阵是通过计算特征映射的内积来获得的。通过实验获得的最佳层集合用于定义风格损失,如等式(7)所示,其中N和M分别代表每层的乘积和通道,g代表特征映射的gram矩阵。通过训练以最小化两侧(
x
y
x_y
xy和
y
x
y_x
yx)的特征映射之间的gram矩阵的差异,可以将y的风格转移到x上。
L
s
=
1
4
N
2
M
2
∑
[
(
g
i
(
x
y
)
−
g
i
(
y
)
)
2
+
(
g
i
(
y
x
)
−
g
i
(
x
)
)
2
]
(7)
L_{s}=\frac{1}{4N^{2}M^{2}}\sum[(g_{i}(x_{y})-g_{i}(y))^{2}+(g_{i}(y_{x})-g_{i}(x))^{2}]\tag{7}
Ls=4N2M21∑[(gi(xy)−gi(y))2+(gi(yx)−gi(x))2](7)
内容损失被定义为一种在像素级最小化特征映射线性差异的方法。由于风格转换的目的是在转移风格的同时保持图像的内容,所以不需要考虑相关性。内容损失的方程与等式(8)中的相同。这是保持人的身份的关键因素;然而,如果这个损失的权重非常大,可能会导致风格转换效果不佳。因此,必须选择适当的超参数以达到期望的结果。
L
c
=
E
x
∼
P
(
X
)
[
l
i
(
x
y
)
−
l
i
(
x
)
]
2
+
E
y
∼
P
(
Y
)
[
l
i
(
y
x
)
−
l
i
(
y
)
]
2
(8)
L_c=\mathbb{E}_{x\sim{P(X)}}[l_i(x_y)-l_i(x)]^2+\mathbb{E}_{y\sim{P(Y)}}[l_i(y_x)-l_i(y)]^2\tag{8}
Lc=Ex∼P(X)[li(xy)−li(x)]2+Ey∼P(Y)[li(yx)−li(y)]2(8)
-
生成器的损失由循环损失、地块损失、头部损失、风格损失和内容损失组成
如等式(9)所示。每个损失都乘以不同的超参数,然后将得到的值的和用作生成器的损失函数。
L G = λ c y L c y + λ l L l + λ h L h + λ s L s + λ c L c (9) L_G=\lambda_{cy}L_{cy}+\lambda_lL_l+\lambda_hL_h+\lambda_sL_s+\lambda_cL_c\tag{9} LG=λcyLcy+λlLl+λhLh+λsLs+λcLc(9)
判别器的损失仅包括对抗损失,遵循GAN结构。判别器的输出是一个32×32×1的结果,基于PatchGAN[27]来评估它们是真实的还是伪造的,考虑每个图像的PatchGAN[27]。
-
用于训练判别器的损失函数由等式(10)给出。
如果 x y x_y xy和 y x y_x yx的片段是假的,而x和y的片段被真实分类,那么损失函数就会减小。
L D = E x ∼ P ( X ) [ ( D x ( y ) − 1 ) 2 + ( D x ( x y ) ) 2 ] + E y ∼ P ( Y ) [ ( D y ( x ) − 1 ) 2 + ( D y ( y x ) ) 2 ] (10) L_{D}=\mathbb{E}_{x\sim{P(X)}}[(D_x(y)-1)^2+(D_x(x_y))^2]+\mathbb{E}_{y\sim{P(Y)}}[(D_y(x)-1)^2+(D_y(y_x))^2]\tag{10} LD=Ex∼P(X)[(Dx(y)−1)2+(Dx(xy))2]+Ey∼P(Y)[(Dy(x)−1)2+(Dy(yx))2](10)
本研究中使用的总损失由等式(11)表示,由生成器和判别器损失组成。
- 生成器试图最小化生成器损失以生成风格转换结果
- 判别器则旨在最小化判别器损失以提高其区分能力
在生成器和判别器性能之间观察到权衡,其中一个改善,另一个则减小。因此,通过在生成器和判别器之间形成竞争关系来优化总损失,从而导致优越的结果。
L
T
o
t
a
l
=
m
i
n
G
m
i
n
D
(
L
G
+
L
D
)
(11)
L_{Total}=\mathop{min}\limits_{G}\mathop{min}\limits_{D}(L_G+L_D)\tag{11}
LTotal=GminDmin(LG+LD)(11)
4.3 训练
本研究的实验环境是在使用GeForce RTX3090和Ubuntu 18.04LTS操作系统的多GPU系统上进行的。由于TensorFlow1.x对CUDA有最低版本要求,因此使用Nvidia-Tensorflow版本1.15.4进行了实验。通过使用Google和Bing搜索引擎进行网络爬取,收集了ID照片和韩国肖像的数据集。
为了提高训练性能,进行了预处理,将韩国肖像的面部区域与通常展示整个身体的整体分开。应用了左右倒置、模糊和噪声等数据增强技术,以增加数据集的有限数量。如图7所示,还进行了Gat预处理,以便于特征映射。
图7:数据集预处理示例

表1显示了由1,054张ID照片和1,736张韩国肖像组成的结果数据集,其中96%用于训练,4%用于测试。由于肖像数量有限,因此使用了更高比例的训练数据,并且测试集没有应用数据增强。由于可以从测试数据生成的组合数量庞大( X T e s t × Y T e s t X_{Test}\times{Y_{Test}} XTest×YTest),评估并未出现问题。以前的研究强调了数据预处理的重要性,本研究的结果进一步支持了其对训练性能的影响。
表1:详细数据集

所提出的网络使用Adam优化器训练了200个周期。初始学习率设为0.0001,并在训练周期的50%之后线性减小到零,以实现稳定学习。
为了在损失函数之间匹配等式,将 λ c y \lambda_{cy} λcy设置为50,这比其他损失的值相对较低。为了增加风格转移的效果,将 λ s \lambda_s λs设置为1,将 λ h \lambda_h λh设置为0.5,有助于在风格转移之间专注于头部区域。最后,通过设置 λ c = 0.1 λ_c=0.1 λc=0.1和 λ l = 0.2 λ_l=0.2 λl=0.2来进行训练。整个训练过程大约花费6.5小时。
结果呈现在图8中,直观地证实了所提出的方法比先前的研究[2]显示出更大的性能改进。虽然先前的方法只关注风格转移,但本研究成功地保持了人物的身份,同时转移了风格。结果显示了出色的成果,即在保留内容图像中角色的形状的同时转移了风格。此外,人员的身份得到了保留,而且Gat自然地转移了。
图8:本文提出的方法的结果

5 实验
5.1 特征映射
为了进行风格损失,本研究从VGG-16层采用了Conv2_2和Conv3_2,而Conv4_1则用于内容损失。尽管前卷积层包含低级信息,但由于风格和内容图像之间的图案和颜色差异很大,因此它们对变化非常敏感,难以训练。为了克服这个问题,本研究利用位于中间的特征映射来提取风格转换所需的低级信息。未采用用于风格损失的特征映射的结果显示在图9中,tensorboard上的平滑设置为0.8。由于在实验中使用未用于风格损失的层时训练失败,所以仅输出了十个周期的损失图。
图9:VGG-16的特定特征映射实验结果,用于风格损失

- Conv2_1层在训练过程中表现出较大的损失值和不稳定的行为,表明该层的训练可能并不有效。
- Conv1_2在大部分损失中接近于零,但由于某些数据的损失非常大,最大最小值相差超过10^4倍,因此不能说训练正在进行。
- Conv1_1在训练过程中表现出与Conv2_1和Conv1_2类似的高损失偏差和不稳定性。此外,由于对颜色敏感,这一层对训练也提出了挑战。
如果Conv4_1被用作风格损失层,它可以转移图像内容的风格。然而,由于特征映射几乎不包括与风格相关的内容,生成器可能会产生缺乏风格的图像。尽管如此,观察到将背景的风格转移是可行的,因为它与图像的整体风格相一致,并且可以被识别为内容,因为服装风格并不是突出的特征。
因此,如Conv4_1之类的高级层只包括角色内容中的背景风格。在图10中显示了使用内容损失的特征映射作为风格损失的结果。一般而言,内容图像的大部分内容得以保留,而风格只是略有转移。因此,我们继续使用可训练的层,这将导致稳定的训练,并使我们能够在保留内容的同时转移风格。
图10:当用于风格损失的特征图与内容损失的相同层一起使用时的结果(第1列:输入图像;第2列和第3列:使用Conv4_1的输出图像)

5.2 消融研究
为了展示本研究中提出的损失函数对生成器损失的有效性,对除循环损失(Cycle Loss)之外的四个损失函数进行了消融研究。结果展示在图11中,其中一行代表使用相同的内容和风格图像。
图 11:本文提出的总损失组成的各种损失函数的重要性结果。第1列到第4列排除损失函数 L c L_c Lc、 L s L_s Ls、 L l L_l Ll和 L h L_h Lh;第5列使用所有损失函数生成的结果。

如果排除 L c L_c Lc,则不会保留字符形状,由于训练过程中的风格集中,导致结果不佳。因此 L l L_l Ll仅传递面部组件。
译者注:上面这一句没太看明白逻辑。
当同时排除 L c L_c Lc和 L l L_l Ll时,风格转换结果缺乏面部组件。
同样,当排除 L s L_s Ls时,风格转换的结果质量较差,角色几乎保持不变。
L c y L_{cy} Lcy的使用允许在不需要单独的风格损失函数的情况下进行背景的风格转换;然而,由于训练主要集中在角色形状上,风格转换几乎不发生,导致在使用 L h L_h Lh时创建了Gat。
排除 L l L_l Ll导致深色面部组件不清晰和模糊,面部颜色变亮。因此, L l L_l Ll在通过使深色面部组件更明显来保留角色身份方面起着关键作用。
如果排除 L h L_h Lh,则头部区域变得模糊或未创建,导致风格转换结果不令人满意。与整体风格转换不同,Gat必须重新生成;
因此, L s L_s Ls起到不同的目的。因此,必须单独设置头部区域,并可以与 L h L_h Lh一起使用 L s L_s Ls来实现这一目的。
因此,本研究提出的所有损失函数的使用都能产生最佳性能,生成没有任何方向偏见的自然图像。
5.3 性能评估
本研究与之前的研究[2]进行了性能比较,主题相同,并进行了消融研究。尽管关于风格迁移有许多现有的研究,但本文的主题与它们有很大的不同,因此只与之前的一项研究[2]进行了比较。基于CycleGAN[3],由于无法任意进行风格迁移,因此无法进行配对评估。因此,通过与来自韩国国立龙脉工业大学计算机工程系的59名不同年级的学生进行在线调查,评估了所提出方法在三个方面的性能:
-
风格转移(Sst)
-
内容保留(Scn)
-
自然图像生成(Snt)。
该调查使用Google Forms在线进行了10天,调查员收到并评估了来自以前研究[2]的10个结果和来自所提出方法的10个结果的组合。表2中的调查结果显示,所提出的方法在所有三个方面均优于之前的方法[2],在保留角色内容方面得分差异最大。相反,以前的方法[2]在风格转移过程中未能保留角色的形状,导致面部地标模糊或消失,这并不自然。然而,所提出的方法成功地保留了角色内容并有效地转移了风格,从而产生了相对自然的结果。因此,所提出的方法比以前的方法[2]表现更好。
表2:调查结果

峰值信噪比(PSNR)和结构相似性指数(SSIM)通常用于衡量性能,如许多研究[28-29]中所观察到的。然而,在保持内容的同时进行风格转移时,确保没有明显偏向内容或风格的自然结果是至关重要的。因此,为了比较性能,我们提出了新的性能指标,利用PSNR和SSIM的中值进一步加权算术平均数。
PSNR通常用于通过测量噪声与最大值之比来评估图像压缩后的质量,可以使用等式(12)计算。该方程中的对数分母表示原始图像和压缩图像之间的平方和的平均值,较低的值表示更高的PSNR和更好的原始图像保留。
相比之下,SSIM用于通过比较它们的结构、亮度和对比度特征来评估图像对之间的图像相似性的失真。等式(13)用于计算SSIM,涉及各种与概率有关的定义,如均值、标准偏差和协方差。
P
S
N
R
(
A
,
B
)
=
10
log
10
(
M
A
X
2
∑
(
A
−
B
)
2
)
(12)
PSNR(A,B)=10\log_{10}(\frac{MAX^{2}}{\sum (A-B)^{2}})\tag{12}
PSNR(A,B)=10log10(∑(A−B)2MAX2)(12)
S S I M ( A , B ) = ( 2 μ A μ B + C 1 ) ( 2 σ A B + C 2 ) ( 2 μ A 2 + μ B 2 + C 1 ) ( σ A 2 + σ B 2 + C 2 ) (13) SSIM(A,B)=\frac{(2\mu_{A}\mu_{B}+C_{1})(2\sigma_{AB}+C_{2})}{(2\mu_{A}^{2}+\mu_{B}^{2}+C_{1})(\sigma_{A}^{2}+\sigma_{B}^{2}+C_{2})}\tag{13} SSIM(A,B)=(2μA2+μB2+C1)(σA2+σB2+C2)(2μAμB+C1)(2σAB+C2)(13)
为了评估性能,指标按升序排序,得到一个由值 [ x 1 , x 2 , x 3 , x 4 , x 5 ] [x_1,x_2,x_3,x_4,x_5] [x1,x2,x3,x4,x5]表示的序列,其中代 x 3 x_3 x3表最佳结果。为了给中位数赋予更多权重,一个权重向量(w)被赋值为 [ 10 , 25 , 50 , 25 , 10 ] [10,25,50,25,10] [10,25,50,25,10],并使用等式(14)计算加权算术平均数。
性能使用等式(15)进行评估,该等式计算加权算术平均数与PSNR和SSIM值之间的差异的平方。所得到的值表示性能的程度,值越小表示性能越好。与平均权重(
w
a
v
g
w_{avg}
wavg)的差异的平方被加起来,得到一个较大的单向结果。最后,内容和风格的平方误差之和(
E
P
S
N
R
,
E
S
S
I
M
E_{PSNR},E_{SSIM}
EPSNR,ESSIM)被呈现为性能评估的最终指标。
w
a
v
g
=
∑
i
=
1
5
x
i
w
i
∑
i
=
1
5
w
i
(14)
w_{avg}=\frac{\sum_{i=1}^{5}x_{i}w_{i}}{\sum_{i=1}^{5}w_{i}}\tag{14}
wavg=∑i=15wi∑i=15xiwi(14)
E d = ( w a v g − x i ) 2 , d = { c o n t e n t , s t y l e } (15) E_{d}=(w_{avg}-x_{i})^{2},d=\{content,style\}\tag{15} Ed=(wavg−xi)2,d={content,style}(15)
表3和表4展示了基于PSNR和SSIM的提出的性能指标的结果,这些结果是基于1,452个生成的结果进行评估的。
表3:消融实验分析(PSNR)
表4:消融实验分析(SSIM)
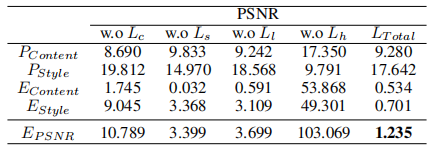

内容和风格图像的PSNR值分别由 P C o n t e n t P_{Content} PContent和 P S t y l e P_{Style} PStyle表示,而 P C o n t e n t P_{Content} PContent和 P S t y l e P_{Style} PStyle分别计算内容和风格图像的SSIM值。 P C o n t e n t + P S t y l e P_{Content}+P_{Style} PContent+PStyle,即内容和风格的平方误差之和,被用作最终的度量标准。在不使用 L h L_h Lh时,内容的保留是最高的,而不使用 L c L_c Lc或 L s L_s Ls会导致内容和风格的损失。 L l L_l Ll在内容方面没有显著差异,而风格相对较高。因此,当使用所有损失函数时, E P S N R E_{PSNR} EPSNR和 E S S I M E_{SSIM} ESSIM是很好的评估指标。
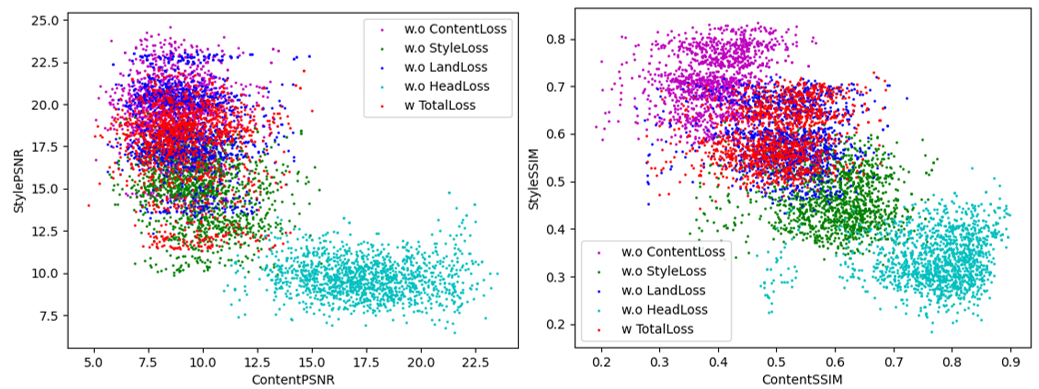
图12显示了具有风格转移性能的内容保留性能生成的结果的分布。
-
当考虑PSNR时,与 L h L_h Lh有关的结果的分布与其他结果不同。与 L c L_c Lc有关的分布位于前半部分,与 L s L_s Ls有关的分布位于后半部分。然而, L T o t a l L_{Total} LTotal的分布相对靠近中心,偏差较小,使其成为最合适的结果。
-
在SSIM的情况下,分布形状与PSNR类似,但几个分布显示平行移动结果。 E S S I M E_{SSIM} ESSIM越小,分布越集中,表明性能越好。因此, L T o t a l L_{Total} LTotal的性能优于 L l L_l Ll,并且 L T o t a l L_{Total} LTotal的差异较小,在中心具有相似的分布。其他结果被认为是相对较差的结果,因为它们位于中心之外。
图 12:通过二维坐标系,内容和风格的结果代表了测试数据集的点(上部:PSNR,下部:SSIM)。
6 结论
本研究的目的是提出一种生成对抗网络,该网络利用面部特征点和损失函数实现任意风格转换,同时保持原始面部形状并转换 Gat。为了保留面部的特征,使用地标蒙版定义了两个损失函数,土地损失和头部损失,以最小化差异并加速学习过程。风格损失使用格拉姆矩阵进行内容损失和风格转换,能够在保留角色形状的同时进行风格转换。然而,如果输入图像存在很大的差异,特征图存在显著的差异,结果将不令人满意,某些情况下还会有颜色差异。为克服这些局限性,建议在未来的研究中定义一个考虑颜色差异并通过面部地标对齐来对齐特征图的损失函数。
参考文献
- 韩国文化百科全书。 在线获取:链接(访问日期:2023年5月2日)。
- J. Si, J. Jeong, G. Kim, 和 S. Kim, “使用CycleGAN进行韩国肖像和ID照片的风格相互转换,” 信息技术韩国研究所会议(KIIT), 页 147-149, 2020。
- J. Zhu, T. Park, P. Isola, 和 A. A. Efros, “使用周期一致的对抗网络进行非配对图像到图像的转换,” IEEE计算机视觉国际会议(ICCV), 页 2223-2232, 2017。
- X. Huang 和 S. Belongie, “使用自适应实例规范化的实时任意风格转换,” IEEE计算机视觉国际会议(ICCV), 页 1501-1510, 2017。
- S. Huang, H. Xiong, T. Wang, Q. Wang, Z. Chen, J. Huan, 和 D. Dou, “参数自由风格投影用于任意风格转换,” arXiv预印本 arXiv:2003.07694, 2020。
- T. Zhu 和 S. Liu, “保持细节的任意风格转换,” IEEE多媒体和博览会国际会议(ICME), 页 1-6, 2020。
- M. Elad 和 P. Milanfar, “通过纹理合成进行风格转换,” IEEE图像处理交易, 卷 26, 期 5, 页 2338-2351, 2017。
- K. Simonyan 和 A. Zisserman, “用于大规模图像识别的非常深的卷积网络,” 学习表示国际会议(ICLR), 页 1-14, 2015。
- S. Li, X. Xu, L. Nie, 和 T. Chua, “拉普拉斯驱动的神经风格转换,” ACM多媒体国际会议, 页 1716-1724, 2017。
- C. Chen, X. Tan, 和 K. Y. K. Wong, “使用金字塔列特征的脸部素描合成与风格转换,” IEEE计算机视觉应用冬季会议(WACV), 页 485-493, 2018。
- B. Blakeslee, R. Ptucha, 和 A. Savakis, “FASTER ART-CNN: 极快的风格转换网络,” IEEE西纽约图像和信号处理研讨会(WNYISPW), 页 1-5, 2018。
- X. Liu, X. Li, M. Cheng, 和 P. Hall, “几何风格转换,” arXiv预印本 arXiv:2007.05471, 2020。
- P. Kaur, H. Zhang, 和 K. Dana, “逼真的面部纹理转换,” IEEE计算机视觉应用会议(WACV), 页 2097-2105, 2019。
- R. Yi, Y. Liu, Y. Lai, 和 P. Rosin, “使用分层GANs生成艺术人物肖像素描,” IEEE/CVF计算机视觉和模式识别会议(CVPR), 页 10743-10752, 2019。
- Z. Xu, M. Wilber, C. Fang, A. Hertzmann, 和 H. Jin, “从多领域艺术图像中学习任意风格转换,” ACM/Eurographics计算美学和基于草图的接口和建模和非摄影动画和渲染会议(Expressive ’19), 页 21-31, 2019。
- R. Zhang, S. Tang, Y. Li, J. Guo, Y. Zhang, J. Li, 和 S. Yan, “通过生成对抗网络的风格分离和合成,” ACM多媒体国际会议, 页 183-191, 2018。
- D. Horita 和 K. Aizawa, “SLGAN: 风格和潜在引导的生成对抗网络,用于理想化化妆转换和去除,” ACM亚洲多媒体国际会议, 页 1-8, 2022。
- T. Li, R. Qian, C. Dong, S. Liu, Q. Yan, W. Zhu, 和 L. Lin, “BeautyGAN: 使用深度生成对抗网络的实例级面部化妆转移,” ACM多媒体国际会议, 页 645-653, 2018。
- H. Chang, J. Lu, F. Yu, 和 A. Finkelstein, “PairedCycleGAN: 用于施加和去除化妆的不对称风格转换,” IEEE计算机视觉和模式识别会议(CVPR), 页 40-48, 2018。
- R. Wu, X. Gu, X. Tao, X. Shen, Y. W. Tai, 和 J. Jia, “地标辅助CycleGAN用于卡通脸生成,” arXiv预印本 arXiv:1907.01424, 2019。
- S. Palsson, E. Agustsson, R. Timofte, 和 L. Van Gool, “面部老化的生成对抗风格转换网络,” IEEE计算机视觉和模式识别研讨会(CVPRW), 页 2084-2092, 2018。
- Z. Wang, Z. Liu, J. Huang, S. Lian, 和 Y. Lin, “你多大了? 使用GANs进行带身份保留的脸部年龄转换,” arXiv预印本 arXiv:1909.04988, 2019。
- R. Yi, Y. J. Liu, Y. K. Lai, 和 P. L. Rosin, “通过非对称周期映射的非配对肖像绘画生成,” IEEE/CVF计算机视觉和模式识别会议(CVPR), 页 8217-8225, 2020。
- L. A. Gatys, A. S. Ecker, 和 M. Bethge, “使用卷积神经网络的图像风格转换,” IEEE计算机视觉和模式识别会议(CVPR), 页 2414-2423, 2016。
- V. Kazemi 和 J. Sullivan, “一毫秒脸部对齐与回归树集合,” IEEE计算机视觉和模式识别会议(CVPR), 页 1867-1874, 2014。
- T. Miyato, T. Kataoka, M. Koyama, 和 Y. Yoshida, “生成对抗网络的谱归一化,” 学习表示国际会议(ICLR), 页 1-10, 2018。
- C. Li 和 M. Wand, “使用马尔可夫生成对抗网络的预计算实时纹理合成,” 欧洲计算机视觉会议(ECCV), 页 702-716, 2016。
- J. Si 和 S. Kim, “基于深度和背景运动估计的第一人称视频中的交通事故检测,” 韩国信息技术研究所杂志(JKIIT), 卷 19, 期 3, 页 25-34, 2021。
- A. Hor’e 和 D. Ziou, “图像质量度量:PSNR与SSIM,” 国际模式识别会议(ICPR), 页 2366-2369, 2010。
References
- Encyclopedia of Korean Culture. Available online: link (accessed on 2 May 2023).
- J. Si, J. Jeong, G. Kim, and S. Kim, “Style Interconversion of Korean Portrait and ID Photo Using CycleGAN,” Proc. of Korean Institute of Information Technology (KIIT), pages 147-149, 2020.
- J. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks,” Proc. of the IEEE International Conf. on Computer Vision (ICCV), pages 2223-2232, 2017.
- X. Huang and S. Belongie, “Arbitrary Style Transfer in Real-Time With Adaptive Instance Normalization,” Proc. of the IEEE International Conf. on Computer Vision (ICCV), pages 1501-1510, 2017.
- S. Huang, H. Xiong, T. Wang, Q. Wang, Z. Chen, J. Huan, and D. Dou, “Parameter-Free Style Projection for Arbitrary Style Transfer,” arXiv preprint arXiv:2003.07694, 2020.
- T. Zhu and S. Liu, “Detail-Preserving Arbitrary Style Transfer,” Proc. of IEEE International Conf. on Multimedia and Expo (ICME), pages 1-6, 2020.
- M. Elad and P. Milanfar, “Style Transfer Via Texture Synthesis,” IEEE Transactions on Image Processing, vol. 26, no. 5, pages 2338-2351, 2017.
- K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” Proc. of International Conf. on Learning Representations (ICLR), pages 1-14, 2015.
- S. Li, X. Xu, L. Nie, and T. Chua, “Laplacian-Steered Neural Style Transfer,” Proc. of ACM international conf. on Multimedia, pages 1716-1724, 2017.
- C. Chen, X. Tan, and K. Y. K. Wong, “Face Sketch Synthesis with Style Transfer Using Pyramid Column Feature,” Proc. of IEEE Winter Conf. on Applications of Computer Vision (WACV), pages 485-493, 2018.
- B. Blakeslee, R. Ptucha, and A. Savakis, “FASTER ART-CNN: AN EXTREMELY FAST STYLE TRANSFER NETWORK,” Proc. of IEEE Western New York Image and Signal Processing Workshop (WNYISPW), pages 1-5, 2018.
- X. Liu, X. Li, M. Cheng, and P. Hall, “Geometric style transfer,” arXiv preprint arXiv:2007.05471, 2020.
- P. Kaur, H. Zhang, and K. Dana, “Photo-Realistic Facial Texture Transfer,” Proc. of IEEE Conf. on Applications of Computer Vision (WACV), pages 2097-2105, 2019.
- R. Yi, Y. Liu, Y. Lai, and P. Rosin, “APDrawingGAN: Generating Artistic Portrait Drawings From Face Photos With Hierarchical GANs,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 10743-10752, 2019.
- Z. Xu, M. Wilber, C. Fang, A. Hertzmann, and H. Jin, “Learning from multi-domain artistic images for arbitrary style transfer,” Proc. of the ACM/Eurographics Expressive Symposium on Computational Aesthetics and Sketch-Based Interfaces and Modeling and Non-Photorealistic Animation and Rendering (Expressive ’19), pages 21-31, 2019.
- R. Zhang, S. Tang, Y. Li, J. Guo, Y. Zhang, J. Li, and S. Yan, “Style Separation and Synthesis via Generative Adversarial Networks,” Proc. of the ACM International Conf. on Multimedia, pages 183-191, 2018.
- D. Horita and K. Aizawa, “SLGAN: Style- and Latent-guided Generative Adversarial Network for Desirable Makeup Transfer and Removal,” Proc. of the ACM International Conf. on Multimedia in Asia, pages 1-8, 2022.
- T. Li, R. Qian, C. Dong, S. Liu, Q. Yan, W. Zhu, and L. Lin, “BeautyGAN: Instance-level Facial Makeup Transfer with Deep Generative Adversarial Network,” Proc. of the ACM international conf. on Multimedia, pages 645-653, 2018.
- H. Chang, J. Lu, F. Yu, and A. Finkelstein, “PairedCycleGAN: Asymmetric Style Transfer for Applying and Removing Makeup,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 40-48, 2018.
- R. Wu, X. Gu, X. Tao, X. Shen, Y. W. Tai, and J. Jia, “Landmark Assisted CycleGAN for Cartoon Face Generation,” arXiv preprint arXiv:1907.01424, 2019.
- S. Palsson, E. Agustsson, R. Timofte, and L. Van Gool, “Generative Adversarial Style Transfer Networks for Face Aging,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 2084-2092, 2018.
- Z. Wang, Z. Liu, J. Huang, S. Lian, and Y. Lin, “How Old Are You? Face Age Translation with Identity Preservation Using GANs,” arXiv preprint arXiv:1909.04988, 2019.
- R. Yi, Y. J. Liu, Y. K. Lai, and P. L. Rosin, “Unpaired portrait drawing generation via asymmetric cycle mapping,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages 8217-8225, 2020.
- L. A. Gatys, A. S. Ecker, and M. Bethge, “Image Style Transfer Using Convolutional Neural Networks,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 2414-2423, 2016.
- V. Kazemi and J. Sullivan, “One millisecond face alignment with an ensemble of regression trees,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 1867-1874, 2014.
- T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, “Spectral Normalization for Generative Adversarial Networks,” Proc. of the International Conf. on Learning Representations (ICLR), pages 1-10, 2018.
- C. Li and M. Wand, “Precomputed real-time texture synthesis with markovian generative adversarial networks,” Proc. of the European Conf. on Computer Vision (ECCV), pages 702-716, 2016.
- J. Si and S. Kim, “Traffic Accident Detection in First-Person Videos based on Depth and Background Motion Estimation,” Journal of Korean Institute of Information Technology (JKIIT), vol. 19, no. 3, pages 25-34, 2021.
- A. Hor’e and D. Ziou, “Image Quality Metrics: PSNR vs. SSIM,” Proc. of the International Conf. on Pattern Recognition (ICPR), pages 2366-2369, 2010.
n generative adversarial networks," Proc. of the European Conf. on Computer Vision (ECCV), pages 702-716, 2016. - J. Si and S. Kim, “Traffic Accident Detection in First-Person Videos based on Depth and Background Motion Estimation,” Journal of Korean Institute of Information Technology (JKIIT), vol. 19, no. 3, pages 25-34, 2021.
- A. Hor’e and D. Ziou, “Image Quality Metrics: PSNR vs. SSIM,” Proc. of the International Conf. on Pattern Recognition (ICPR), pages 2366-2369, 2010.