PatchmatchNet,论文名为:PatchmatchNet: Learned Multi-View Patchmatch Stereo,本篇论文结合了较多过往文章的优化思想和类似模块,因此可能要更复杂一些。
本文是MVSNet系列的第10篇,建议看过【论文精读1】MVSNet系列论文详解-MVSNet之后再看便于理解。
一、模型结构
- 这篇论文模型部分是按照模块功能来划分介绍(初始化、传播、评估),但由于是分Stage的由粗到细推断、且每个Stage当中会迭代多个iteration,因此直接按模块理解起来很绕,为方便理解以下讲解部分按照时间顺序来介绍一个完整的训练流程(Stage3 - Stage 0)
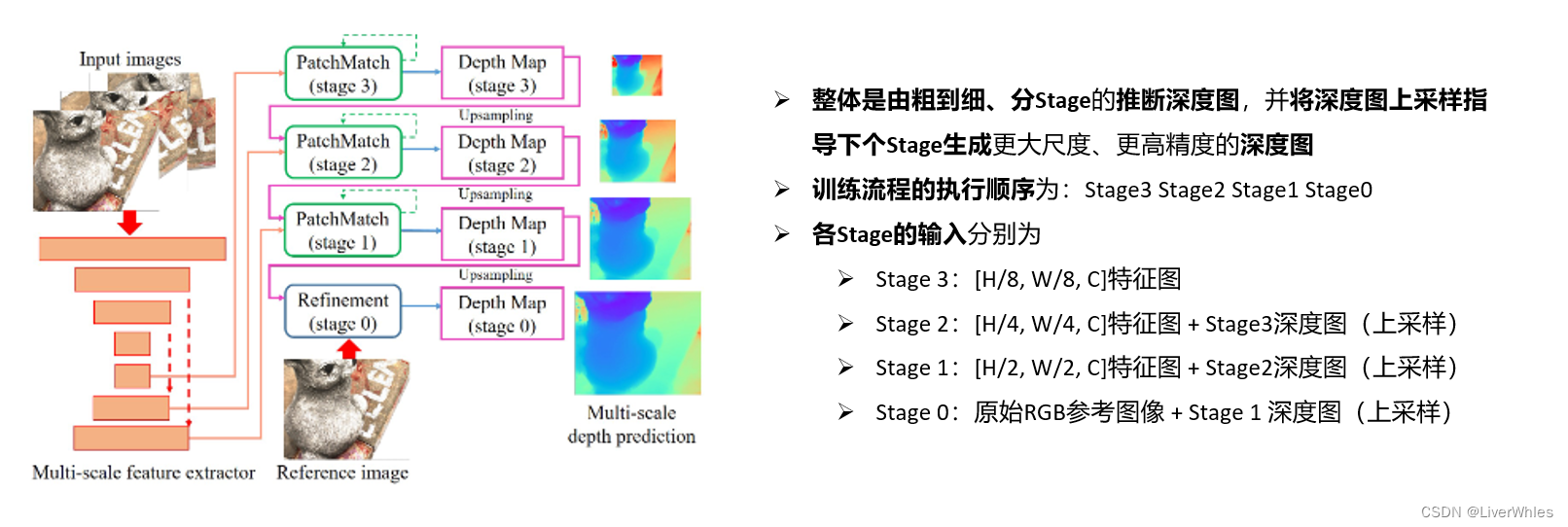
二、训练流程
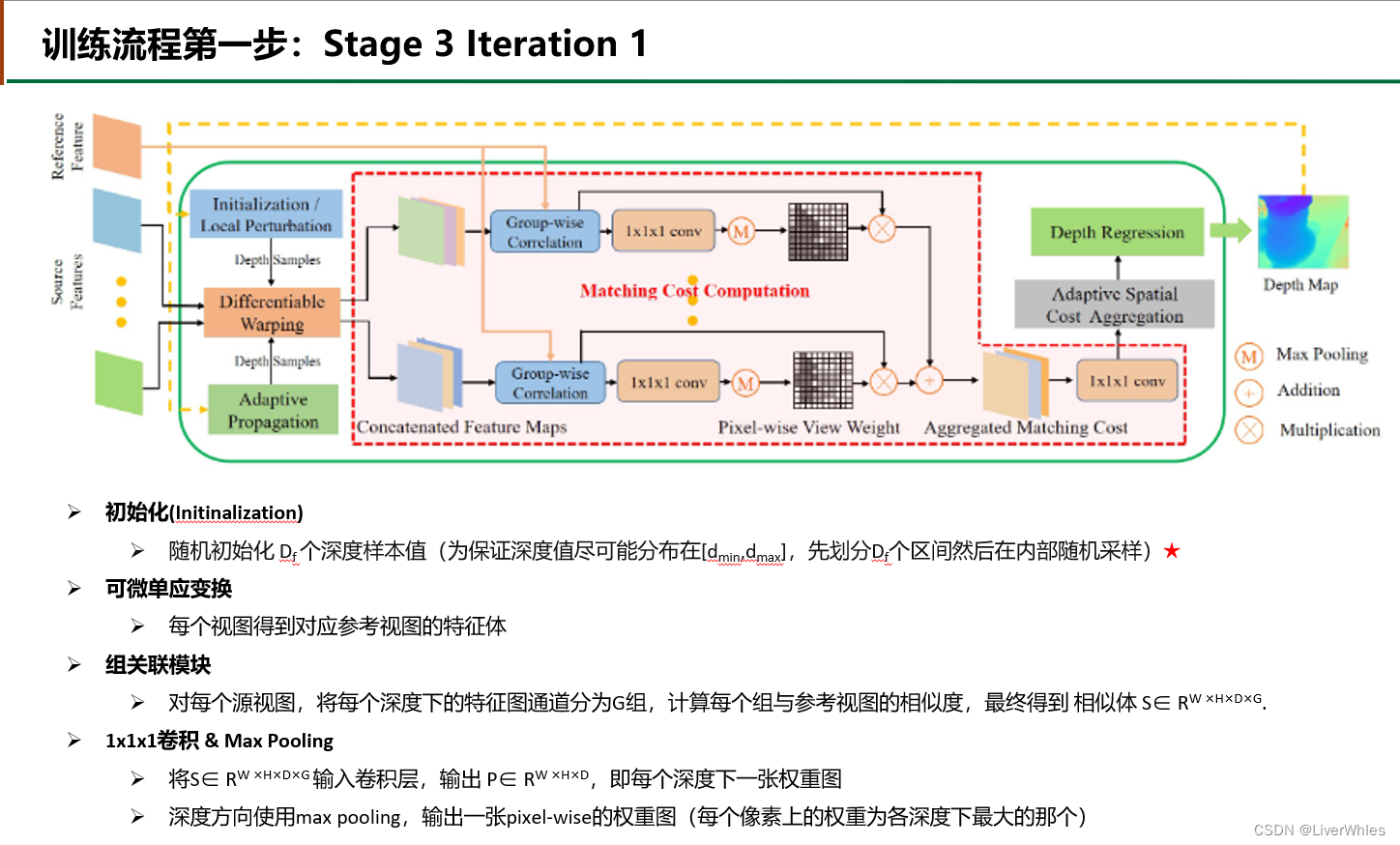
- 在Stage 1 的 第一个iteration,对于深度样本的选取只使用了 Initinalizaiton模块(Local Perturbation、Adaptive Propagation在下一个iteration才使用)
- 可微单应变换和MVSnet一致
- 组关联模块来自CIDER 2.代价体构建部分,即将特征体的32通道分为G个组,然后与参考视图的特征体按组计算出G张相似度图(其实就是逐特征通道做内积,然后一组内的加在一起取平均作为相似度)
- 随后基于与参考视图上各像素点特征的相似情况,使用1X1X1的卷积来计算出一张包含各像素权重的权重图
- 将各源视图的特征体乘以权重后取平均来构建聚合的匹配代价体(之所要加上权重,是因为参考视图中有些像素点可能由于遮挡等问题,在某张源视图中并不存在对应点,这时候该视图下提供的该像素点的特征(即错误的),如果被均匀的计算方差来代表整体匹配代价那可肯定会造成误差;而通过预先计算各视图下各像素点是否与参考视图下足够相似(即能够匹配)来赋予较大权重,匹配度低赋予较小权重,就可以减少由遮挡、光照等不同视角变换时误匹配带来的损失)
- 随后通过1x1x1的卷积来变换通道数(将 【宽、高、组(Group)、深度】变为 【宽、高、深度】的代价体,其实就是聚合Group维度,来使得每个假设深度下存在一张匹配代价图,即各像素点若在该深度下,则具体的匹配代价为C(h,w,d))
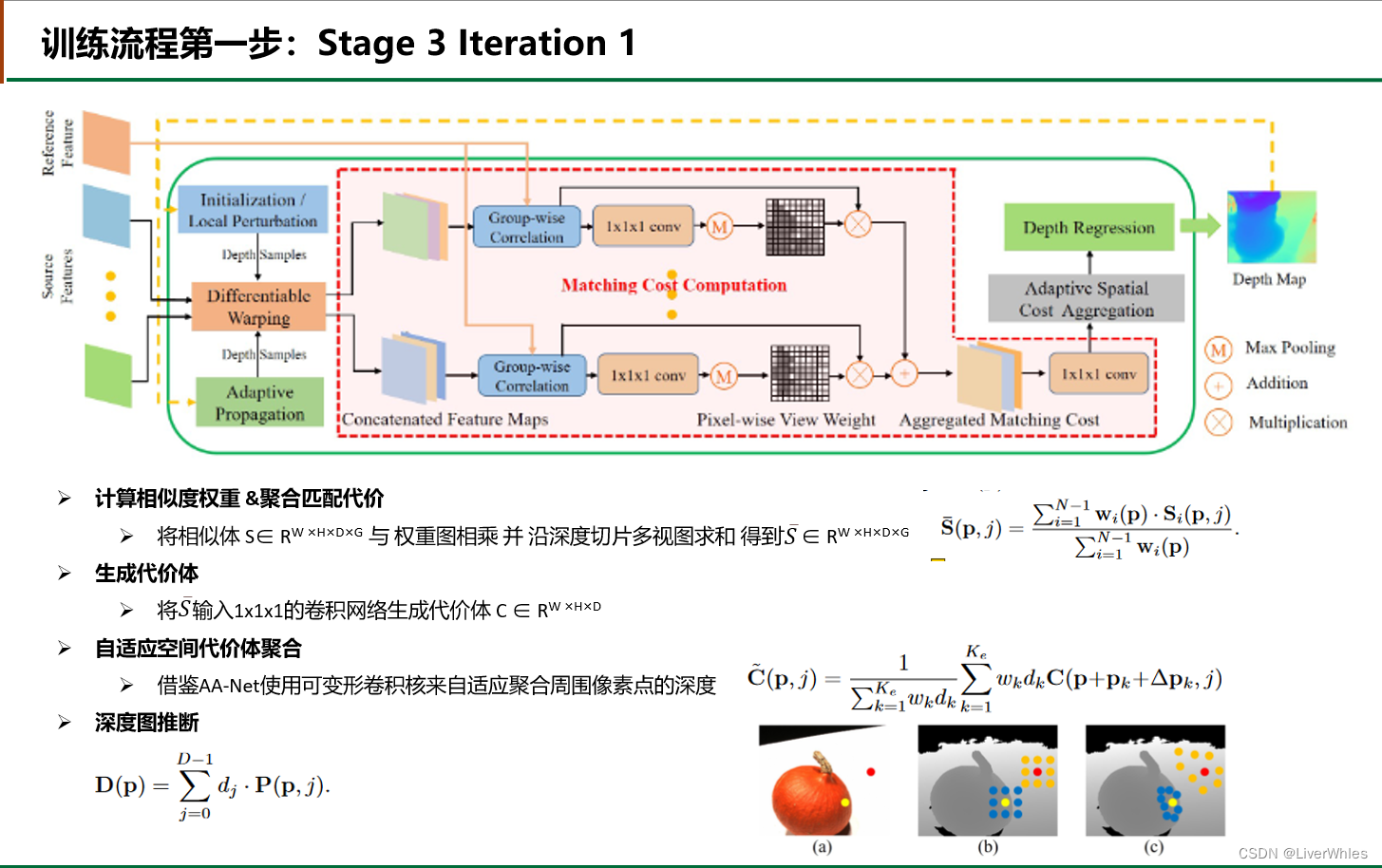
- 在利用各像素点在各深度下匹配代价(匹配代价越小越可能在该深度)计算估计深度之前,考虑周围在同一物体平面上的点的深度可能是很相似的,因此使用卷积网络在参考视图的特征图上去做卷积,为每一个像素点输出周围N个像素点来一起计算该像素点深度(如图中abc所示,b为传统直接取周围固定间距的8个点,而自适应选取的意思就是让神经网络根据各像素点与周围点特征,选取周围可变距离的8各点,可以看到在物体边缘纹理丰富处间距小,而纹理稀疏处间距大,这就是自适应的含义),其中wk和dk是周围各点对中心点深度影响的权重,具体值则是根据在特征图和深度图上计算相似度得到的
- 得到最终考虑周围点深度的代价体之后,对各深度下各像素点的匹配代价值取负号即变为概率体P(即匹配代价越小在该深度概率越大),随后通过MVSNet的求期望方式得到该点的最终深度推断值
- 在经过Iteration 1 之后产生了深度图(H/8, W/8),之后Stage 3 的多个iteration 都可以用上一个iteration的深度图来选取新的深度样本,其中用于做单应变换的深度样本值来自两个模块的总和 ——
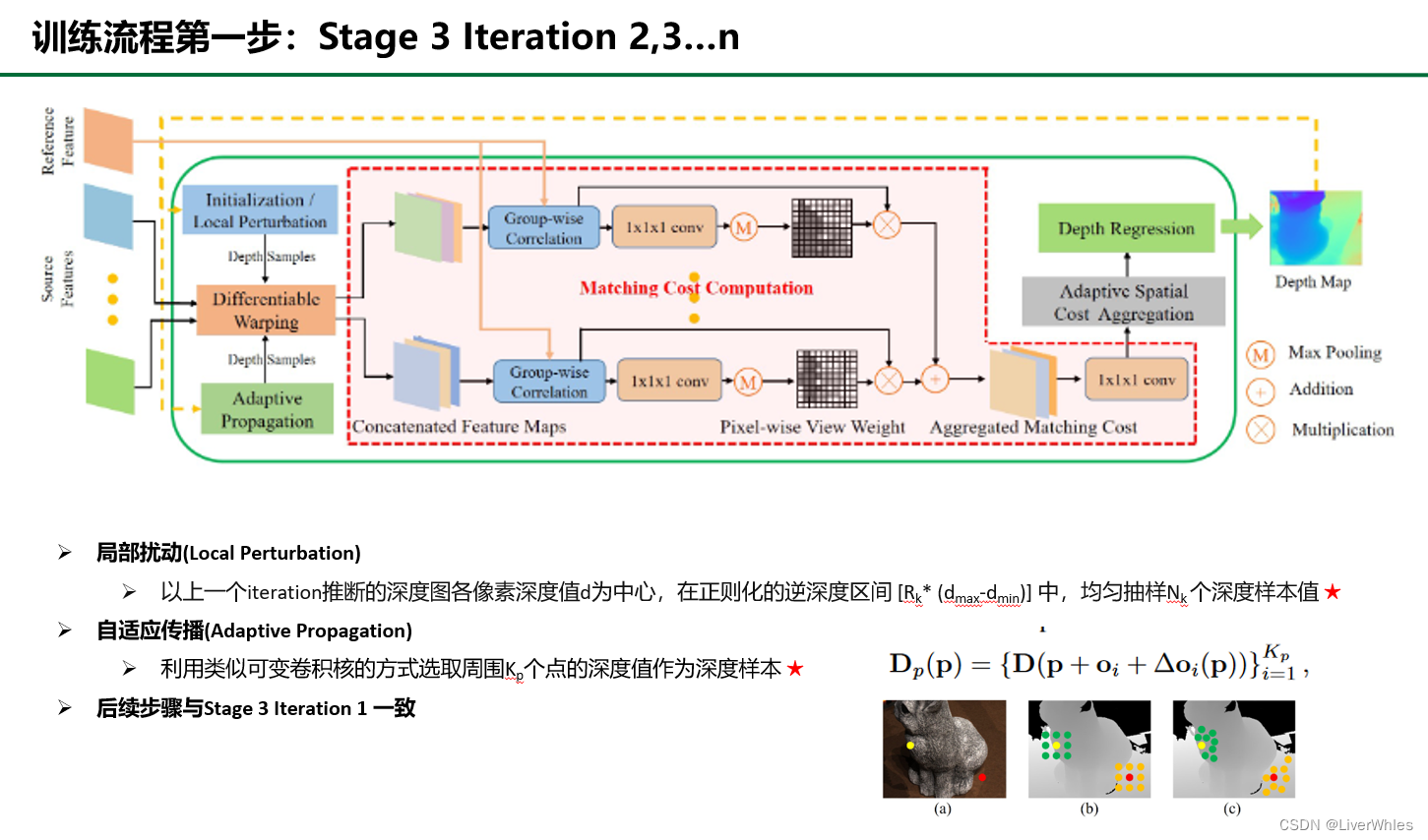
- 局部扰动(Local perturbation) 从以上一个iteration的深度图上各像素深度值为中心,[RK* (dmax-dmin)]即原始深度范围*RK的区间上均匀采样深度值(Rk随Stage推进逐渐变小,因为推断的深度越来越精确且可以减少内存和时间消耗)
- 自适应传播(Adaptive Propagation)类似上一步的可变卷积核概念,只不过这一次不是利用周围点来计算当前点深度,而是直接选取周围区域可变距离的k个点的深度值作为深度假设,这样每个点都可能逐渐利用到周围点的深度并逐渐扩展到所有点,也是**“传播”一词的含义所在**
- 在确定深度假设值之后,和前边iteration的单应变换及之后的步骤一致,迭代的推断出新的深度图,直到迭代至设定的n次则Stage 3结束
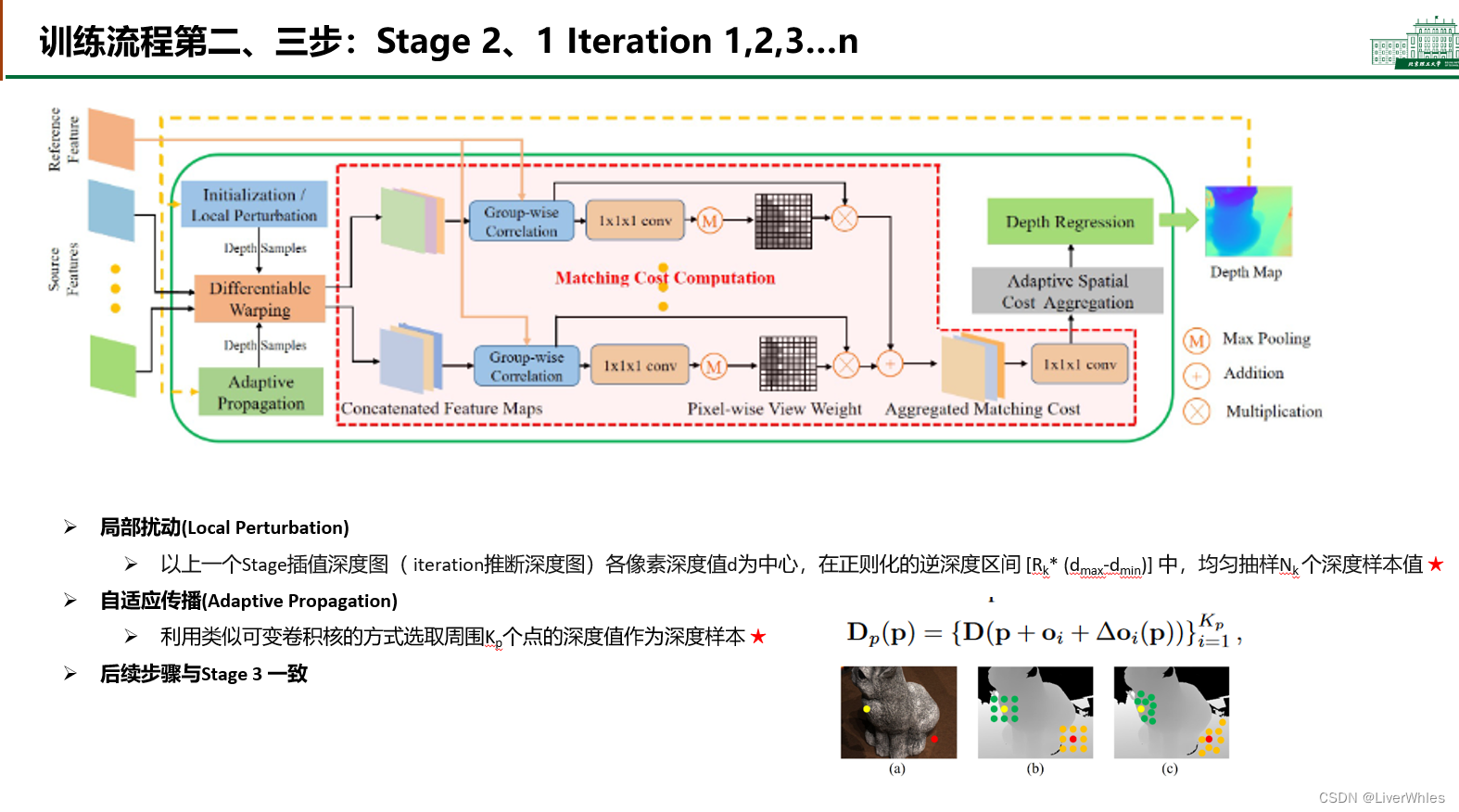
- 在Stage 2 iteration 1,深度采样类似于之前的Stage 3 iteration2,但深度图来自上一个Stage,因此需要做一个插值后再进行
- 之后的iteration则和Stage 3 iteration2后续完全一致
- Stage 1也与上两步一致
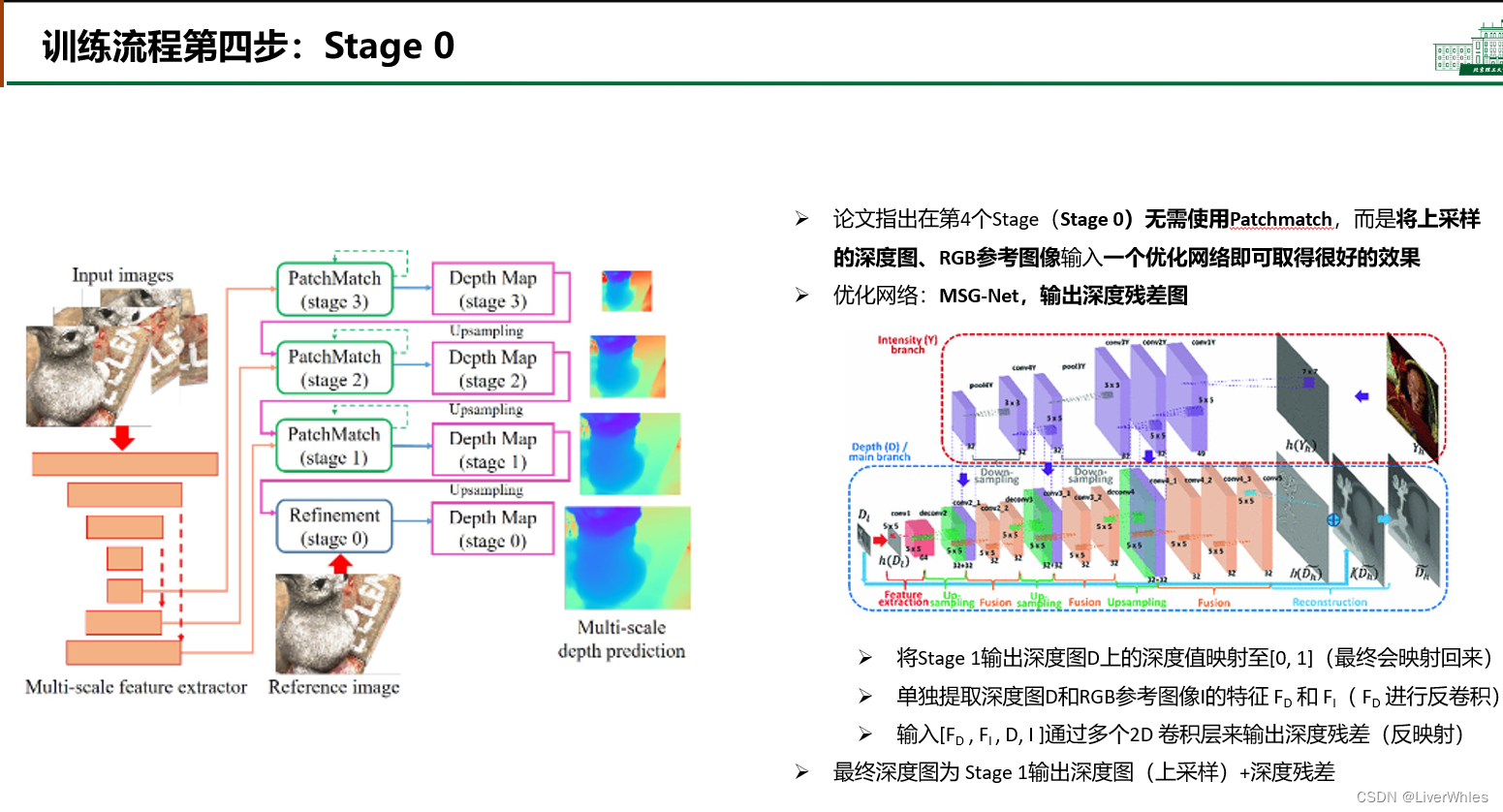
- 论文最后一步没有再使用Patchmatch,而是用了一个优化网络做最后一次优化并恢复深度图至输入图像的尺度

三、总结
- 整体来看PatchmatchNet使用了之前MVSNet中多种优化的技巧(多尺度由粗到细优化、组关联度、考虑视图间遮挡因素、可变卷积等),并且引入传播的概念来让各点试探周围同物体表面的深度值
- 更离谱的是看supplementary还发现很多再读论文觉得明白时、但其实没有考虑到的问题——比如文中由于各点深度采样可能来自initialization的随机选取、或是基于上一次深度推断的local perturbation(加上局部扰动)、亦或是直接选取来自周围同表面点的深度,因此导致构建的“代价体”和MVSNet里边直接取D个统一深度假设平面的代价体时不一样的,它的代价体由于各像素点的深度取值不同,因而假设深度D个数一致但具体值不同导致代价体不规则,因而直接使用之前模型常用的3D U-Net来进行正则化时无益的(因为同一深度层周围像素点的深度值可能不同、各像素深度维度具体取值也不同,UNet聚合空间上下文及深度维度的作用无法发挥)…只能说太强了🤦♂️
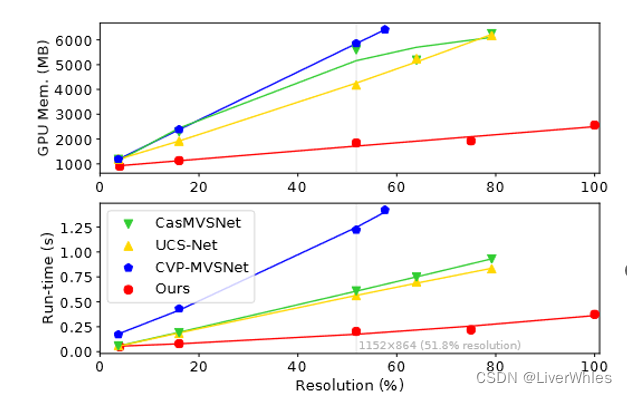
- 从结果上来说,它的精度不是最好却在第一阶梯,但完整度损失直接降低了20%达到0.277,均衡损失也在第一阶梯;更重要的是它的内存、时间消耗非常少
- 论文写作上也有值得学习之处,不仅英语语法和语句高级感十足,而且对模型各模块开头先讲一个听起来很有道理的故事动机,然后引入具体的模块实现,这种写作逻辑读起来引人入胜