需求:
创建基于Maven的Java项目,连接数据库,实现对站点信息的管理,即实现对站点的新增,修改,删除,查询操作。
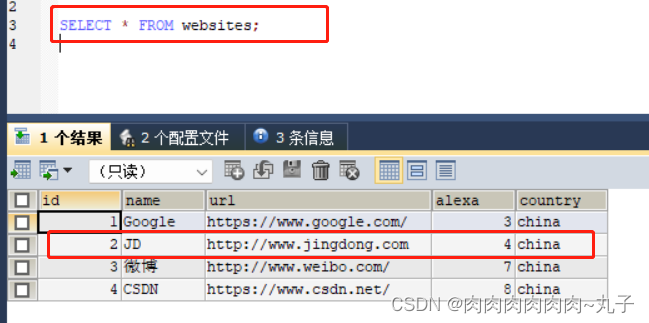
以下是站点表的建表语句:
CREATE TABLE `websites` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(20) NOT NULL DEFAULT '' COMMENT '站点名称',
`url` varchar(255) NOT NULL DEFAULT '',
`alexa` int(11) NOT NULL DEFAULT '0' COMMENT 'Alexa 排名',
`country` char(10) NOT NULL DEFAULT '' COMMENT '国家',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;步骤:
1. 创建 Maven 项目:
- 使用 Maven 创建一个新的 Java 项目
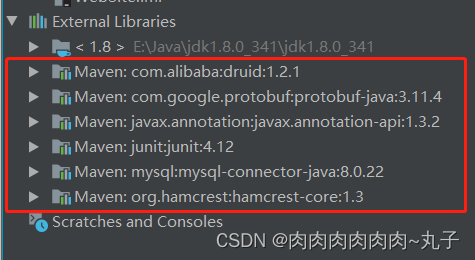
- 在项目的 `pom.xml` 文件中添加所需的依赖项
【MysQL Connector/J 、Druid 版本 1.2.1、Junit 版本 4.12】
新建`libs`文件夹添加相应的jar包:

pom.xml代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.ambow</groupId>
<artifactId>WebSite</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>解析上述代码含义:
这是一个 Maven POM(Project Object Model)文件,用于描述和管理 Java 项目的结构、依赖关系和构建配置。
- `<project>` 元素是根元素,包含整个 POM 文件的内容。
- `xmlns` 属性定义了 XML 命名空间,指定了 Maven 的命名空间。
- `xmlns:xsi` 属性定义了 `xsi` 命名空间,并指定了 `xsi` 命名空间的位置。
- `xsi:schemaLocation` 属性指定了 XSD(XML Schema Definition)的位置,以验证 POM 文件的格式是否正确。
- `<modelVersion>` 元素指定了 POM 模型的版本,通常使用 4.0.0。
- `<groupId>` 元素定义了项目的组织或组织的唯一标识符。
- `<artifactId>` 元素定义了项目的唯一标识符,通常是项目的名称。
- `<version>` 元素定义了项目的版本号。
- `<dependencies>` 元素包含了项目所依赖的外部库或模块。
- `<dependency>` 元素定义了一个依赖项。
- `<groupId>` 元素指定了依赖项的组织或组织的唯一标识符。
- `<artifactId>` 元素指定了依赖项的唯一标识符,通常是库或模块的名称。
- `<version>` 元素指定了依赖项的版本号。
- `<scope>` 元素定义了依赖项的作用范围,例如编译时依赖、测试时依赖等。
该项目使用了以下依赖项:
- MySQL Connector/J 版本 8.0.22:用于与 MySQL 数据库建立连接。
- Druid 版本 1.2.1:一个 Java 数据库连接池。
- Junit 版本 4.12:用于编写和运行单元测试。
这段代码描述了一个基于 Maven 的 Java 项目的结构和依赖关系。它还可以包含其他配置,例如构建插件、资源文件的位置和项目的特定设置等。
2. 创建站点实体类:
- 在项目中创建一个名为 `Website` 的 Java 类,代表站点对象
- 在 `Website` 类中定义站点属性(id、name、url、alexa、country)
提供相应的 getter 和 setter 方法
package com.ambow.druid;
/*
* 实体类(封装数据)
* 封装:
* 1.属性私有化
* 2.公共的get set方法
*
* */
public class website {
//属性 --数据表的字段
private int id;
private String name;
private String url;
private int alexa;
private String country;
//构造方法
public website(){
}
public website(int id, String name, String url, int alexa, String country) {
this.id = id;
this.name = name;
this.url = url;
this.alexa = alexa;
this.country = country;
}
public website(String name, String url, int alexa, String country) {
this.name = name;
this.url = url;
this.alexa = alexa;
this.country = country;
}
//get set方法
public int getId(){
return id;
}
public void setId(int id){
this.id = id;
}
public String getName(){
return name;
}
public void setName(String name){
this.name = name;
}
public String geturl(){
return url;
}
public void setUrl(String url){
this.url = url;
}
public int getAlexa(){
return alexa;
}
public void setAlexa(int alexa){
this.alexa = alexa;
}
public String getCountry(){
return country;
}
public void setCountry(String country){
this.country = country;
}
@Override
public String toString(){
return "website{" +
"id = " + id +
",name = " + name + '\'' +
",url = " + url + '\'' +
",alexa = " + alexa + '\'' +
",country = " + country + '\'' + '}';
}
}
3. 创建数据库访问对象Dao:
- 创建一个名为 `WebsiteDao` 的 Java 类,用于执行站点信息在数据库中的增删改查操作
- 在 `WebsiteDao` 类中使用 JDBC 或者任何 ORM 框架(如 MyBatis)来连接数据库
实现对站点信息的新增、修改、删除和查询操作
package com.ambow.druid;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
/*
* Website数据访问对象
* 跟站点操作相关的方法
* 1.添加
* 2.修改
* 3.删除
* 4.查询
* */
public class WebsiteDao {
//新增站点
public int addSite(website site) throws Exception{
//把站点,连接数据库,保存数据库
int row = 0;
Connection conn = DruidUtil.getConn();
String sql ="insert into websites values(null,?,?,?,?)";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1,site.getName());
pstmt.setString(2,site.geturl());
pstmt.setInt(3,site.getAlexa());
pstmt.setString(4,site.getCountry());
row = pstmt.executeUpdate();
return row;
}
public void modifySite(){
}
public void dropSite(){
}
public ArrayList<website> selectSite() throws Exception{
ArrayList<website> list = new ArrayList<website>();
Connection conn = DruidUtil.getConn();
String sql = "select * from websites";
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery();
while(rs.next()){
website site = new website();
site.setId(rs.getInt(1));
site.setName(rs.getString(2));
site.setUrl(rs.getString(3));
site.setAlexa(rs.getInt(4));
site.setCountry(rs.getString(5));
list.add(site);
}
return list;
}
}
4. 创建工具类 DruidUtil :
- 创建一个名为`DruidUtil`的工具类 ,主要用于获取数据库连接
- 只需通过调用 DruidUtil.getConn() 方法,获取到一个可用的数据库连接
package com.ambow.druid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.util.Properties;
public class DruidUtil {
//获取数据库连接
public static Connection getConn() throws Exception{
Connection connection = null;
Properties prop = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
prop.load(is);
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
connection = dataSource.getConnection();
return connection;
}
}解析上述代码含义:
首先,通过 `ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties")` 获取 `druid.properties` 配置文件的输入流,并使用 `Properties` 类加载配置文件。
然后,使用 `DruidDataSourceFactory.createDataSource(prop)` 创建了一个数据源 `DataSource` 对象。
接着,调用 `dataSource.getConnection()` 方法获取一个数据库连接 `Connection` 对象,并将其返回给调用者。
这个工具类的作用:封装了获取数据库连接的操作,使得其他代码可以方便地调用该方法来获取数据库连接而无需重复编写获取连接的代码。
5. 实现站点管理功能:
- 创建一个名为 `DruidSys` 的 Java 类,用于处理站点信息的业务逻辑
- 在 `DruidSys` 类中使用Druid连接池和MySQL数据库进行站点管理的,实现了增删改查功能
package com.ambow.druid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.Properties;
import java.util.Scanner;
public class DruidSys {
static Scanner sc = new Scanner(System.in);
public static void main(String[] args) throws Exception {
while (true) {
System.out.println("------------------------------");
System.out.println("-------- 站点管理系统 ---------");
System.out.println("-------- 1.新增站点 ---------");
System.out.println("-------- 2.删除站点 ---------");
System.out.println("-------- 3.修改站点 ---------");
System.out.println("-------- 4.查询站点 ---------");
System.out.println("-------- 0.退出系统 ---------");
System.out.println("-------- 请选择!!! ---------");
int choose = sc.nextInt();
switch (choose) {
case 1:
addWebsite();
break;
case 2:
deleteWebsite();
break;
case 3:
modifyWebsite();
break;
case 4:
queryWebsite();
break;
case 0:
System.out.println("退出系统!");
System.exit(0);
break;
default:
System.out.println("对不起,我的能力有限!");
break;
}
}
}
//添加站点信息
private static void addWebsite() throws Exception {
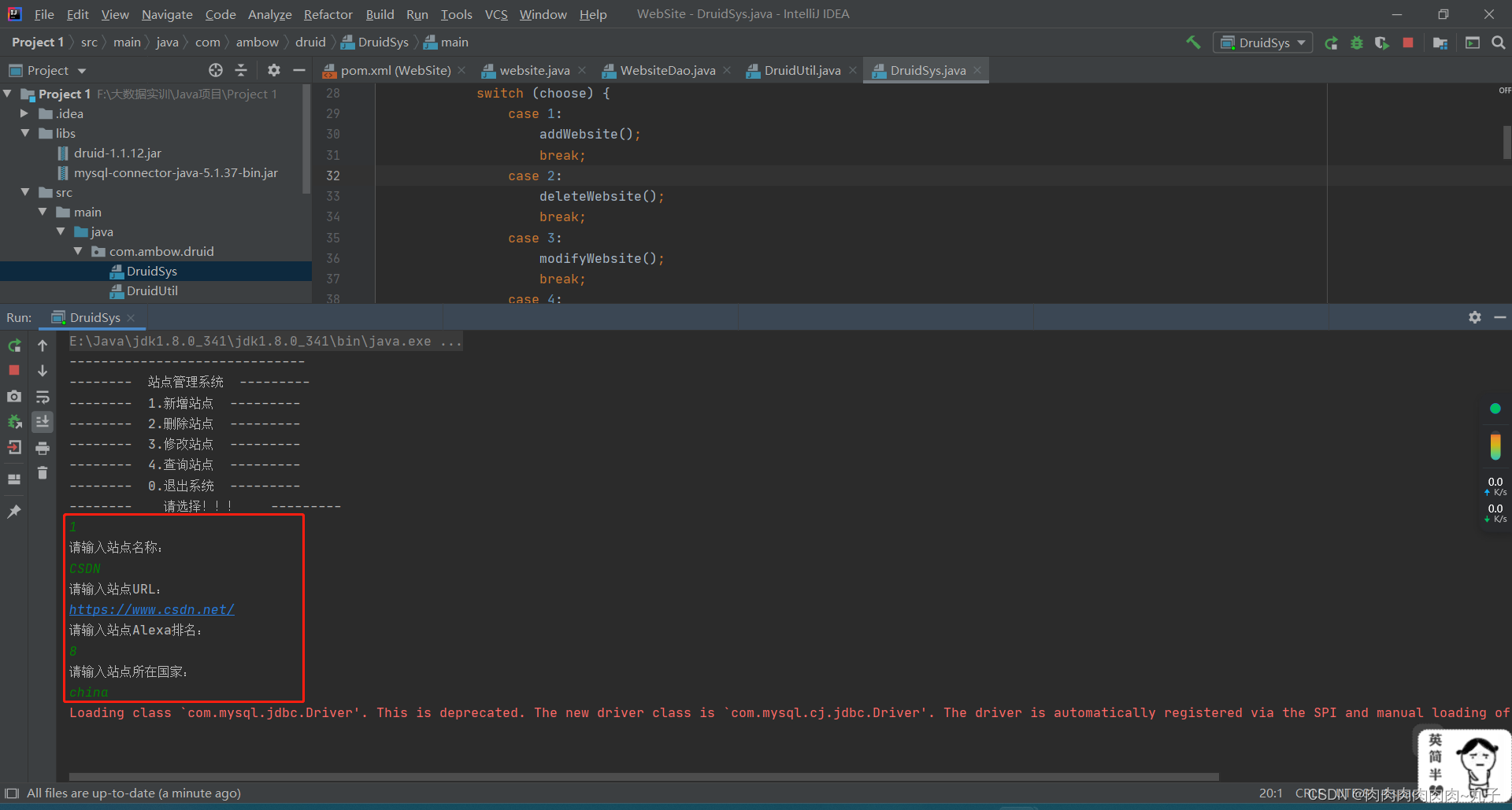
System.out.println("请输入站点名称:");
String name = sc.next();
System.out.println("请输入站点URL:");
String url = sc.next();
System.out.println("请输入站点Alexa排名:");
int alexa = sc.nextInt();
System.out.println("请输入站点所在国家:");
String country = sc.next();
Properties prop = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
prop.load(is);
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
Connection conn = dataSource.getConnection();
String sql = "INSERT INTO websites (name, url, alexa, country) VALUES (?, ?, ?, ?)";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, name);
pstmt.setString(2, url);
pstmt.setInt(3, alexa);
pstmt.setString(4, country);
int row = pstmt.executeUpdate();
if (row != 0) {
System.out.println("添加站点成功!");
} else {
System.out.println("添加站点失败!");
}
pstmt.close();
conn.close();
}
//删除站点信息
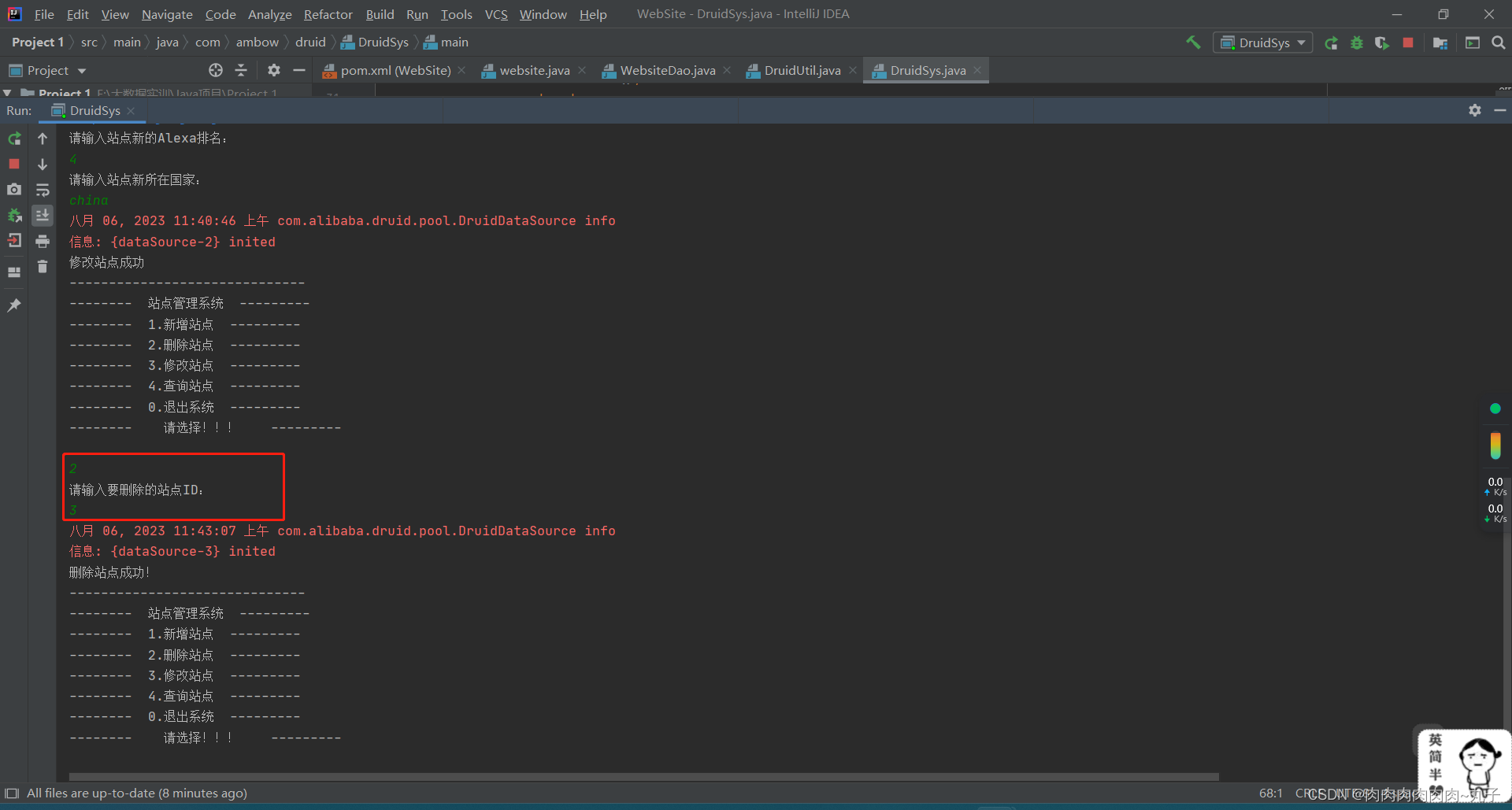
private static void deleteWebsite() throws Exception {
System.out.println("请输入要删除的站点ID:");
int id = sc.nextInt();
Properties prop = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
prop.load(is);
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
Connection conn = dataSource.getConnection();
String sql = "DELETE FROM websites WHERE id = ?";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, id);
int row = pstmt.executeUpdate();
if (row != 0) {
System.out.println("删除站点成功!");
} else {
System.out.println("删除站点失败!");
}
pstmt.close();
conn.close();
}
//修改站点信息
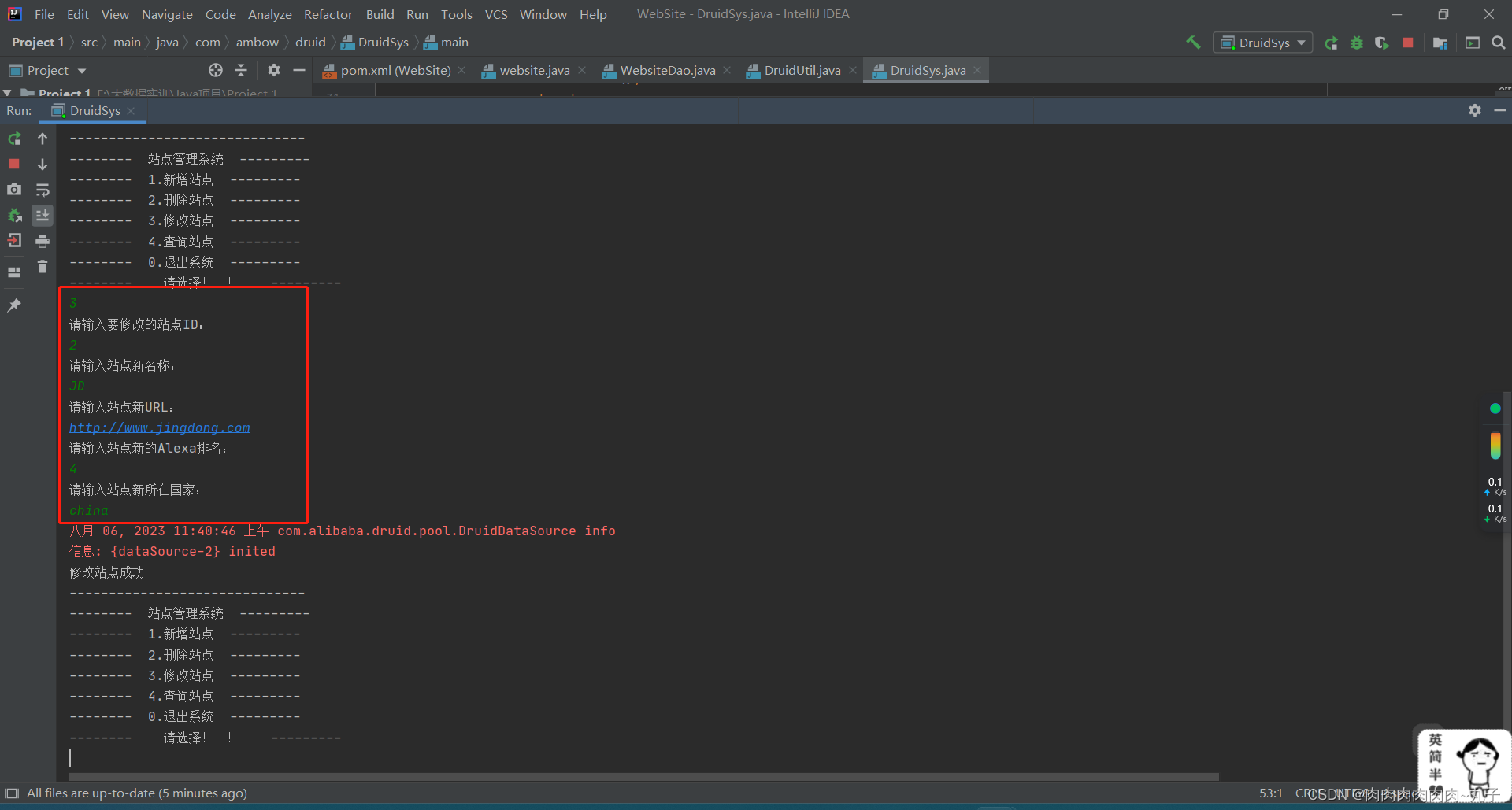
private static void modifyWebsite() throws Exception {
System.out.println("请输入要修改的站点ID:");
int id = sc.nextInt();
System.out.println("请输入站点新名称:");
String name = sc.next();
System.out.println("请输入站点新URL:");
String url = sc.next();
System.out.println("请输入站点新的Alexa排名:");
int alexa = sc.nextInt();
System.out.println("请输入站点新所在国家:");
String country = sc.next();
Properties prop = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
prop.load(is);
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
Connection conn = dataSource.getConnection();
String sql = "UPDATE websites SET name = ?, url = ?, alexa = ?, country = ? WHERE id = ?";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, name);
pstmt.setString(2, url);
pstmt.setInt(3, alexa);
pstmt.setString(4, country);
pstmt.setInt(5, id);
int row = pstmt.executeUpdate();
if (row != 0) {
System.out.println("修改站点成功");
} else {
System.out.println("修改站点失败");
}
pstmt.close();
conn.close();
}
//查询站点信息
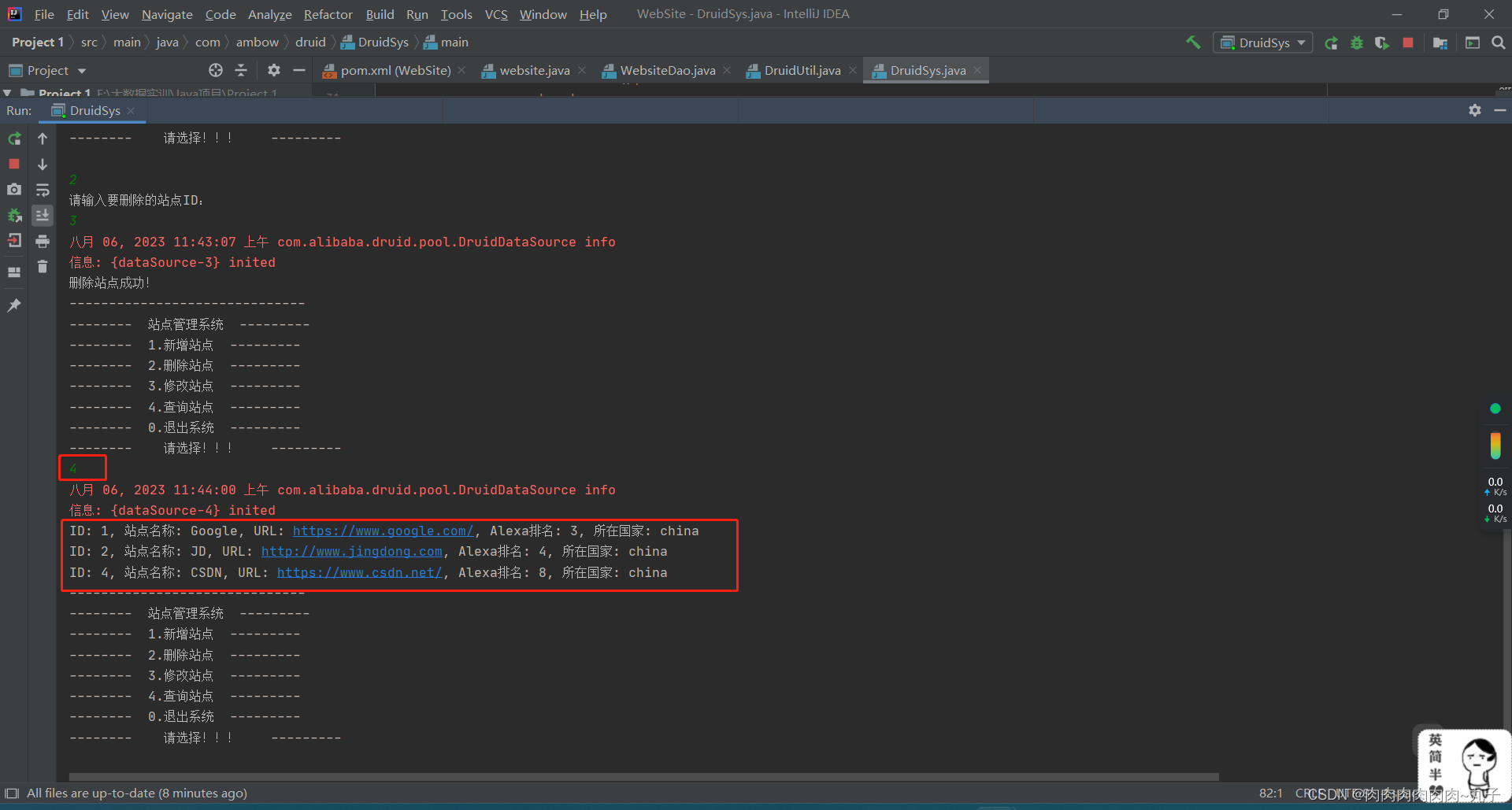
private static void queryWebsite() throws Exception {
Properties prop = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
prop.load(is);
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
Connection conn = dataSource.getConnection();
String sql = "SELECT * FROM websites";
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery();
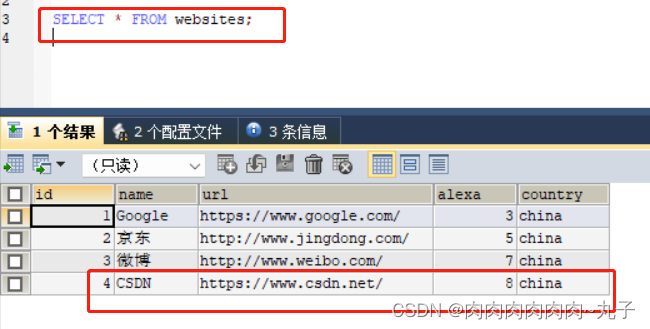
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
String url = rs.getString("url");
int alexa = rs.getInt("alexa");
String country = rs.getString("country");
System.out.println("ID: " + id + ", 站点名称: " + name + ", URL: " + url + ", Alexa排名: " + alexa + ", 所在国家: " + country);
}
rs.close();
pstmt.close();
conn.close();
}
}
解析上述代码含义:
代码使用了Druid连接池,首先通过`DruidDataSourceFactory.createDataSource(prop)`创建了一个数据源`dataSource`,其中`prop`是加载的配置文件`druid.properties`。然后获取数据库连接`Connection conn = dataSource.getConnection()`。
接下来,代码提供了一个菜单选择功能,用户可以选择新增、删除、修改或查询站点的操作。根据用户的选择,调用相应的方法进行处理。
- `addWebsite` 方法用于添加新的站点。用户需要输入站点名称、URL、Alexa排名和所在国家,然后通过执行INSERT语句将站点信息插入到数据库中。
- `deleteWebsite` 方法用于删除指定的站点。用户需要输入要删除的站点ID,然后通过执行DELETE语句从数据库中删除对应的站点信息。
- `modifyWebsite` 方法用于修改指定的站点信息。用户需要输入要修改的站点ID,然后输入新的站点名称、URL、Alexa排名和所在国家,通过执行UPDATE语句更新数据库中对应的站点信息。
- `queryWebsite` 方法用于查询所有站点信息。通过执行SELECT语句从数据库中获取所有站点的信息,并打印显示出来。
无论是新增、删除、修改还是查询,都会在完成操作后关闭连接和相关资源。
项目结构如下:
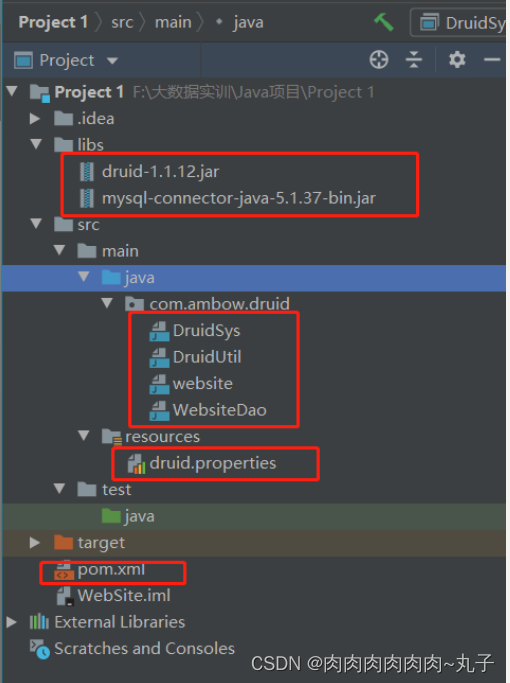
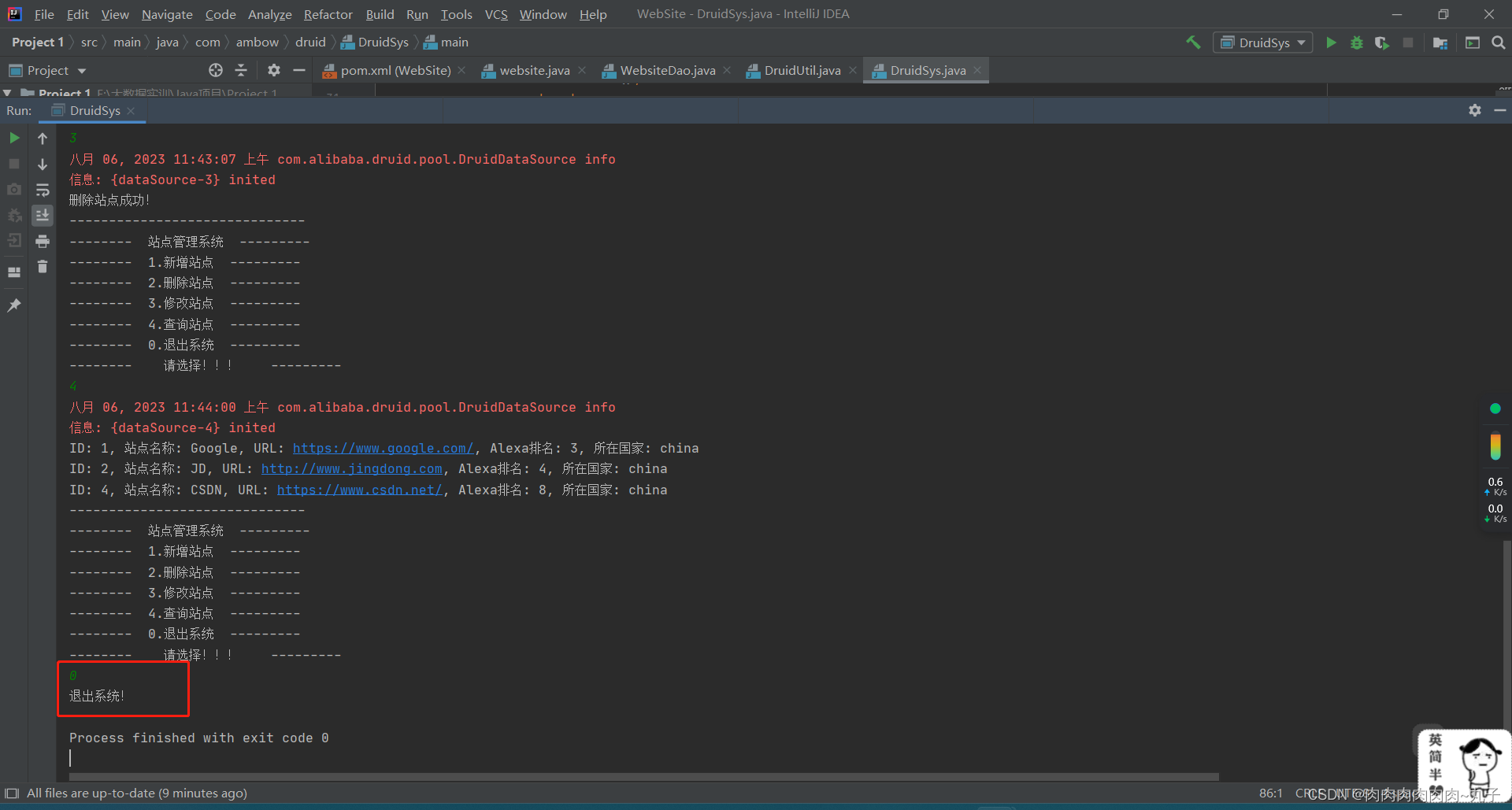
运行主程序:
`DruidSys `:
增
改
删

查
退出程序: