
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,Kerberos安全认证,大数据OLAP体系技术栈-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1.MergeTree引擎表目录解析
2. MergeTree引擎表设置分区
1.MergeTree引擎表目录解析
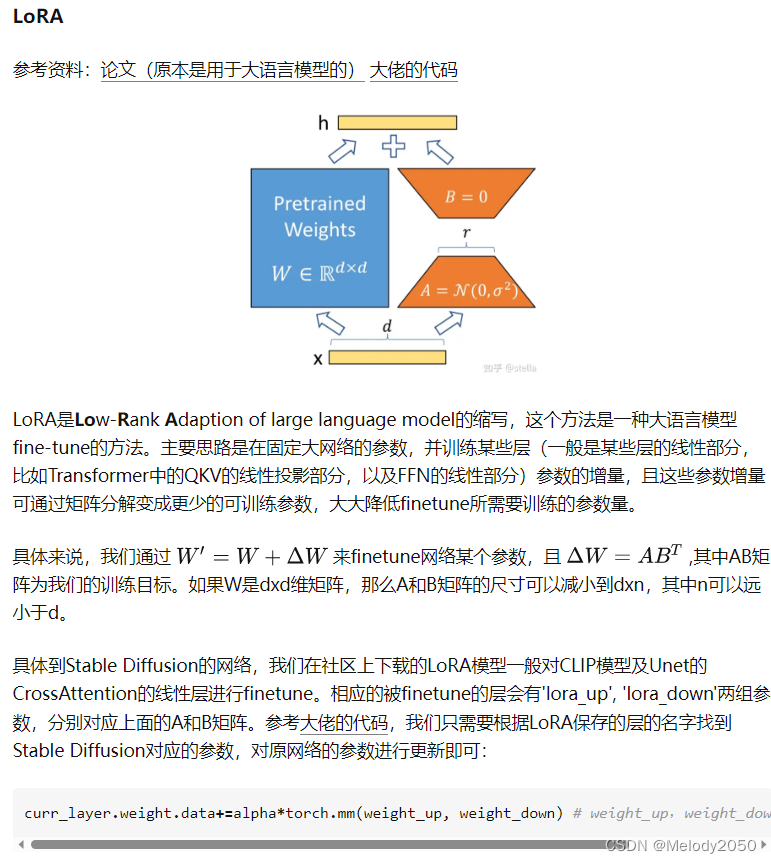
下面我们介绍下MergeTree引擎表 t_mt对应到磁盘的数据目录,为了方便从零开始了解,这里我们删除t_mt表,重新创建t_mt表,并插入数据,执行命令如下:
#删除表 t_mt,重新创建表t_mt,并加载数据
node1 :) drop table t_mt;
node1 :)create table t_mt( id UInt8, name String, age UInt8, birthday Date, location String ) engine = MergeTree() order by (id,age) partition by toYYYYMM(birthday);
node1 :) insert into t_mt values (1,'张三',18,'2021-06-01','上海'), (2,'李四',19,'2021-02-10','北京'), (3,'王五',12,'2021-06-01','天津'), (1,'马六',10,'2021-06-18','上海'), (5,'田七',22,'2021-02-09','广州');以上创建好表t_mt,当插入数据完成后,在clickhouse节点/var/lib/clickhouse/data/newdb/路径下会生成对应目录“t_mt”,进入此目录下,可以看到对应的分区目录,如图示:

以上分区目录也可以在系统表“system.parts”中查询得到:
#在系统表 system.part中查询表 t_mt的分区信息:
node1 :) select table ,partition ,name ,active from system.parts where table = 't_mt';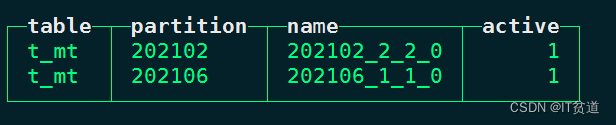
以上表各列的解释如下:
- table代表当前表。
- partition是当前表的分区名称。
- name是对应到磁盘上数据所在的分区目录片段。例如“202102_2_2_0”中“202102”是分区名称,“2”是数据块的最小编号,“2”是数据块的最大编号,“0”代表该块在MergeTree中第几次合并得到。
- active代表当前分区片段的状态:1代表激活状态,0代表非激活状态,非激活片段是那些在合并到较大片段之后剩余的源数据片段,损坏的数据片段也表示为非活动状态。非激活片段会在合并后的10分钟左右被删除。
进入到某一个分区目录片段“202102_2_2_0”中,我们可以看到如下目录:
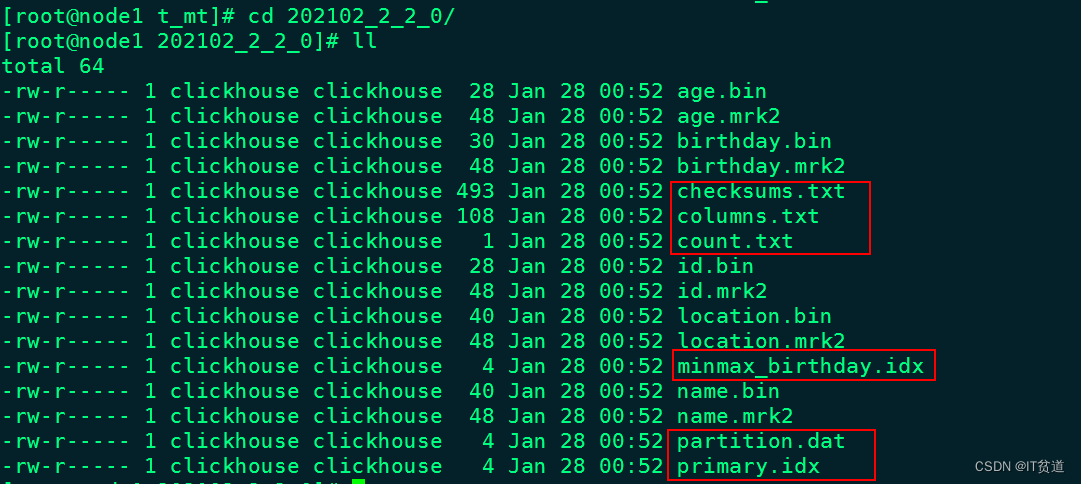
对以上目录的解释如下:
- checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件(primary. idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
- columns.txt: 存储当前分区所有列信息。使用明文格式存储。
[root@node1 202102_2_2_0]# cat columns.txt
columns format version: 1
5 columns:
`id` UInt8
`name` String
`age` UInt8
`birthday` Date
`location` String- count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数。
[root@node1 202102_2_2_0]# cat count.txt
2- primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引,即通过ORDER BY或者PRIMARY KEY指定字段。借助稀疏索引,在数据查询的时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。
- 列.bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据。由于MergeTree采用列式存储,所以每一个列字段都拥有独立的.bin数据文件,并以列字段名称命名。
- 列.mrk2:列字段标记文件,使用二进制格式存储。标记文件中保存了.bin文件中数据的偏移量信息
- partition.dat与minmax_[Column].idx:如果指定了分区键,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值,即分区字段值;而minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值。比如当使用birthday字段对应的原始数据为2021-02-17、2021-02-23,分区表达式为PARTITION BY toYYYYMM(birthday),即按月分区。partition.dat中保存的值将会是202102,而minmax索引中保存的值将会是2021-02-17、2021-02-23。
ClickHouse MergeTree引擎表支持分区,索引,修改,并发查询数据,当查询MergeTree表数据时,首先向primary.idx文件中获取对应的索引,根据索引找到【列.mrk2】文件获取对应的数据块偏移量,然后再根据偏移量从【列.bin】文件中读取块数据。
2. MergeTree引擎表设置分区
给表设置分区可以在查询过程中跳过不需要的数据目录,提升查询效率。在ClickHouse中并不是所有的表都支持分区,目前只有MergeTree家族系列的表引擎才支持数据分区。
通过前面的学习,我们知道向MergeTree分区表中每次插入数据时,每次都会生成对应的分区片段,不会立刻合并相同分区的数据,需要等待15分钟左右,ClickHouse会自动合并相同的分区片段,并删除合并之前的源数据片段,当然这里我们也可以手动执行OPTIMIZE 语句手动触发合并分区表中的分区片段。通过下面案例来学习分区表中分区片段合并的规则。
#创建表 login_info ,设置MergeTree引擎
node1 :) create table login_info(
:-] id UInt8,
:-] name String,
:-] log_time Date
:-] ) engine = MergeTree()
:-] order by (id)
:-] partition by toYYYYMM(log_time);
#向表 login_info中插入以下数据
node1 :) insert into login_info values (1,'zs','2021-06-01'),
:-] (2,'ls','2021-06-01'),
:-] (3,'ww','2021-07-01'),
:-] (4,'ml','2021-07-01');
#查看表 login_info 中数据
node1 :) select * from login_info;
SELECT *
FROM login_info
┌─id─┬─name─┬───log_time─┐
│ 3 │ ww │ 2021-07-01 │
│ 4 │ ml │ 2021-07-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 1 │ zs │ 2021-06-01 │
│ 2 │ ls │ 2021-06-01 │
└────┴──────┴────────────┘
4 rows in set. Elapsed: 0.008 sec.经过以上步骤,在clickhouse节点上查看表login_info数据目录/var/lib/clickhouse/data/newdb/login_info,如下图示:

继续向表 login_info中插入以下数据:
#继续向表login_info中插入以下数据
node1 :) insert into login_info values (5,'zs1','2021-06-01'),
:-] (6,'ls1','2021-06-01'),
:-] (7,'ww1','2021-07-01'),
:-] (8,'ml1','2021-07-01');
#查看表 login_info数据
node1 :) select * from login_info;
SELECT *
FROM login_info
┌─id─┬─name─┬───log_time─┐
│ 3 │ ww │ 2021-07-01 │
│ 4 │ ml │ 2021-07-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 1 │ zs │ 2021-06-01 │
│ 2 │ ls │ 2021-06-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 5 │ zs1 │ 2021-06-01 │
│ 6 │ ls1 │ 2021-06-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 7 │ ww1 │ 2021-07-01 │
│ 8 │ ml1 │ 2021-07-01 │
└────┴──────┴────────────┘
8 rows in set. Elapsed: 0.006 sec.通过插入数据之后再次查询发现,相同分区的数据展示在不同的数据块中。在clickhouse节点上再次查看表login_info数据目录/var/lib/clickhouse/data/newdb/login_info,如下图示:

“202106_3_3_0”为例,“202006”为分区,“3”代表数据块的最小编号,“3”代表数据块的最大编号,“0”代表合并的第几次(合并树中块的级别)。
手动执行OPTIMIZE 语句手动触发合并分区表中的分区片段:
#执行如下命令,手动合并分区片段
node1 :) optimize table login_info partition '202106' ;
node1 :) optimize table login_info partition '202107' ;
#查看表 login_info中的数据:
node1 :) select * from login_info;
SELECT *
FROM login_info
┌─id─┬─name─┬───log_time─┐
│ 3 │ ww │ 2021-07-01 │
│ 4 │ ml │ 2021-07-01 │
│ 7 │ ww1 │ 2021-07-01 │
│ 8 │ ml1 │ 2021-07-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 1 │ zs │ 2021-06-01 │
│ 2 │ ls │ 2021-06-01 │
│ 5 │ zs1 │ 2021-06-01 │
│ 6 │ ls1 │ 2021-06-01 │
└────┴──────┴────────────┘
8 rows in set. Elapsed: 0.006 sec.通过合并分区片段之后,在clickhouse节点上再次查看表login_info数据目录/var/lib/clickhouse/data/newdb/login_info,如下图示:
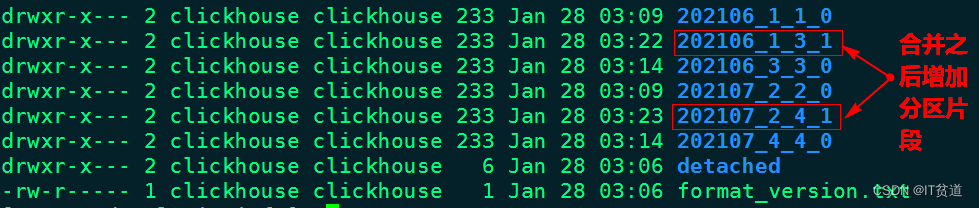
经过一段时间再次查询当前目录数据,只剩余合并最后的两个分区片段,如下图所示:

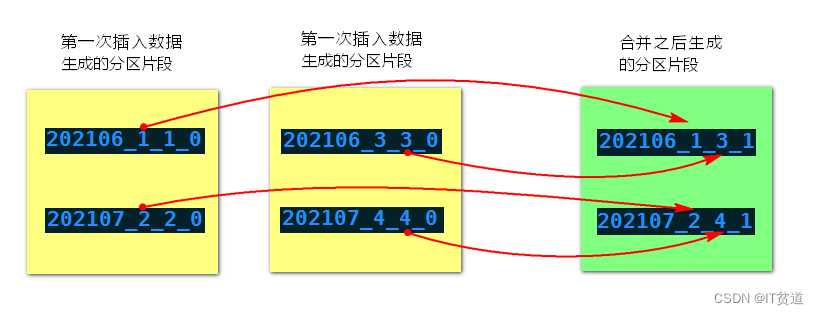
MergeTree分区表合并分区规则如下:获取相同分区片段中最小编号和最大编号,组合成新的分区片段,同时修改合并的次数(合并树中块的级别),合并示意图如下:
继续向表login_info中插入数据:
#继续向表login_info中插入以下数据
node1 :) insert into login_info values (9,'zs1','2021-06-01'),
:-] (10,'ls1','2021-06-01'),
:-] (11,'ww1','2021-07-01'),
:-] (12,'ml1','2021-07-01');
#查看表 login_info数据
node1 :) select * from login_info;
SELECT *
FROM login_info
┌─id─┬─name─┬───log_time─┐
│ 3 │ ww │ 2021-07-01 │
│ 4 │ ml │ 2021-07-01 │
│ 7 │ ww1 │ 2021-07-01 │
│ 8 │ ml1 │ 2021-07-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 11 │ ww1 │ 2021-07-01 │
│ 12 │ ml1 │ 2021-07-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 1 │ zs │ 2021-06-01 │
│ 2 │ ls │ 2021-06-01 │
│ 5 │ zs1 │ 2021-06-01 │
│ 6 │ ls1 │ 2021-06-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 9 │ zs1 │ 2021-06-01 │
│ 10 │ ls1 │ 2021-06-01 │
└────┴──────┴────────────┘
12 rows in set. Elapsed: 0.006 sec在clickhouse节点上再次查看表login_info数据目录/var/lib/clickhouse/data/newdb/login_info,如下图示:

再次执行合并分区命令,合并表login_info分区片段:
#执行如下命令,手动合并分区片段
node1 :) optimize table login_info partition '202106' ;
node1 :) optimize table login_info partition '202107' ;
#查看表 login_info中的数据:
node1 :) select * from login_info;
SELECT *
FROM login_info
┌─id─┬─name─┬───log_time─┐
│ 3 │ ww │ 2021-07-01 │
│ 4 │ ml │ 2021-07-01 │
│ 7 │ ww1 │ 2021-07-01 │
│ 8 │ ml1 │ 2021-07-01 │
│ 11 │ ww1 │ 2021-07-01 │
│ 12 │ ml1 │ 2021-07-01 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───log_time─┐
│ 1 │ zs │ 2021-06-01 │
│ 2 │ ls │ 2021-06-01 │
│ 5 │ zs1 │ 2021-06-01 │
│ 6 │ ls1 │ 2021-06-01 │
│ 9 │ zs1 │ 2021-06-01 │
│ 10 │ ls1 │ 2021-06-01 │
└────┴──────┴────────────┘
12 rows in set. Elapsed: 0.008 sec.通过合并分区片段之后,在clickhouse节点上再次查看表login_info数据目录/var/lib/clickhouse/data/newdb/login_info,如下图示:
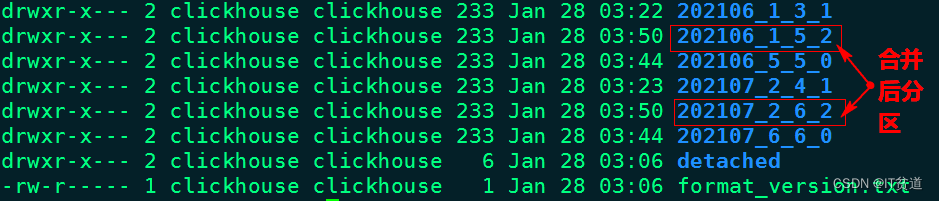
经过一段时间再次查询当前目录数据,只剩余合并最后的两个分区片段,如下图所示:

此外,表设置分区字段时,分区健不仅可以指定成时间列,也可以是表中任意列或者列的表达式。下面案例使用表中的地区列当做分区:
#创建表 emp_info ,使用MergeTree分区
node1 :) create table emp_info (
:-] id UInt8,
:-] name String,
:-] age UInt8,
:-] loc String,
:-] salary Decimal32(2)
:-] )engine = MergeTree()
:-] order by id
:-] partition by loc;
# 向表中插入以下数据
node1 :) insert into emp_info values (1,'张三',18,'上海',10.11),
:-] (2,'李四',19,'北京',100.123),
:-] (3,'王五',20,'上海',200.2),
:-] (4,'马六',21,'上海',300.456),
:-] (5,'田七',22,'北京',400.78),
:-] ;
#查看表中的数据,可以观察到所有数据都是按照地区合并在一起。
node1 :) select * from emp_info;
SELECT *
FROM emp_info
┌─id─┬─name─┬─age─┬─loc──┬─salary─┐
│ 2 │ 李四 │ 19 │ 北京 │ 100.12 │
│ 5 │ 田七 │ 22 │ 北京 │ 400.78 │
└───┴────┴────┴─────┴──────┘
┌─id─┬─name─┬─age─┬─loc──┬─salary─┐
│ 1 │ 张三 │ 18 │ 上海 │ 10.11 │
│ 3 │ 王五 │ 20 │ 上海 │ 200.20 │
│ 4 │ 马六 │ 21 │ 上海 │ 300.45 │
└───┴────┴────┴─────┴──────┘
5 rows in set. Elapsed: 0.006 sec.注意:如果按照字符串字段来进行分区,在底层/var/lib/clickhouse/data/newdb/目录下对应的表emp_info中的分区片段名称是使用字符串的hashcode+编码的形式来命名。
👨💻如需博文中的资料请私信博主。







![QTableWidget对单元格(QWidget/QTableWidgetItem)的内存管理[clearContents()]](https://img-blog.csdnimg.cn/2e42c9d235a6424f946dd147a7963bd8.png)
