目录
匿名页的生成
匿名页生成时的状态
do_anonymous_page缺页中断源码
从匿名页加入Inactive lru引出 一个非常重要内核patch
匿名页何时回收
本文以Linux5.9源码讲述
匿名页的生成
- 用户空间malloc/mmap(非映射文件时)来分配内存,在内核空间发生缺页中断时,do_anonymous_page会产生匿名页,这是最主要的生成场景。
- 写时复制。缺页中断出现写保护错误,新分配的页面是匿名页。主要是do_wp_page和do_cow_page。
- do_swap_page,从swap分区读回数据会分配匿名页
- 迁移页面。
匿名页生成时的状态
migrate type: moveable
page->_refcount: 2
page->_mapcount: 0
page->mapping: 指向vma中的anon_vma数据结构,跟rmap反向映射有关
page->index: 虚拟地址是vma中第几个页面,这个offset即为index
Lru :inactive aono lru
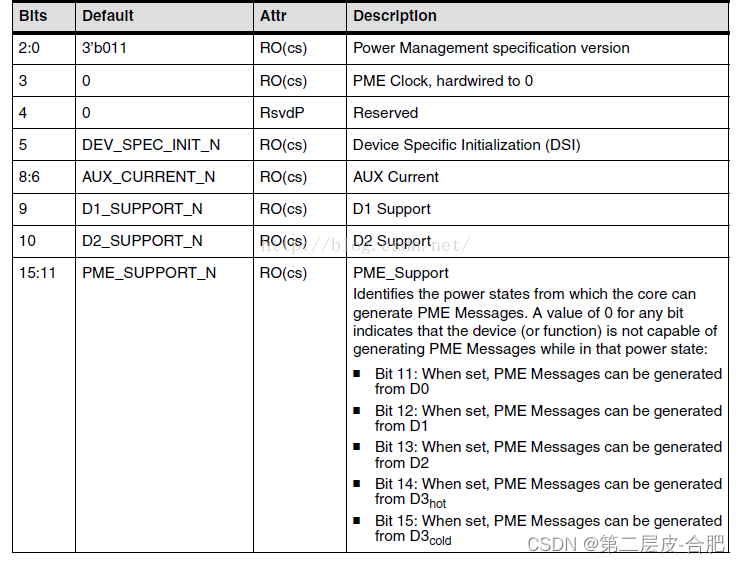
flags: [PG_Swapbacked | PG_lru]。页面支持swap,android上比如时zram压缩,注意没有设置PG_referenced.- PG_swapbacked:匿名页do_anonymous_page调用page_add_new_anon_rmap时设置了该flag,代表可以交换到swap分区(比如android的zram)。内核有个函数叫PageSwapBacked,满足条件是两种页面:一是此处的anon page,另外一种是shmem page。
- moveable可以理解,因为匿名页面也会缺页中断do_anonymous_page的时候会填充页表,page mirgrate迁移的时候只要修改页表映射即可。参见 do_anonymous_page中的alloc_zeroed_user_highpage_movable。
- _refcount 等于2说明被内核中引用了两次。
- 第一次引用:alloc_pages从buddy中申请出来的page默认_refcount = 1。这个很好理解,被分配就相当于”出嫁“有了约束,相当于被引用(约束)了一次,释放回buddy之后意味了自由和无约束,那么_refcount = 0;
- 第二次引用:加入inactive lru。匿名页产生的时候会加入inactive anon lru中,参见do_anonymous_page代码中的lru_cache_add_inactive_or_unevictable
- _mapcount: 0,说明匿名页生成时,只有一个进程页表映射了该匿名页。设置该字段参见下面的page_add_new_anon_rmap函数。
- mapping:指向anon_vma结构
- 对于匿名页来讲,其mapping指向匿名映射的anon_vam数据结构(文件页对一个address_space)。
- 既然mapping字段对于不同类型的文件指向不同对象,内核可以利用该字段判定page是否是匿名页,即PageAnon函数:mapping指针的最低位不是0,那么就是匿名页。
-
#define PAGE_MAPPING_ANON 0x1 #define PAGE_MAPPING_MOVABLE 0x2 #define PAGE_MAPPING_KSM (PAGE_MAPPING_ANON | PAGE_MAPPING_MOVABLE) #define PAGE_MAPPING_FLAGS (PAGE_MAPPING_ANON | PAGE_MAPPING_MOVABLE) static __always_inline int PageAnon(struct page *page) { page = compound_head(page); return ((unsigned long)page->mapping & PAGE_MAPPING_ANON) != 0; } - mapping字段赋值:参见do_anonymous_page的page_add_new_anon_rmap函数
-
/** * page_add_new_anon_rmap - add pte mapping to a new anonymous page * @page: the page to add the mapping to * @vma: the vm area in which the mapping is added * @address: the user virtual address mapped * @compound: charge the page as compound or small page * * Same as page_add_anon_rmap but must only be called on *new* pages. * This means the inc-and-test can be bypassed. * Page does not have to be locked. */ void page_add_new_anon_rmap(struct page *page, struct vm_area_struct *vma, unsigned long address, bool compound) { int nr = compound ? hpage_nr_pages(page) : 1; VM_BUG_ON_VMA(address < vma->vm_start || address >= vma->vm_end, vma); __SetPageSwapBacked(page); if (compound) { VM_BUG_ON_PAGE(!PageTransHuge(page), page); /* increment count (starts at -1) */ atomic_set(compound_mapcount_ptr(page), 0); __inc_node_page_state(page, NR_ANON_THPS); } else { /* Anon THP always mapped first with PMD */ VM_BUG_ON_PAGE(PageTransCompound(page), page); /* increment count (starts at -1) */ atomic_set(&page->_mapcount, 0); } __mod_node_page_state(page_pgdat(page), NR_ANON_MAPPED, nr); __page_set_anon_rmap(page, vma, address, 1); } /** * __page_set_anon_rmap - set up new anonymous rmap * @page: Page to add to rmap * @vma: VM area to add page to. * @address: User virtual address of the mapping * @exclusive: the page is exclusively owned by the current process */ static void __page_set_anon_rmap(struct page *page, struct vm_area_struct *vma, unsigned long address, int exclusive) { struct anon_vma *anon_vma = vma->anon_vma; BUG_ON(!anon_vma); if (PageAnon(page)) return; /* * If the page isn't exclusively mapped into this vma, * we must use the _oldest_ possible anon_vma for the * page mapping! */ if (!exclusive) anon_vma = anon_vma->root; anon_vma = (void *) anon_vma + PAGE_MAPPING_ANON; page->mapping = (struct address_space *) anon_vma; page->index = linear_page_index(vma, address); }
do_anonymous_page缺页中断源码
/*
* We enter with non-exclusive mmap_lock (to exclude vma changes,
* but allow concurrent faults), and pte mapped but not yet locked.
* We return with mmap_lock still held, but pte unmapped and unlocked.
*/
static vm_fault_t do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page;
vm_fault_t ret = 0;
pte_t entry;
...
//从该函数名字就知道最终调用的伙伴系统申请了zero且moveable的页面
//从伙伴系统中刚分配的页面:_refcount = 1,_mapcount = -1;
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
if (!page)
goto oom;
...
/*
* The memory barrier inside __SetPageUptodate makes sure that
* preceding stores to the page contents become visible before
* the set_pte_at() write.
*/
__SetPageUptodate(page);
...
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, vmf->address, false);
lru_cache_add_inactive_or_unevictable(page, vma);
...
}从匿名页加入Inactive lru引出 一个非常重要内核patch
上面有个很重要的点:anon page刚产生时候在5.9源码版本上加入的是Inactive anon lru列表中。而在更早的内核版本中,比如4.14的时候anon page还是加入active anon lru,这个点要特别注意,而内核改动这个逻辑主要是由于如下patch引入:
[PATCH v7 0/6] workingset protection/detection on the anonymous LRU list
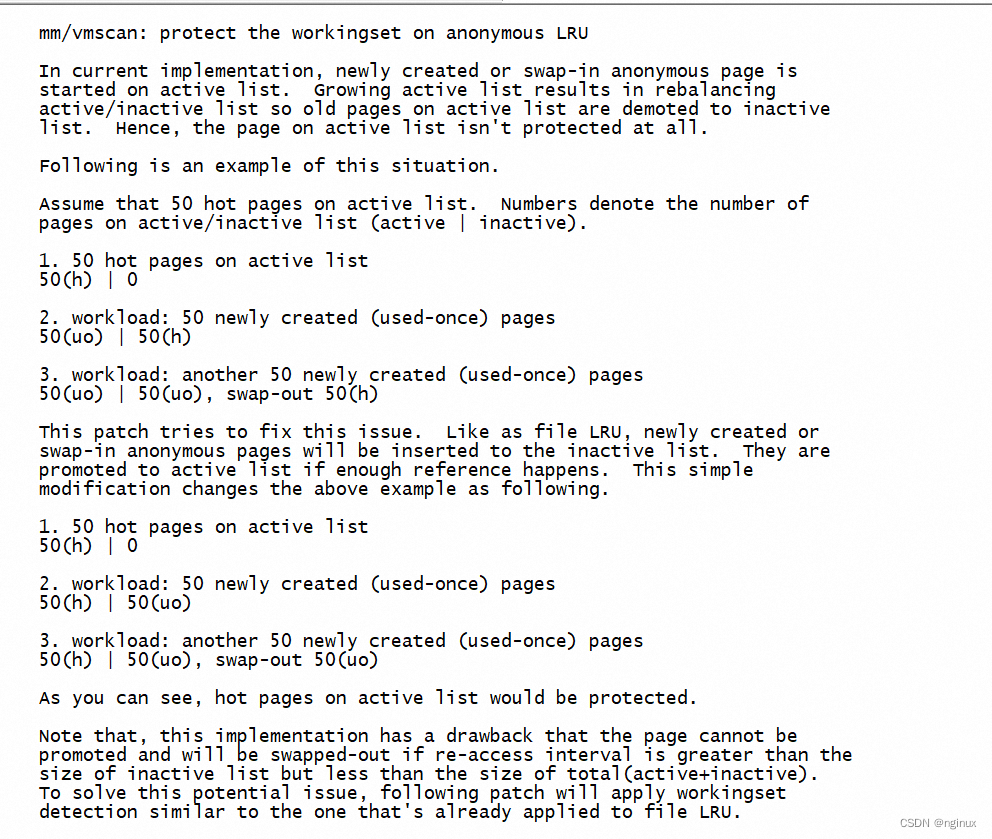
说明:内核之所以如此修改主要是因为系统可能产生大量的仅used-once的anon page,如果将这些匿名页加入active page会导致active过度增长,进而active : inactive lru链表的比例失调,我们知道页面老化shrink的时候如果比例失调会触发shrink_active_list,那么这些used-once anon page就会将active lru中hot的page给老化到inactive anon lru链表中,这个patch将anon page创建后加入了inactive anon lru链表中。
不过万事有利也有弊,这个patch也说明了一个缺点:anon page加入了inactive anon lru,就是anon page更容易被换出释放掉。比如anon re-access interval介于inactive list但是小于active + inactive list的时候,就被换出了,而内核workingset的refault-distance算法正是为了解决这个问题,起初内核只对file-back page使用该算法,即算法只保护了file-back page,而在5.9内核中anon page也被该算法保护,所以也就可以将刚生成的anon page加入到inactive anon lru链表了。
匿名页何时回收
1. used-once
如果匿名页只使用一次,且如上面所述,anon page处于inactive anon lru之中,会经历两次老化才能释放页面,这也是"两次机会法"的体现,也就是说两次机会在访问和释放page的时候都会给page两次机会,不能稍有风吹草动就把page给释放,即两次shrink_page_list才能释放used-once anon page:
第一次shrink: 清理掉referenced_ptes和PG_referenced状态,page_check_references返回PAGEREF_KEEP
第二次shrink: 第一次shrink清理了标志状态,第二次shrink可直接回收了。
2.多次访问
第一种情况:访问间隔很短 - 迁移入active anon lru
当前anon page处于inactive anon lru链表中,推动其在inactive和inactive切换的驱动力也是页面老化(这个点非常重要):如果内存一直充足而不触发页面回收老化,那么anon page将一直保持在inactive 列表中,只有内存紧张触发page reclaim的时候才开始决定page何去何从:回收或者保持在inactive或者迁移到active列表中。
基于上面描述,由于页面re-access,那么pte访问重新置位,那么page_check_referenced返回PAGEREF_ACTIVATE,将该anon page迁移到active anon lru链表中。
static enum page_references page_check_references(struct page *page,
struct scan_control *sc)
{
int referenced_ptes, referenced_page;
unsigned long vm_flags;
referenced_ptes = page_referenced(page, 1, sc->target_mem_cgroup,
&vm_flags);
referenced_page = TestClearPageReferenced(page);
if (referenced_ptes) {
/*
* All mapped pages start out with page table
* references from the instantiating fault, so we need
* to look twice if a mapped file page is used more
* than once.
*
* Mark it and spare it for another trip around the
* inactive list. Another page table reference will
* lead to its activation.
*
* Note: the mark is set for activated pages as well
* so that recently deactivated but used pages are
* quickly recovered.
*/
SetPageReferenced(page);
//re-acess page触发该逻辑
if (referenced_page || referenced_ptes > 1)
return PAGEREF_ACTIVATE;
/*
* Activate file-backed executable pages after first usage.
*/
if ((vm_flags & VM_EXEC) && !PageSwapBacked(page))
return PAGEREF_ACTIVATE;
return PAGEREF_KEEP;
}
/* Reclaim if clean, defer dirty pages to writeback */
if (referenced_page && !PageSwapBacked(page))
return PAGEREF_RECLAIM_CLEAN;
return PAGEREF_RECLAIM;
}第二种情况:访问间隔很长 - refault distance算法决定page到底迁入inactive还是active
如果访问间隔较长,两次老化shrink后就会将该anon page回收(anon page对于android上就是放入swap分区,即zram压缩中)。被回收之后再次访问时缺页称为refault,refault之后该内核会判定该anon page再回收释放时,到re-access refault时候,内核一共老化了多少页面,假设是num:
- num < inactive anon lru 那么将anon page加入inactive lru.
- inactive anon list < num < inactive anon lru + active anon lru,那么将anon page迁移到active anon lru中,这样可以尽量避免anon page被再次回收释放。