文章目录
- 1 前言
- 2 创建第一个应用 📝🚀
- 3 获取数据 📦🔍
- 4 函数缓存🚀🔍📊
- 5 赏析原始数据 ✨🎉
- 6 绘制直方图 📊✨
- 7 所有乘车点的地图 🌍🚖
- 8 完整代码
1 前言
📣 重要通知!在我之前的博客中,曾经介绍过Streamlit的安装方法和初步应用。如果你还没有参阅过,请先阅读这篇文章,它为我们接下来的探索铺垫了基础。🔍😊
(一) 初识Streamlit——安装以及初步应用 在这篇文章中,我向大家简要介绍了Streamlit的安装过程,并分享了一个简单应用的示例供大家参考。让我们回顾一下这篇文章:(一)初识streamlit——安装以及初步应用🚀🔗
感谢大家一直以来的支持与鼓励!接下来,我们将继续探索如何使用Streamlit创建第一个应用。请随我一同展开这个令人兴奋的旅程!💡✨
本文涉及到每章节的详细内容都会在之后的博文中讲解,这里是为了向读者展示利用streamlit搭建数据看板的完整流程
2 创建第一个应用 📝🚀
在本部分中,我们将一起探索如何使用Streamlit来创建第一个应用程序。Streamlit不仅仅是创建数据应用的一种方式,它还为我们提供了一个活跃的社区平台,让我们可以分享应用和创意,并相互帮助改进工作。赶快加入我们的社区论坛吧,我们非常乐于听取你的问题和想法,并帮助你解决困扰 —— 今天就开始吧!
首先,我们需要创建一个新的Python脚本,我们可以将其命名为 uber_pickups.py。
打开你最喜欢的集成开发环境(IDE)或文本编辑器,然后添加以下几行代码:
import streamlit as st
import pandas as pd
import numpy as np
每个优秀的应用程序都需要一个标题,因此让我们来添加一个:
st.title('Uber在纽约市的搭车数据')
现在,我们可以在命令行中运行Streamlit:
streamlit run uber_pickups.py
运行Streamlit应用与运行其他Python脚本没有任何区别。每当你需要查看应用程序时,只需使用这个命令即可。应用程序通常会在浏览器中自动开启一个新的选项卡。

3 获取数据 📦🔍
现在我们已经创建了一个应用程序,下一步需要做的是获取纽约市Uber的搭车和下车数据。
让我们首先编写一个功能来加载数据。我们将编写一个名为load_data的函数,该函数使用pandas库的read_csv函数从指定的URL下载数据,并将其存储在一个名为data的数据帧中。我们还将所有列名称转换为小写,并将日期/时间列转换为pandas的日期时间类型。
# 设置日期/时间列的名称
DATE_COLUMN = 'date/time'
# 定义数据集的URL地址
DATA_URL = ('https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
# 定义加载数据的函数
def load_data(nrows):
# 从指定URL下载数据,并将其加载到数据帧中
data = pd.read_csv(DATA_URL, nrows=nrows)
# 将列名称转换为小写
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True)
# 将日期/时间列转换为日期时间类型
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
# 返回加载的数据帧
return data
在上述代码中,我们使用DATA_URL变量来指定数据集的URL地址。然后,我们调用read_csv函数,并传入nrows参数来加载指定数量的行数据。
接下来,我们在应用程序中使用这个函数来加载实际的数据。我们创建一个文本元素data_load_state,用于在应用程序中显示加载数据的状态信息。然后,我们调用load_data函数,并传入10000作为要加载的行数。一旦数据加载完成,我们使用text方法来更新data_load_state文本元素的内容,提示数据加载已完成。
# 创建一个文本元素,告诉读者数据正在加载中。
data_load_state = st.text('正在加载数据...')
# 加载10,000行数据到数据帧中。
data = load_data(10000)
# 通知读者数据已成功加载。
data_load_state.text('加载数据...完成!')
最后,我们通过运行streamlit run命令来启动应用程序,并选择"Always Rerun"选项。这样,当对应用程序进行任何更改并保存后,它都会自动重新加载,并显示数据加载的状态信息。

4 函数缓存🚀🔍📊
缓存是一种性能优化技术,可以将函数计算的结果保存在内存中,以便在下次调用时快速获取。而Streamlit的缓存功能非常简单,只需要使用@st.cache装饰器即可激活。
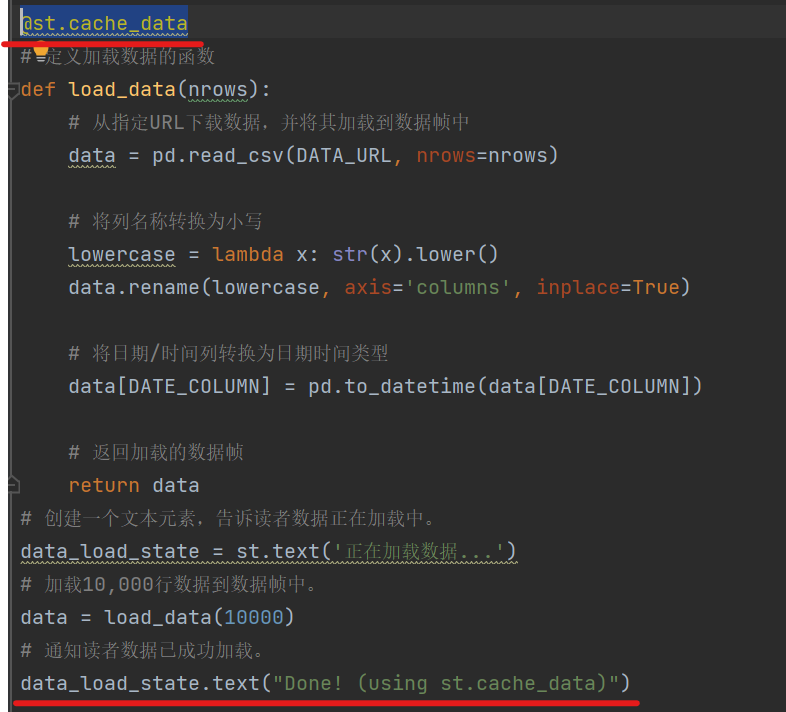
使用@st.cache装饰器标记一个函数后,Streamlit会自动管理函数的缓存。在函数调用时,Streamlit会检查两个方面:
(1)使用的输入参数:如果提供的参数值与之前的一样,Streamlit会直接从缓存中获取结果,而不会重新计算。
(2)函数内部的代码:如果代码没有发生变化,Streamlit也会从缓存中获取结果,从而避免重复计算。
使用缓存功能有很多好处。特别是对于加载大型数据集或进行耗时计算的情况下,缓存可以显著提高应用程序的性能和响应速度。通过避免重复计算,我们可以使应用程序更加高效。
要使用缓存功能,只需在函数定义之前使用@st.cache装饰器标记函数即可。这一行简单的代码就可以为你的应用程序带来神奇的缓存效果。

5 赏析原始数据 ✨🎉
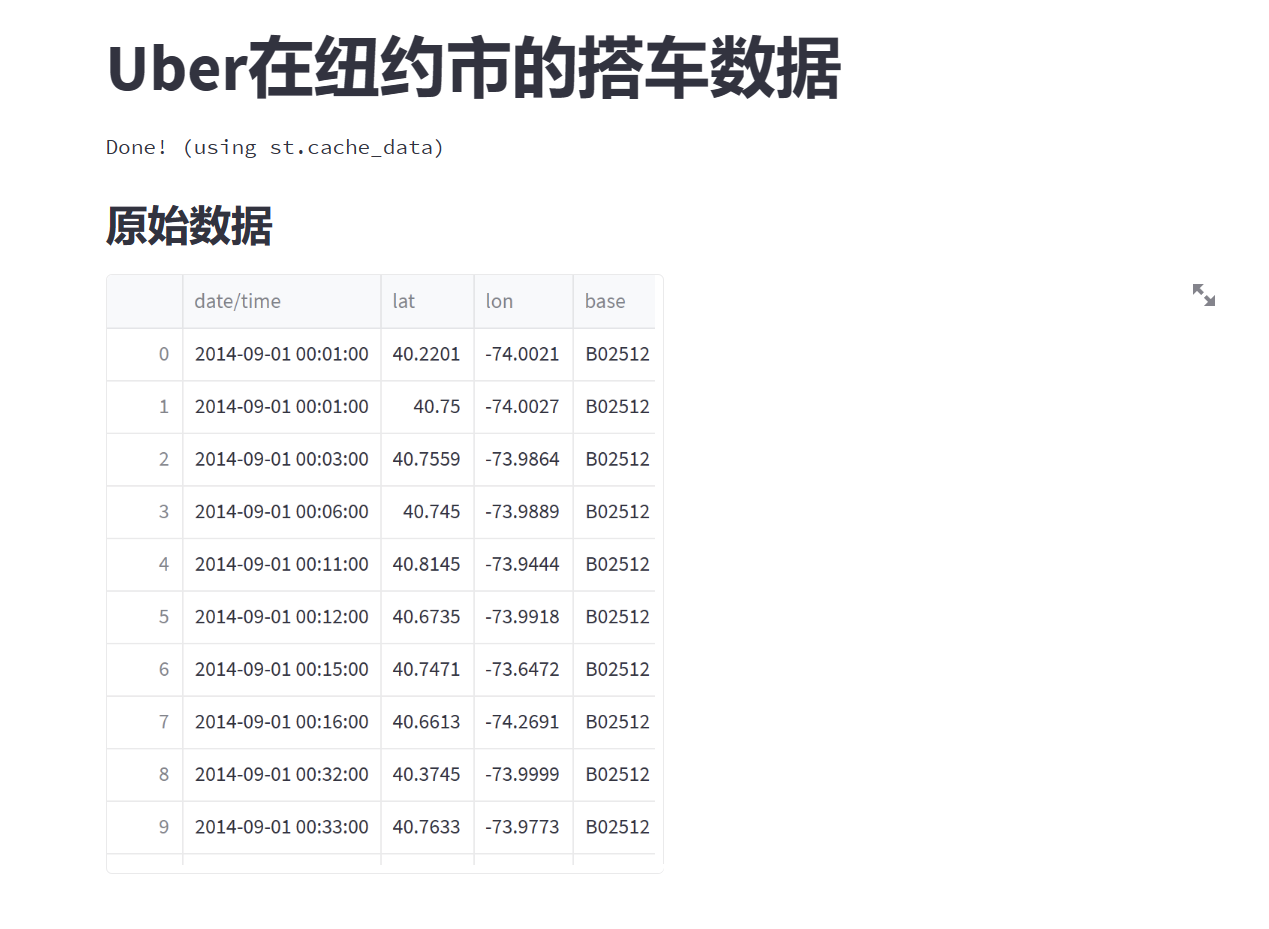
在开始处理数据之前,咱们得先瞄一眼要处理的原始数据,这是个非常不错的主意哦!那么咱们来为应用程序添加一个炫酷的副标题,并将原始数据打印出来:
import streamlit as st
# 添加子标题
st.subheader('原始数据')
# 打印原始数据
st.write(data)
在上面的代码中,我们使用st.subheader()函数添加了一个子标题,以强调原始数据的重要性。然后,使用st.write()函数将数据打印出来。有趣的是,st.write()函数可以渲染几乎任何你传递给它的内容。
st.write()函数会根据数据类型的不同尝试展示最合适的方式。如果它没有按照你的预期工作,你可以尝试使用专门的命令,如st.dataframe()来显示数据框。完整的命令列表可以查看 API 参考文档。
通过观察原始数据,你可以对数据的结构和特征有一个初步的了解。这对于理解数据和选择适当的分析方法非常重要。
6 绘制直方图 📊✨
现在,我们将进一步分析数据集,通过绘制直方图来了解Uber在纽约市最繁忙的小时段。
首先,在原始数据部分下面添加一个子标题:
st.subheader('每小时乘车次数')
接下来,使用NumPy生成一个直方图,按小时统计乘车时间:
# 使用NumPy生成一个直方图,按小时统计乘车时间
hist_values = np.histogram(
data[DATE_COLUMN].dt.hour, bins=24, range=(0,24))[0]
这段代码使用NumPy库生成了直方图的值,将乘车时间按小时进行分类并统计出现的次数。
现在,让我们使用Streamlit的st.bar_chart()方法来绘制直方图:
# 通过Streamlit的st.bar_chart()方法绘制直方图
st.bar_chart(hist_values)
保存你的脚本。这个直方图应该会立即显示在你的应用程序中。经过快速查看,我们可以看到最繁忙的时间是下午17点(5点)。
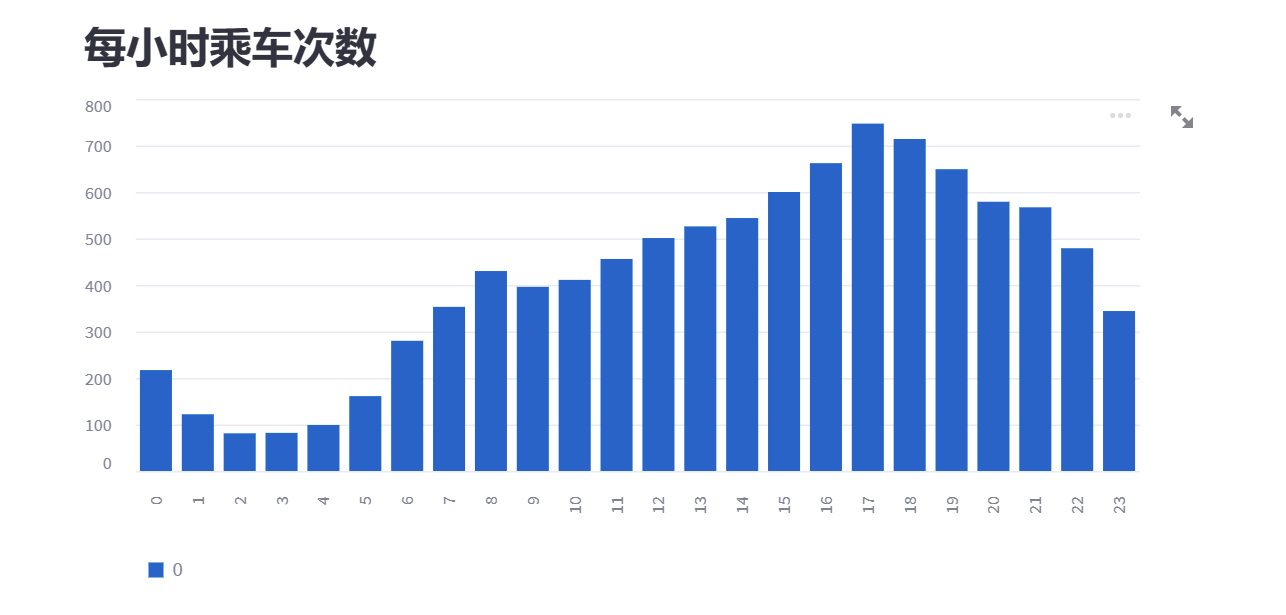
7 所有乘车点的地图 🌍🚖
当我们使用直方图分析Uber数据集时,我们可以确定乘车最繁忙的时间段,但是如果我们想弄清楚城市中的乘车集中区域呢?虽然我们可以使用条形图来展示这些数据,但是这很难理解,除非你对城市的纬度和经度坐标非常熟悉。为了展示乘车集中情况,让我们使用Streamlit的st.map()函数将数据叠加在纽约市的地图上。
首先,在该部分下方添加一个子标题:
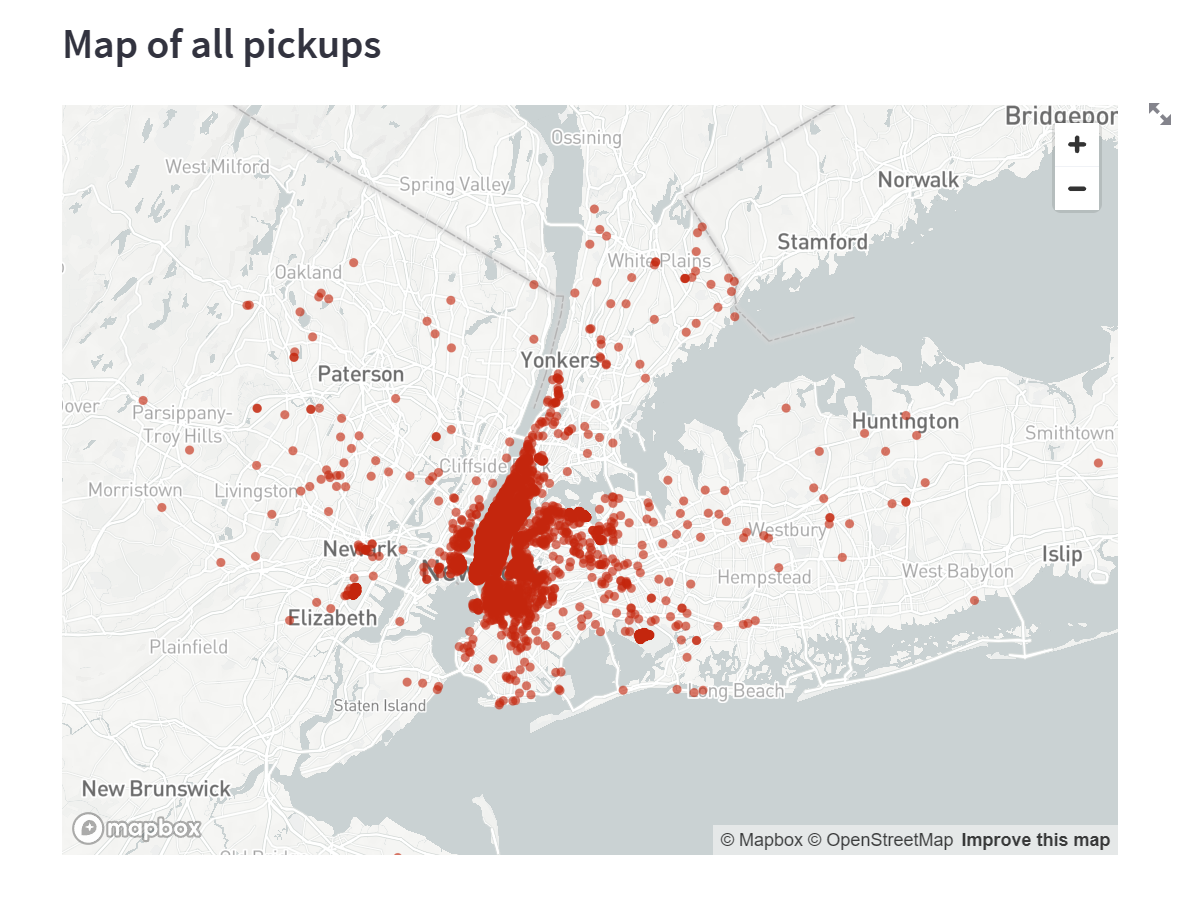
st.subheader('Map of all pickups')
接下来,使用st.map()函数来绘制地图:
st.map(data)
保存你的脚本。这个地图是完全交互式的。尝试使用平移和缩放功能来探索一下吧!
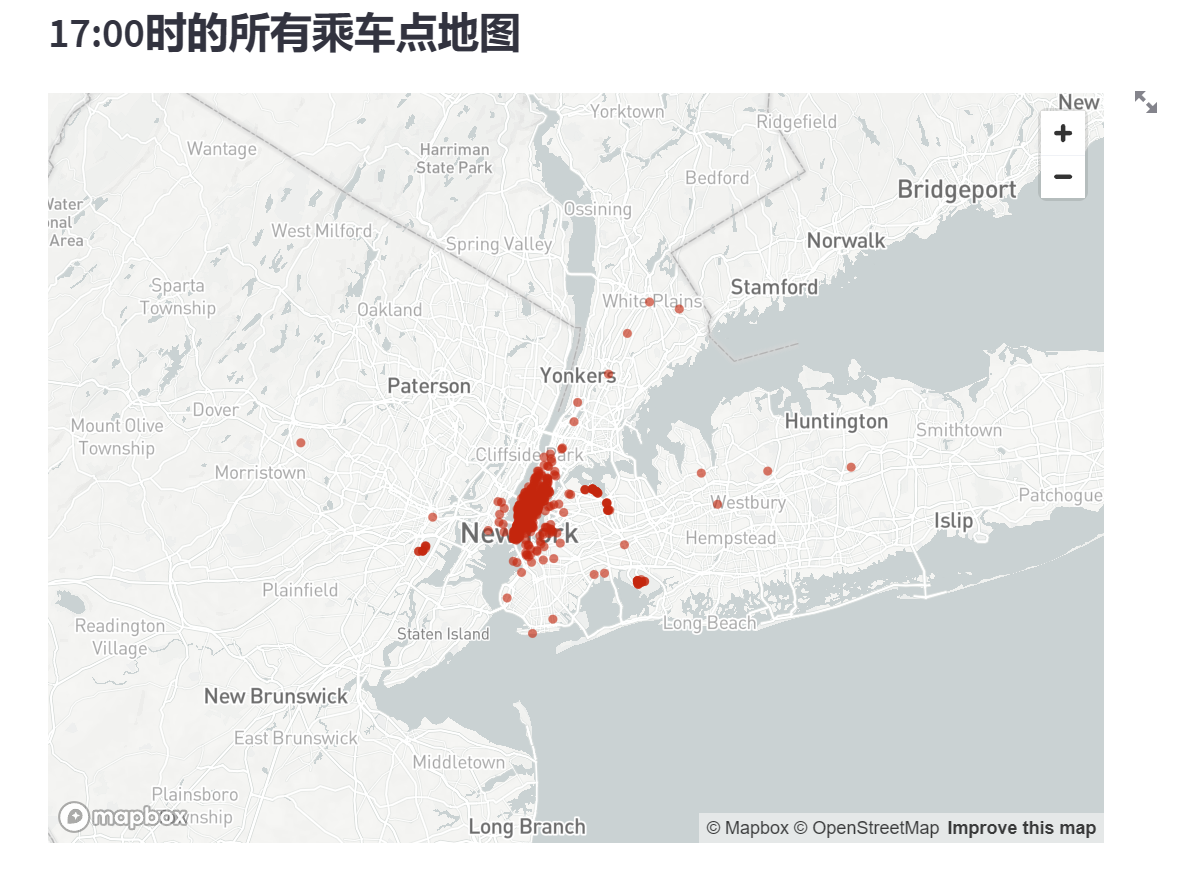
在绘制完直方图之后,你确定了最繁忙的乘车时间是下午17:00。让我们重新绘制地图,展示在17:00乘车点的集中情况。
在绘制完直方图之后,确定了最繁忙的乘车时间是下午17:00。让我们重新绘制地图,展示在17:00乘车点的集中情况。
hour_to_filter = 17
filtered_data = data[data[DATE_COLUMN].dt.hour == hour_to_filter]
st.subheader(f'{hour_to_filter}:00时的所有乘车点地图')
st.map(filtered_data)
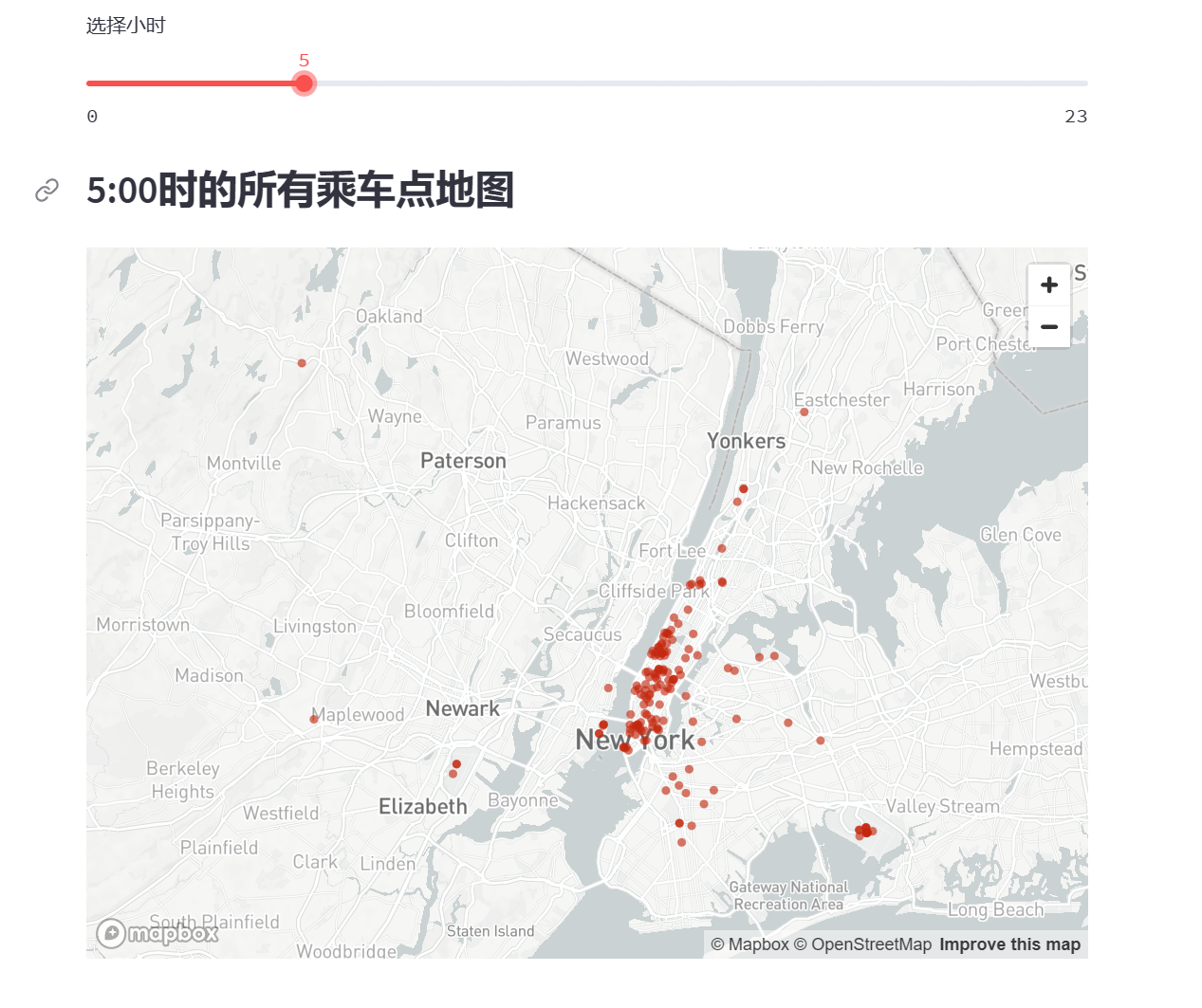
当我们绘制地图时,用于过滤结果的时间是硬编码在代码中的,但是如果我们希望读者能够实时动态地过滤数据怎么办呢?使用Streamlit的小部件,你可以实现这个功能。让我们在应用程序中添加一个滑块,使用st.slider()方法。
首先,找到 hour_to_filter 的代码片段,并将其替换为:
hour_to_filter = st.slider('选择小时', 0, 23, 17) # min: 0h, max: 23h, 默认为 17h
这段代码创建了一个滑块,它允许用户通过拖动滑块来选择小时数。滑块的范围是从0到23(表示0点到23点),默认值是17点。
保存你的代码,现在你可以使用滑块实时观察地图的更新了。
滑块只是动态更改应用程序组成部分的一种方式。让我们使用st.checkbox()函数向你的应用程序添加一个复选框。我们将使用这个复选框来在应用程序顶部显示/隐藏原始数据表格。
首先,找到下面的代码段:
st.subheader('Raw data')
st.write(data)
将其替换为以下代码:
if st.checkbox('显示原始数据'):
st.subheader('原始数据')
st.write(data)
这段代码创建了一个复选框,并且在复选框被选中时显示原始数据表格。如果复选框未被选中,则不显示原始数据表格。
保存你的脚本,现在你可以使用复选框来显示或隐藏原始数据表格了。
8 完整代码
import streamlit as st
import pandas as pd
import numpy as np
st.title('Uber在纽约市的搭车数据')
# 设置日期/时间列的名称
DATE_COLUMN = 'date/time'
# 定义数据集的URL地址
DATA_URL = ('https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
@st.cache_data
# 定义加载数据的函数
def load_data(nrows):
# 从指定URL下载数据,并将其加载到数据帧中
data = pd.read_csv(DATA_URL, nrows=nrows)
# 将列名称转换为小写
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True)
# 将日期/时间列转换为日期时间类型
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
# 返回加载的数据帧
return data
# 创建一个文本元素,告诉读者数据正在加载中。
data_load_state = st.text('正在加载数据...')
# 加载10,000行数据到数据帧中。
data = load_data(10000)
# 通知读者数据已成功加载。
data_load_state.text("Done! (using st.cache_data)")
if st.checkbox('显示原始数据'):
st.subheader('原始数据')
st.write(data)
st.subheader('每小时乘车次数')
# 使用NumPy生成一个直方图,按小时统计乘车时间
hist_values = np.histogram(
data[DATE_COLUMN].dt.hour, bins=24, range=(0,24))[0]
# 通过Streamlit的st.bar_chart()方法绘制直方图
st.bar_chart(hist_values)
st.subheader('Map of all pickups')
st.map(data)
hour_to_filter = st.slider('选择小时', 0, 23, 17) # min: 0h, max: 23h, 默认为 17h
filtered_data = data[data[DATE_COLUMN].dt.hour == hour_to_filter]
st.subheader(f'{hour_to_filter}:00时的所有乘车点地图')
st.map(filtered_data)
至此,创建streamlit的第一个应用的内容介绍完成,你还可以将项目上传至streamlit cloud,具体内容我会在后续的博文中讲解,还请大家三连呀~