🍁 博客主页:江池俊的博客
💫收录专栏:C语言——探索高效编程的基石
💻 其他专栏:数据结构探索
💡代码仓库:江池俊的代码仓库
🎪 社区:GeekHub🍁 如果觉得博主的文章还不错的话,请点赞👍收藏🌟 三连支持一下博主💞
文章目录
- 🌴数据类型介绍
- 📌类型的基本归类:
- 🌴整形在内存中的存储
- 📌原码、反码、补码
- 📌大小端介绍
- 1. 什么是大端小端:
- 2.为什么有大端和小端:
- 🌴练习
- 📌1.百度2015年系统工程师笔试题:
- 📌2.练习2
- 📌3.练习3
- 📌4.练习4
- 📌5.练习5
- 📌6.练习6
- 📌7.练习7
🌴数据类型介绍
- 基本的内置类型:
1. char 占1个字节 ----->字符数据类型
2. short 占2个字节 -----> 短整型
3. int 占4个字节 ----->整形
4. long 占4/8个字节 ----->长整型
5. long long 占8个字节 -----> 更长的整形
6. float 占4个字节 -----> 单精度浮点数
7. double 占8个字节 -----> 双精度浮点数
注意:C语言中没有字符串类型
类型的意义:
- 内存占用和范围:不同的数据类型在内存中占用不同的字节数,并且能够表示的数值范围也不同。
正确选择数据类型可以优化内存使用,同时确保数据不会超出所允许的范围,避免溢出和精度丢失的问题。 - 数据操作和运算规则:不同数据类型支持不同的操作,并且对于不同数据类型之间的运算有明确的规则。了解这些规则可以帮助开发者正确地处理数据,
避免数据转换错误和意外的计算结果。 - 类型检查和数据表达:C语言是一种静态类型语言,编译器在编译时会对数据类型进行检查。
正确定义数据类型可以帮助发现类型错误和潜在问题,增强代码的可靠性。此外,不同的数据类型也能够更直观地表达数据,使代码更易读和理解。
📌类型的基本归类:
- 整形家族:
- char
unsigned char:无符号字符型,范围为 0 到 255。
signed char:一个字节大小的有符号整数,范围为 -128 到 127。
注意:char是否为signed char,C语言标准并没有规定,取决于编译器。
字符在内存中存储的是字符的ASCII码值,ASCII码值是整型,所以字符类型归类到整型家族- short
unsigned short [int]:无符号短整型,范围为 0 到 65,535。
signed short [int]:两个字节大小的有符号整数,范围为 -32,768 到 32,767。- int
unsigned int:无符号整型,范围为 0 到 4,294,967,295。
signed int:四个字节大小的有符号整数,范围为 -2,147,483,648 到 2,147,483,647。- long
unsigned long [int]:无符号长整型,范围取决于编译器,但至少和 unsigned int 类型的范围相同。
signed long [int]:四个或八个字节大小的有符号整数,范围取决于编译器,但至少是 int 类型的范围。
以下以char的两种类型为例(其他类型类似),我们可以利用画圈的方法来方便我们的记忆,我个人让我这是一个非常好的方法(牛🖊)具体参照下方两幅图片:


- 浮点数家族:
- float::float是单精度浮点类型,通常占用4个字节(32位)。它可以表示大约6到7位有效数字,并且具有范围约为1.2E-38到3.4E+38的取值范围。在表示浮点数时,通常使用后缀f或F来标识float类型,例如:3.14f。
- double:double是双精度浮点类型,通常占用8个字节(64位)。它可以表示大约15到16位有效数字,并且具有更大的范围,约为2.3E-308到1.7E+308。在表示浮点数时,C语言通常默认为double类型,不需要显式指定后缀。例如:3.14表示的是double类型。
- 构造类型:
- 数组类型
- 结构体类型
struct- 枚举类型
enum- 联合类型
union
- 指针类型:
1.
int *pi;
2.char *pc;
3.float* pf;
4.void* pv;(无具体类型的指针)
- 空类型:
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
🌴整形在内存中的存储
我们之前讲过一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。
那接下来我们谈谈数据在所开辟内存中到底是如何存储的?
比如:
int a = 20;
int b = -10;
我们知道为 a 分配四个字节的空间。
那如何存储?
下来了解下面的概念:
📌原码、反码、补码
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位
正数的原、反、补码都相同。
负整数的三种表示方法各不相同。
在我上一篇文章中也有涉及到,具体请移步【C语言】操作符—详解
- 原码
直接将数值按照正负数的形式翻译成二进制就可以得到原码。- 反码
将原码的符号位不变,其他位依次按位取反就可以得到反码。- 补码
反码+1就得到补码。
注意:补码+1得到的是原码。
对于整形来说:数据存放内存中其实存放的是补码。
为什么呢?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程 是相同的,
不需要额外的硬件电路。
我们看看在内存中的存储:
注意:这里是各个变量对应补码的16进制表示形式
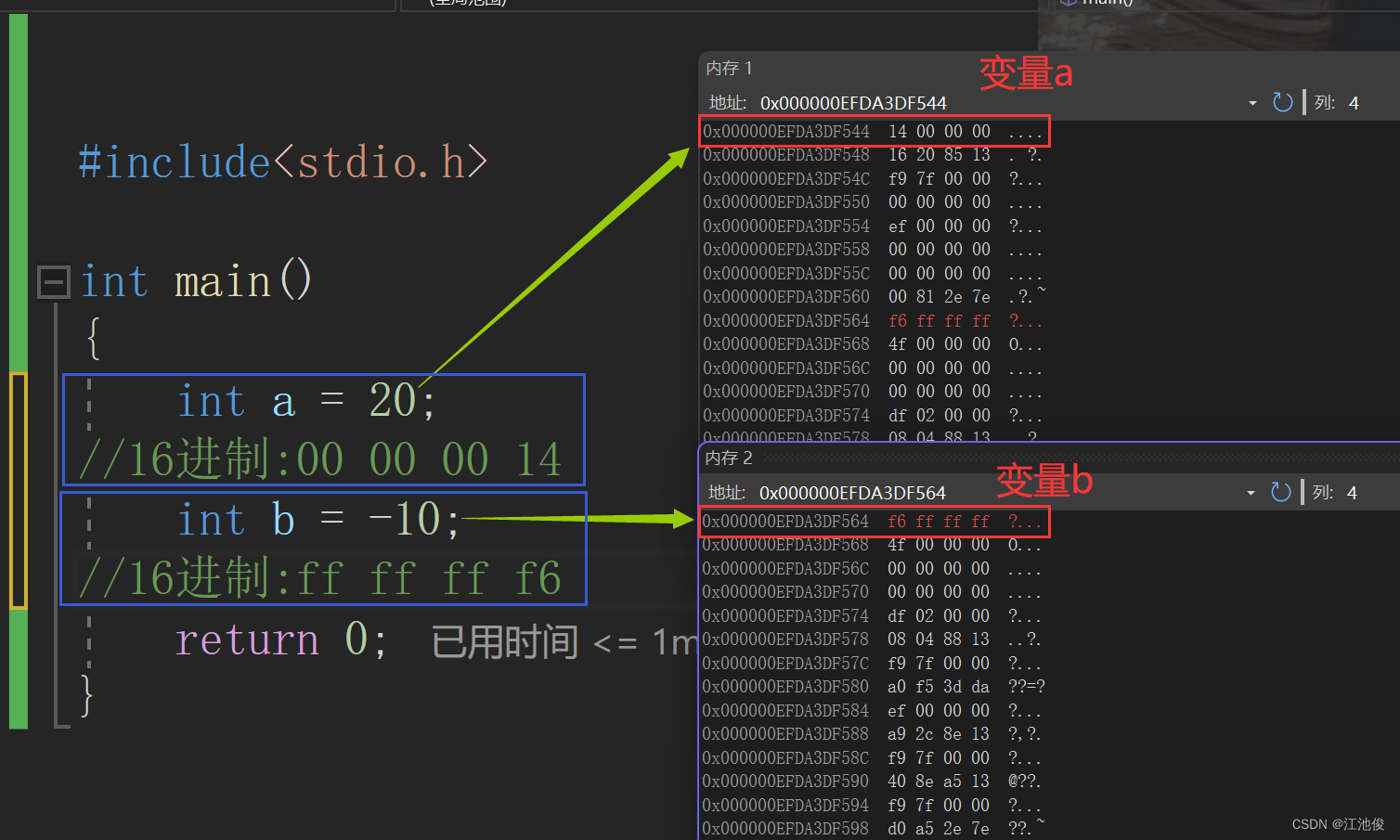
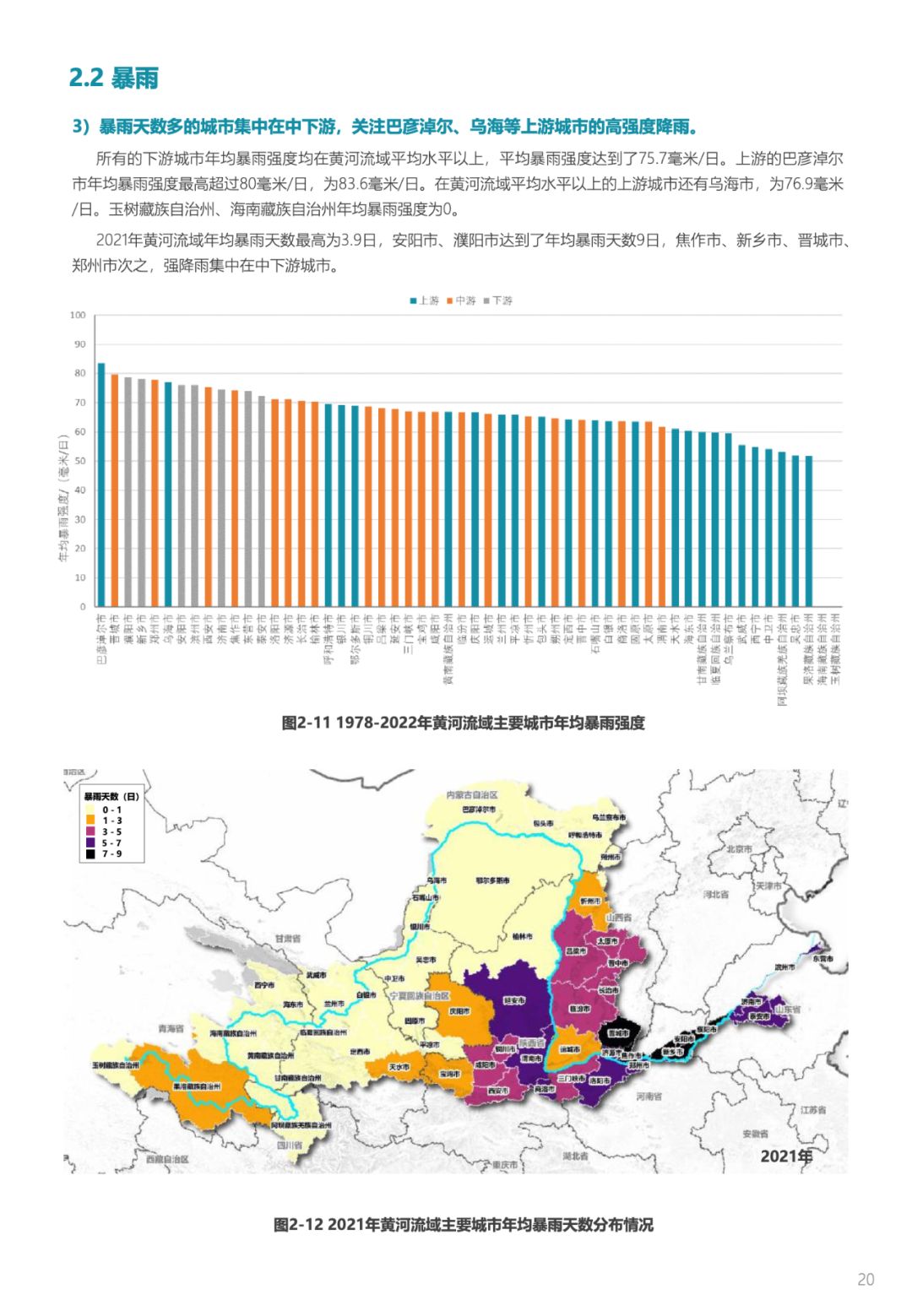
我们可以看到对于a和b分别存储的是补码。但是我们发现顺序有点不对劲。
这是因为数据的存储被分为大小端两种情况。
📌大小端介绍
1. 什么是大端小端:
-
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中。
-小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,保存在内存的高地址中。
2.为什么有大端和小端:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元
都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short
型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32
位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因
此就导致了大端存储模式和小端存储模式。
例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为
高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高
地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则
为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式
还是小端模式。
🌴练习
📌1.百度2015年系统工程师笔试题:
题目描述:请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(10分)
思路:
因为1的二进制序列的16进制表示形式为00 00 00 01,所以如果机器是小端字节序存储形式,那么整型 1 在内存中存储地址由低到高依次为 01 00 00 00;如果机器是大端字节序存储形式,那么在整型 1 在内存中存储地址由低到高依次为 00 00 00 01,这时我们可以利用字符(cha)型指针访问此地址存储的值,因为char型指针一次只能访问一个字节,所以如果是小端,则访问的值为01,如果是打端,则访问的值是00。
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char *)&i);
}
int main()
{
int ret = check_sys();
if(ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
📌2.练习2
//下面程序输出什么?
#include <stdio.h>
int main()
{
char a= -1;
//10000000000000000000000000000001 -a的原码
//11111111111111111111111111111110
//11111111111111111111111111111111 -a的补码
//11111111 - a
signed char b=-1;
//11111111 - b
unsigned char c=-1;
//11111111 - c
printf("a=%d,b=%d,c=%d",a,b,c);//结果为a=-1 b=-1 c=255
//%d 是以10进制的形式打印有符号的整数
//打印时a,b为有符号的char,所以打印时将第一个1看成符号位,在左边补上24个1
//所以打印时a,b又变成11111111111111111111111111111111,但这是补码,
//打印的数字需要为原码对应的值,所以转换为原码为
//10000000000000000000000000000001,对应的十进制为-1
//而c为无符号的char,所以打印时不分符号位,左边补上24个0
//即为00000000000000000000000011111111,
//因为无符号为正数,所以原码补码相同,对应的十进制为255
return 0;
}
📌3.练习3
#include <stdio.h>
int main()
{
char a = -128;
//10000000000000000000000010000000 -a的原码
//11111111111111111111111101111111
//11111111111111111111111110000000 -a的补码
//10000000 - 内存中存储的a
//打印时需要整型提升,此时看a的类型,因为a的类型为有符号的char,
//所以将内存中a的首位看成符号位,为1则左边全补上1;为0,则全补0
//即:11111111111111111111111110000000 ---将它看成无符号的数打印,
//则它是一个很大的数,值为:4294967168
printf("%u\n",a);//结果为:4294967168
//%u 是10进制的形式,打印无符号的整数
//%d 是10进制的形式,打印有符号的整数
return 0;
}
#include <stdio.h>
int main()
{
char a = 128;
//00000000000000000000000010000000 -a的原码,反码,补码
//10000000 -内存中存储的a
//11111111111111111111111110000000 - a整型提升后的值
printf("%u\n",a);//结果为:4294967168
//%u 是10进制的形式,打印无符号的整数
//%d 是10进制的形式,打印有符号的整数
return 0;
}
📌4.练习4
int i= -20;
//10000000000000000000000000010100 -i的原码
//11111111111111111111111111101011
//11111111111111111111111111101100 -i的补码
unsigned int j = 10;
// 00000000000000000000000000001010 -j的原码,反码,补码
// + 11111111111111111111111111101100
// = 11111111111111111111111111110110 -i+j的补码
// 10000000000000000000000000001001 -i+j的反码
// 10000000000000000000000000001010 -i+j的原码,对应十进制值为:-10
printf("%d\n", i+j); //结果为:-10
//按照补码的形式进行运算,最后格式化成为有符号整数
📌5.练习5
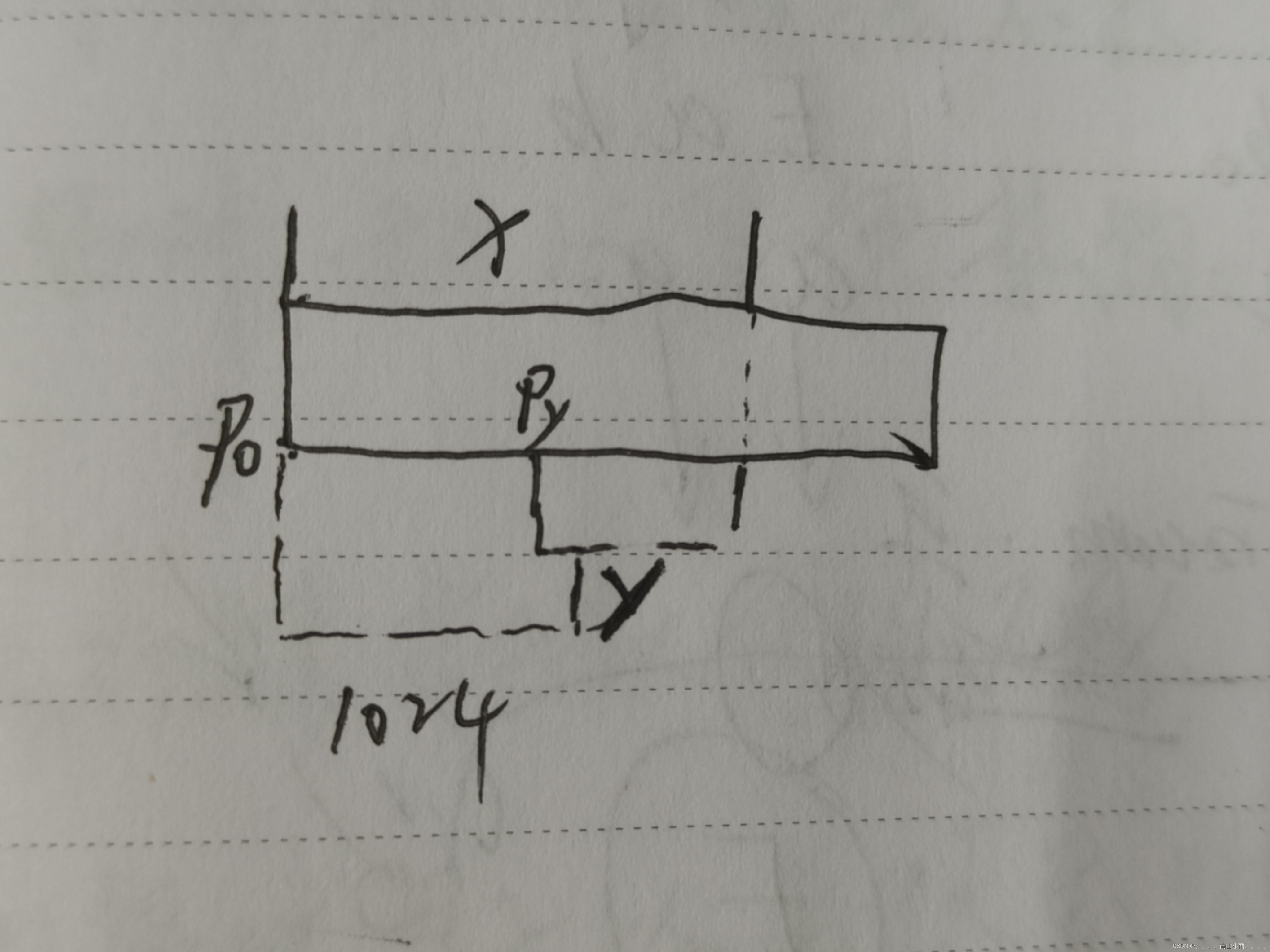
unsigned int i;//因为是无符号的整型,所以i一直大于等于于0
for(i = 9; i >= 0; i--)
{
printf("%u\n",i);
}//所以此代码会进入死循环
如图说示,i=9开始,逆时针走,一直在0~65535这个范围内。

📌6.练习6
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
//这里也可以使用画圈的方法,数组中的值从-1开始一直到0,如下:
//-1 -2 -3 -4 -5 .. -128 127 .. 6 5 4 3 2 1 0
//-1~-128一个有:128个数,127~1一共有:127个数,所以共有:128 + 127 = 255
}
printf("%d",strlen(a));
//strlen 统计的是\0之前出现的字符的个数
//'\0' - 对应的ASCII码值:0
return 0;
}
📌7.练习7
#include <stdio.h>
unsigned char i = 0;
//无符号的插入取值范围在0~255之间
int main()
{
for(i = 0;i<=255;i++)
//i的值从0到255,然后再从255到0,一直这样循环
{
printf("hello world\n");
//陷入死循环
}
return 0;
}
🔥今天的分享就到这里,如果觉得博主的文章还不错的话,请👍三连支持一下博主哦🤞