Apache Arrow是一种开放的、与语言无关的列式内存格式,在本系列文章[1]的前几篇中,我们都聚焦于内存表示[2]与内存操作[3]。
但对于一个数据库系统或大数据分析平台来说,数据不能也无法一直放在内存中,虽说目前内存很大也足够便宜了,但其易失性也决定了我们在特定时刻还是要将数据序列化后存储到磁盘或一些低成本的存储服务上(比如AWS的S3等)。
那么将Arrow序列化成什么存储格式呢?CSV、JSON?显然这些格式都不是为最大限度提高空间效率以及数据检索能力而设计的。在数据分析领域,Apache Parquet是与Arrow相似的一种开放的、面向列的数据存储格式,它被设计用于高效的数据编码和检索并最大限度提高空间效率。
和Arrow是一种内存格式不同,Parquet是一种数据文件格式。此外,Arrow和Parquet在设计上也做出了各自的一些取舍。Arrow旨在由矢量化计算内核对数据进行操作,提供对任何数组索引的 O(1) 随机访问查找能力;而Parquet为了最大限度提高空间效率,采用了可变长度编码方案和块压缩来大幅减小数据大小,这些技术都是以丧失高性能随机存取查找为代价的。
Parquet也是Apache的顶级项目[4],大多数实现了Arrow的编程语言也都提供了支持Arrow格式与Parquet文件相互转换的库实现,Go也不例外。在本文中,我们就来粗浅看一下如何使用Go实现Parquet文件的读写,即Arrow和Parquet的相互转换。
注:关于Parquet文件的详细格式(也蛮复杂),我可能会在后续文章中说明。
1. Parquet简介
如果不先说一说Parquet文件格式,后面的内容理解起来会略有困难的。下面是一个Parquet文件的结构示意图:
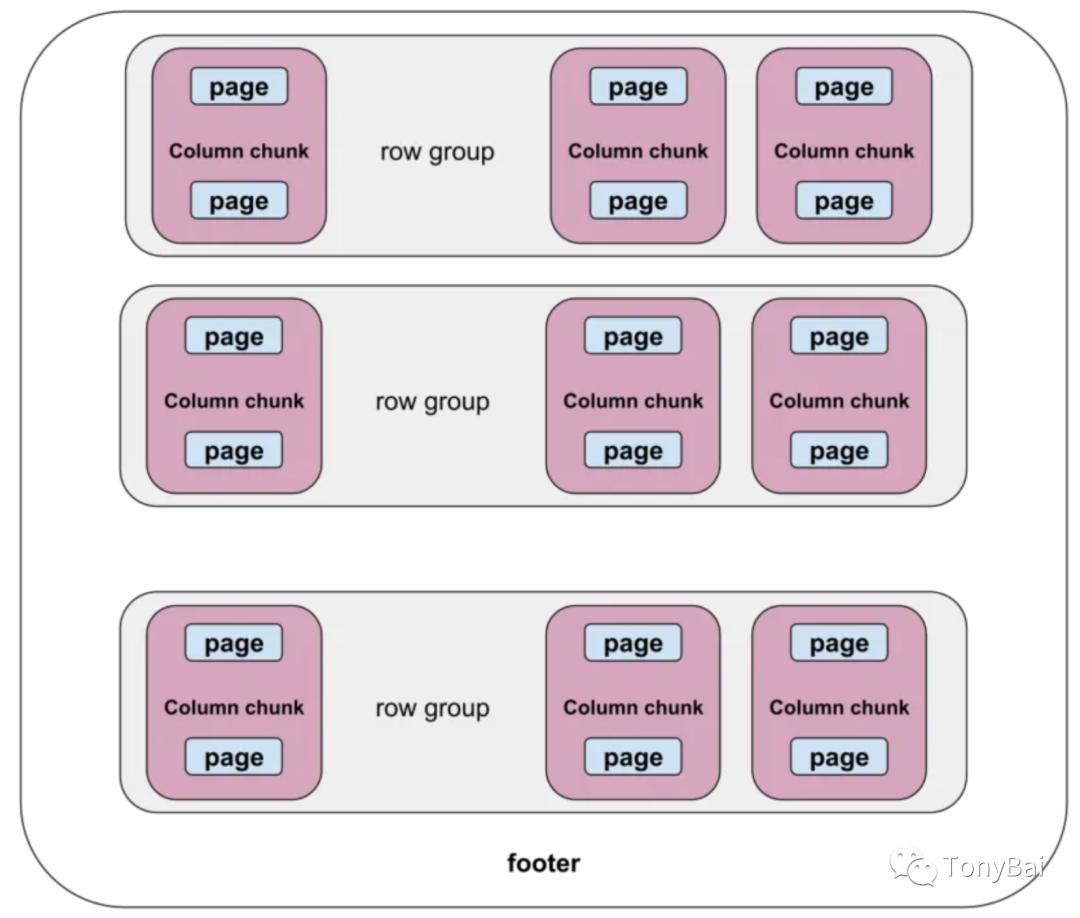
我们看到Parquet格式的文件被分为多个row group,每个row group由每一列的列块(column chunk)组成。考虑到磁盘存储的特点,每个列块又分为若干个页。这个列块中的诸多同构类型的列值可以在编码和压缩后存储在各个页中。下面是Parquet官方文档中Parquet文件中数据存储的具体示意图:
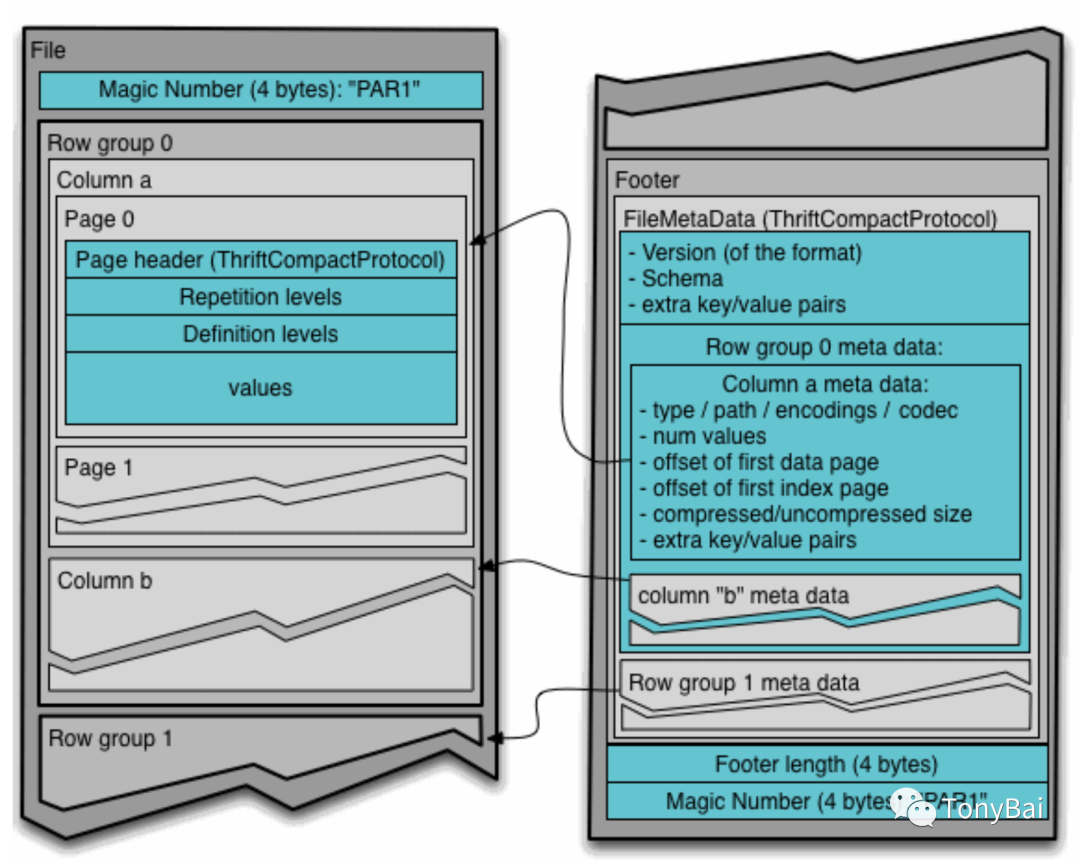
我们看到Parquet按row group顺序向后排列,每个row group中column chunk也是依column次序向后排列的。
注:关于上图中repetion level和definition level这样的高级概念,不会成为理解本文内容的障碍,我们将留到后续文章中系统说明。
2. Arrow Table <-> Parquet
有了上面Parquet文件格式的初步知识后,接下来我们就来看看如何使用Go在Arrow和Parquet之间进行转换。
在《高级数据结构》[5]一文中,我们学习了Arrow Table和Record Batch两种高级结构。接下来我们就来看看如何将Table或Record与Parquet进行转换。一旦像Table、Record Batch这样的高级结构的转换搞定了,那Arrow中的那些简单数据类型[6])也就不在话下了。况且在实际项目中,我们面对更多的也是Arrow的高级数据结构(Table或Record)与Parquet的转换。
我们先来看看Table。
2.1 Table -> Parquet
通过在《高级数据结构》[7]一文,我们知道了Arrow Table的每一列本质上就是Schema+Chunked Array,这和Parquet的文件格式具有较高的适配度。
Arrow Go的parquet实现提供对了Table的良好支持,我们通过一个WriteTable函数就可以将内存中的Arrow Table持久化为Parquet格式的文件,我们来看看下面这个示例:
// flat_table_to_parquet.go
package main
import (
"os"
"github.com/apache/arrow/go/v13/arrow"
"github.com/apache/arrow/go/v13/arrow/array"
"github.com/apache/arrow/go/v13/arrow/memory"
"github.com/apache/arrow/go/v13/parquet/pqarrow"
)
func main() {
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "col1", Type: arrow.PrimitiveTypes.Int32},
{Name: "col2", Type: arrow.PrimitiveTypes.Float64},
{Name: "col3", Type: arrow.BinaryTypes.String},
},
nil,
)
col1 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
ib := array.NewInt32Builder(memory.DefaultAllocator)
defer ib.Release()
ib.AppendValues([]int32{1, 2, 3}, nil)
i1 := ib.NewInt32Array()
defer i1.Release()
ib.AppendValues([]int32{4, 5, 6, 7, 8, 9, 10}, nil)
i2 := ib.NewInt32Array()
defer i2.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Int32,
[]arrow.Array{i1, i2},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(0), chunk)
}()
defer col1.Release()
col2 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
fb := array.NewFloat64Builder(memory.DefaultAllocator)
defer fb.Release()
fb.AppendValues([]float64{1.1, 2.2, 3.3, 4.4, 5.5}, nil)
f1 := fb.NewFloat64Array()
defer f1.Release()
fb.AppendValues([]float64{6.6, 7.7}, nil)
f2 := fb.NewFloat64Array()
defer f2.Release()
fb.AppendValues([]float64{8.8, 9.9, 10.0}, nil)
f3 := fb.NewFloat64Array()
defer f3.Release()
c := arrow.NewChunked(
arrow.PrimitiveTypes.Float64,
[]arrow.Array{f1, f2, f3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(1), chunk)
}()
defer col2.Release()
col3 := func() *arrow.Column {
chunk := func() *arrow.Chunked {
sb := array.NewStringBuilder(memory.DefaultAllocator)
defer sb.Release()
sb.AppendValues([]string{"s1", "s2"}, nil)
s1 := sb.NewStringArray()
defer s1.Release()
sb.AppendValues([]string{"s3", "s4"}, nil)
s2 := sb.NewStringArray()
defer s2.Release()
sb.AppendValues([]string{"s5", "s6", "s7", "s8", "s9", "s10"}, nil)
s3 := sb.NewStringArray()
defer s3.Release()
c := arrow.NewChunked(
arrow.BinaryTypes.String,
[]arrow.Array{s1, s2, s3},
)
return c
}()
defer chunk.Release()
return arrow.NewColumn(schema.Field(2), chunk)
}()
defer col3.Release()
var tbl arrow.Table
tbl = array.NewTable(schema, []arrow.Column{*col1, *col2, *col3}, -1)
defer tbl.Release()
f, err := os.Create("flat_table.parquet")
if err != nil {
panic(err)
}
defer f.Close()
err = pqarrow.WriteTable(tbl, f, 1024, nil, pqarrow.DefaultWriterProps())
if err != nil {
panic(err)
}
}我们基于arrow的Builder模式以及NewTable创建了一个拥有三个列的Table(该table的创建例子来自于《高级数据结构》[8]一文)。有了table后,我们直接调用pqarrow的WriteTable函数即可将table写成parquet格式的文件。
我们来运行一下上述代码:
$go run flat_table_to_parquet.go执行完上面命令后,当前目录下会出现一个flat_table.parquet的文件!
我们如何查看该文件内容来验证写入的数据是否与table一致呢?arrow go的parquet实现提供了一个parquet_reader的工具可以帮助我们做到这点,你可以执行如下命令安装这个工具:
$go install github.com/apache/arrow/go/v13/parquet/cmd/parquet_reader@latest之后我们就可以执行下面命令查看我们刚刚生成的flat_table.parquet文件的内容了:
$parquet_reader flat_table.parquet
File name: flat_table.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 10
Number of RowGroups: 1
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: col1 (INT32/INT_32)
Column 1: col2 (DOUBLE)
Column 2: col3 (BYTE_ARRAY/UTF8)
--- Row Group: 0 ---
--- Total Bytes: 396 ---
--- Rows: 10 ---
Column 0
Values: 10, Min: 1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 111, Compressed Size: 111
Column 1
Values: 10, Min: 1.1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 169, Compressed Size: 169
Column 2
Values: 10, Min: [115 49], Max: [115 57], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 116, Compressed Size: 116
--- Values ---
col1 |col2 |col3 |
1 |1.100000 |s1 |
2 |2.200000 |s2 |
3 |3.300000 |s3 |
4 |4.400000 |s4 |
5 |5.500000 |s5 |
6 |6.600000 |s6 |
7 |7.700000 |s7 |
8 |8.800000 |s8 |
9 |9.900000 |s9 |
10 |10.000000 |s10 |parquet_reader列出了parquet文件的meta数据和每个row group中的column列的值,从输出来看,与我们arrow table的数据是一致的。
我们再回头看一下WriteTable函数,它的原型如下:
func WriteTable(tbl arrow.Table, w io.Writer, chunkSize int64,
props *parquet.WriterProperties, arrprops ArrowWriterProperties) error这里说一下WriteTable的前三个参数,第一个是通过NewTable得到的arrow table结构,第二个参数也容易理解,就是一个可写的文件描述符,我们通过os.Create可以轻松拿到,第三个参数为chunkSize,这个chunkSize是什么呢?会对parquet文件的写入结果有影响么?其实这个chunkSize就是每个row group中的行数。同时parquet通过该chunkSize也可以计算出arrow table转parquet文件后有几个row group。
我们示例中的chunkSize值为1024,因此整个parquet文件只有一个row group。下面我们将其值改为5,再来看看输出的parquet文件内容:
$parquet_reader flat_table.parquet
File name: flat_table.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 10
Number of RowGroups: 2
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: col1 (INT32/INT_32)
Column 1: col2 (DOUBLE)
Column 2: col3 (BYTE_ARRAY/UTF8)
--- Row Group: 0 ---
--- Total Bytes: 288 ---
--- Rows: 5 ---
Column 0
Values: 5, Min: 1, Max: 5, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 86, Compressed Size: 86
Column 1
Values: 5, Min: 1.1, Max: 5.5, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 122, Compressed Size: 122
Column 2
Values: 5, Min: [115 49], Max: [115 53], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 80, Compressed Size: 80
--- Values ---
col1 |col2 |col3 |
1 |1.100000 |s1 |
2 |2.200000 |s2 |
3 |3.300000 |s3 |
4 |4.400000 |s4 |
5 |5.500000 |s5 |
--- Row Group: 1 ---
--- Total Bytes: 290 ---
--- Rows: 5 ---
Column 0
Values: 5, Min: 6, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 86, Compressed Size: 86
Column 1
Values: 5, Min: 6.6, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 122, Compressed Size: 122
Column 2
Values: 5, Min: [115 49 48], Max: [115 57], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 82, Compressed Size: 82
--- Values ---
col1 |col2 |col3 |
6 |6.600000 |s6 |
7 |7.700000 |s7 |
8 |8.800000 |s8 |
9 |9.900000 |s9 |
10 |10.000000 |s10 |当chunkSize值为5后,parquet文件的row group变成了2,然后parquet_reader工具会按照两个row group的格式分别输出它们的meta信息和列值信息。
接下来,我们再来看一下如何从生成的parquet文件中读取数据并转换为arrow table。
2.2 Table <- Parquet
和WriteTable函数对应,arrow提供了ReadTable函数读取parquet文件并转换为内存中的arrow table,下面是代码示例:
// flat_table_from_parquet.go
func main() {
f, err := os.Open("flat_table.parquet")
if err != nil {
panic(err)
}
defer f.Close()
tbl, err := pqarrow.ReadTable(context.Background(), f, parquet.NewReaderProperties(memory.DefaultAllocator),
pqarrow.ArrowReadProperties{}, memory.DefaultAllocator)
if err != nil {
panic(err)
}
dumpTable(tbl)
}
func dumpTable(tbl arrow.Table) {
s := tbl.Schema()
fmt.Println(s)
fmt.Println("------")
fmt.Println("the count of table columns=", tbl.NumCols())
fmt.Println("the count of table rows=", tbl.NumRows())
fmt.Println("------")
for i := 0; i < int(tbl.NumCols()); i++ {
col := tbl.Column(i)
fmt.Printf("arrays in column(%s):\n", col.Name())
chunk := col.Data()
for _, arr := range chunk.Chunks() {
fmt.Println(arr)
}
fmt.Println("------")
}
}我们看到ReadTable使用起来非常简单,由于parquet文件中包含meta信息,我们调用ReadTable时,一些参数使用默认值或零值即可。
我们运行一下上述代码:
$go run flat_table_from_parquet.go
schema:
fields: 3
- col1: type=int32
metadata: ["PARQUET:field_id": "-1"]
- col2: type=float64
metadata: ["PARQUET:field_id": "-1"]
- col3: type=utf8
metadata: ["PARQUET:field_id": "-1"]
------
the count of table columns= 3
the count of table rows= 10
------
arrays in column(col1):
[1 2 3 4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5 6.6 7.7 8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2" "s3" "s4" "s5" "s6" "s7" "s8" "s9" "s10"]
------2.3 Table -> Parquet(压缩)
前面提到,Parquet文件格式的设计充分考虑了空间利用效率,再加上其是面向列存储的格式,Parquet支持列数据的压缩存储,并支持为不同列选择不同的压缩算法。
前面示例中调用的WriteTable在默认情况下是不对列进行压缩的,这从parquet_reader读取到的列的元信息中也可以看到(比如下面的Compression: UNCOMPRESSED):
Column 0
Values: 10, Min: 1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 111, Compressed Size: 111我们在WriteTable时也可以通过parquet.WriterProperties参数来为每个列指定压缩算法,比如下面示例:
// flat_table_to_parquet_compressed.go
var tbl arrow.Table
tbl = array.NewTable(schema, []arrow.Column{*col1, *col2, *col3}, -1)
defer tbl.Release()
f, err := os.Create("flat_table_compressed.parquet")
if err != nil {
panic(err)
}
defer f.Close()
wp := parquet.NewWriterProperties(parquet.WithCompression(compress.Codecs.Snappy),
parquet.WithCompressionFor("col1", compress.Codecs.Brotli))
err = pqarrow.WriteTable(tbl, f, 1024, wp, pqarrow.DefaultWriterProps())
if err != nil {
panic(err)
}在这段代码中,我们通过parquet.NewWriterProperties构建了新的WriterProperties,这个新的Properties默认所有列使用Snappy压缩,针对col1列使用Brotli算法压缩。我们将压缩后的数据写入flat_table_compressed.parquet文件。使用go run运行flat_table_to_parquet_compressed.go,然后使用parquet_reader查看文件flat_table_compressed.parquet得到如下结果:
$go run flat_table_to_parquet_compressed.go
$parquet_reader flat_table_compressed.parquet
File name: flat_table_compressed.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 10
Number of RowGroups: 1
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: col1 (INT32/INT_32)
Column 1: col2 (DOUBLE)
Column 2: col3 (BYTE_ARRAY/UTF8)
--- Row Group: 0 ---
--- Total Bytes: 352 ---
--- Rows: 10 ---
Column 0
Values: 10, Min: 1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: BROTLI, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 111, Compressed Size: 98
Column 1
Values: 10, Min: 1.1, Max: 10, Null Values: 0, Distinct Values: 0
Compression: SNAPPY, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 168, Compressed Size: 148
Column 2
Values: 10, Min: [115 49], Max: [115 57], Null Values: 0, Distinct Values: 0
Compression: SNAPPY, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 116, Compressed Size: 106
--- Values ---
col1 |col2 |col3 |
1 |1.100000 |s1 |
2 |2.200000 |s2 |
3 |3.300000 |s3 |
4 |4.400000 |s4 |
5 |5.500000 |s5 |
6 |6.600000 |s6 |
7 |7.700000 |s7 |
8 |8.800000 |s8 |
9 |9.900000 |s9 |
10 |10.000000 |s10 |从parquet_reader的输出,我们可以看到:各个Column的Compression信息不再是UNCOMPRESSED了,并且三个列在经过压缩后的Size与未压缩对比都有一定的减小:
Column 0:
Compression: BROTLI, Uncompressed Size: 111, Compressed Size: 98
Column 1:
Compression: SNAPPY, Uncompressed Size: 168, Compressed Size: 148
Column 2:
Compression: SNAPPY, Uncompressed Size: 116, Compressed Size: 106从文件大小对比也能体现出压缩算法的作用:
-rw-r--r-- 1 tonybai staff 786 7 22 08:06 flat_table.parquet
-rw-r--r-- 1 tonybai staff 742 7 20 13:19 flat_table_compressed.parquetGo的parquet实现支持多种压缩算法:
// github.com/apache/arrow/go/parquet/compress/compress.go
var Codecs = struct {
Uncompressed Compression
Snappy Compression
Gzip Compression
// LZO is unsupported in this library since LZO license is incompatible with Apache License
Lzo Compression
Brotli Compression
// LZ4 unsupported in this library due to problematic issues between the Hadoop LZ4 spec vs regular lz4
// see: http://mail-archives.apache.org/mod_mbox/arrow-dev/202007.mbox/%3CCAAri41v24xuA8MGHLDvgSnE+7AAgOhiEukemW_oPNHMvfMmrWw@mail.gmail.com%3E
Lz4 Compression
Zstd Compression
}{
Uncompressed: Compression(parquet.CompressionCodec_UNCOMPRESSED),
Snappy: Compression(parquet.CompressionCodec_SNAPPY),
Gzip: Compression(parquet.CompressionCodec_GZIP),
Lzo: Compression(parquet.CompressionCodec_LZO),
Brotli: Compression(parquet.CompressionCodec_BROTLI),
Lz4: Compression(parquet.CompressionCodec_LZ4),
Zstd: Compression(parquet.CompressionCodec_ZSTD),
}你只需要根据你的列的类型选择最适合的压缩算法即可。
2.4 Table <- Parquet(压缩)
接下来,我们来读取这个数据经过压缩的Parquet。读取压缩的Parquet是否需要在ReadTable时传入特殊的Properties呢?答案是不需要!因为Parquet文件中存储了元信息(metadata),可以帮助ReadTable使用对应的算法解压缩并提取信息:
// flat_table_from_parquet_compressed.go
func main() {
f, err := os.Open("flat_table_compressed.parquet")
if err != nil {
panic(err)
}
defer f.Close()
tbl, err := pqarrow.ReadTable(context.Background(), f, parquet.NewReaderProperties(memory.DefaultAllocator),
pqarrow.ArrowReadProperties{}, memory.DefaultAllocator)
if err != nil {
panic(err)
}
dumpTable(tbl)
}运行这段程序,我们就可以读取压缩后的parquet文件了:
$go run flat_table_from_parquet_compressed.go
schema:
fields: 3
- col1: type=int32
metadata: ["PARQUET:field_id": "-1"]
- col2: type=float64
metadata: ["PARQUET:field_id": "-1"]
- col3: type=utf8
metadata: ["PARQUET:field_id": "-1"]
------
the count of table columns= 3
the count of table rows= 10
------
arrays in column(col1):
[1 2 3 4 5 6 7 8 9 10]
------
arrays in column(col2):
[1.1 2.2 3.3 4.4 5.5 6.6 7.7 8.8 9.9 10]
------
arrays in column(col3):
["s1" "s2" "s3" "s4" "s5" "s6" "s7" "s8" "s9" "s10"]
------接下来,我们来看看Arrow中的另外一种高级数据结构Record Batch如何实现与Parquet文件格式的转换。
3. Arrow Record Batch <-> Parquet
注:大家可以先阅读/温习一下《高级数据结构》[9]一文来了解一下Record Batch的概念。
3.1 Record Batch -> Parquet
Arrow Go实现将一个Record Batch作为一个Row group来对应。下面的程序向Parquet文件中写入了三个record,我们来看一下:
// flat_record_to_parquet.go
func main() {
var records []arrow.Record
schema := arrow.NewSchema(
[]arrow.Field{
{Name: "archer", Type: arrow.BinaryTypes.String},
{Name: "location", Type: arrow.BinaryTypes.String},
{Name: "year", Type: arrow.PrimitiveTypes.Int16},
},
nil,
)
rb := array.NewRecordBuilder(memory.DefaultAllocator, schema)
defer rb.Release()
for i := 0; i < 3; i++ {
postfix := strconv.Itoa(i)
rb.Field(0).(*array.StringBuilder).AppendValues([]string{"tony" + postfix, "amy" + postfix, "jim" + postfix}, nil)
rb.Field(1).(*array.StringBuilder).AppendValues([]string{"beijing" + postfix, "shanghai" + postfix, "chengdu" + postfix}, nil)
rb.Field(2).(*array.Int16Builder).AppendValues([]int16{1992 + int16(i), 1993 + int16(i), 1994 + int16(i)}, nil)
rec := rb.NewRecord()
records = append(records, rec)
}
// write to parquet
f, err := os.Create("flat_record.parquet")
if err != nil {
panic(err)
}
props := parquet.NewWriterProperties()
writer, err := pqarrow.NewFileWriter(schema, f, props,
pqarrow.DefaultWriterProps())
if err != nil {
panic(err)
}
defer writer.Close()
for _, rec := range records {
if err := writer.Write(rec); err != nil {
panic(err)
}
rec.Release()
}
}和调用WriteTable完成table到parquet文件的写入不同,这里我们创建了一个FileWriter,通过FileWriter将构建出的Record Batch逐个写入。运行上述代码生成flat_record.parquet文件并使用parquet_reader展示该文件的内容:
$go run flat_record_to_parquet.go
$parquet_reader flat_record.parquet
File name: flat_record.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 9
Number of RowGroups: 3
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: archer (BYTE_ARRAY/UTF8)
Column 1: location (BYTE_ARRAY/UTF8)
Column 2: year (INT32/INT_16)
--- Row Group: 0 ---
--- Total Bytes: 255 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 48], Max: [116 111 110 121 48], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 79
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 48], Max: [115 104 97 110 103 104 97 105 48], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 99
Column 2
Values: 3, Min: 1992, Max: 1994, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 77
--- Values ---
archer |location |year |
tony0 |beijing0 |1992 |
amy0 |shanghai0 |1993 |
jim0 |chengdu0 |1994 |
--- Row Group: 1 ---
--- Total Bytes: 255 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 49], Max: [116 111 110 121 49], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 79
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 49], Max: [115 104 97 110 103 104 97 105 49], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 99
Column 2
Values: 3, Min: 1993, Max: 1995, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 77
--- Values ---
archer |location |year |
tony1 |beijing1 |1993 |
amy1 |shanghai1 |1994 |
jim1 |chengdu1 |1995 |
--- Row Group: 2 ---
--- Total Bytes: 255 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 50], Max: [116 111 110 121 50], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 79
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 50], Max: [115 104 97 110 103 104 97 105 50], Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 99
Column 2
Values: 3, Min: 1994, Max: 1996, Null Values: 0, Distinct Values: 0
Compression: UNCOMPRESSED, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 77
--- Values ---
archer |location |year |
tony2 |beijing2 |1994 |
amy2 |shanghai2 |1995 |
jim2 |chengdu2 |1996 |我们看到parquet_reader分别输出了三个row group的元数据和列值,每个row group与我们写入的一个record对应。
那读取这样的parquet文件与ReadTable有何不同呢?我们继续往下看。
3.2 Record Batch <- Parquet
下面是用于读取
// flat_record_from_parquet.go
func main() {
f, err := os.Open("flat_record.parquet")
if err != nil {
panic(err)
}
defer f.Close()
rdr, err := file.NewParquetReader(f)
if err != nil {
panic(err)
}
defer rdr.Close()
arrRdr, err := pqarrow.NewFileReader(rdr,
pqarrow.ArrowReadProperties{
BatchSize: 3,
}, memory.DefaultAllocator)
if err != nil {
panic(err)
}
s, _ := arrRdr.Schema()
fmt.Println(*s)
rr, err := arrRdr.GetRecordReader(context.Background(), nil, nil)
if err != nil {
panic(err)
}
for {
rec, err := rr.Read()
if err != nil && err != io.EOF {
panic(err)
}
if err == io.EOF {
break
}
fmt.Println(rec)
}
}我们看到相对于将parquet转换为table,将parquet转换为record略为复杂一些,这里的一个关键是在调用NewFileReader时传入的ArrowReadProperties中的BatchSize字段,要想正确读取出record,这个BatchSize需适当填写。这个BatchSize会告诉Reader 每个读取的Record Batch的长度,也就是row数量。这里传入的是3,即3个row为一个Recordd batch。
下面是运行上述程序的结果:
$go run flat_record_from_parquet.go
{[{archer 0x26ccc00 false {[PARQUET:field_id] [-1]}} {location 0x26ccc00 false {[PARQUET:field_id] [-1]}} {year 0x26ccc00 false {[PARQUET:field_id] [-1]}}] map[archer:[0] location:[1] year:[2]] {[] []} 0}
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 3
col[0][archer]: ["tony0" "amy0" "jim0"]
col[1][location]: ["beijing0" "shanghai0" "chengdu0"]
col[2][year]: [1992 1993 1994]
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 3
col[0][archer]: ["tony1" "amy1" "jim1"]
col[1][location]: ["beijing1" "shanghai1" "chengdu1"]
col[2][year]: [1993 1994 1995]
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 3
col[0][archer]: ["tony2" "amy2" "jim2"]
col[1][location]: ["beijing2" "shanghai2" "chengdu2"]
col[2][year]: [1994 1995 1996]我们看到:每3行被作为一个record读取出来了。如果将BatchSize改为5,则输出如下:
$go run flat_record_from_parquet.go
{[{archer 0x26ccc00 false {[PARQUET:field_id] [-1]}} {location 0x26ccc00 false {[PARQUET:field_id] [-1]}} {year 0x26ccc00 false {[PARQUET:field_id] [-1]}}] map[archer:[0] location:[1] year:[2]] {[] []} 0}
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 5
col[0][archer]: ["tony0" "amy0" "jim0" "tony1" "amy1"]
col[1][location]: ["beijing0" "shanghai0" "chengdu0" "beijing1" "shanghai1"]
col[2][year]: [1992 1993 1994 1993 1994]
record:
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
rows: 4
col[0][archer]: ["jim1" "tony2" "amy2" "jim2"]
col[1][location]: ["chengdu1" "beijing2" "shanghai2" "chengdu2"]
col[2][year]: [1995 1994 1995 1996]这次:前5行作为一个record,后4行作为另外一个record。
当然,我们也可以使用flat_table_from_parquet.go中的代码来读取flat_record.parquet(将读取文件名改为flat_record.parquet),只不过由于将parquet数据转换为了table,其输出内容将变为:
$go run flat_table_from_parquet.go
schema:
fields: 3
- archer: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- location: type=utf8
metadata: ["PARQUET:field_id": "-1"]
- year: type=int16
metadata: ["PARQUET:field_id": "-1"]
------
the count of table columns= 3
the count of table rows= 9
------
arrays in column(archer):
["tony0" "amy0" "jim0" "tony1" "amy1" "jim1" "tony2" "amy2" "jim2"]
------
arrays in column(location):
["beijing0" "shanghai0" "chengdu0" "beijing1" "shanghai1" "chengdu1" "beijing2" "shanghai2" "chengdu2"]
------
arrays in column(year):
[1992 1993 1994 1993 1994 1995 1994 1995 1996]
------3.3 Record Batch -> Parquet(压缩)
Recod同样支持压缩写入Parquet,其原理与前面table压缩存储是一致的,都是通过设置WriterProperties来实现的:
// flat_record_to_parquet_compressed.go
func main() {
... ...
f, err := os.Create("flat_record_compressed.parquet")
if err != nil {
panic(err)
}
defer f.Close()
props := parquet.NewWriterProperties(parquet.WithCompression(compress.Codecs.Zstd),
parquet.WithCompressionFor("year", compress.Codecs.Brotli))
writer, err := pqarrow.NewFileWriter(schema, f, props,
pqarrow.DefaultWriterProps())
if err != nil {
panic(err)
}
defer writer.Close()
for _, rec := range records {
if err := writer.Write(rec); err != nil {
panic(err)
}
rec.Release()
}
}不过这次针对arrow.string类型和arrow.int16类型的压缩效果非常“差”:
$parquet_reader flat_record_compressed.parquet
File name: flat_record_compressed.parquet
Version: v2.6
Created By: parquet-go version 13.0.0-SNAPSHOT
Num Rows: 9
Number of RowGroups: 3
Number of Real Columns: 3
Number of Columns: 3
Number of Selected Columns: 3
Column 0: archer (BYTE_ARRAY/UTF8)
Column 1: location (BYTE_ARRAY/UTF8)
Column 2: year (INT32/INT_16)
--- Row Group: 0 ---
--- Total Bytes: 315 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 48], Max: [116 111 110 121 48], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 105
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 48], Max: [115 104 97 110 103 104 97 105 48], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 125
Column 2
Values: 3, Min: 1992, Max: 1994, Null Values: 0, Distinct Values: 0
Compression: BROTLI, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 85
--- Values ---
archer |location |year |
tony0 |beijing0 |1992 |
amy0 |shanghai0 |1993 |
jim0 |chengdu0 |1994 |
--- Row Group: 1 ---
--- Total Bytes: 315 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 49], Max: [116 111 110 121 49], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 105
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 49], Max: [115 104 97 110 103 104 97 105 49], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 125
Column 2
Values: 3, Min: 1993, Max: 1995, Null Values: 0, Distinct Values: 0
Compression: BROTLI, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 85
--- Values ---
archer |location |year |
tony1 |beijing1 |1993 |
amy1 |shanghai1 |1994 |
jim1 |chengdu1 |1995 |
--- Row Group: 2 ---
--- Total Bytes: 315 ---
--- Rows: 3 ---
Column 0
Values: 3, Min: [97 109 121 50], Max: [116 111 110 121 50], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 79, Compressed Size: 105
Column 1
Values: 3, Min: [98 101 105 106 105 110 103 50], Max: [115 104 97 110 103 104 97 105 50], Null Values: 0, Distinct Values: 0
Compression: ZSTD, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 99, Compressed Size: 125
Column 2
Values: 3, Min: 1994, Max: 1996, Null Values: 0, Distinct Values: 0
Compression: BROTLI, Encodings: RLE_DICTIONARY PLAIN RLE
Uncompressed Size: 77, Compressed Size: 85
--- Values ---
archer |location |year |
tony2 |beijing2 |1994 |
amy2 |shanghai2 |1995 |
jim2 |chengdu2 |1996 |越压缩,parquet文件的size越大。当然这个问题不是我们这篇文章的重点,只是提醒大家选择适当的压缩算法十分重要。
3.4 Record Batch <- Parquet(压缩)
和读取table转换后的压缩parquet文件一样,读取record转换后的压缩parquet一样无需特殊设置,使用flat_record_from_parquet.go即可(需要改一下读取的文件名),这里就不赘述了。
4. 小结
本文旨在介绍使用Go进行Arrow和Parquet文件相互转换的基本方法,我们以table和record两种高级数据结构为例,分别介绍了读写parquet文件以及压缩parquet文件的方法。
当然本文中的例子都是“平坦(flat)”的简单例子,parquet文件还支持更复杂的嵌套数据,我们会在后续的深入讲解parquet格式的文章中提及。
5. 参考资料
Parquet File Format - https://parquet.apache.org/docs/file-format/
《Dremel: Interactive Analysis of Web-Scale Datasets》 - https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36632.pdf
Announcing Parquet 1.0: Columnar Storage for Hadoop - https://blog.twitter.com/engineering/en_us/a/2013/announcing-parquet-10-columnar-storage-for-hadoop
Dremel made simple with Parquet - https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet
parquet项目首页 - http://parquet.apache.org/
Apache Parquet介绍 by influxdata - https://www.influxdata.com/glossary/apache-parquet/
Intro to InfluxDB IOx - https://www.influxdata.com/blog/intro-influxdb-iox/
Apache Arrow介绍 by influxdb - https://www.influxdata.com/glossary/apache-arrow/
开源时序数据库解析 - InfluxDB IOx - https://zhuanlan.zhihu.com/p/534035337
Arrow and Parquet Part 1: Primitive Types and Nullability - https://arrow.apache.org/blog/2022/10/05/arrow-parquet-encoding-part-1/
Arrow and Parquet Part 2: Nested and Hierarchical Data using Structs and Lists - https://arrow.apache.org/blog/2022/10/08/arrow-parquet-encoding-part-2/
Arrow and Parquet Part 3: Arbitrary Nesting with Lists of Structs and Structs of Lists - https://arrow.apache.org/blog/2022/10/17/arrow-parquet-encoding-part-3/
Cost Efficiency @ Scale in Big Data File Format - https://www.uber.com/blog/cost-efficiency-big-data/
“Gopher部落”知识星球[10]旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2023年,Gopher部落将进一步聚焦于如何编写雅、地道、可读、可测试的Go代码,关注代码质量并深入理解Go核心技术,并继续加强与星友的互动。欢迎大家加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[11]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 - https://github.com/bigwhite/gopherdaily
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
本系列文章: https://tonybai.com/tag/arrow
[2]内存表示: https://tonybai.com/2023/06/25/a-guide-of-using-apache-arrow-for-gopher-part1
[3]内存操作: https://tonybai.com/2023/07/13/a-guide-of-using-apache-arrow-for-gopher-part4/
[4]Parquet也是Apache的顶级项目: https://parquet.apache.org
[5]《高级数据结构》: https://tonybai.com/2023/07/08/a-guide-of-using-apache-arrow-for-gopher-part3/
[6]简单数据类型: https://tonybai.com/2023/06/25/a-guide-of-using-apache-arrow-for-gopher-part1
[7]《高级数据结构》: https://tonybai.com/2023/07/08/a-guide-of-using-apache-arrow-for-gopher-part3/
[8]《高级数据结构》: https://tonybai.com/2023/07/08/a-guide-of-using-apache-arrow-for-gopher-part3/
[9]《高级数据结构》: https://tonybai.com/2023/07/08/a-guide-of-using-apache-arrow-for-gopher-part3/
[10]“Gopher部落”知识星球: https://wx.zsxq.com/dweb2/index/group/51284458844544
[11]链接地址: https://m.do.co/c/bff6eed92687




![[PaddlePaddle] [学习笔记] PaddlePaddle 官方文档 —— 使用Python和NumPy构建神经网络模型](https://img-blog.csdnimg.cn/eb1e2139e69546f8b806fb5b34d23614.png#pic_center)