阿丹:
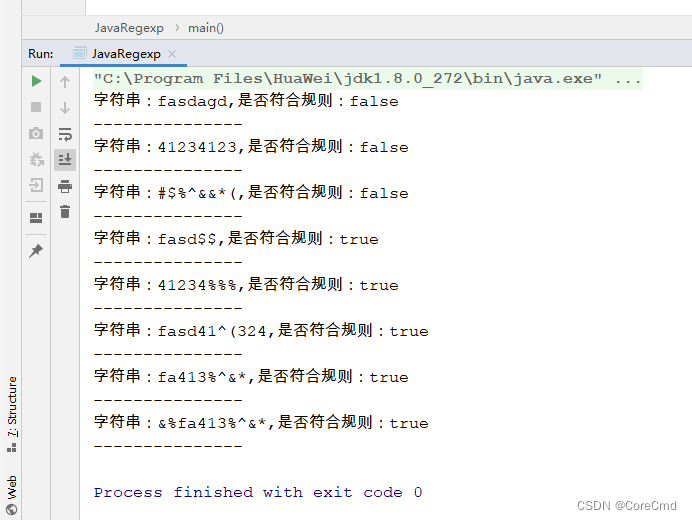
之前研究了MongoDB的基础增删改查。在学会基础的数据库增删改查肯定是不够的。这个时候就涉及到了数据库搜索的时候的效率。需要提高数据的搜索效率。
MongoDB索引
在所以数据库中如果没有数据索引的时候。如果需要查找到一些数据。都会去主动扫描所有可能存在的集合。引入了索引概念就能很高效的使用索引来限制必须在集合中去搜索的文档数。
索引的概念:
索引是特殊数据集,用于存储集合数据的一部分。由于数据是部分数据。因此读取该数据变得更加容易。此部分集存储特定字段的值或按字段值排序的一组字段。
对索引的影响:
- 如何创建索引:createIndex()
- 如何查找索引:getindexes()
- 如何删除索引:dropindex()
索引的影响
从上面的介绍可以看到固然索引对于数据库很友好对于性能的提升也很友好,但是索引太多会减少其他操作。例如插入删除以及其他更新操作。反而得不偿失。
如果语句文档进行频繁的删除等更新操作,如果对于索引的这些字段也进行了影响。那么就需要对这些索引也进行更正改正。
也就是说本对于查询来说是很友好的,但是如果涉及到了索引字段的值修改就要修改MongoDB的两个内容阶段。
所以在索引的选择上要选择不经常更新的字段以及相对重要的字段来作为索引。

如上图所示;
id与code为不经常变更的数据字段所以将这两个字段可以设置为索引。方便我们进行搜索。
如何创建索引:createIndex()
在MongoDB中通过createindex的方法来创建
我先使用如下语句来进行创建了一个ExampleDB集合,然后将3个文档存放到了这个集合中去。
var Example = [
{
"_id":2,
"adncode":1,
"员工姓名":"帅丹"
},
{
"_id":3,
"adncode":2,
"员工姓名":"大力丹"
},
{
"_id":4,
"adncode":1,
"员工姓名":"库库丹"
}
]
db.ExampleDB.insert(Example)在这个文档的格式中我们就可以使用“_id”和“adncode”作为索引。
那么我们接下来使用createindex方法创建索引
#创建索引
db.ExampleDB.createIndex({adncode:1})
代码解释:
这个语句是用于在ExampleDB数据库中创建一个索引,索引的名称是adncode,索引的列是第一列。
具体来说,db.ExampleDB.createIndex({adncode:1}) 是对名为ExampleDB的数据库中的adncode列创建索引,其中adncode是索引的名称,1表示该列是第一列。通过创建索引,可以提高查询adncode列的数据的效率。
参数“ 1”表示使用“ adncode”字段值创建索引时,应按升序对其进行排序。请注意,这与_id字段(ID字段用于唯一标识集合中的每个文档)不同,后者由MongoDB在集合中自动创建。现在,将按照adncode而不是_id字段对文档进行排序。
参数为1表示升序排序,而参数为-1表示倒序排序。在MongoDB中,索引的方向可以是单向(1或-1)或双向({-1,1}或{1,-1}),分别表示从左到右或从右到左的顺序。在创建索引时,可以根据实际需求选择适当的的方向和列来创建索引,以提供更快速的文件访问和查询性能。总之,索引的方向和参数可以根据具体的需求进行选择和调整,以实现最佳的性能和查询效果。
创建成功返回语句解释:
- numIndexesBefore:1表示运行命令之前索引中存在的字段值(集合中的实际字段)的数量。请记住,每个集合都有_id字段,该字段也算作索引的Field值。由于_id索引字段在最初创建时是集合的一部分,因此numIndexesBefore的值为1。
- numIndexesAfter:2表示运行命令后索引中存在的字段值的数目。
- 此处的“ ok:1”输出指定操作已成功,并且新索引已添加到集合中。
上面的代码显示了如何基于一个字段值创建索引,但是也可以基于多个字段值创建索引。
创建索引语句参数讲解
db.ExampleDB.createIndex(keys, options)是MongoDB中用于创建索引的语句。其中的keys参数指定要创建索引的键,可以是一个键文档(如{adncode: 1})或一个包含多个键的数组(如[adncode, code2])。options参数用于指定索引的选项和行为,它是一个包含多个选项的文档。
以下是一些常用的选项和它们的作用:
background:指定索引是否在后台创建,这样可以在创建索引时继续其他操作。默认情况下,索引是在前台创建的,这意味着其他操作会被阻塞。unique:指定索引是否是唯一的。如果设置为true,则在文档中不允许出现重复的索引键值。dropDups:在创建索引时是否删除重复的文档。如果设置为true,则在创建索引时将删除所有重复的文档。name:索引的名称,用于标识和引用该索引。expireAfterSeconds:指定文档过期的时间,以秒为单位。如果设置为一个正数,则在该时间后,文档将被删除。
在使用这个语句时,基本的语法是:
db.collection.createIndex(keys, options)
其中,keys参数可以根据需要设置为一个键文档或一个包含多个键的数组。options参数是可选的,可以根据需要设置为一个包含选项的文档。
需要注意的是,在创建索引时,应该根据实际需求和性能要求选择合适的类型和参数。索引的创建会增加存储空间和计算开销,并且在修改文档时也会受到影响。因此,应该仔细评估索引的需求和影响,并选择适当的的选择和参数。
一次性创建多个字段索引
db.Employee.createIndex({Employeeid:1, EmployeeName:1])代码解释:
现在,createIndex方法考虑多个字段值,这些值现在将导致根据“ Employeeid”和“ EmployeeName”创建索引。Employeeid:1和EmployeeName:1指示应在这2个字段值上创建索引,而:1则指示索引应按升序排列。
如何查找索引:使用getindexes()方法
#查找索引
db.ExampleDB.getIndexes()
代码解释:
- getIndexes方法用于查找集合中的所有索引。
- 输出返回一个文档,该文档仅显示集合中有2个索引,即_id字段,另一个是Employee id字段。:1表示索引中的字段值是按升序创建的。
如何删除索引:dropindex()
通过使用dropindex方法在MongoDB中删除索引
#删除索引
db.ExampleDB.dropIndex({adncode:1})
代码解释:
- dropIndex方法采用必需的字段值,该值需要从索引中删除。
- 返回结果值nIndexesWas:2表示在运行命令之前索引中存在的字段值的数目。请记住,每个集合都有_id字段,该字段也算作索引的Field值。
- ok:1输出指定该操作成功,并且从索引中删除了“ adncode”字段。
-
要一次删除集合中的所有索引,可以使用dropIndexes命令。
删除所有索引
db.ExampleDB.dropIndexes()代码解释
- dropIndexes方法将删除除_id索引以外的所有索引。
小总结:
- 定义索引对于快速高效地搜索集合中的文档非常重要。
- 可以使用createIndex方法创建索引。可以仅在一个字段或多个字段值上创建索引。
- 可以使用getIndexes方法找到索引。
- 可以通过将dropIndex用于单个索引或将dropIndex用于删除所有索引来删除索引。
在MongoDB中使用正则表达式(Regex)-爬虫可用
正则表达式基本概念:
正则表达式用于模式匹配,基本上用于在文档中发现和匹配字符串,以及一些校验规则。
通过正则表达式可以帮助我们在文档中快速的找到和定位到相应的字符串。
使用$regex运算符进行模式匹配
MongoDB中的regex运算符用于在集合中搜索特定的字符串。
比如在上面我们向目标集合中添加的文档们,我现在想要查询有“丹”字出现的文档。我就可以使用正则表达式类指定搜索条件。
#使用正则表达式来制定搜索条件
db.ExampleDB.find(
{
员工姓名 : {$regex : "丹"}
}
).forEach(printjson)

代码解释:
在这里,查找了所有带“丹”字符的员工姓名。因此使用$ regex运算符来定义“ 丹”的搜索条件,也能从结果看到返回了包含对应汉字的文档。
使用正则表达式中的语法对查询规则进行精准描述
规则“^”
比如我们可以使用在匹配规则字符串前添加“^”来保证匹配的时候前面是没有字符的。


可从结果看到“^”符号的作用就是规定在查找的时候关键字前面不能有其他字符。
规则“$”
还可以使用$符号规则来规定在匹配字符的后面不允许有其他字符


从两次的结果可以看到在加上$符号后,在关键字后面如果有字符就不在参与搜索了。
其他规则
字符匹配
元字符 . 可以匹配除换行符之外的任何字符。
例如:. " 可以匹配任何字符串,包括空字符串。
字符集合
用花括号 [] 表示一个字符集合,可以匹配其中任意一个字符。
例如:[abc] 可以匹配字符 a、b 或 c。
字符范围
用连字符 - 表示字符范围,可以匹配一定范围内的字符。
例如:[a-z] 可以匹配小写字母。
否定字符集合
用花括号 [^] 表示一个否定字符集合,可以匹配除了其中指定的字符之外的任何字符。
例如:[^abc] 可以匹配除了字符 a、b 或 c 之外的任何字符。
量词
量词用于匹配前面的元素出现的次数。常见的量词包括:
*表示前面的元素可以出现 0 次或多次。+表示前面的元素可以出现 1 次或多次。?表示前面的元素可以出现 0 次或 1 次。{n}表示前面的元素出现 n 次。{n,}表示前面的元素至少出现 n 次。{n,m}表示前面的元素至少出现 n 次,但不超过 m 次。
例如:a* 可以匹配 0 个或多个字母 a。
转义字符
在正则表达式中,一些特殊字符需要使用反斜杠 \ 进行转义,例如 \d 表示数字、\s 表示空白字符等。
例如:\d+ 可以匹配一个或多个数字。
与$ options进行模式匹配
使用正则表达式运算符时,还可以使用$ options关键字提供其他选项。假设我们想查找所有在目标集合中中带有英文字符的文档,而不管它是区分大小写还是不区分大小写。如果需要这样的结果,那么我们需要使用不区分大小写参数的$ options。
现在,我们运行与上一个相同的查询,我们将永远不会在结果中看到带有大写的英文的文档。为了确保将其包含在结果集中,我们需要添加$ options“ I”参数。
db.Employee.find({EmployeeName:{$regex: “Gu”,$options:’i’}}).forEach(printjson)代码解释:
1、带“ I”参数(表示不区分大小写)的$ options指定无论我们发现字母是小写还是大写,我们都希望执行搜索
2、结果表明,即使一个文档具有大写的目标字母,该文档仍会显示在结果集中
没有regex运算符的模式匹配

在这里没有使用regex运算符,也可以正常使用正则表达式匹配操作
#使用正则表达式来制定搜索条件
db.ExampleDB.find(
{
员工姓名 : /库库丹/
}
).forEach(printjson)
说明:
“//”在MongoDB中这个选项就说明在这些定界符中指定了搜索的条件。
具体正则表达式如何书写可以根据上面提供过的文档来书写。