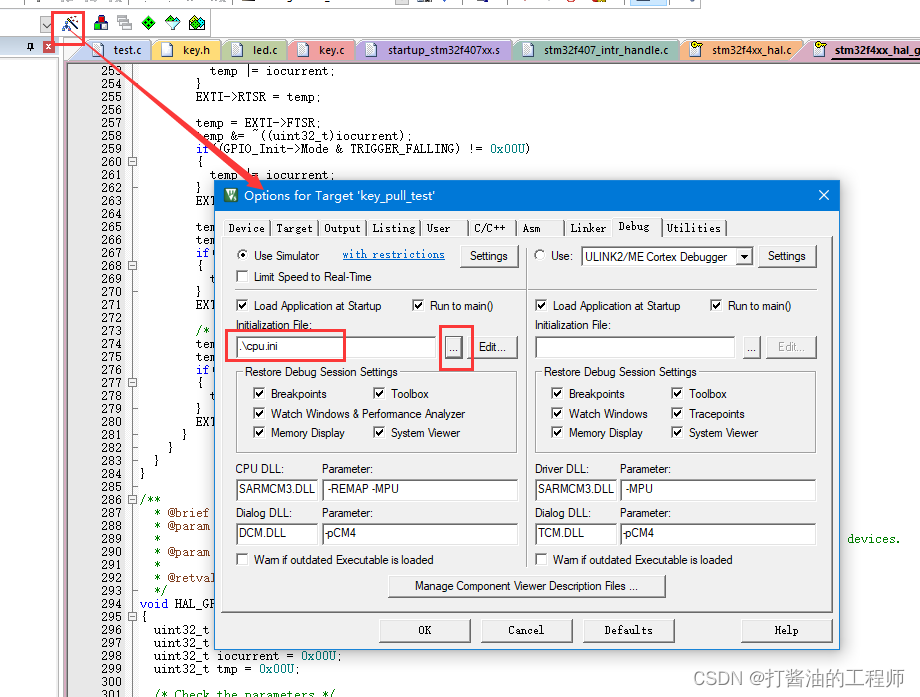
上篇文章中,我给你留了一个思考题:如何构建一个商品搜索系统?
今天这篇文章,我们来说一下电商的商品搜索系统。
引言
搜索这个特性可以说是无处不在,现在很少有网站或者系统不提供搜索功能了,所以,即使你不是一个专业做搜索的程序员,也难免会遇到一些搜索相关的需求。搜索这个东西,表面上看功能很简单,就是一个搜索框,输入关键字,然后搜出来想要的内容就好了。
搜索背后的实现,可以非常简单,简单到什么程度呢?我们就用一个 SQL,LIKE 一下就能实现;也可以很复杂,复杂到什么程度呢?不说百度谷歌这种专业做搜索的公司,其他非专业做搜索的互联网大厂,搜索团队大多是千人规模,这里面不仅有程序员,还有算法工程师、业务专家等等。二者的区别也仅仅是,搜索速度的快慢,以及搜出来的内容好坏而已。
这篇文章,我们就以电商中的商品搜索作为例子,来讲一下,如何用 ES(Elasticsearch) 来快速、低成本地构建一个体验还不错的搜索系统。
理解倒排索引机制
刚刚我们说了,既然我们的数据大多都是存在数据库里,用 SQL 的 LIKE 也能实现匹配,也能搜出结果,为什么还要专门做一套搜索系统呢?我们先来分析一下,为什么数据库不适合做搜索。
搜索的核心需求是全文匹配,对于全文匹配,数据库的索引是根本派不上用场的,那只能全表扫描。全表扫描已经非常慢了,这还不算,还需要在每条记录上做全文匹配,也就是一个字一个字的比对,这个速度就更慢了。所以,使用数据来做搜索,性能上完全没法满足要求。
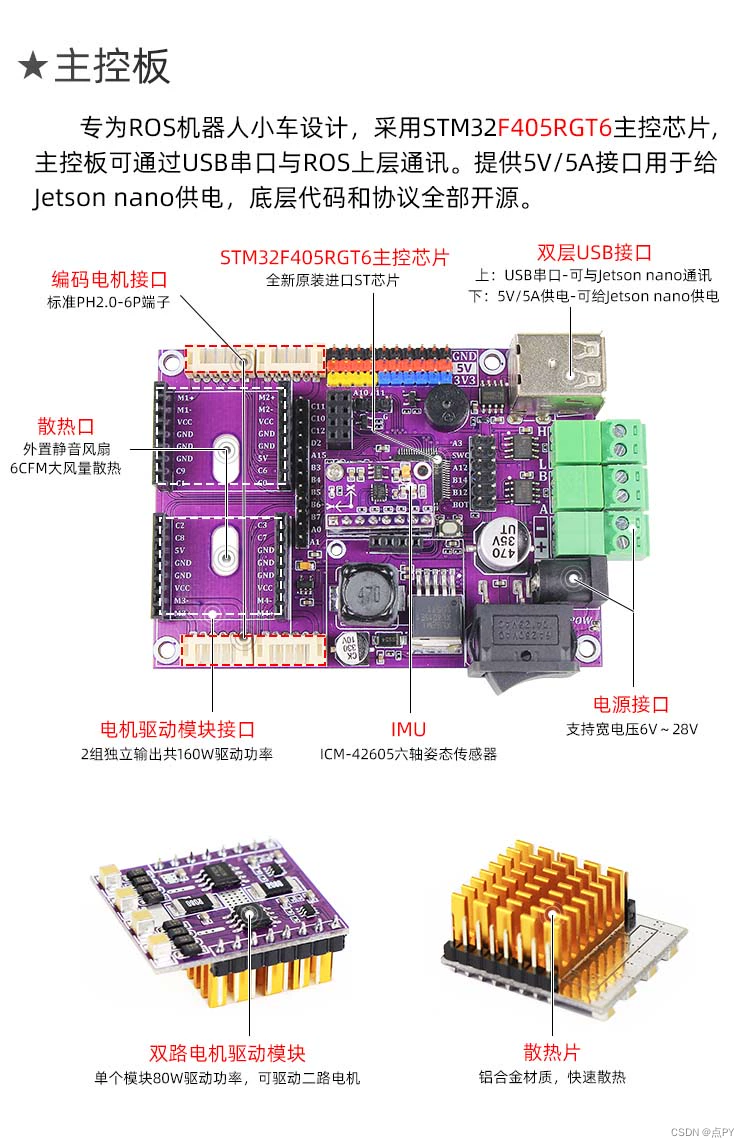
那 ES 是怎么来解决搜索问题的呢?我们来举个例子说明一下,假设我们有这样两个商品,一个是烟台红富士苹果,一个是苹果手机 iPhone XS Max。
这个表里面的 DOCID 就是唯一标识一条记录的 ID,和数据库里面的主键是类似的。
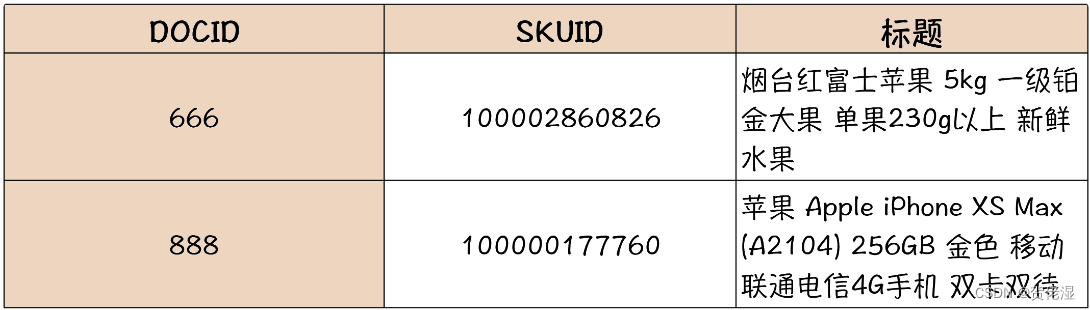
为了能够支持快速地全文搜索,ES 中对于文本采用了一种特殊的索引:倒排索引(Inverted Index)。那我们看一下在 ES 中,这两条商品数据倒排索引长什么样?请看下面这个表。
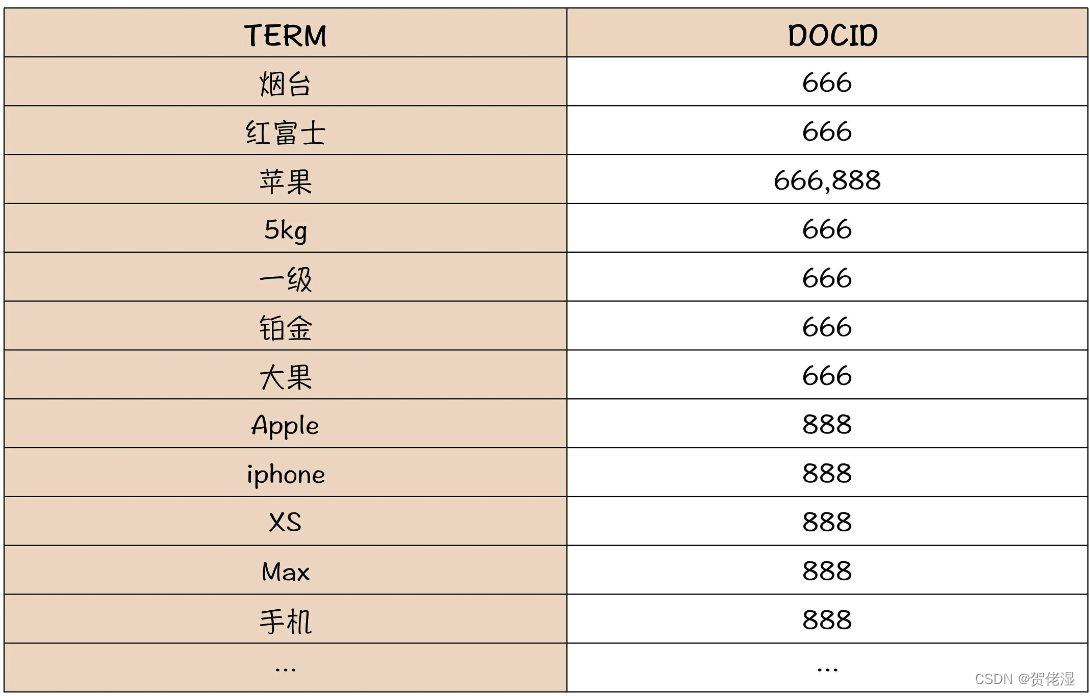
可以看到,这个倒排索引的表,它是以单词作为索引的 Key,然后每个单词的倒排索引的值是一个列表,这个列表的元素就是含有这个单词的商品记录的 DOCID。
这个倒排索引怎么构建的呢?
当我们往 ES 写入商品记录的时候,ES 会先对需要搜索的字段,也就是商品标题进行分词。分词就是把一段连续的文本按照语义拆分成多个单词。然后 ES 按照单词来给商品记录做索引,就形成了上面那个表一样的倒排索引。
当我们搜索关键字“苹果手机”的时候,ES 会对关键字也进行分词,比如说,“苹果手机”被分为“苹果”和“手机”。然后,ES 会在倒排索引中去搜索我们输入的每个关键字分词,搜索结果应该是:

666 和 888 这两条记录都能匹配上搜索的关键词,但是 888 这个商品比 666 这个商品匹配度更高,因为它两个单词都能匹配上,所以按照匹配度把结果做一个排序,最终返回的搜索结果就是:
苹果Apple iPhone XS Max (A2104) 256GB 金色 移动联通电信 4G手机双卡双待
烟台红富士苹果5kg 一级铂金大果 单果 230g 以上 新鲜水果
看起来搜索的效果还是不错的。
为什么倒排索引可以做到快速搜索?我们一起来分析一下上面这个例子的查找性能。
这个搜索过程,其实就是对上面的倒排索引做了二次查找,一次找“苹果”,一次找“手机”。注意,整个搜索过程中,我们没有做过任何文本的模糊匹配。ES 的存储引擎存储倒排索引时,肯定不是像我们上面表格中展示那样存成一个二维表,实际上它的物理存储结构和 MySQL 的 InnoDB 的索引是差不多的,都是一颗查找树。
对倒排索引做两次查找,也就是对树进行二次查找,它的时间复杂度,类似于 MySQL 中的二次命中索引的查找。显然,这个查找速度,比用 MySQL 全表扫描加上模糊匹配的方式,要快好几个数量级。
如何在 ES 中构建商品的索引?
理解了倒排索引的原理之后,我们一起用 ES 构建一个商品索引,简单实现一个商品搜索系统。虽然 ES 是为搜索而生的,但本质上,它仍然是一个存储系统。ES 里面的一些概念,基本上都可以在关系数据库中找到对应的名词,为了便于你快速理解这些概念,我把这些概念的对应关系列出来,你可以对照理解。
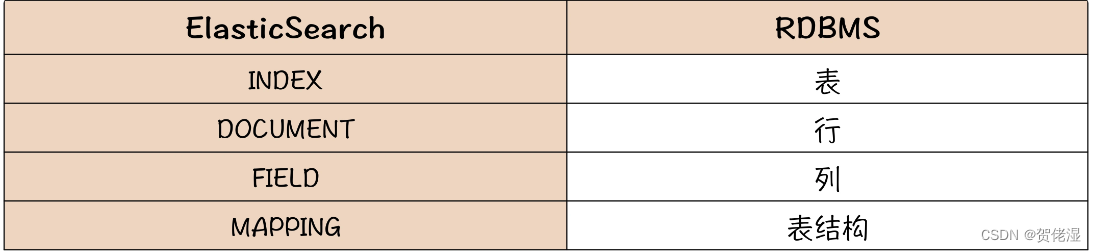
在 ES 里面,数据的逻辑结构类似于 MongoDB,每条数据称为一个 DOCUMENT,简称 DOC。DOC 就是一个 JSON 对象,DOC 中的每个 JSON 字段,在 ES 中称为 FIELD,把一组具有相同字段的 DOC 存放在一起,存放它们的逻辑容器叫 INDEX,这些 DOC 的 JSON 结构称为 MAPPING。这里面最不好理解的就是这个 INDEX,它实际上类似于 MySQL 中表的概念,而不是我们通常理解的用于查找数据的索引。
ES 是一个用 Java 开发的服务端程序,除了 Java 以外就没有什么外部依赖了,安装部署都非常简单,具体你可以参照它的官方文档先把 ES 安装好,也可以参考我的ELK教程安装好ES。
另外,为了能让 ES 支持中文分词,需要给 ES 安装一个中文的分词插件IK Analysis for Elasticsearch,这个插件的作用就是告诉 ES 怎么对中文文本进行分词。
为了能实现商品搜索,我们需要先把商品信息存放到 ES 中,首先我们先定义存放在 ES 中商品的数据结构,也就是 MAPPING。

我们这个 MAPPING 只要两个字段就够了,sku_id 就是商品 ID,title 保存商品的标题,当用户在搜索商品的时候,我们在 ES 中来匹配商品标题,返回符合条件商品的 sku_id 列表。
ES 默认提供了标准的 RESTful 接口,不需要客户端,直接使用 HTTP 协议就可以访问,可以使用curl通过命令行来操作 ES。
接下来我们使用上面这个 MAPPING 创建 INDEX,类似于 MySQL 中创建一个表。
curl -X PUT "localhost:9200/sku" -H 'Content-Type: application/json' -d '{
"mappings": {
"properties": {
"sku_id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}'
{"acknowledged":true,"shards_acknowledged":true,"index":"sku"}这里面,使用 PUT 方法创建一个 INDEX,INDEX 的名称是“sku”,直接写在请求的 URL 中。请求的 BODY 是一个 JSON 对象,内容就是我们上面定义的 MAPPING,也就是数据结构。这里面需要注意一下,由于我们要在 title 这个字段上进行全文搜索,所以我们把数据类型定义为 text,并指定使用我们刚刚安装的中文分词插件 IK 作为这个字段的分词器。
创建好 INDEX 之后,就可以往 INDEX 中写入商品数据,插入数据需要使用 HTTP POST 方法:
curl -X POST "localhost:9200/sku/_doc/" -H 'Content-Type: application/json' -d '{
"sku_id": 100002860826,
"title": "烟台红富士苹果 5kg 一级铂金大果 单果230g以上 新鲜水果"
}'
{"_index":"sku","_type":"_doc","_id":"yxQVSHABiy2kuAJG8ilW","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}
curl -X POST "localhost:9200/sku/_doc/" -H 'Content-Type: application/json' -d '{
"sku_id": 100000177760,
"title": "苹果 Apple iPhone XS Max (A2104) 256GB 金色 移动联通电信4G手机 双卡双待"
}'
{"_index":"sku","_type":"_doc","_id":"zBQWSHABiy2kuAJGgim1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":1,"_primary_term":1}这里面我们插入了两条商品数据,一个烟台红富士,一个 iPhone 手机。然后就可以直接进行商品搜索了,搜索使用 HTTP GET 方法。
curl -X GET 'localhost:9200/sku/_search?pretty' -H 'Content-Type: application/json' -d '{
"query" : { "match" : { "title" : "苹果手机" }}
}'
{
"took" : 23,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.8594865,
"hits" : [
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "zBQWSHABiy2kuAJGgim1",
"_score" : 0.8594865,
"_source" : {
"sku_id" : 100000177760,
"title" : "苹果 Apple iPhone XS Max (A2104) 256GB 金色 移动联通电信4G手机 双卡双待"
}
},
{
"_index" : "sku",
"_type" : "_doc",
"_id" : "yxQVSHABiy2kuAJG8ilW",
"_score" : 0.18577608,
"_source" : {
"sku_id" : 100002860826,
"title" : "烟台红富士苹果 5kg 一级铂金大果 单果230g以上 新鲜水果"
}
}
]
}
}我们先看一下请求中的 URL,其中的“sku”代表要在 sku 这个 INDEX 内进行查找,“_search”是一个关键字,表示要进行搜索,参数 pretty 表示格式化返回的 JSON,这样方便阅读。再看一下请求 BODY 的 JSON,query 中的 match 表示要进行全文匹配,匹配的字段就是 title,关键字是“苹果手机”。
可以看到,在返回结果中,匹配到了 2 条商品记录,和我们在前面讲解倒排索引时,预期返回的结果是一致的。
回顾一下使用 ES 构建商品搜索服务的整个过程:首先安装 ES 并启动服务,然后创建一个 INDEX,定义 MAPPING,写入数据后,执行查询并返回查询结果,其实,这个过程和我们使用数据库时,先建表、插入数据然后查询的过程,就是一样的。所以,你就把 ES 当做一个支持全文搜索的数据库来使用就行了。
总结
ES 本质上是一个支持全文搜索的分布式内存数据库,特别适合用于构建搜索系统。ES 之所以能有非常好的全文搜索性能,最重要的原因就是采用了倒排索引。
倒排索引是一种特别为搜索而设计的索引结构,倒排索引先对需要索引的字段进行分词,然后以分词为索引组成一个查找树,这样就把一个全文匹配的查找转换成了对树的查找,这是倒排索引能够快速进行搜索的根本原因。
但是,倒排索引相比于一般数据库采用的 B 树索引,它的写入和更新性能都比较差,因此倒排索引也只是适合全文搜索,不适合更新频繁的交易类数据。
感谢阅读,如果你觉得这篇文章对你有一些启发,也欢迎把它分享给你的朋友。
思考题
订单数据越来越多,数据库越来越慢该怎么办?
期待、欢迎你留言或在线联系,与我一起讨论交流,“一起学习,一起成长”。
上一篇文章
电商系统架构设计系列(六):电商的「账户系统」设计要特别考虑哪些问题?
推荐阅读
- 技术破局,业绩狂飙十倍:亿级电商平台重构大揭秘
- 当我们聊高并发时,到底是在聊什么?如何真正地掌握高并发设计能力?
- 微服务架构实战 - 我的经验分享总结2019(系统架构师)架构演进过程-从信息流架构到电商中台架构
系列分享
- Elasticsearch教程
- 微服务架构实战
- 架构思维成长系列
- 电商系统架构设计系列
------------------------------------------------------
------------------------------------------------------
我的CSDN主页
关于我(个人域名,更多我的信息)
我的开源项目集Github
期望和大家 一起学习,一起成长,共勉,O(∩_∩)O谢谢
如果你有任何建议,或想学习的知识,可与我一起讨论交流
欢迎交流问题,可加个人QQ 469580884,
或者,加我的群号 751925591,一起探讨交流问题
不讲虚的,只做实干家
Talk is cheap,show me the code