一、问题描述
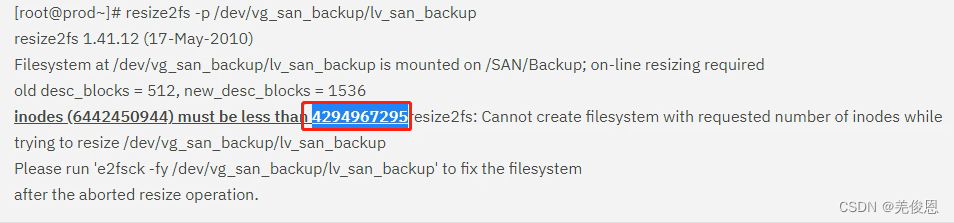
某次在线环境,存储使用率告警在线扩容时,文件系统扩容失败,报错如下:

Size of logical volume sihua/video changed from <162.00 TiB (42467321 extents) to <258.00 TiB (67633142 extents).
Logical volume sihua/video successfully resized.
resize2fs 1.42.9 (28-Dec-2013)
Filesystem at /dev/mapper/sihua-video is mounted on /video; on-line resizing required
old_desc_blocks = 20736, new_desc_blocks = 33024
resize2fs: Invalid argument While checking for on-line resizing support
fsadm: ext4 resize failed.
/usr/sbin/fsadm failed: 1
环境:resize2fs 1.42.9 (28-Dec-2013);内核:3.10.0-1160.25.1.el7.x86_64
OS:CentOS Linux release 7.9.2009 (Core)
二、问题分析处理
1、查看日志:
查看/var/log/messages,日志中提到文件系统扩展可能会导致i节点数溢出,即超过最大限制,因此resize2fs操作被放弃。

Dec 12 19:04:59 zq-sihua-63-cms kernel: EXT4-fs warning (device dm-0): ext4_resize_fs:1921: resize would cause inodes_count overflow
Dec 12 19:04:59 zq-sihua-63-cms kernel: EXT4-fs warning (device dm-0): ext4_group_extend:1744: can't shrink FS - resize aborted
Dec 12 19:07:09 zq-sihua-63-cms kernel: EXT4-fs warning (device dm-0): ext4_resize_fs:1921: resize would cause inodes_count overflow
Dec 12 19:07:09 zq-sihua-63-cms kernel: EXT4-fs warning (device dm-0): ext4_group_extend:1744: can't shrink(伸缩) FS - resize aborted
#跟踪resize2fs命令
strace -o /tmp/resize.strace resize2fs /dev/mapper/sihua-video
#debug模式运行
resize2fs -d /dev/mapper/sihua-video
相关资料:
2、检查lv的当前inode情况:
dumpe2fs -h /dev/mapper/sihua-video | grep node //输出如下
dumpe2fs 1.42.9 (28-Dec-2013)
Inode count: 2717908992
Free inodes: 2717908981
Inodes per group: 2048
Inode blocks per group: 128
First inode: 11
Inode size: 256
Journal inode: 8
First orphan inode: 503980036
Journal backup: inode blocks
#以下命令只能卸载文件系统情况下进行
e2fsck -vp /dev/mapper/sihua-video
#
resize2fs -d 32 /dev/mapper/sihua-video
resize2fs 1.42.9 (28-Dec-2013)
fs has 11 inodes, 1 groups required.
fs requires 32773 data blocks.
With 1 group(s), we have 28285 blocks available.
Added 1 extra group(s), data_needed 34693, data_blocks 56570, last_start 28285
Last group's overhead is 4483
Need 6408 data blocks in last group
Final size of last group is 10891
Estimated blocks needed: 43659
Extents safety margin: 86972986
Filesystem at /dev/mapper/sihua-video is mounted on /video; on-line resizing required
old_desc_blocks = 20736, new_desc_blocks = 33024
resize2fs: Invalid argument While checking for on-line resizing support
#
tune2fs -l /dev/mapper/sihua-video
tune2fs 1.42.9 (28-Dec-2013)
Filesystem volume name: <none>
Last mounted on: /www
Filesystem UUID: 7c2f6ed2-d3bf-4d6a-aa75-5d457235d73c
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr dir_index filetype needs_recovery meta_bg extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 2717908992
Block count: 43486536704
Reserved block count: 1830694921
Free blocks: 43313818078
Free inodes: 2717908981
First block: 0
Block size: 4096 //即4k
Fragment size: 4096
Group descriptor size: 64
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 2048
Inode blocks per group: 128
First meta block group: 4352
Flex block group size: 16
Filesystem created: Sat Jul 16 19:43:29 2022
Last mount time: Sat Jul 16 19:44:45 2022
Last write time: Sat Jul 16 19:44:45 2022
Mount count: 1
Maximum mount count: -1
Last checked: Sat Jul 16 19:43:29 2022
Check interval: 0 (<none>)
Lifetime writes: 197 MB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
First orphan inode: 503980036
Default directory hash: half_md4
Directory Hash Seed: cde24d29-a605-4ffb-baf8-db9d578dc9f9
Journal backup: inode blocks
注:
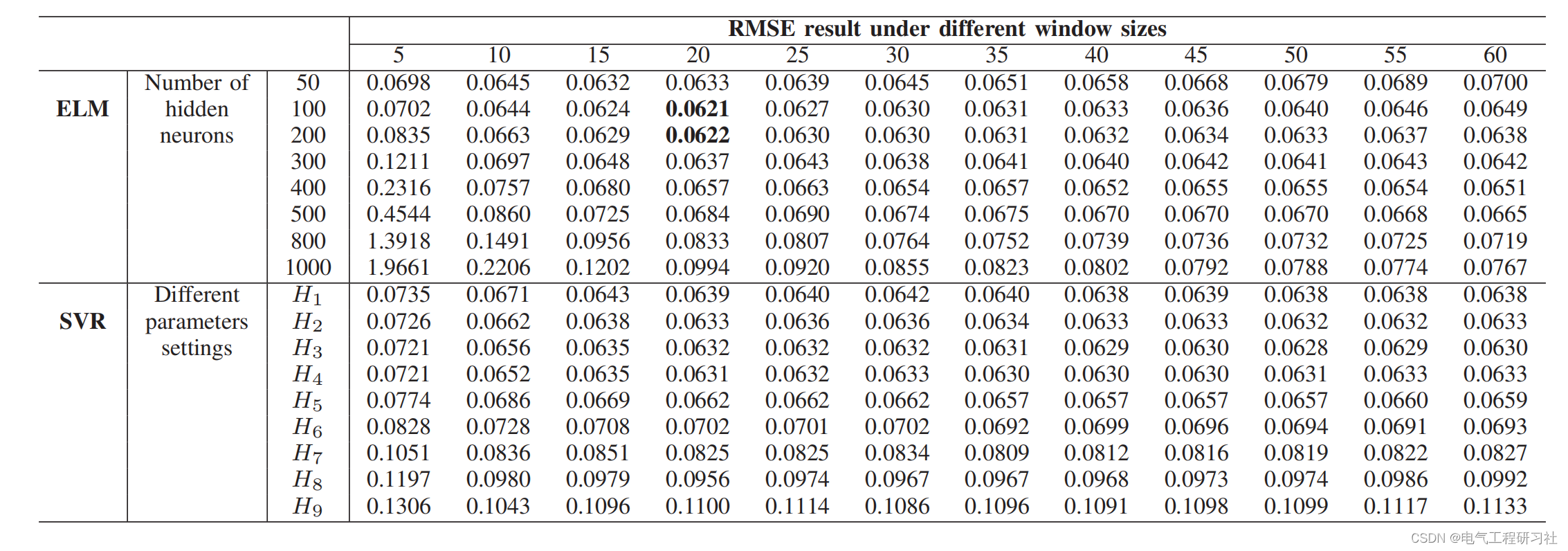
bytes-per-inodes=“block count” x “block size” / “inode count”=65535.98919753086
“maximum size” = 2^32 * “bytes-per-inode”=255T ,而本项目258T,超过了最大大小
3、停服缩容后再扩文件系统
1)umount /dev/mapper/sihua-video /video ##卸载文件系统
2)e2fsck -f /dev/mapper/sihua-video ##检测文件系统一致性,必须在文件系统离线/卸载后才能检测
3 lvreduce -L -5G /dev/mapper/sihua-video ##将当前lv大小缩小/释放1G空间
4)mount /dev/mapper/sihua-video /video ##回挂文件系统
5) resize2fs -d /dev/mapper/sihua-video
4、其他
#fuser安装
yum install -y psmisc
# 文件系统IO错误修复
e2fsck -fy /dev/mapper/sihua-video
e2fsck: unable to set superblock flags on /dev/sihua/video
/dev/sihua/video: ***** FILE SYSTEM WAS MODIFIED *****
/dev/sihua/video: ********** WARNING: Filesystem still has errors **********
三、附录
3.1、ext4 vs ext3
ext3 和 ext4 有一些非常明确的差别, ext4 特地设计为尽可能地向后兼容 ext3。这不仅允许 ext3 文件系统原地升级到 ext4;也允许 ext4 驱动程序以 ext3 模式自动挂载 ext3 文件系统,因此使它无需单独维护两个代码库。
Ext3:ext3 文件系统使用 32 位寻址,这限制它仅支持 2 TiB 文件大小和 16 TiB 文件系统系统大小(这是假设在块大小为 4 KiB 的情况下,一些 ext3 文件系统使用更小的块大小,因此对其进一步被限制);ext3 仅限于 32000 个子目录;ext3 没有对日志进行校验,这给处于内核直接控制之外的磁盘或自带缓存的控制器设备带来了问题。如果控制器或具自带缓存的磁盘脱离了写入顺序,则可能会破坏 ext3 的日记事务顺序,从而可能破坏在崩溃期间(或之前一段时间)写入的文件。ext3 提供粒度为一秒的时间戳。虽然足以满足大多数用途,但任务关键型应用程序经常需要更严格的时间控制。
Ext4:ext4 使用 48 位的内部寻址,理论上可以在文件系统上分配高达 16 TiB 大小的文件,其中文件系统大小最高可达 1000000 TiB(1 EiB)。在早期 ext4 的实现中有些用户空间的程序仍然将其限制为最大大小为 16 TiB 的文件系统,但截至 2011 年,e2fsprogs 已经直接支持大于 16 TiB 大小的 ext4 文件系统。例如,红帽企业 Linux 在其合同上仅支持最高 50 TiB 的 ext4 文件系统,并建议 ext4 卷不超过 100 TiB。虽然 ext4 可以处理高达 1 EiB 大小(相当于 1,000,000 TiB)大小的数据,但你 真的 不应该尝试这样做。除了能够记住更多块的地址之外,还存在规模上的问题。并且现在 ext4 不会处理(并且可能永远不会)超过 50-100 TiB 的数据。如果数据已经在磁盘上被破坏,ext4 无法检测或修复这种损坏。
ext4 在将存储块写入磁盘之前对存储块的分配方式进行了大量改进,这可以显著提高读写性能。 (extent)是一系列连续的物理块 (最多达 128 MiB,假设块大小为 4 KiB),可以一次性保留和寻址。使用区段可以减少给定文件所需的 inode 数量,并显著减少碎片并提高写入大文件时的性能。ext3 为每一个新分配的块调用一次块分配器。当多个写入同时打开分配器时,很容易导致严重的碎片。然而,ext4 使用延迟分配,这允许它合并写入并更好地决定如何为尚未提交的写入分配块。ext4 允许无限数量的子目录。从 2.6.23 内核版本开始,ext4 使用 HTree 索引来减少大量子目录的性能损失。在 ext3 下,在 fsck 被调用时会检查整个文件系统 —— 包括已删除或空文件。相比之下,ext4 标记了 inode 表未分配的块和扇区,从而允许 fsck 完全跳过它们。这大大减少了在大多数文件系统上运行 fsck 的时间,它实现于内核 2.6.24。ext4 通过提供纳秒级的时间戳,使其可用于那些企业、科学以及任务关键型的应用程序。ext4 通过 e4defrag 可实现在线碎片管理,且是一个在线、内核模式、文件系统感知、块和区段级别的碎片整理实用程序。
在持久预分配方面,在为文件预分配磁盘空间时,大部分文件系统必须在创建时将零写入该文件的块中。ext4 允许替代使用 fallocate(),它保证了空间的可用性(并试图为它找到连续的空间),而不需要先写入它。这显著提高了写入和将来读取流和数据库应用程序的写入数据的性能。另外,ext4新增延迟分配特性,这允许 ext4 等待分配将写入数据的实际块,直到它准备好将数据提交到磁盘。(相比之下,即使数据仍然在往写入缓存中写入,ext3 也会立即分配块。)当缓存中的数据累积时,延迟分配块允许文件系统对如何分配块做出更好的选择,降低碎片(写入,以及稍后的读)并显著提升性能。然而不幸的是,它 增加 了还没有专门调用 fsync() 方法(当程序员想确保数据完全刷新到磁盘时)的程序的数据丢失的可能性。注意:保证数据立即写入磁盘的唯一方法是正确调用 fsync()。
由于 ext4 具有冗余超级块,因此为文件系统校验其中的元数据提供了一种方法,可以自行确定主超级块是否已损坏并需要使用备用块。可以在没有校验和的情况下,从损坏的超级块恢复 —— 但是用户首先需要意识到它已损坏,然后尝试使用备用方法手动挂载文件系统。由于在某些情况下,使用损坏的主超级块安装文件系统读写可能会造成进一步的损坏,即使是经验丰富的用户也无法避免,这也不是一个完美的解决方案!
与 Btrfs 或 ZFS 等下一代文件系统提供的极其强大的每块校验和相比,ext4 的元数据校验和的功能非常弱。
3.2、XFS
XFS 与非 ext 文件系统在 Linux 中的主线中的地位一样。它是一个 64 位的日志文件系统,自 2001 年以来内置于 Linux 内核中,为大型文件系统和高度并发性提供了高性能(即大量的进程都会立即写入文件系统)。
从 RHEL 7 开始,XFS 成为 Red Hat Enterprise Linux 的默认文件系统。对于家庭或小型企业用户来说,它仍然有一些缺点 —— 最值得注意的是,重新调整现有 XFS 文件系统是一件非常痛苦的事情,不如创建另一个并复制数据更有意义。
虽然 XFS 是稳定的且是高性能的,但它和 ext4 之间没有足够具体的最终用途差异,以值得推荐在非默认(如 RHEL7)的任何地方使用它,除非它解决了对 ext4 的特定问题,例如大于 50 TiB 容量的文件系统。
XFS 在任何方面都不是 ZFS、Btrfs 甚至 WAFL(一个专有的 SAN 文件系统)的“下一代”文件系统。就像 ext4 一样,它应该被视为一种更好的方式的权宜之计。
注:xfs千万不要收缩空间,可能导致数据丢失。
![[附源码]计算机毕业设计付费自习室管理小程序Springboot程序](https://img-blog.csdnimg.cn/1cee4fd785f546eb92e20b403a2a4b4d.png)









![[附源码]JAVA毕业设计英语课程学习网站(系统+LW)](https://img-blog.csdnimg.cn/232092a2d6204ef0bccceb28b1df6956.png)