前言
Redis是目前最火爆的内存数据库之一,通过在内存中读写数据,大大提高了读写速度,可以说Redis是实现网站高并发不可或缺的一部分。
我们使用Redis时,会接触Redis的5种对象类型(字符串、哈希、列表、集合、有序集合),丰富的类型是Redis相对于Memcached等的一大优势。在了解Redis的5种对象类型的用法和特点的基础上,进一步了解Redis的内存模型,对Redis的使用有很大帮助,例如:
1、估算Redis内存使用量。目前为止,内存的使用成本仍然相对较高,使用内存不能无所顾忌;根据需求合理的评估Redis的内存使用量,选择合适的机器配置,可以在满足需求的情况下节约成本。
2、优化内存占用。了解Redis内存模型可以选择更合适的数据类型和编码,更好的利用Redis内存。
3、分析解决问题。当Redis出现阻塞、内存占用等问题时,尽快发现导致问题的原因,便于分析解决问题。
这篇文章主要介绍Redis的内存模型(以3.0为例),包括Redis占用内存的情况及如何查询、不同的对象类型在内存中的编码方式、内存分配器(jemalloc)、简单动态字符串(SDS)、RedisObject等;然后在此基础上介绍几个Redis内存模型的应用。
一、Redis内存统计
工欲善其事必先利其器,在说明Redis内存之前首先说明如何统计Redis使用内存的情况。
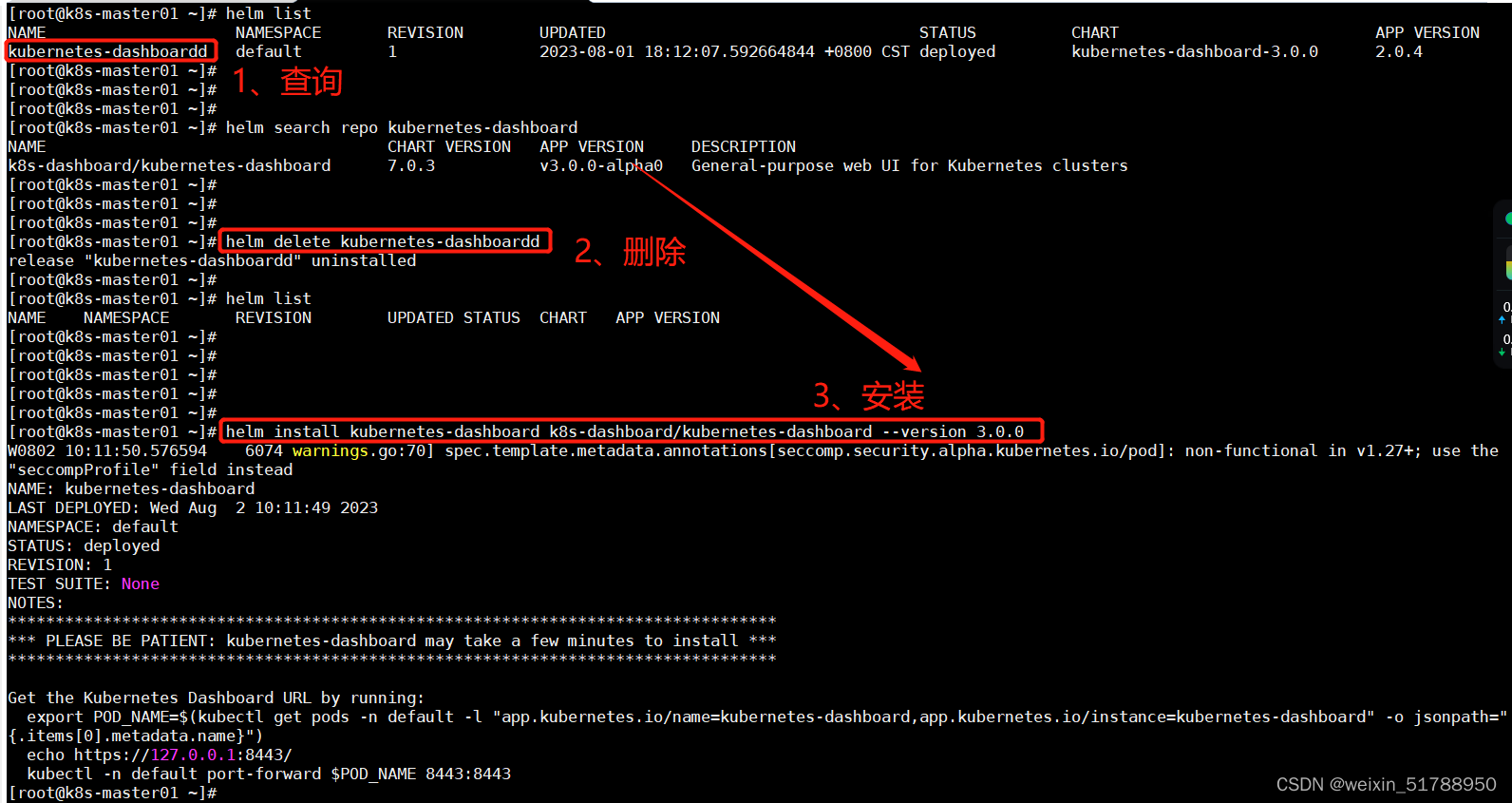
在客户端通过redis-cli连接服务器后(后面如无特殊说明,客户端一律使用redis-cli),通过info命令可以查看内存使用情况:
| 1 |
|

其中,info命令可以显示redis服务器的许多信息,包括服务器基本信息、CPU、内存、持久化、客户端连接信息等等;memory是参数,表示只显示内存相关的信息。
返回结果中比较重要的几个说明如下:
(1)used_memory:Redis分配器分配的内存总量(单位是字节),包括使用的虚拟内存(即swap);Redis分配器后面会介绍。used_memory_human只是显示更友好。
(2)used_memory_rss:Redis进程占据操作系统的内存(单位是字节),与top及ps命令看到的值是一致的;除了分配器分配的内存之外,used_memory_rss还包括进程运行本身需要的内存、内存碎片等,但是不包括虚拟内存。
因此,used_memory和used_memory_rss,前者是从Redis角度得到的量,后者是从操作系统角度得到的量。二者之所以有所不同,一方面是因为内存碎片和Redis进程运行需要占用内存,使得前者可能比后者小,另一方面虚拟内存的存在,使得前者可能比后者大。
由于在实际应用中,Redis的数据量会比较大,此时进程运行占用的内存与Redis数据量和内存碎片相比,都会小得多;因此used_memory_rss和used_memory的比例,便成了衡量Redis内存碎片率的参数;这个参数就是mem_fragmentation_ratio。
(3)mem_fragmentation_ratio:内存碎片比率,该值是used_memory_rss / used_memory的比值。
mem_fragmentation_ratio一般大于1,且该值越大,内存碎片比例越大。mem_fragmentation_ratio<1,说明Redis使用了虚拟内存,由于虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。
一般来说,mem_fragmentation_ratio在1.03左右是比较健康的状态(对于jemalloc来说);上面截图中的mem_fragmentation_ratio值很大,是因为还没有向Redis中存入数据,Redis进程本身运行的内存使得used_memory_rss 比used_memory大得多。
(4)mem_allocator:Redis使用的内存分配器,在编译时指定;可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc;截图中使用的便是默认的jemalloc。
二、Redis内存划分
Redis作为内存数据库,在内存中存储的内容主要是数据(键值对);通过前面的叙述可以知道,除了数据以外,Redis的其他部分也会占用内存。
Redis的内存占用主要可以划分为以下几个部分:
1、数据
作为数据库,数据是最主要的部分;这部分占用的内存会统计在used_memory中。
Redis使用键值对存储数据,其中的值(对象)包括5种类型,即字符串、哈希、列表、集合、有序集合。这5种类型是Redis对外提供的,实际上,在Redis内部,每种类型可能有2种或更多的内部编码实现;此外,Redis在存储对象时,并不是直接将数据扔进内存,而是会对对象进行各种包装:如redisObject、SDS等;这篇文章后面将重点介绍Redis中数据存储的细节。
2、进程本身运行需要的内存
Redis主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
补充说明:除了主进程外,Redis创建的子进程运行也会占用内存,如Redis执行AOF、RDB重写时创建的子进程。当然,这部分内存不属于Redis进程,也不会统计在used_memory和used_memory_rss中。
3、缓冲内存
缓冲内存包括客户端缓冲区、复制积压缓冲区、AOF缓冲区等;其中,客户端缓冲存储客户端连接的输入输出缓冲;复制积压缓冲用于部分复制功能;AOF缓冲区用于在进行AOF重写时,保存最近的写入命令。在了解相应功能之前,不需要知道这些缓冲的细节;这部分内存由jemalloc分配,因此会统计在used_memory中。
4、内存碎片
内存碎片是Redis在分配、回收物理内存过程中产生的。例如,如果对数据的更改频繁,而且数据之间的大小相差很大,可能导致redis释放的空间在物理内存中并没有释放,但redis又无法有效利用,这就形成了内存碎片。内存碎片不会统计在used_memory中。
内存碎片的产生与对数据进行的操作、数据的特点等都有关;此外,与使用的内存分配器也有关系:如果内存分配器设计合理,可以尽可能的减少内存碎片的产生。后面将要说到的jemalloc便在控制内存碎片方面做的很好。
如果Redis服务器中的内存碎片已经很大,可以通过安全重启的方式减小内存碎片:因为重启之后,Redis重新从备份文件中读取数据,在内存中进行重排,为每个数据重新选择合适的内存单元,减小内存碎片。
三、Redis数据存储的细节
1、概述
关于Redis数据存储的细节,涉及到内存分配器(如jemalloc)、简单动态字符串(SDS)、5种对象类型及内部编码、redisObject。在讲述具体内容之前,先说明一下这几个概念之间的关系。
下图是执行set hello world时,所涉及到的数据模型。

图片来源:https://searchdatabase.techtarget.com.cn/7-20218/
(1)dictEntry:Redis是Key-Value数据库,因此对每个键值对都会有一个dictEntry,里面存储了指向Key和Value的指针;next指向下一个dictEntry,与本Key-Value无关。
(2)Key:图中右上角可见,Key(”hello”)并不是直接以字符串存储,而是存储在SDS结构中。
(3)redisObject:Value(“world”)既不是直接以字符串存储,也不是像Key一样直接存储在SDS中,而是存储在redisObject中。实际上,不论Value是5种类型的哪一种,都是通过redisObject来存储的;而redisObject中的type字段指明了Value对象的类型,ptr字段则指向对象所在的地址。不过可以看出,字符串对象虽然经过了redisObject的包装,但仍然需要通过SDS存储。
实际上,redisObject除了type和ptr字段以外,还有其他字段图中没有给出,如用于指定对象内部编码的字段;后面会详细介绍。
(4)jemalloc:无论是DictEntry对象,还是redisObject、SDS对象,都需要内存分配器(如jemalloc)分配内存进行存储。以DictEntry对象为例,有3个指针组成,在64位机器下占24个字节,jemalloc会为它分配32字节大小的内存单元。
下面来分别介绍jemalloc、redisObject、SDS、对象类型及内部编码。
2、jemalloc
Redis在编译时便会指定内存分配器;内存分配器可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc。
jemalloc作为Redis的默认内存分配器,在减小内存碎片方面做的相对比较好。jemalloc在64位系统中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;当Redis存储数据时,会选择大小最合适的内存块进行存储。
jemalloc划分的内存单元如下图所示:

图片来源:http://blog.csdn.net/zhengpeitao/article/details/76573053
例如,如果需要存储大小为130字节的对象,jemalloc会将其放入160字节的内存单元中。
3、redisObject
前面说到,Redis对象有5种类型;无论是哪种类型,Redis都不会直接存储,而是通过redisObject对象进行存储。
redisObject对象非常重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要redisObject支持,下面将通过redisObject的结构来说明它是如何起作用的。
redisObject的定义如下(不同版本的Redis可能稍稍有所不同):
| 1 2 3 4 5 6 7 |
|
redisObject的每个字段的含义和作用如下:
(1)type
type字段表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
当我们执行type命令时,便是通过读取RedisObject的type字段获得对象的类型;如下图所示:

(2)encoding
encoding表示对象的内部编码,占4个比特。
对于Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码。通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵活性和效率。以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
通过object encoding命令,可以查看对象采用的编码方式,如下图所示:

5种对象类型对应的编码方式以及使用条件,将在后面介绍。
(3)lru
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
通过对比lru时间与当前时间,可以计算某个对象的空转时间;object idletime命令可以显示该空转时间(单位是秒)。object idletime命令的一个特殊之处在于它不改变对象的lru值。

lru值除了通过object idletime命令打印之外,还与Redis的内存回收有关系:如果Redis打开了maxmemory选项,且内存回收算法选择的是volatile-lru或allkeys—lru,那么当Redis内存占用超过maxmemory指定的值时,Redis会优先选择空转时间最长的对象进行释放。
(4)refcount
refcount与共享对象
refcount记录的是该对象被引用的次数,类型为整型,占4个字节。refcount的作用,主要在于对象的引用计数和内存回收。当创建新对象时,refcount初始化为1;当有新程序使用该对象时,refcount加1;当对象不再被一个新程序使用时,refcount减1;当refcount变为0时,对象占用的内存会被释放。
Redis中被多次使用的对象(refcount>1),称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。
共享对象的具体实现
Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为O(1);对于普通字符串,判断复杂度为O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)。
就目前的实现来说,Redis服务器在初始化时,会创建10000个字符串对象,值分别是0~9999的整数值;当Redis需要使用值为0~9999的字符串对象时,可以直接使用这些共享对象。10000这个数字可以通过调整参数REDIS_SHARED_INTEGERS(4.0中是OBJ_SHARED_INTEGERS)的值进行改变。
共享对象的引用次数可以通过object refcount命令查看,如下图所示。命令执行的结果页佐证了只有0~9999之间的整数会作为共享对象。

(5)ptr
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。ptr指针占据的字节数与系统有关,例如64位系统中占8个字节。
(6)总结
综上所述,redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;在64位系统中,一个redisObject对象的大小为16字节:
4bit+4bit+24bit+4Byte+8Byte=16Byte。
4、SDS
Redis没有直接使用C字符串(即以空字符’\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS。SDS是简单动态字符串(Simple Dynamic String)的缩写。
(1)SDS结构
sds的结构如下:
| 1 2 3 4 5 |
|
其中,buf表示字节数组,用来存储字符串;len表示buf已使用的长度,free表示buf未使用的长度。下面是两个例子。


图片来源:《Redis设计与实现》
通过SDS的结构可以看出,buf数组的长度=free+len+1(其中1表示字符串结尾的空字符);所以,一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
(2)SDS与C字符串的比较
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
- 获取字符串长度:SDS是O(1),C字符串是O(n)
- 缓冲区溢出:使用C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
- 修改字符串时内存的重分配:对于C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化:空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
- 存取二进制数据:SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS以字符串长度len来作为字符串结束标识,因此没有这个问题。
此外,由于SDS中的buf仍然使用了C字符串(即以’\0’结尾),因此SDS可以使用C字符串库中的部分函数;但是需要注意的是,只有当SDS用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’\0’不一定是结尾)。
(3)SDS与C字符串的应用
Redis在存储对象时,一律使用SDS代替C字符串。例如set hello world命令,hello和world都是以SDS的形式存储的。而sadd myset member1 member2 member3命令,不论是键(”myset”),还是集合中的元素(”member1”、 ”member2”和”member3”),都是以SDS的形式存储。除了存储对象,SDS还用于存储各种缓冲区。
只有在字符串不会改变的情况下,如打印日志时,才会使用C字符串。
四、Redis的对象类型与内部编码
前面已经说过,Redis支持5种对象类型,而每种结构都有至少两种编码;这样做的好处在于:一方面接口与实现分离,当需要增加或改变内部编码时,用户使用不受影响,另一方面可以根据不同的应用场景切换内部编码,提高效率。
Redis各种对象类型支持的内部编码如下图所示(图中版本是Redis3.0,Redis后面版本中又增加了内部编码,略过不提;本章所介绍的内部编码都是基于3.0的):

图片来源:《Redis设计与实现》
关于Redis内部编码的转换,都符合以下规律:编码转换在Redis写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存编码转换。
1、字符串
(1)概况
字符串是最基础的类型,因为所有的键都是字符串类型,且字符串之外的其他几种复杂类型的元素也是字符串。
字符串长度不能超过512MB。
(2)内部编码
字符串类型的内部编码有3种,它们的应用场景如下:
- int:8个字节的长整型。字符串值是整型时,这个值使用long整型表示。
- embstr:<=39字节的字符串。embstr与raw都使用redisObject和sds保存数据,区别在于,embstr的使用只分配一次内存空间(因此redisObject和sds是连续的),而raw需要分配两次内存空间(分别为redisObject和sds分配空间)。因此与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。
- raw:大于39个字节的字符串
示例如下图所示:

embstr和raw进行区分的长度,是39;是因为redisObject的长度是16字节,sds的长度是9+字符串长度;因此当字符串长度是39时,embstr的长度正好是16+9+39=64,jemalloc正好可以分配64字节的内存单元。
(3)编码转换
当int数据不再是整数,或大小超过了long的范围时,自动转化为raw。
而对于embstr,由于其实现是只读的,因此在对embstr对象进行修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了39个字节。示例如下图所示:

2、列表
(1)概况
列表(list)用来存储多个有序的字符串,每个字符串称为元素;一个列表可以存储2^32-1个元素。Redis中的列表支持两端插入和弹出,并可以获得指定位置(或范围)的元素,可以充当数组、队列、栈等。
(2)内部编码
列表的内部编码可以是压缩列表(ziplist)或双端链表(linkedlist)。
双端链表:由一个list结构和多个listNode结构组成;典型结构如下图所示:

图片来源:《Redis设计与实现》
通过图中可以看出,双端链表同时保存了表头指针和表尾指针,并且每个节点都有指向前和指向后的指针;链表中保存了列表的长度;dup、free和match为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。而链表中每个节点指向的是type为字符串的redisObject。
压缩列表:压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块(而不是像双端链表一样每个节点是指针)组成的顺序型数据结构;具体结构相对比较复杂,略。与双端链表相比,压缩列表可以节省内存空间,但是进行修改或增删操作时,复杂度较高;因此当节点数量较少时,可以使用压缩列表;但是节点数量多时,还是使用双端链表划算。
压缩列表不仅用于实现列表,也用于实现哈希、有序列表;使用非常广泛。
(3)编码转换
只有同时满足下面两个条件时,才会使用压缩列表:列表中元素数量小于512个;列表中所有字符串对象都不足64字节。如果有一个条件不满足,则使用双端列表;且编码只可能由压缩列表转化为双端链表,反方向则不可能。
下图展示了列表编码转换的特点:

其中,单个字符串不能超过64字节,是为了便于统一分配每个节点的长度;这里的64字节是指字符串的长度,不包括SDS结构,因为压缩列表使用连续、定长内存块存储字符串,不需要SDS结构指明长度。后面提到压缩列表,也会强调长度不超过64字节,原理与这里类似。
3、哈希
(1)概况
哈希(作为一种数据结构),不仅是redis对外提供的5种对象类型的一种(与字符串、列表、集合、有序结合并列),也是Redis作为Key-Value数据库所使用的数据结构。为了说明的方便,在本文后面当使用“内层的哈希”时,代表的是redis对外提供的5种对象类型的一种;使用“外层的哈希”代指Redis作为Key-Value数据库所使用的数据结构。
(2)内部编码
内层的哈希使用的内部编码可以是压缩列表(ziplist)和哈希表(hashtable)两种;Redis的外层的哈希则只使用了hashtable。
压缩列表前面已介绍。与哈希表相比,压缩列表用于元素个数少、元素长度小的场景;其优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于哈希中元素数量较少,因此操作的时间并没有明显劣势。
hashtable:一个hashtable由1个dict结构、2个dictht结构、1个dictEntry指针数组(称为bucket)和多个dictEntry结构组成。
正常情况下(即hashtable没有进行rehash时)各部分关系如下图所示:

图片改编自:《Redis设计与实现》
下面从底层向上依次介绍各个部分:
dictEntry
dictEntry结构用于保存键值对,结构定义如下:
| 1 2 3 4 5 6 7 8 9 |
|
其中,各个属性的功能如下:
- key:键值对中的键;
- val:键值对中的值,使用union(即共用体)实现,存储的内容既可能是一个指向值的指针,也可能是64位整型,或无符号64位整型;
- next:指向下一个dictEntry,用于解决哈希冲突问题
在64位系统中,一个dictEntry对象占24字节(key/val/next各占8字节)。
bucket
bucket是一个数组,数组的每个元素都是指向dictEntry结构的指针。redis中bucket数组的大小计算规则如下:大于dictEntry的、最小的2^n;例如,如果有1000个dictEntry,那么bucket大小为1024;如果有1500个dictEntry,则bucket大小为2048。
dictht
dictht结构如下:
| 1 2 3 4 5 6 |
|
其中,各个属性的功能说明如下:
- table属性是一个指针,指向bucket;
- size属性记录了哈希表的大小,即bucket的大小;
- used记录了已使用的dictEntry的数量;
- sizemask属性的值总是为size-1,这个属性和哈希值一起决定一个键在table中存储的位置。
dict
一般来说,通过使用dictht和dictEntry结构,便可以实现普通哈希表的功能;但是Redis的实现中,在dictht结构的上层,还有一个dict结构。下面说明dict结构的定义及作用。
dict结构如下:
| 1 2 3 4 5 6 |
|
其中,type属性和privdata属性是为了适应不同类型的键值对,用于创建多态字典。
ht属性和trehashidx属性则用于rehash,即当哈希表需要扩展或收缩时使用。ht是一个包含两个项的数组,每项都指向一个dictht结构,这也是Redis的哈希会有1个dict、2个dictht结构的原因。通常情况下,所有的数据都是存在放dict的ht[0]中,ht[1]只在rehash的时候使用。dict进行rehash操作的时候,将ht[0]中的所有数据rehash到ht[1]中。然后将ht[1]赋值给ht[0],并清空ht[1]。
因此,Redis中的哈希之所以在dictht和dictEntry结构之外还有一个dict结构,一方面是为了适应不同类型的键值对,另一方面是为了rehash。
(3)编码转换
如前所述,Redis中内层的哈希既可能使用哈希表,也可能使用压缩列表。
只有同时满足下面两个条件时,才会使用压缩列表:哈希中元素数量小于512个;哈希中所有键值对的键和值字符串长度都小于64字节。如果有一个条件不满足,则使用哈希表;且编码只可能由压缩列表转化为哈希表,反方向则不可能。
下图展示了Redis内层的哈希编码转换的特点:

4、集合
(1)概况
集合(set)与列表类似,都是用来保存多个字符串,但集合与列表有两点不同:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
一个集合中最多可以存储2^32-1个元素;除了支持常规的增删改查,Redis还支持多个集合取交集、并集、差集。
(2)内部编码
集合的内部编码可以是整数集合(intset)或哈希表(hashtable)。
哈希表前面已经讲过,这里略过不提;需要注意的是,集合在使用哈希表时,值全部被置为null。
整数集合的结构定义如下:
| 1 2 3 4 5 |
|
其中,encoding代表contents中存储内容的类型,虽然contents(存储集合中的元素)是int8_t类型,但实际上其存储的值是int16_t、int32_t或int64_t,具体的类型便是由encoding决定的;length表示元素个数。
整数集合适用于集合所有元素都是整数且集合元素数量较小的时候,与哈希表相比,整数集合的优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于集合数量较少,因此操作的时间并没有明显劣势。
(3)编码转换
只有同时满足下面两个条件时,集合才会使用整数集合:集合中元素数量小于512个;集合中所有元素都是整数值。如果有一个条件不满足,则使用哈希表;且编码只可能由整数集合转化为哈希表,反方向则不可能。
下图展示了集合编码转换的特点:

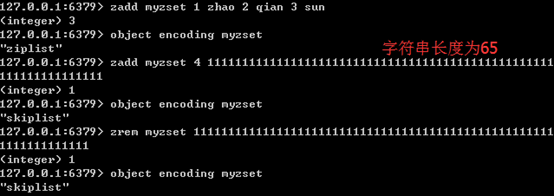
5、有序集合
(1)概况
有序集合与集合一样,元素都不能重复;但与集合不同的是,有序集合中的元素是有顺序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
(2)内部编码
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。ziplist在列表和哈希中都有使用,前面已经讲过,这里略过不提。
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。跳跃表支持平均O(logN)、最坏O(N)的复杂点进行节点查找,并支持顺序操作。Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾节点、长度等),后者用于表示跳跃表节点。具体结构相对比较复杂,略。
(3)编码转换
只有同时满足下面两个条件时,才会使用压缩列表:有序集合中元素数量小于128个;有序集合中所有成员长度都不足64字节。如果有一个条件不满足,则使用跳跃表;且编码只可能由压缩列表转化为跳跃表,反方向则不可能。
下图展示了有序集合编码转换的特点:
五、应用举例
了解Redis的内存模型之后,下面通过几个例子说明其应用。
1、估算Redis内存使用量
要估算redis中的数据占据的内存大小,需要对redis的内存模型有比较全面的了解,包括前面介绍的hashtable、sds、redisobject、各种对象类型的编码方式等。
下面以最简单的字符串类型来进行说明。
假设有90000个键值对,每个key的长度是7个字节,每个value的长度也是7个字节(且key和value都不是整数);下面来估算这90000个键值对所占用的空间。在估算占据空间之前,首先可以判定字符串类型使用的编码方式:embstr。
90000个键值对占据的内存空间主要可以分为两部分:一部分是90000个dictEntry占据的空间;一部分是键值对所需要的bucket空间。
每个dictEntry占据的空间包括:
1) 一个dictEntry,24字节,jemalloc会分配32字节的内存块
2) 一个key,7字节,所以SDS(key)需要7+9=16个字节,jemalloc会分配16字节的内存块
3) 一个redisObject,16字节,jemalloc会分配16字节的内存块
4) 一个value,7字节,所以SDS(value)需要7+9=16个字节,jemalloc会分配16字节的内存块
5) 综上,一个dictEntry需要32+16+16+16=80个字节。
bucket空间:bucket数组的大小为大于90000的最小的2^n,是131072;每个bucket元素为8字节(因为64位系统中指针大小为8字节)。
因此,可以估算出这90000个键值对占据的内存大小为:90000*80 + 131072*8 = 8248576。
下面写个程序在redis中验证一下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
运行结果:8247552
理论值与结果值误差在万分之1.2,对于计算需要多少内存来说,这个精度已经足够了。之所以会存在误差,是因为在我们插入90000条数据之前redis已分配了一定的bucket空间,而这些bucket空间尚未使用。
作为对比将key和value的长度由7字节增加到8字节,则对应的SDS变为17个字节,jemalloc会分配32个字节,因此每个dictEntry占用的字节数也由80字节变为112字节。此时估算这90000个键值对占据内存大小为:90000*112 + 131072*8 = 11128576。
在redis中验证代码如下(只修改插入数据的代码):
| 1 2 3 4 5 |
|
运行结果:11128576;估算准确。
对于字符串类型之外的其他类型,对内存占用的估算方法是类似的,需要结合具体类型的编码方式来确定。
2、优化内存占用
了解redis的内存模型,对优化redis内存占用有很大帮助。下面介绍几种优化场景。
(1)利用jemalloc特性进行优化
上一小节所讲述的90000个键值便是一个例子。由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用内存很大的变动;在设计时可以利用这一点。
例如,如果key的长度如果是8个字节,则SDS为17字节,jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则每个key所占用的空间都可以缩小一半。
(2)使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。
(3)共享对象
利用共享对象,可以减少对象的创建(同时减少了redisObject的创建),节省内存空间。目前redis中的共享对象只包括10000个整数(0-9999);可以通过调整REDIS_SHARED_INTEGERS参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可以共享。
考虑这样一种场景:论坛网站在redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。
(4)避免过度设计
然而需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影响到代码的复杂度、可维护性。
如果数据量较小,那么为了节省内存而使得代码的开发、维护变得更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
3、关注内存碎片率
内存碎片率是一个重要的参数,对redis 内存的优化有重要意义。
如果内存碎片率过高(jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重;这时便可以考虑重启redis服务,在内存中对数据进行重排,减少内存碎片。
如果内存碎片率小于1,说明redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取速度比物理内存差很多(2-3个数量级),此时redis的访问速度可能会变得很慢。因此必须设法增大物理内存(可以增加服务器节点数量,或提高单机内存),或减少redis中的数据。
要减少redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。