背景
设计出一个高性能的API,需要综合网络、业务、数据库的优化。一下是我在实际的开发过程中总结的优化思想和一些效率提升的技巧。
批量思想
很多的数据库操作都含有batch或者bulk的api,如我最近常使用的mybatis、mybatis plus以及``elastic Search的数据操作API。从单条循环插入到批量插入,减少了session` 的链接,更高的效率。
# 优化前
for (User user: UserList) {
mapper.insert(user);
}
# 优化后
mapper.batchInsert(UserList);
对应的实际sql为:
insert into user(id, name) values(1,2)
insert into user(id, name) values(1,2)
insert into user(id, name) values(1,2) ,(3,4), (5,6)
所以java的开发也有一种规范:禁止在循环中操作数据库
异步思想
对于服务的调用链路特别长的情况,接口的响应时间也特别的长。如果前端再去控制timeout的时间,直接出现接口超时的异常。于是异步的思想就出来了,允许耗时长的操作异步的执行。这类一般见于电商服务的业务流程中。
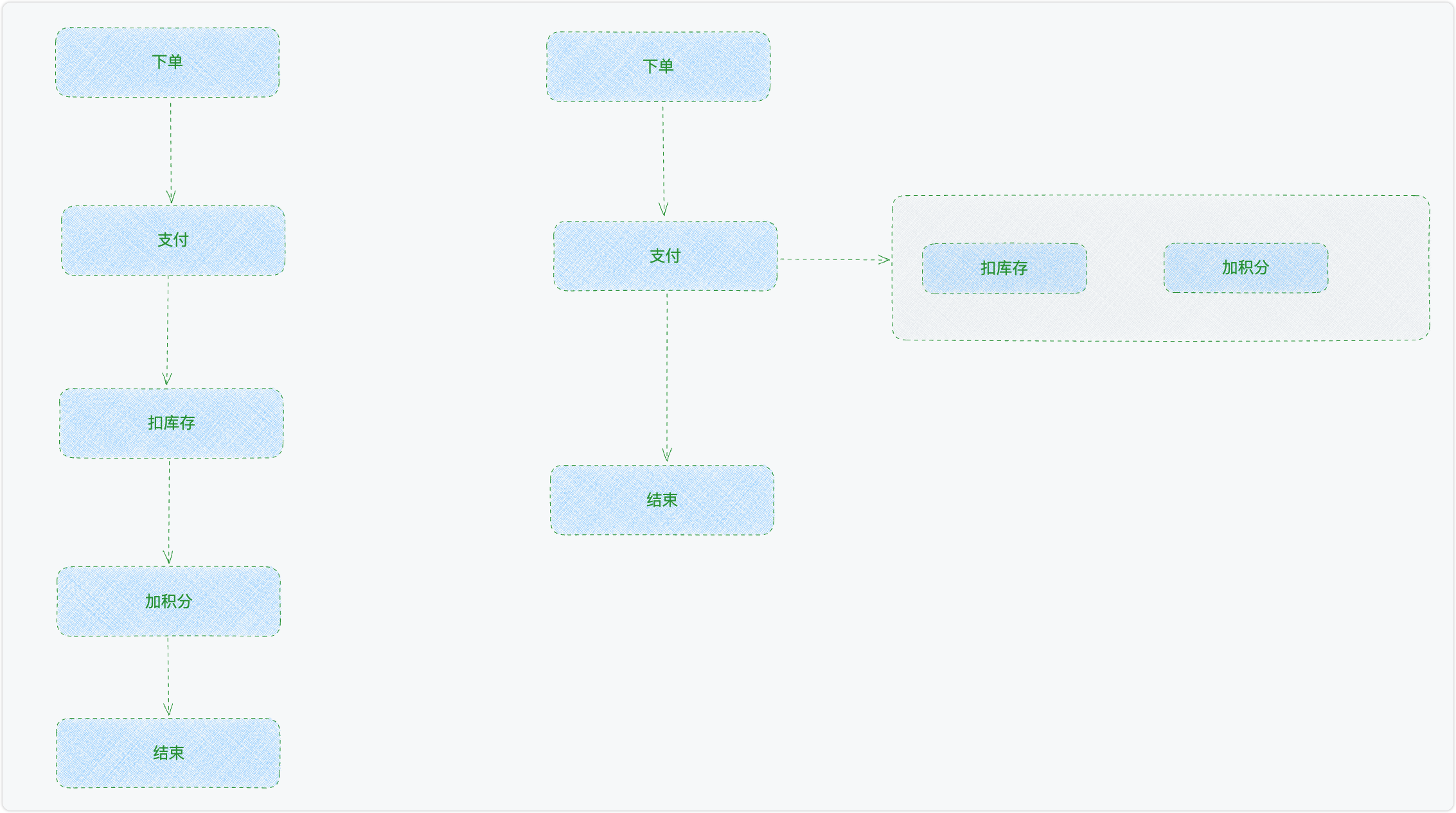
空间换时间
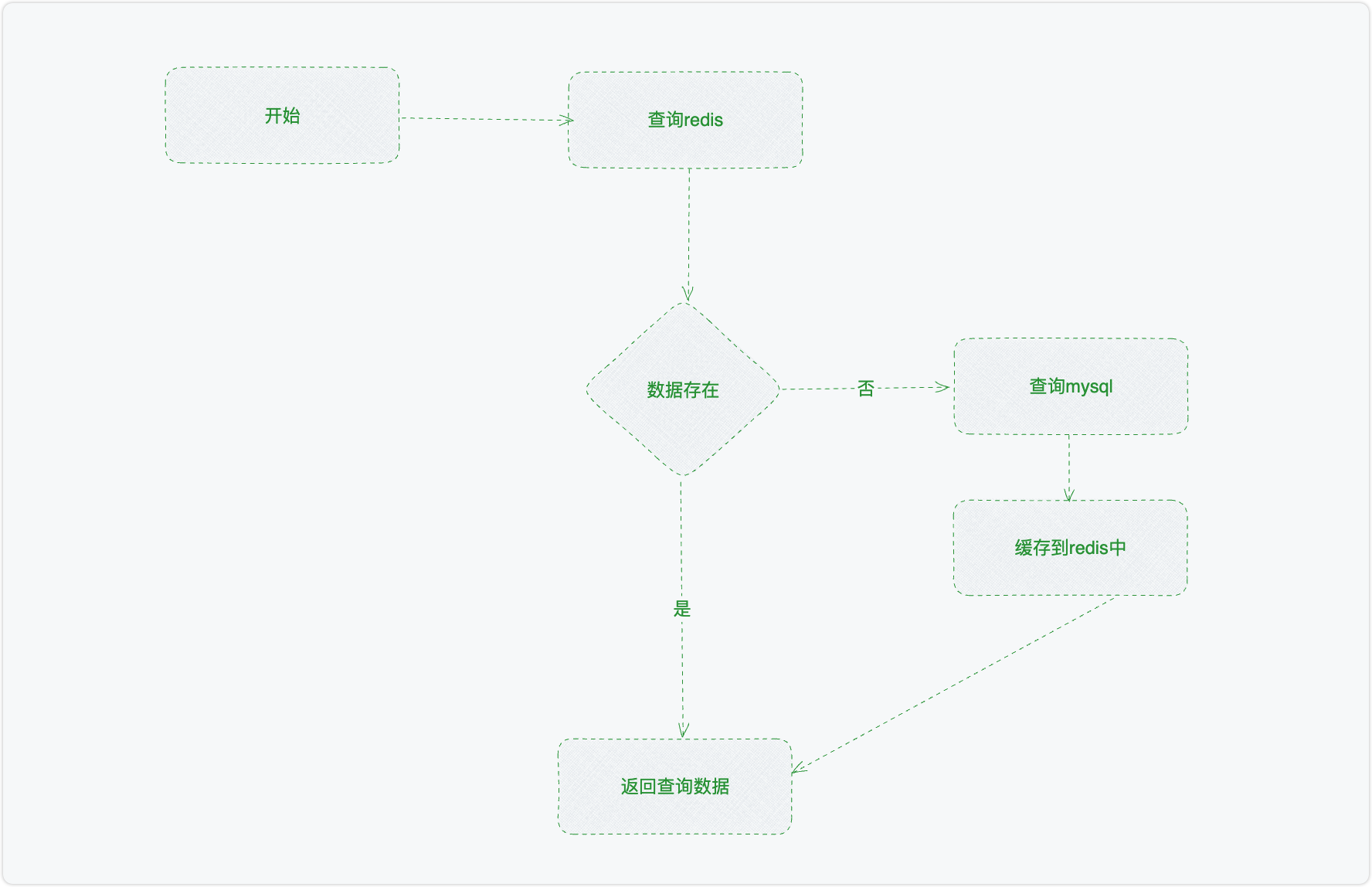
提到这个有点像算法了,空间复杂度和时间复杂度之间的一个权衡。这里的空间,指的是类似于redis的缓存 中间件。以查询数据为例:
池化思想
在这里不得不提到线程池了,这是多少人的噩梦!面试要问,项目要用,用不好服务直接搞挂!
我们常见的线程池类型有:数据库连接池、线程池、redis连接池
总结下来的功能有:
- 避免线程的频繁创建和销毁
Thread t = new Thread(() -> {System.out.println("hello world")});
t.start();
瞧瞧这new的多恐怖。spring bean都交给容器管理了,线程还要单独new?来看看一段优雅的代码:
@Override
public int executeNotify() throws InterruptedException {
// 获得需要通知的任务
List<PayNotifyTaskDO> tasks = payNotifyTaskMapper.selectListByNotify();
if (CollUtil.isEmpty(tasks)) {
return 0;
}
// 遍历,逐个通知
CountDownLatch latch = new CountDownLatch(tasks.size());
tasks.forEach(task -> threadPoolTaskExecutor.execute(() -> {
try {
executeNotifySync(task);
} finally {
latch.countDown();
}
}));
// 等待完成
awaitExecuteNotify(latch);
// 返回执行完成的任务数(成功 + 失败)
return tasks.size();
}
优雅在任务直接往池子里塞,具体的什么时候完成一直等着就好了。
- 预分配
- 循环使用
在这里,我也必须补充一下线程池的构造方法:
/**
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
*/
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
int maximumPoolSize,//线程池的最大线程数
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,//时间单位
BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
线程池的逻辑如下:

远程调用串行改并行
对于远程调用一系列接口,可以使用异步调用的方式,减少时间消耗。
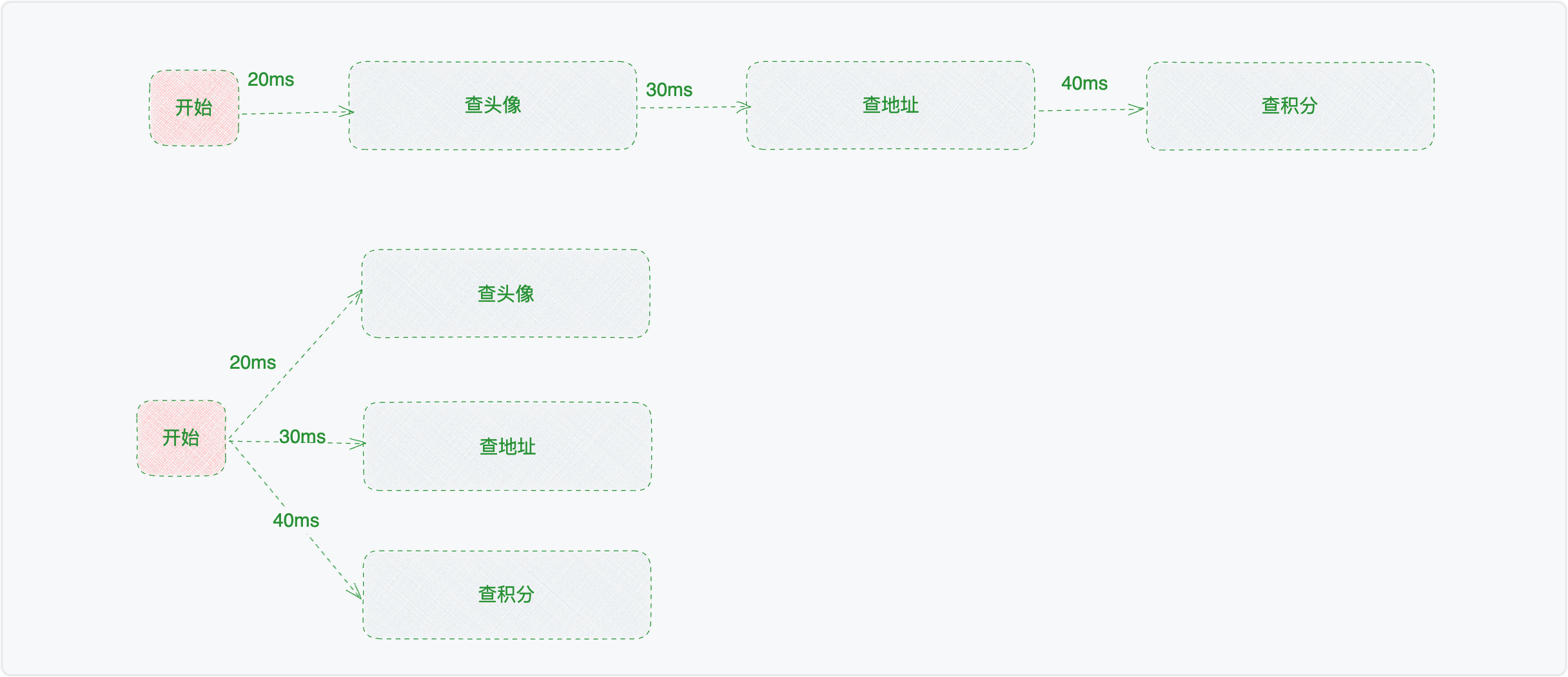
为了实现以上的效果,我也结合线程池,用到了异步的方式模拟以上两种方式的效果。
public int getCoreSize() {
return Runtime.getRuntime().availableProcessors();
}
public static void someMethod(Long minutes) {
try {
Thread.sleep(minutes);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " is running.....");
}
public void serial() {
Date start = new Date();
someMethod(1000L);
someMethod(1000L);
someMethod(300L);
System.out.println(DateUtil.between(start, new Date(), DateUnit.MS));
}
public void parallel() {
Date start = new Date();
CompletableFuture<Void> completableFutureOne = CompletableFuture.runAsync(() -> someMethod(1000L), poolExecutor);
CompletableFuture<Void> completableFutureTwo = CompletableFuture.runAsync(() -> someMethod(1000L), poolExecutor);
CompletableFuture<Void> completableFutureThree = CompletableFuture.runAsync(() -> someMethod(300L), poolExecutor);
try {
// get()方法会阻塞线程
CompletableFuture.allOf(completableFutureOne, completableFutureTwo, completableFutureThree).get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
System.out.println(DateUtil.between(start, new Date(), DateUnit.MS));
poolExecutor.shutdown();
}
以上就是《高性能API设计》的第一部分了,时间和篇幅原因,剩下的部分将在下一期展开。







![[Python] Pylance 插件打开 Python 的类型检查](https://img-blog.csdnimg.cn/a3e7252df9c94fadbb22632af69e0cae.png)