目录
- 前言
- 一、什么是 模板编译?
- 二、模板编译 到 render 函数字符串的流程
- 三、深入模板编译源码
- baseCompile ()
- parse() - 解析阶段
- optimize() - 优化阶段
- generate() - 生成阶段
- (1)了解 render函数字符串 和 with 语法
- (2)generate
- (3)genElement()
- 四、组件渲染/更新 完整过程
- 初识组件渲染/更新
- 组件渲染/更新过程
- (1)初次渲染过程
- (2)更新过程
- (3)异步渲染
- 疑问点整理
前言
这是一个系列学习源码的文章,感兴趣的可以继续阅读其他文章
Vue源码学习 - new Vue初始化都做了什么?
Vue源码学习 - 数据响应式原理
Vue源码学习 - 异步更新队列 和 nextTick原理
Vue源码学习 - 虚拟Dom 和 diff算法
一、什么是 模板编译?
平时开发写的 <template></template> 以及里面的变量、表达式、指令等,不是html语法,是浏览器识别不出来的。所以需要将 template 转化成一个 JS 函数,这样浏览器就可以执行这一个函数并渲染出对应的 HTML 元素,就可以让视图跑起来了,这一个转化的过程,就成为模板编译。
主要流程就是:
- 提取出模板中的原生和非原生 HTML,比如绑定的属性、事件、指令、变量等。
- 经过一些处理生成
render函数字符串。render函数再将模板内容生成对应的vnode。- 再经过
patch过程(Diff)得到要渲染到视图中的vnode。- 最后根据 vnode 创建
真实 DOM节点,也就是原生 HTML 插入到视图中,完成渲染。
上面的1、2、3条就是模板编译的过程。具体是怎么编译生成 render 函数字符串的,继续往下看。
二、模板编译 到 render 函数字符串的流程
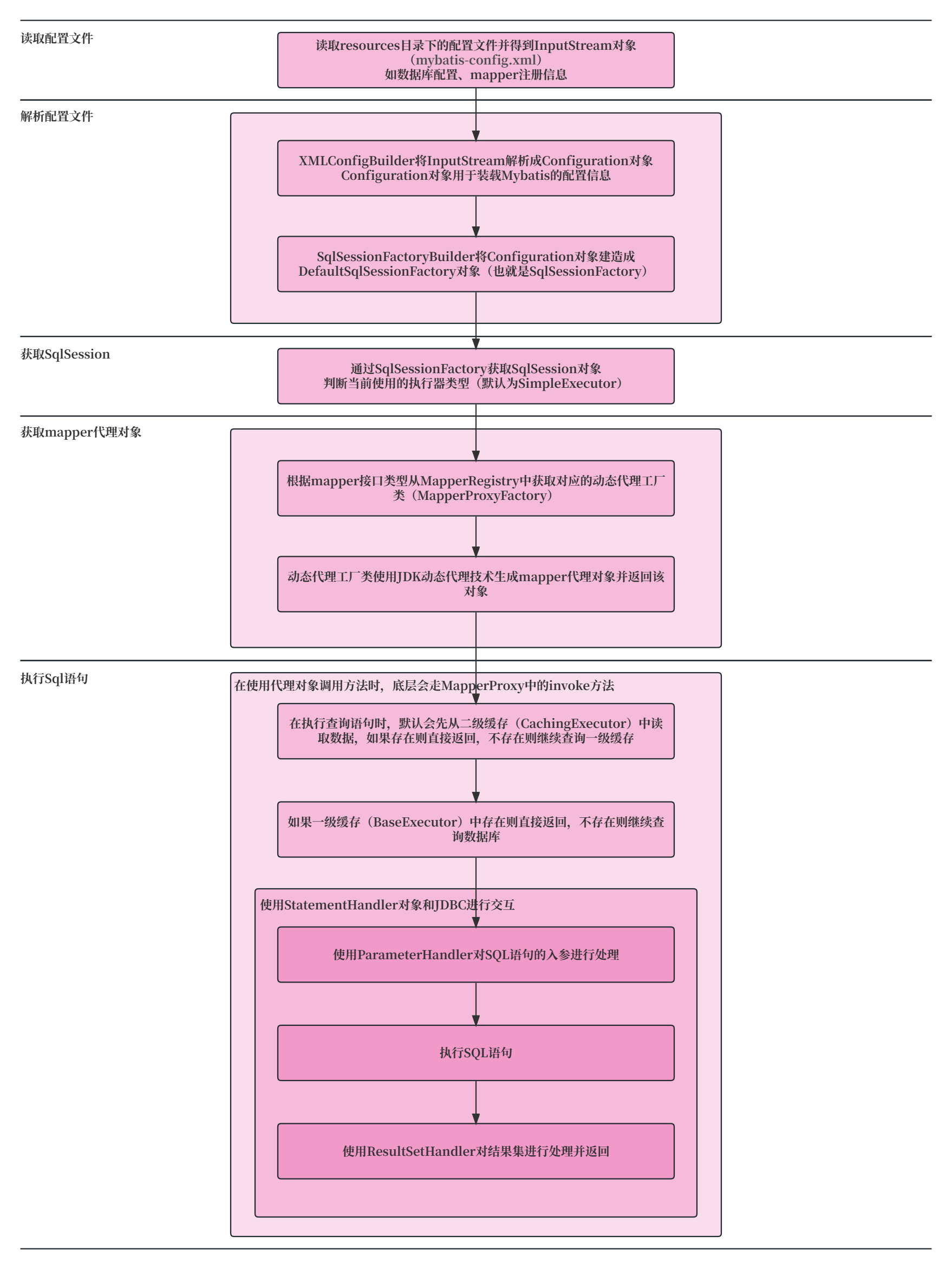
主要有三个阶段:解析 parse;优化 optimise;生成 generate,最终生成可执行函数 render。
-
模板解析阶段: 使用大量的正则表达式提取出
<template></template>模板里的标签、属性、变量等信息,并解析成抽象语法树 AST。 -
优化阶段:
遍历 AST,找到其中的一些静态节点并标记,方便在页面重渲染的时候进行 diff 比较时,直接跳过这些静态节点,优化 runtime 的性能。 -
生成阶段 :将最终的
AST转化为render函数字符串。
这三步分别对应三个函数,后面会挨个介绍,先看一下 baseCompile 源码中是在哪里调用的。
三、深入模板编译源码
baseCompile ()
这是模板编译的入口函数,接收两个参数:
template:要转换的模板字符串options:转换时需要的参数
// src/compiler/index.ts
export const createCompiler = createCompilerCreator(function baseCompile(
template: string, // 要转换的模板字符串
options: CompilerOptions // 转换时需要的参数
): CompiledResult {
// 1. 进行模板编译,并将结果保存为抽象语法树 AST
const ast = parse(template.trim(), options)
// 没有禁用静态优化的话
if (options.optimize !== false) {
// 2. 遍历 AST,找到其中的一些静态节点并标记
optimize(ast, options)
}
// 3. 将最终的 AST 转化为 render渲染函数
const code = generate(ast, options)
return {
ast,
render: code.render, // 返回渲染函数 render
staticRenderFns: code.staticRenderFns
}
})
就这么几行代码,三步,调用了三个方法很清晰。
我们先看一下最后 return 出去的是个啥,再来深入这三步分别调用的方法源码,也好更清楚的知道这三步分别是要做哪些处理。
比如有这样的模板:
<template>
<div id="app">{{name}}</div>
</template>
打印一下编译后的结果,也就是上面源码 return 出去的结果,看看是啥。
// 把 模板 编译成 抽象语法树 AST
{
ast: {
type: 1,
tag: 'div',
attrsList: [ { name: 'id', value: 'app' } ],
attrsMap: { id: 'app' },
rawAttrsMap: {},
parent: undefined,
children: [
{
type: 2,
expression: '_s(name)',
tokens: [ { '@binding': 'name' } ],
text: '{{name}}',
static: false
}
],
plain: false,
attrs: [ { name: 'id', value: '"app"', dynamic: undefined } ],
static: false,
staticRoot: false
},
render: `with(this){return _c('div',{attrs:{"id":"app"}},[_v(_s(name))])}`,
staticRenderFns: [],
errors: [],
tips: []
}
这里暂时看不明白也没有关系,注意看return 里提到的三步都干了什么?
ast:就是第一步生成的。static: 就是静态节点标记,是在第二步中的根据ast里的type加上去的。(具体的type类型可看下面的表格)render:就是第三步生成的。
有个大概的印象了,然后再来看源码。
parse() - 解析阶段
这个方法就是解析器的主函数,它通过多个正则方法提取出 <template></template> 模板字符串里所有的tag、props、children 信息,生成一个对应结构的 AST 对象。
核心步骤:调用 parseHTML() 对 模板字符串 进行解析。
- 解析到 开始标签、结束标签、文本、注释分别进行不同的处理。
- 解析过程中遇到 文本信息 ,就调用文本解析器
parseText()进行文本解析。- 解析过程中遇到 包含过滤器 ,就调用过滤器解析器
parseFilters()进行解析。- 每一步解析的结果都合并到一个对象上(就是最后的 AST).
// src/complier/parser/index.ts
export function parse(template: string, options: CompilerOptions): ASTElement {
parseHTML(template, {
warn,
expectHTML: options.expectHTML,
isUnaryTag: options.isUnaryTag,
canBeLeftOpenTag: options.canBeLeftOpenTag,
shouldDecodeNewlines: options.shouldDecodeNewlines,
shouldDecodeNewlinesForHref: options.shouldDecodeNewlinesForHref,
shouldKeepComment: options.comments,
outputSourceRange: options.outputSourceRange,
// 解析到 开始标签 时调用,如<div>
start(tag, attrs, unary, start, end) {
// unary 是否是自闭合标签,如 <img />
// ...
},
// 解析到 结束标签 时调用,如</div>
end(tag, start, end) {
// ...
},
// 解析 文本 时调用
chars(text: string, start?: number, end?: number) {
// 这里会判断判断很多东西,来看它是不是带变量的动态文本
// 然后创建动态文本或静态文本对应的 AST 节点
// ...
},
// 解析到注释时调用
comment(text: string, start, end) {
// ...
}
})
return root
}
上面解析文本时调用的 chars() 会根据不同类型节点加上不同 type,来标记 AST 节点类型,这个属性在下一步标记的时候会用到。
| type | AST节点类型 |
|---|---|
| 1 | 元素节点 |
| 2 | 包含变量的动态文本节点 |
| 3 | 没有变量的纯文本节点(静态节点) |
optimize() - 优化阶段
这个函数就是在 AST 里找出 静态节点 和 静态根节点,并添加标记,为了后面 patch 过程中就会跳过静态节点的对比,直接克隆一份过去,从而优化了 patch 的性能。这个我们在上一篇虚拟dom和diff算法里也讲过(patchVnode 函数)。
// src/compiler/optimizer.ts
export function optimize(
root: ASTElement | null | undefined,
options: CompilerOptions
) {
if (!root) return
isStaticKey = genStaticKeysCached(options.staticKeys || '')
isPlatformReservedTag = options.isReservedTag || no
// 标记静态节点
markStatic(root)
// 标记静态根节点
markStaticRoots(root, false)
}
具体函数里面的代码,大致过程是这样的:(有个了解就好)
标记静态节点(markStatic):就是判断 type 值,参考上面表格。
- type值为1:就是包含子元素的节点;设置 static 为 false;并递归子节点,直到标记完所有的子节点。
- type值为2:设置 static 为 false。
- type值为3:就是不包含子节点和动态属性的纯文本节点,设置 static 为 true;patch的时候就会跳过这个,直接克隆一份过去。
标记静态根节点(markStaticRoots):静态根节点是指在组件渲染过程中不会发生变化的整个子树;原理和标记静态节点基本相同,只是需要满足下面条件的节点才算是静态根节点。
- 节点本身必须是静态节点
- 必须有子节点
- 子节点不能只有一个文本节点
generate() - 生成阶段
这个就是生成 render 函数字符串 ,就是说最终会返回下面这样的东西。
// 比如有这么个模板
<template>
<div id="app">{{ name }}</div>
</template>
// 上面模板编译后返回的 render 字段 就是这样的
render: `with(this){return _c('div',{attrs:{"id":"app"}},[_v(_s(name))])}`
// 把内容格式化一下,容易理解一点
with(this){
return _c(
'div',
{ attrs:{"id":"app"} },
[ _v(_s(name)) ]
)
}
了解虚拟 DOM 就可以看出来,上面的 render 正是虚拟 DOM 的结构,就是把一个标签分为 tag、props、children。
在看 generate 源码之前,我们要先了解一下上面这最后返回的 render 字段是什么意思。
(1)了解 render函数字符串 和 with 语法
这个 with 是用来欺骗词法作用域的关键字,它可以让我们更快的引用一个对象上的多个属性。
下面先用一个例子来展示 with 语法与普通语法的不同。
不使用with语法执行程序时:
const obj = { name: '铁锤妹妹', age: 18 }
console.log(obj.name) // 铁锤妹妹
console.log(obj.age) // 18
console.log(obj.sex) // undefined
使用with语法执行程序时:
const obj = { name: '铁锤妹妹', age: 18 }
with (obj) {
console.log(name) // 铁锤妹妹 不需要写 obj.name 了
console.log(age) // 18 不需要写 obj.age了
console.log(sex) // 会报错!!!
}
with 语法总结:
- with 语法会改变词法作用域中的属性指向,当做 obj 属性来查找。
- 如果在
{ }内找不到匹配的obj属性会报错。 with要谨慎使用,它打破了作用域规则,会让其易读性变差。
那 _c、 _v 和 _s 是什么呢?
export function installRenderHelpers(target: any) {
target._s = toString // 转字符串函数
target._v = createTextVNode // 创建文本节点函数
}
// 补充
_c = createElement // 创建虚拟节点函数
到此为止我们再来看下返回的 render 字段,就会清楚多了。
with(this){ // 欺骗词法作用域,将该作用域里所有属姓和方法都指向当前组件
return _c( // 创建一个虚拟节点
'div', // 标签为 div
{ attrs:{"id":"app"} }, // 有一个属性 id 为 'app'
[ _v(_s(name)) ] // 是一个文本节点,所以把获取到的动态属性 name 转成字符串
)
}
接下来我们再来看 generate() 源码。
(2)generate
就是先判断 AST 是不是为空,不为空就根据 AST 创建 vnode,否则就创建一个空div 的 vnode。
// src/complier/codegen/index.ts
export function generate(
ast: ASTElement | void,
options: CompilerOptions
): CodegenResult {
const state = new CodegenState(options)
// 就是先判断 AST 是不是为空,不为空就根据 AST 创建 vnode,否则就创建一个空div的 vnode
const code = ast
? ast.tag === 'script'
? 'null'
: genElement(ast, state)
: '_c("div")'
return {
render: `with(this){return ${code}}`,
staticRenderFns: state.staticRenderFns
}
}
可以看出这里面主要就是通过 genElement() 方法来创建 vnode 的,所以我们来看一下它的源码,看是怎么创建的。
(3)genElement()
就是一堆 if/else 判断传进来的 AST 元素节点的属性来执行不同的生成函数。
这里还可以发现另一个知识点: v-for 的优先级要高于 v-if,因为先判断 for 的。
// src/complier/codegen/index.ts
export function genElement(el: ASTElement, state: CodegenState): string {
if (el.parent) {
el.pre = el.pre || el.parent.pre
}
if (el.staticRoot && !el.staticProcessed) {
return genStatic(el, state)
} else if (el.once && !el.onceProcessed) { // v-once
return genOnce(el, state)
} else if (el.for && !el.forProcessed) { // v-for
return genFor(el, state)
} else if (el.if && !el.ifProcessed) { // v-if
return genIf(el, state)
// template 节点 && 没有插槽 && 没有 pre 标签
} else if (el.tag === 'template' && !el.slotTarget && !state.pre) {
return genChildren(el, state) || 'void 0'
} else if (el.tag === 'slot') { // v-slot
return genSlot(el, state)
} else {
// component or element
let code
// 如果有子组件
if (el.component) {
code = genComponent(el.component, el, state)
} else {
let data
const maybeComponent = state.maybeComponent(el)
// 获取元素属性 props
if (!el.plain || (el.pre && maybeComponent)) {
data = genData(el, state)
}
let tag: string | undefined
const bindings = state.options.bindings
if (maybeComponent && bindings && bindings.__isScriptSetup !== false) {
tag = checkBindingType(bindings, el.tag)
}
if (!tag) tag = `'${el.tag}'`
// 获取元素子节点
const children = el.inlineTemplate ? null : genChildren(el, state, true)
code = `_c(${tag}${
data ? `,${data}` : '' // data
}${
children ? `,${children}` : '' // children
})`
}
for (let i = 0; i < state.transforms.length; i++) {
code = state.transforms[i](el, code)
}
// 返回上面作为 with 作用域执行的内容
return code
}
}
每一种类型调用的生成函数就不一一列举了,总的来说最后创建出来的 vnode 节点类型无非就三种,元素节点、文本节点、注释节点
四、组件渲染/更新 完整过程
初识组件渲染/更新
讲完上完的内容,我们再来讲一个与 编译模板 关联性很强的知识点:组件渲染/更新过程。
一个组件,从 渲染到页面上开始,再到修改 data 去触发更新(数据驱动视图),它背后的原理是什么,下面是需要掌握的要点。
- 事实上,组件在渲染之前,会先进行
模板编译,模板template会编译成render函数。 - 之后就是数据的监听了,就是vue的
响应式数据。通过操作Object.defineProperty(),去监听data属性,触发getter和setter方法,来实现数据实时更新。 - 监听完数据之后,就是执行
render函数,生成vnode。 - 到了
vnode(即vdom)这一步后,会进行patch(elem,vnode)和patch(vnode,newVnode)的比较。根据对比的结果,Vue 会将更新的内容应用到真实 DOM上,使页面显示与最新的虚拟 DOM 结果保持一致。
这一部分还是挺重要的,前几篇文章我们明白了如何生成 render渲染函数、数据响应式原理、什么是虚拟dom?diff算法?但是对于它们之间的联系还是有些模糊的,这里就直接把前几篇的内容串联起来了。继续往下看吧。
如有需要,可去查看我的前几篇文章学习。
Vue源码学习 - new Vue初始化都做了什么?
Vue源码学习 - 数据响应式原理
Vue源码学习 - 虚拟Dom 和 diff算法
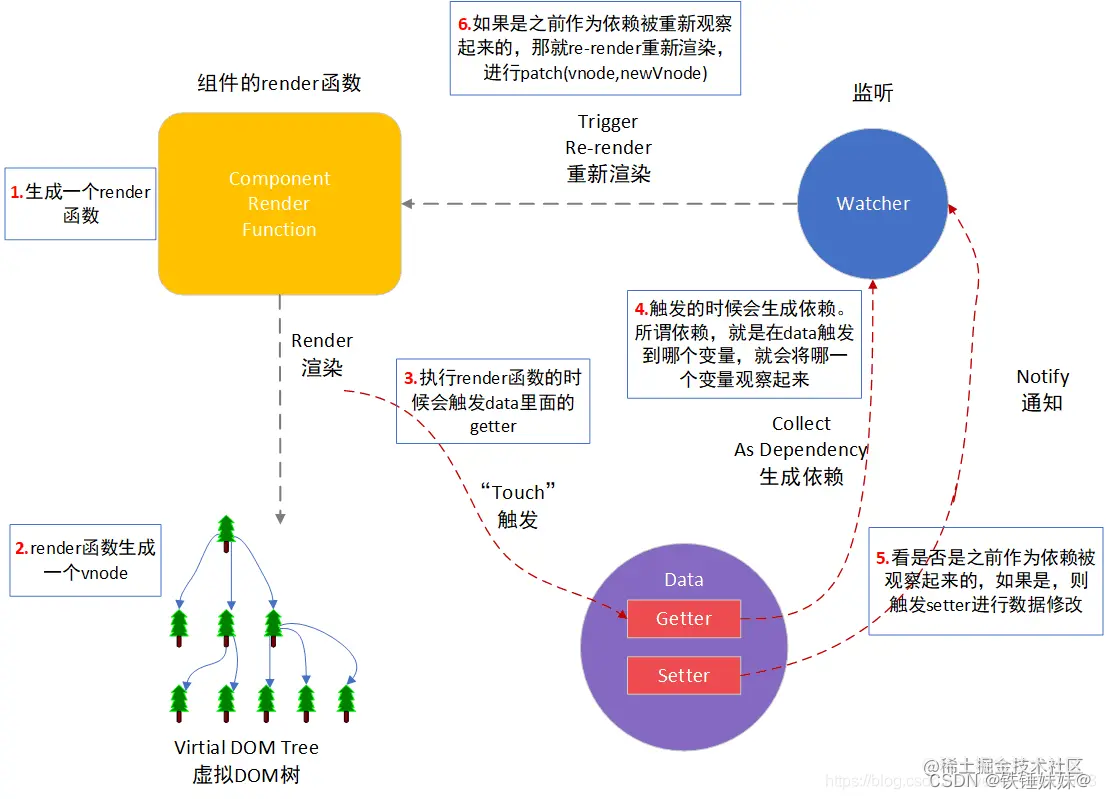
组件渲染/更新过程
组件渲染和更新过程主要经过以下三个步骤:初次渲染过程 =》 更新过程 =》 异步渲染。
(1)初次渲染过程
初次渲染过程,即组件第一次渲染是怎么样的。具体有以下 三个步骤:
- 解析组件模板:解析
template模板为render函数。 - 创建组件实例:在渲染之前,Vue 会创建组件的实例。(会初始化组件的props,data,methods,computed,watch)
- 触发响应式:当组件实例化之后,将数据传递给
render函数 进行渲染时,会监听data属性 ,触发getter和setter方法。 - 执行渲染函数:执行
render渲染函数,生成vnode,进行patch(elem,vnode)。
下面就这几个步骤来进行依次讲解。
1.1)触发响应式
监听 data 属性,这时我们就需要触发响应式,也就是渲染数据。
这个阶段我们需要执行 render 函数, render 函数会触发 getter 方法,因为数据没有进行更新,只是进行渲染。只有在进行更新的时候才会操作 setter 方法。
1.2)执行渲染函数
最后,当数据渲染完毕后,就会执行第一步生成的 render 渲染函数,渲染函数会根据组件的状态和数据生成 虚拟DOM树 ,之后进行 patch(elem,vnode)。
(2)更新过程
在这个阶段,将会修改 data,并且触发 setter(注意:在此之前 data 在 getter 中已经被依赖收集、监听)
触发完 setter 之后,重新执行 render 函数,并生成 newVode,最后进行 patch(vnode, newVode)的 diff 比较。
通过对比,Vue 可以找出需要进行更新的部分,从而减少操作真实 DOM 的次数。根据对比的结果,Vue 会将更新的内容应用到真实 DOM 上,使页面显示与最新的虚拟 DOM 结果保持一致。
组件渲染/更新完整流程图:(用一张网上的图片)
(3)异步渲染
在渲染和更新结束之后,我们的程序可能还有可能会发生 多个程序 同时加载,这就涉及到一个 异步渲染 问题。
多个数据变更,直接更新视图多次的话,性能就会降低,所以对视图更新做一个异步更新的队列,避免不必要的计算和 DOM 操作。在下一轮事件循环的时候,刷新队列并执行已去重的工作(nextTick的回调函数),组件重新渲染,更新视图。
异步渲染问题,我们用 $nextTick 来解决。
对DOM异步更新渲染视图,感兴趣的可以移步去看另一篇系列文章: Vue源码学习 - 异步更新队列 和 nextTick原理
疑问点整理
1. Vue 组件在渲染过程中为什么不直接加载数据,而是先解析模板转化成一个 render 函数呢?
这是因为 Vue 的渲染过程可以分为两个阶段:
编译阶段和运行阶段。
- 编译阶段:在组件被实例化之前,需要先进行模板编译。这个阶段会将模板解析并转换为可执行的 render 函数。编译阶段会分析模板的结构和指令,生成一个抽象语法树(AST),然后根据 AST 生成 render 函数。在这个阶段,Vue并不会加载实际的数据,因为具体的数据是在组件实例化后才传入的。
- 运行阶段:在组件实例化后,会触发运行阶段。Vue会调用之前生成的 render 函数,并将组件的数据传入。这时候,render 函数会根据传入的数据生成 虚拟DOM,并进行 diff 算法的对比,最终更新到 真实DOM 上。
2. 将数据与渲染过程分开的好处?
- 分离关注点:将模板和数据分开,使得组件的关注点更加清晰。模板负责描述组件的结构和样式,而数据负责描述组件的状态和行为。这样可以使得组件的开发更加模块化和可维护。
- 性能优化:通过将模板编译为 render 函数,Vue 可以在编译阶段进行一些优化操作,如静态节点提前标记、事件监听器的优化等。这样可以减少运行时的开销,提高组件的渲染性能。
可参考:
render 函数是怎么来的?深入浅出 Vue 中的模板编译
模板编译template的背后,究竟发生了什么事?