目录
什么是运行时数据区?
方法区
堆
程序计数器
虚拟机栈
局部变量表
操作数栈
动态连接
运行时常量池
方法返回地址
附加信息
本地方法栈
总结:
什么是运行时数据区?
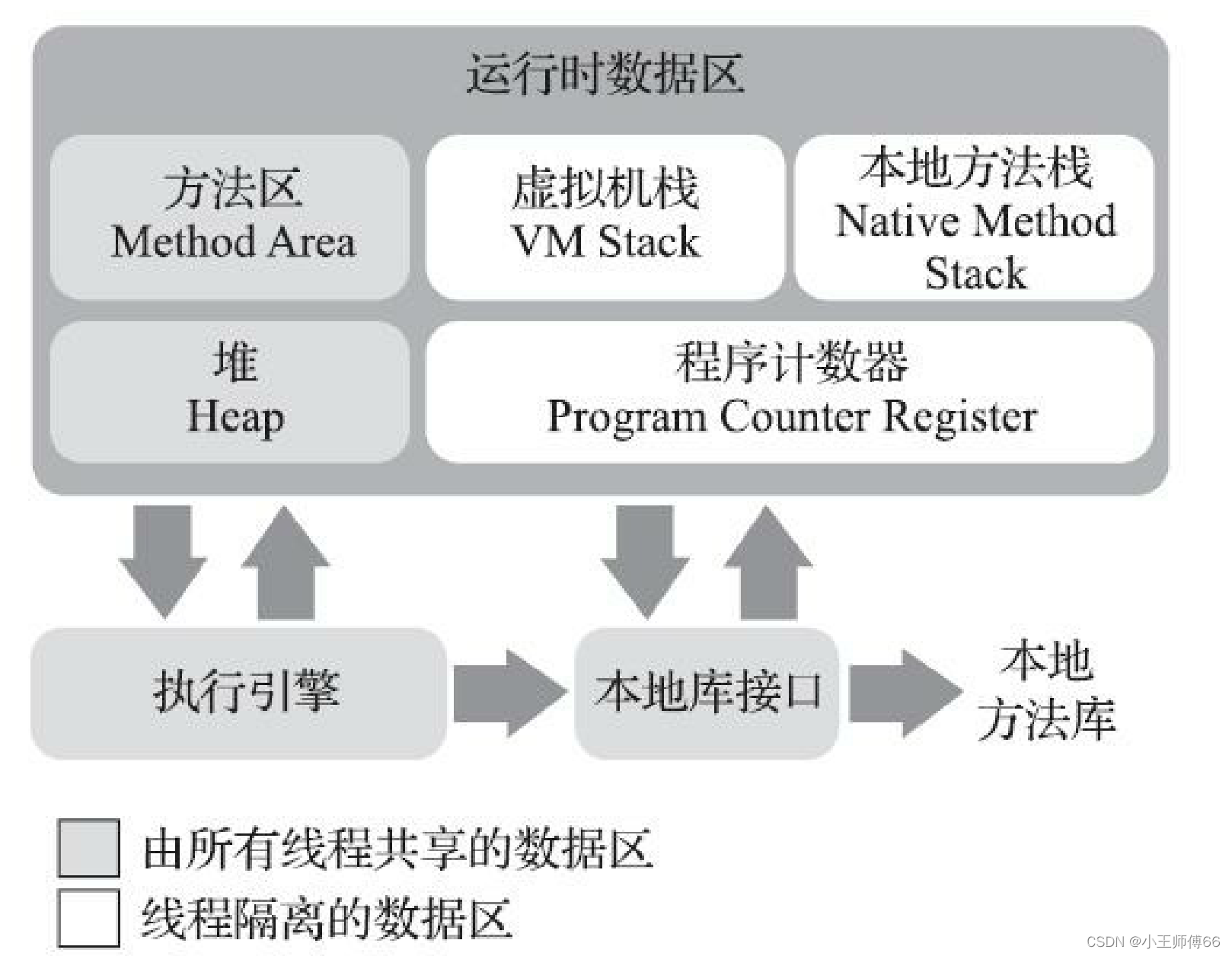
Java虚拟机在执行Java程序时,将它管理的内存分为不同的区域。这些区域用途不同,创建和销毁的时间也不同。有的随虚拟机进程启动一直存在,有的依赖用户线程启动和结束而创建和销毁。根据《Java虚拟机规范》,Java虚拟机管理的内存区域包括以下几个运行时数据区域。
方法区
方法区用于存储已被虚拟机加载的类型信息,常量,静态变量,即时编译器编译后的代码缓存等数据。可以理解为被线程共享的内存区域。
根据《Java虚拟机规范》的规定,如果方法区无法满足新的内存分配需求时,将抛出
OutOfMemoryError异常。
堆
Java堆(Java heap)是虚拟机管理的最大一块内存,线程共享,虚拟机启动时创建,用于存储对象实例。虽然在《Java虚拟机规范》中对Java堆的描述是:“所有 的对象实例以及数组都应当在堆上分配”,但随着即时编译技术的发展,栈上分配,标量替换等优化手段,Java实例不仅仅分配在堆上。
Java堆是垃圾回收的主要区域,HotSpot VM 的堆内存又分为新生代、老年代和永久代。新生代又分为Eden空间和Survivor空间。 常见的垃圾收集器也都是围绕这些内存区域进行工作的。将Java堆细分,主要是为了更好的回收内存或更快分配内存。
根据《Java虚拟机规范》的规定,Java堆可以处于物理上不连续的内存空间中,但在逻辑上应是连续的,就像我们使用磁盘空间存储文件一样,并不要求所有文件连续存放。但对于大对象(典型的如数组对象),多数虚拟机实现出于实现简单、存储高效的考虑,很可能会要求连续的 内存空间。
Java堆既可以被实现成固定大小的,也可以是可扩展的,不过当前主流的Java虚拟机都是按照可扩展来实现的(通过参数-Xmx和-Xms设定)。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出OutOfMemoryError异常。
程序计数器
因为Java虚拟机中的多线程通过线程轮流切换、分配处理器的执行时间的方式实现,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。为了在线程切换后准确恢复到正确的执行位置,需要记录每个线程的所执行的字节码的行号,这时就需要程序计数器。
程序计数器是一块较小的内存,每个线程都需要一个独立的程序计数器,每个线程之间程序计数器互不影响,独立存储,是“线程私有”的内存。在Java虚拟机的概念模型里,通过改变程序计数器的值选取下一条需要执行的字节码指令。程序计数器,是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础都需要依赖这个计数器完成。大家会想到程序在计算机上执行过程中的程序技术器,决定着程序执行的流程。
如果执行的是本地(Native)方法,程序计数器的值则应为空(undefined),此区域是为一个一个在《Java虚拟机规范》中没有任何OutOfMemeoryError情况的区域。
虚拟机栈
Java虚拟机栈,也是线程私有的,和线程的生命周期相同。
每个方法被执行时,Java虚拟机会同步创建一个栈帧,每个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中刚从入栈到出栈的过程。
栈帧由几部分组成?
局部变量表,操作数栈,方法返回地址,动态连接,附加信息等。
局部变量表
我们知道方法由:访问修饰符(可选),返回值,方法名,参数列表,方法体组成。
局部变量表,保存方法参数和方法内部的局部变量,在局部变量表中的存储空间以变量槽(slot)为单位,每个槽都应该能存放一个boolean,byte,char,short,int,float,reference或returnAddress类型的数据,这8种数据类型都可以使用32位或更小的物理内存累存储,且随着处理器、操作系统或虚拟机实现的不同而发生变化。局部变量表的空间在编译期即可根据源码和虚拟机的具体栈内存实现方式确定,不会受程序运行时数据的影响。
操作数栈
操作数栈,是一个先进后出的栈结构,用于临时保存方法执行过程的操作数。比如在进行加法运算:1+2=3时。
1. 将第一个操作数 1 压入操作数栈;
2. 将第二个操作数 2 压入操作数栈;
3. 从操作数栈弹出第二个操作数 2;
4. 从操作数栈弹出第一个操作数 1;
5. 将两个操作数相加得到结果 3;
6. 将结果 3 压入操作数栈;
7. 从操作数栈弹出结果 3;
通过操作数栈,虚拟机可以方便地对运算中的操作数进行入栈和出栈,实现复杂的算术运算逻辑。它避免了每次运算都需要在堆内存中分配新的操作数对象,可以提高执行效率。高效地对方法运算过程中的操作数进行入栈出栈操作,这是实现Java虚拟机高效运行的重要组成部分。每个栈帧的操作数栈的深度,在编译器也可确定,在运行期间不会变。
动态连接
在讲动态连接之前,我们先回顾一下运行时常量池的知识。
运行时常量池
运行时常量池位于方法区。Class文件中除了有类的版本、字段、方法、接口等描述信息,还有一项是常量池表,用于存放编译期生成的各种字面量和符号引用,常量池表中这部分内容将在类加载后存放在方法区的常量池中,运行期间也可以将新的常量放到常量池中。
Class文件的常量池中存在大量的符号引用,字节码中的方法调用指令就以常量池里指向方法的符号引用作为参数。这些符号引用一部分会在类加载阶段或者第一次使用的时候被转为直接引用,这种转化被称为静态解析。另一部分将在每次运行期间都转化为直接引用,这部分称为动态连接。
动态连接是指在程序运行时才去解析字节码中的符号引用,并把符号引用替换为直接引用的过程,主要为了支持Java动态绑定机制。动态绑定允许程序运行时才去决定实际调用的方法,给Java带来很大的灵活性,支持Java的多态特性。
举个例子:
public class Main {
public static void main(String[] args) {
Animal a = new Dog();
a.run();
}
}
class Animal {
public void run() {
System.out.println("Animal is running");
}
}
class Dog extends Animal {
@Override
public void run() {
System.out.println("Dog is running");
}
}编译时,编译器只知道a是一个Animal对象,它不知道a最终会指向一个Dog对象。
运行时,JVM通过动态连接,才会根据实际的对象类型Dog,动态地绑定到Dog.run()这个方法上,从而输出"Dog is running"。如果没有动态连接,那么只能静态地绑定到Animal.run(),就无法利用多态的特性了。所以动态连接是支持运行时多态以及动态绑定的关键。它让Java语言可以更灵活地处理对象的多态特性。
方法返回地址
方法执行完退出时,无论是遇到方法返回的字节码指令还是遇到异常退出,都需要返回到最初方法被调用的位置,程序才能继续执行。这个位置就是方法返回地址。
例如:
public int sum(int a, int b) {
return a + b;
}
public static void main(String[] args) {
int s = sum(1, 2);
System.out.println(s);
}在main方法调用sum方法时,会先记录下 “int s = sum(1,2);” 这行代码的位置,当sum方法执行完返回结果后,返回到该位置,执行后面的“System.out.pringln(s);”方法。所以,方法返回地址,就是调用该方法的具体代码位置。
JVM通过动态连接找到方法的入口,并记录下返回地址,以便在方法执行后正确返回到调用方。返回地址是实现正确的方法调用流程所必需的。动态连接使得返回地址可以在运行时确定,这样Java程序才可以实现动态绑定和灵活的函数调用机制。
而方法返回后,该方法对应的栈帧会出栈,栈顶的栈帧就是该方法的调用者,调用者的局部变量表可能会发生变化,这取决于方法的返回值是否被赋值给了调用者栈帧的某个局部变量。还以上面的方法为例,当sum方法执行完返回后,main方法栈帧的局部变量s被赋值为sum方法的返回值3。
附加信息
附加信息,是指在进行方法调用时,除了明确的参数和返回值之外,还可以传递的一些额外信息。从理论上讲,它提供了一种传递方法调用的额外上下文的方式,对JVM内部来说可以提供更多信息。一些专业的程序分析和追踪工具可能会用到它们,对日常开发影响不大。
本地方法栈
本地方法栈(Native Method Stack):与虚拟机栈类似,用于支持Native方法的执行。关于本地方法,可参考Java本地方法/Java native方法/JNI_jni native方法_小王师傅66的博客-CSDN博客
总结:
JVM运行时数据区主要包括:方法区,堆,虚拟机栈,程序计数器,本地方法栈。
方法区(Method Area):用于存储类信息、静态变量、静态方法等数据,可以理解为所有线程共享的内存区域。方法区无法满足新的内存分配需求时,会抛出OutOfMemeoryError异常;
堆内存(Heap):用于存储对象实例,可以理解为所有线程共享的内存区域。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出OutOfMemoryError异常。可以通过调整-Xms和-Xmx参数调整堆空间;
虚拟机栈(VM stack):用于存储局部变量表、操作栈、动态链接、方法返回地址/方法出口等信息,属于线程私有。每个线程都有自己的虚拟机栈。当线程请求的栈深度超过虚拟机所允许的最大深度时,就会抛出 StackOverflowError 异常。当虚拟机栈的空间无法分配时,将抛出 OutOfMemoryError 异常。可以通过调整-Xss参数调整栈空间;
程序计数器(PC Register):用于存储指向下一条将要执行的指令的地址,每个线程都有自己的程序计数器,它的空间是非常小的,基本不会发生溢出的情况。
本地方法栈(Native Method Stack):与虚拟机栈类似,用于支持Native方法的执行。本地方法栈也是线程私有,与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。