目录
单片机堆栈指针的介绍
引用
一、堆栈指针sp的简介
1、堆栈的两种方式(向上模型与向下模型)
2、两种模型的优缺点
二、堆栈的实现方法
深入理解ARM三个寄存器
三级流水线
三个寄存器
栈的整体作用
1. 保护现场
2. 传递参数
3. 临时变量保存在栈中
单片机堆栈指针的介绍
引用
堆栈指针SP是CPU中用来指示当前堆栈顶部位置的寄存器。在计算机中,堆栈主要用来保存临时数据、局部变量和中断/调用子程序程序的返回地址。堆栈的指针SP初始化一般在堆栈段的高地址,也就是内存的高地址,然后让堆栈指针向下增长(递减)。这样做的好处是将堆栈空间远离其他段,避免与其他段重叠,防止修改其他段数据而引起不可预料的后果。同时,设置堆栈大小的原则是确保栈不会下溢出到数据空间或程序空间。堆栈溢出是指堆栈指针SP向下增长到其他段空间,如果栈指针向下增长到其他段空间,就称为堆栈溢出。堆栈溢出会修改其他空间的值,严重情况下可能导致系统崩溃。因此,在调用C程序之前,必须设定堆栈指针SP。
一、堆栈指针sp的简介
堆栈指针sp在片内RAM128B中开辟栈区,并随时跟踪栈顶地址。它是按"先进后出"的原则存取数据。开机复位后,单片机栈底地址为07H。
主要用来保存临时数据,局部变量和中断%2F自程序的返回地址。
堆栈指针总是指向栈顶元素。所以数据入栈的时候,堆栈指针先加1,再压栈。向上增长方式。和计算机的方式一样。
出栈的时候先弹出数据,堆栈指针再减1。
1、堆栈的两种方式(向上模型与向下模型)
- 如果堆栈的实现是往上长的(就是说往顶的方向长,其实质是你的栈底是定死的不能动,入栈的东西只能不断往上叠,这就像你在书桌上放书一样,桌底是定死的,所以你的书只能一本一本地往上堆,往上长),计算机内部的堆栈的实现采取的就是这种模式,所以就得像你说的那样,“先修改指针,然后插入数据,出栈时刚好相反”,因为你堆栈指针指向的总是栈顶元素,栈底不能动,所以数据入栈前要先修改指针使它指向新的空余空间然后再把数据存进去,出栈的时候自然相反。
- 然而,如果堆栈的实现是往下长的(就是说你每压一个元素入栈,栈底就自动下移一个元素的位置,其实质就是这种堆栈模型是一个“无底洞”型),这个时候,你的栈顶就变成了定死的,你就可以先压入元素,然后再修改指针。因为你的栈底是无限的,你压入一个元素,新的元素就取代先前的栈顶元素占据栈顶的位置,那么你先前的指向栈顶元素的指针这个时候就该修改让它指向这个新的栈顶元素了。
下面的就是对“无底洞”型堆栈的一种实现的描述:
压栈(入栈):将对象或者数据压入栈中,更新栈顶指针,使其指向最后入栈的对象或数据。
弹栈(出栈):返回栈顶指向的对象或数据,并从栈中删除该对象或数据,更新栈顶。
2、两种模型的优缺点
话说回来,计算机内部肯定选第一种模型,不会选第二种,因为第二种模型,每压入一个新的元素,都需要把之前堆栈里的所有元素整体下移动一个元素的位置,腾出栈顶元素的位置让新的元素进来,这种平移可是一笔不小的开销啊!但是并不是说“无底洞”模型就没办法实现了,其实它可以通过第一种模型来模拟的,每需要压入一个新的元素的时候,就先开辟一个空间,数据存入这个空间,然后再修改栈顶元素指针使其指向这个新的栈顶元素。
换句话说,用链表的话,只要有足够的空间可开辟出来作为一个节点,那么两种堆栈模型都能实现(当然“无底洞”型还是如我上面说的那样用第一种模拟出来的,否则平移的工作量相当可观),如果用数组,由于数组在内存中是连续分配出来的空间,用第一种模型更自然一些。
二、堆栈的实现方法
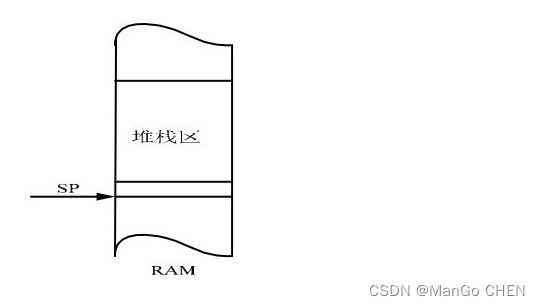
在随机存储器区划出一块区域作为堆栈区,数据可以一个个顺序地存入(压入)到这个区域之中,这个过程称为‘压栈’(push )。通常用一个指针(堆栈指针 SP—StackPointer)实现做一次调整,SP总指向最后一个压入堆栈的数据所在的数据单元(栈顶)。从堆栈中读取数据时,按照堆栈 指针指向的堆栈单元读取堆栈数据,这个过程叫做 ‘弹出’(pop ),每弹出一个数据,SP 即向相反方向做一次调整,如此就实现了后进先出的原则。
堆栈是计算机中广泛应用的技术,基于堆栈具有的数据进出LIFO特性,常应用于保存中断断点、保存子程序调用返回点、保存CPU现场数据等,也用于程序间传递参数。
ARM处理器中通常将寄存器R13作为堆栈指针(SP)。ARM处理器针对不同的模式,共有 6 个堆栈指针(SP),其中用户模式和系统模式共用一个SP,每种异常模式都有各自专用的R13寄存器(SP)。它们通常指向各模式所对应的专用堆栈,也就是ARM处理器允许用户程序有六个不同的堆栈空间。这些堆栈指针分别为R13、R13_svc、R13_abt、R13_und、R13_irq、R13_fiq,如表2-3堆栈指针寄存器所示。

为了更准确地描述堆栈,根据“压栈”操作时堆栈指针的增减方向,将堆栈区分为‘递增堆栈’(SP 向大数值方向变化)和‘递减堆栈’(SP 向小数值方向变化);又根据SP 指针指向的存储单元是否含有堆栈数据,又将堆栈区分为‘满堆栈’(SP 指向单元含有堆栈有效数据)和‘空堆栈’(SP 指向单元不含有堆栈有效数据)。
这样两两组合共有四种堆栈方式——满递增、空递增、满递减和空递减。
ARM处理器的堆栈操作具有非常大的灵活性,对这四种类型的堆栈都支持。
ARM处理器中的R13被用作SP。当不使用堆栈时,R13 也可以用做通用数据寄存器。
深入理解ARM三个寄存器
深入理解ARM的这三个寄存器,对编程以及操作系统的移植都有很大的裨益。
三级流水线
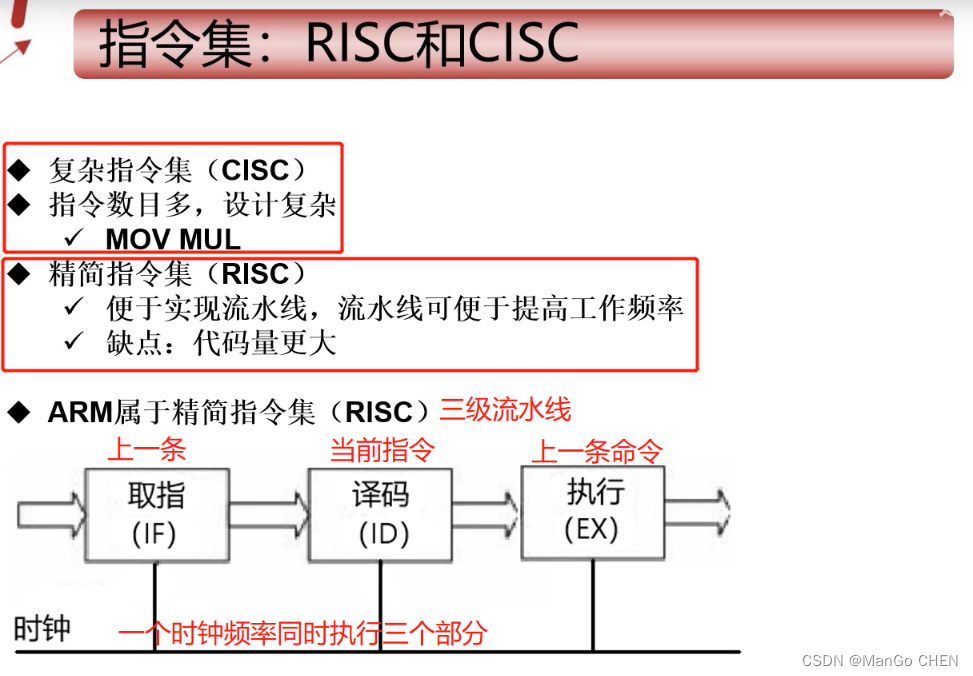
PC 代表程序计数器,流水线使用三个阶段,因此指令分为三个阶段执行:
- 1.取指(从存储器装载一条指令);
- 2.译码(识别将要被执行的指令);
- 3.执行(处理 指令并将结果写回寄存器)。
R15(PC)总是指向“正在取指”的指令
ARM指令是三级流水线,取指,译指,执行时同时执行的,现在PC指向的是正在取指的地址,那么cpu正在译指的指令地址是PC-4(假设在ARM状态 下,一个指令占4个字节),cpu正在执行的指令地址是PC-8,也就是说PC所指向的地址和现在所执行的指令地址相差8。
当突然发生中断的时候,保存的是PC的地址
这样你就知道了,如果返回的时候返回PC,那么中间就有一个指令没有执行,所以用SUB pc lr-irq #4。
三个寄存器
1、堆栈指针r13(SP):每一种异常模式都有其自己独立的r13,它通常指向异常模式所专用的堆栈,也就是说五种异常模式、非异常模式(用户模式和系统模式),都有各自独立的堆栈,用不同的堆栈指针来索引。这样当ARM进入异常模式的时候,程序就可以把一般通用寄存器压入堆栈,返回时再出栈,保证了各种模式下程序的状态的完整性。
2、连接寄存器r14(LR):每种模式下r14都有自身版组,它有两个特殊功能。
- (1)保存子程序返回地址。使用BL或BLX时,跳转指令自动把返回地址放入r14中;子程序通过把r14复制到PC来实现返回,通常用下列指令之一:
MOV PC, LR
BX LR
通常子程序这样写,保证了子程序中还可以调用子程序。
stmfd sp!, {lr}
……
ldmfd sp!, {pc}
- (2)当异常发生时,异常模式的r14用来保存异常返回地址,将r14入栈可以处理嵌套中断。
3、程序计数器r15(PC):PC是有读写限制的。当没有超过读取限制的时候,读取的值是指令的地址加上8个字节,由于ARM指令总是以字对齐的,故bit[1:0]总是00。当用str或stm存储PC的时候,偏移量有可能是8或12等其它值。在V3及以下版本中,写入bit[1:0]的值将被忽略,而在V4及以上版本写入r15的bit[1:0]必须为00,否则后果不可预测。
ARM处理器使用流水线来增加处理器指令流的速度,这样可使几个操作同时进行,并使处理与存储器系统之间的操作更加流畅,连续,能提供0.9MIPS/MHZ的指令执行速度。
栈的整体作用
1. 保护现场
现场/上下文相当于案发现场,总有一些案发现场,要记录下来,否则被别人破坏,便无法恢复。而此处说的现场,是指CPU运行时,用到的一些寄存器,比如r0,r1等,对于这些寄存器的值,如果不保存而直接跳转到子函数中执行,其很可能被破坏,因为其函数执行也要用到这些寄存器。因此,在函数调用之前,应该将这些寄存器等现场暂时保存(入栈push),等调用函数执行完毕后出栈(pop)再恢复现场。这样CPU就可以正确的继续执行了。
保存寄存器的值,一般用push指令,将对应的某些寄存器的值,一个个放到栈中,即所谓的压栈。然后待被调用的子函数执行完毕后再调用pop,把栈中的一个个的值,赋值给对应的那些你刚开始压栈时用到的寄存器,把对应的值从栈中弹出去,即所谓的出栈。
其中保存的寄存器中,也包括lr的值(因为用bl指令进行跳转的话,之前的pc值存在lr中),在子程序执行完毕后,再把栈中的lr值pop出来,赋值给pc,这样就实现了子函数的正确的返回。
2. 传递参数
C语言函数调用时,会传给被调用函数一些参数,对于这些C语言级别参数,被编译器翻译成汇编语言时,要找个地方存放下来,并且让被调用函数能访问,否则没法传递。找个地方存放下来分2种情况。
- 一是,本身传递的参数不多于4个,可以通过寄存器传送。因为在前面的保存现场动作中,已经保存好对应的寄存器的值,此时这些寄存器是空闲的,可以供我们使用存放参数。
- 二是,参数多于4个,寄存器不够用,就得用栈。
3. 临时变量保存在栈中
这些临时变量包括函数的非静态局部变量以及编译器自动生成的其他临时变量
举例分析C语言函数调用如何使用栈
上面的解释有些抽象,此处再用例子简单说明一下,就容易明白了:
用arm-inux-objdump –d u-boot dump_u-boot.txt得到dump_u-boot.txt文件。该文件是包含了u-boot可执行汇编代码,从中我们可以看到相应C程序对应的汇编代码。
下面贴出两个函数的汇编代码,一个是clock_init,另一个是与clock_init在同一C源文件中的函数CopyCode2Ram:
33d0091c: CopyCode2Ram:
33d0091c: e92d4070 push {r4, r5, r6, lr}
33d00920: e1a06000 mov r6, r0
33d00924: e1a05001 mov r5, r1
33d00928: e1a04002 mov r4, r2
33d0092c: ebffffef bl 33d008f0 b BootFrmNORFlash
......
33d00984: ebffff14 bl 33d005dc nand_read_ll
......
33d009a8: e3a00000 mov r0, #0 ; 0x0
33d009ac: e8bd8070 pop {r4, r5, r6, pc}
33d009b0:clock_init:
33d009b0: e3a02313 mov r2, #1275068416 ;0x4c000000
33d009b4: e3a03005 mov r3, #5 ; 0x5
33d009b8: e5823014 str r3,
......
33d009f8: e1a0f00e mov pc, lr
(1) 先分析clock_init对应的汇编代码,可以看到该函数第一行
:33d009b0: e3a02313 mov r2, #1275068416 ;0x4c000000
没有我们期望的push指令,即没有将一些寄存器的值放入栈。这是因为,clock_init用到的r2,r3等寄存器,和前面调用clock_init前用到的寄存器r0,没有冲突,故此处不用push保存,有个寄存器要注意,r14,即lr,前面调用clock_init时,用的bl指令,所以会自动把跳转时的pc值赋值给lr,所以也不需要push将PC值保存到栈。而clock_init对应的汇编代码最后一行: 33d009f8: e1a0f00e mov pc, lr 就是我们常见的mov pc,lr,把lr值,即之前保存的函数调用时的PC值,赋值给现在的PC,这样便实现了函数的正确返回,即返回到了函数调用时下一个指令的位置。CPU可以继续执行原先函数内剩下的代码。
(2) CopyCode2Ram对应汇编代码第一行:33d0091c: e92d4070 push {r4, r5, r6, lr}
就是我们所期望的,用push保存r4,r5,r6,lr,是因为此函数还包括其他函数调用
:33d0092c: ebffffef bl 33d008f0 b BootFrmNORFlash……
33d00984: ebffff14 bl 33d005dc nand_read_ll
……
也用到bl指令,会改变我们最开始进入clock_init时的lr值,所以也要push暂时保存起来。
而对应地,CopyCode2Ram最后一行:33d009ac: e8bd8070 pop {r4, r5, r6,pc}是把之前push的值给pop出来,还给对应的寄存器,其中最后一个是将开始push的lr的值pop出来赋给PC,实现了函数的返回。另外我们注意到,CopyCode2Ram的倒数第二行:33d009a8: e3a00000 movr0, #0 ; 0x0 是把0赋值给r0寄存器,就是我们说的返回值的传递,此处的返回值为0,也对应着C代码中的“ return 0”。
当然也可以用其他暂时空闲没有用到的寄存器来传递返回值。
对于使用哪个寄存器来传递返回值,是根据ARM的APCS寄存器的使用约定而设计的,最好按照其约定的来处理,不要随便改变它。这样程序将更加规范。