我们先来弄一个最基础的infer类:
class Infer{ public: bool load_model(const string &file){ context_ = file; return true; } void forward(){ if(context_.empty()){ printf("加载模型异常\n"); return; } printf("使用%s进行推理\n " , context_.c_str()); } void destroy(){ context_.clear(); } private: string context_; };正常的模型是很复杂的,但在这里我们就用string代替了。
那这个代码重点就在于异常逻辑,在正常工作代码中,异常逻辑如果没有写好,就会造成封装的不安全性,甚至会导致程序崩溃。
比如之前的load model:如果没有load过还好,但是如果load过了,那不久导致了两次load_model么?
bool load_model(const string &file){
if (!context_.empty())
{
/* code */destroy();
}
context_ = file;
return true;
} 所以在load前要先看一眼,如果load过了就destroy
这个时候就能引出我们的RAII + 接口模式了
RAII
RAII -------> 资源获取即初始化
接口i模式 ------> 设计模式,是一种封装模式,实现类与接口分离的模式
那就是将原本的
Infer infer_;
infer.load_model("aa");合为一步,即获取就可以初始化
shared_ptr <Infer> create_infer(const string& file){
shared_ptr <Infer> instance(new Infer);
if (!instance->load_model(file))
{
instance.reset();
}
return instance;
}
所以这里是表示如果模型加载失败,则代表资源获取失败,返回空指针。
int main(){
auto infer_ = create_infer("aa");
if (infer_ == nullptr)
{
/* code */printf("failed\n");
return -1;
}
infer_->forward();
return 0;
}
所以现在的结果非常简单,只要为空指针则表示失败。不为空则成功。
这样就避免了外部执行load_model(RAII制作到一部分没有完全做到)。
避免了load_model不会执行超过一次
获取的模型一定初始化成功,因此forward不用判断模型初始化成功。
load model中可以删除对于重复load的判断,forward可以删掉是否家在成功的判断。
接口模式封装:
那么既然我们已经能用create了,可基于Infer的public属性,还是可以调用load_model的,所以就要进入到接口模式封装了。
接口模式解决问题:
1、解决load_model还能被外部看到的问题。
2、解决成员变量对外可见的问题(比如成员函数是特殊类型的,比如cudaStream_t ,那么头文件必须包含cuda_runtime.h,就会造成命名空间污染,头文件污染的问题 , 不干净的结果就会造成程序错误等异常)
接口类是一个纯虚类
原则是只暴露调用者需要的函数,其他一概隐藏起来
比如说load_model,咱们通过RAII做了定义,因此load_model属于不需要的范畴
内部如果有启动线程等等,start , stop ,也不需要暴露 , 而是初始化的时候自动启动,都是RAII的定义
class InferInterface
{
private:
/* data */
public:
virtual void forward() = 0 ;
};
forward 要做成纯虚函数。
class InferImpl : public InferInterface{
public:
bool load_model(const string &file){
context_ = file;
return true;
}
virtual void forward()override{
printf("使用%s进行推理\n " , context_.c_str());
}
void destroy(){
context_.clear();
}
private:
string context_;
};然后要让原来的类继承于接口类
shared_ptr <InferInterface> create_infer(const string& file){
shared_ptr <InferImpl> instance(new InferImpl);
if (!instance->load_model(file))
{
instance.reset();
}
return instance;
}在返回类型的时候返回的是Interface , 在new的时候选的是InferImpl。
这样作为一个使用者除了forward真的还没有其他的可选项。
之后可以再进一步设置Infer.hpp作为头文件
#ifndef INFER_HPP
#define INFER_HPP
#include<memory>
#include<string>
class InferInterface
{
private:
/* data */
public:
virtual void forward() = 0 ;
};
std::shared_ptr <InferInterface> create_infer(const std::string& file);
#endif /. INFER_HPP实现放到Infer.cpp中:
#include "infer.hpp"
using namespace std;
class InferImpl : public InferInterface{
public:
bool load_model(const string &file){
context_ = file;
return !context_.empty();
}
virtual void forward()override{
printf("使用%s进行推理\n " , context_.c_str());
}
void destroy(){
context_.clear();
}
private:
string context_;
};
shared_ptr <InferInterface> create_infer(const string& file){
shared_ptr <InferImpl> instance(new InferImpl);
if (!instance->load_model(file))
{
instance.reset();
}
return instance;
}这样在main函数里就只需要
#include"infer.hpp"
using namespace std;
int main(){
auto infer_ = create_infer("aa");
if (infer_ == nullptr)
{
/* code */printf("failed\n");
return -1;
}
infer_->forward();
return 0;
}
这样就做到了
- 头文件只依赖最简单的
- 成员变量看不到
- 只能访问forward
RAII接口总结原则:
1、头文件应尽量简洁
2、不需要的东西都放到cpp当中,不要让接口类看到
比如:
#include <cudaruntime.h> class InferInterface { private: cudaStream_t stream; public: virtual void forward() = 0 ; };这样就不符合尽量简洁的原则,因为这里用不到stream,应该尽可能放到cpp里。
3、尽量不要在头文件写using namespace,因为写了这个就代表命名空间被打开了,这样就使得所有包含了这个头文件的人的所有命名空间都被打开。但CPP里可以写
多batch实现:
在这里我们主要是进行一个推理的实现。
老规矩:弄一个线程worker_thread_,为了尽量使得资源尽量那里分配那里释放,这样可以保证程序足够简单。在worker内实现模型的家在,使用,与释放。
那样的话
bool load_model(const string &file){
//使得资源尽量那里分配那里释放,这样可以保证程序足够简单
worker_thread_ = thread(&InferImpl::worker , this , file);
return context_.empty();
} 这肯定是不可以的,毕竟这个线程还没来的及进行worker,就要return了
这时候就要使用future
bool load_model(const string &file){
//使得资源尽量那里分配那里释放,这样可以保证程序足够简单
promise<bool> pro;
worker_thread_ = thread(&InferImpl::worker , this , file , ref(pro));
context_ = file;
return pro.get_future().get();
} 对应的worker:
void worker(string file , promise<bool>&pro){
string context_ = file;
if (context_.empty())
{
/* code */pro.set_value(false);
}else
{
pro.set_value(true);
}
while (true)
{
/* code */
}
}这样我们就完成了在局部内加载使用释放
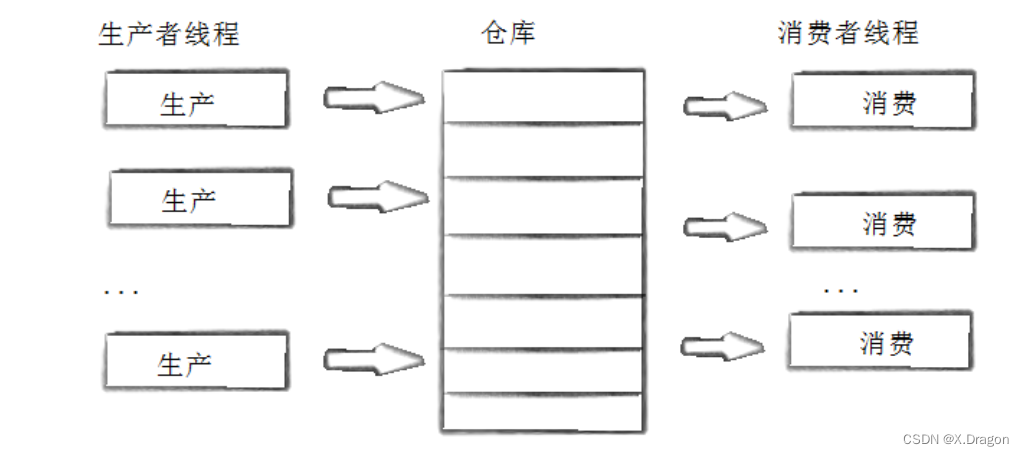
仿照上一节完成一下消费者模式:
struct Job{
shared_ptr<promise<string>>pro;
string input;
};
class InferImpl : public InferInterface{
public:
bool load_model(const string &file){
//使得资源尽量那里分配那里释放,这样可以保证程序足够简单
promise<bool> pro;
worker_thread_ = thread(&InferImpl::worker , this , file , ref(pro));
return pro.get_future().get();
}
virtual void forward(string pic) override{
// printf("使用%s进行推理\n " , context_.c_str());
Job job;
job.pro.reset(new promise<string>());
job.input = pic;
lock_guard<mutex> l(job_lock);
qjobs_.push(job);
}
//实际的推理阶段
void worker(string file , promise<bool>&pro){
string context_ = file;
if (context_.empty())
{
/* code */pro.set_value(false);
}else
{
pro.set_value(true);
}
while (true)
{
if (!qjobs_.empty())
{
lock_guard<mutex> l(job_lock);
auto job = qjobs_.front();
qjobs_.pop();
//inference:
printf();
}
this_thread::yield();
}
}
private:
thread worker_thread_;
queue<Job> qjobs_;
mutex job_lock;
condition_variable cv_;
};但这里每次都是一个一个地拿出来pop,我们要的是多batch,最好是一次能拿batchsize个出来。
这是就可以用vector:
int maxbatchsize = 5;
vector<Job> jobs;
while (true)
{
if (!qjobs_.empty())
{
lock_guard<mutex> l(job_lock);
while (jobs.size < maxbatchsize && !qjobs_.empty())
{
jobs.emplace_back( qjobs_.front());
qjobs_.pop();
}
//inference:
printf();
}
this_thread::yield();
} 通知模式
那我们这个消费者不能一直while(true)啊,于是就要对其进行一个通知,也就是有东西进来了,再进行消费。所以就要使用到condition_variable的wait()和notify_one()了。
virtual void forward(string pic) override{
// printf("使用%s进行推理\n " , context_.c_str());
Job job;
job.pro.reset(new promise<string>());
job.input = pic;
lock_guard<mutex> l(job_lock);
qjobs_.push(job);
cv_.notify_one();
}在传入的时候通知一下我。
void worker(string file , promise<bool>&pro){
string context_ = file;
if (context_.empty())
{
/* code */pro.set_value(false);
}else
{
pro.set_value(true);
}
int maxbatchsize = 5;
vector<Job> jobs;
//i消费者:
while (true)
{
unique_lock<mutex> l(job_lock);
cv_.wait(l , [&]{
return !qjobs_.empty();
});
while (jobs.size() < maxbatchsize && !qjobs_.empty())
{
jobs.emplace_back( qjobs_.front());
qjobs_.pop();
}
//inference:
printf();
}
}在这里要进行一个等待。之后还可以去除qjobs_.empty()的判断。
这种通知的模式也要比我们之前主动检查模式要更好。
之后就要进行推理了:
for (int i = 0; i < jobs.size(); i++) { auto& job = jobs[i]; char result [100]; sprintf(result ,"%s : batch-> %d [%d]" , job.input.c_str() , batch_id , jobs.size()); job.pro->set_value(result); } batch_id++; jobs.clear(); this_thread::sleep_for(chrono::milliseconds(1000));
而这个时候set_value过后我们就要考虑一下返回的操作了。
返回future格式
如果forward是采用了
virtual string forward(string pic) override{
// printf("使用%s进行推理\n " , context_.c_str());
Job job;
job.pro.reset(new promise<string>());
job.input = pic;
lock_guard<mutex> l(job_lock);
qjobs_.push(job);
cv_.notify_one();
return job.pro->get_future().get();
}这种形式进行返回的话,get() will wait until the whole inference , this not the meaning of batchs
virtual shared_future<string> forward(string pic) override{
// printf("使用%s进行推理\n " , context_.c_str());
Job job;
job.pro.reset(new promise<string>());
job.input = pic;
lock_guard<mutex> l(job_lock);
qjobs_.push(job);
cv_.notify_one();
return job.pro->get_future();
}这样的话就可以直接返回future,让执行人有更多的选择。
int main(){
auto infer_a = create_infer("aa");
auto result_a = infer_a->forward("aa");
auto result_b =infer_a->forward("bb");
auto result_c =infer_a->forward("cc");
printf("%s \n" , result_a.get().c_str());
printf("%s \n" , result_b.get().c_str());
printf("%s \n" , result_c.get().c_str());
return 0;
}执行过后:

可见是一个batch去实现的。
但是如果要是先get的话,
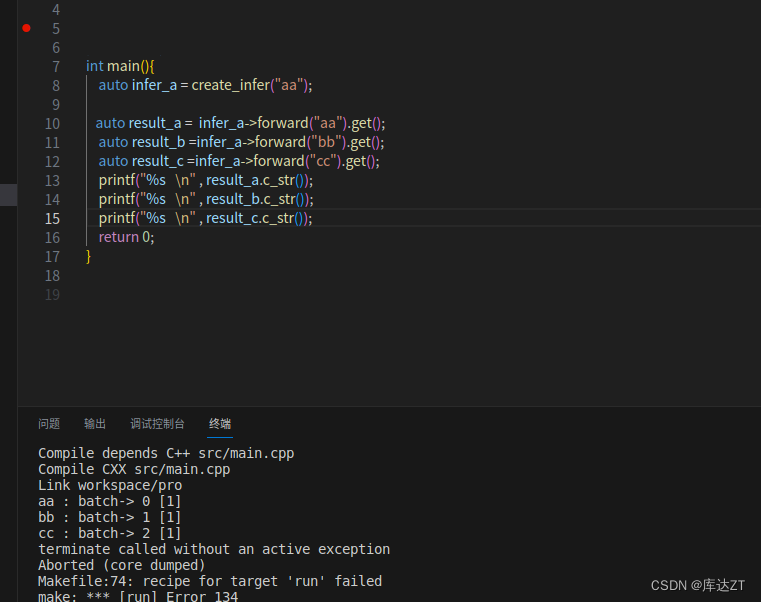
那就是分批次了,因为get就代表必须完成整个步骤之后返回。
退出模型
atomic<bool> running_{false};设立私有变量,表示程序是否还在运行。
在loadmodel时设立running_为true
bool load_model(const string &file){
//使得资源尽量那里分配那里释放,这样可以保证程序足够简单
running_ = true;
promise<bool> pro;
worker_thread_ = thread(&InferImpl::worker , this , file , ref(pro));
return pro.get_future().get();
} void worker(string file , promise<bool>&pro){
string context_ = file;
if (context_.empty())
{
/* code */pro.set_value(false);
}else
{
pro.set_value(true);
}
int maxbatchsize = 5;
vector<Job> jobs;
int batch_id = 0;
//i消费者:
while (running_)
{
unique_lock<mutex> l(job_lock);
cv_.wait(l , [&]{
return !qjobs_.empty() || !running_;
});
if(! running_){
break;
}
while (jobs.size() < maxbatchsize && !qjobs_.empty())
{
jobs.emplace_back( qjobs_.front());
qjobs_.pop();
}
for (int i = 0; i < jobs.size(); i++)
{
auto& job = jobs[i];
char result [100];
sprintf(result ,"%s : batch-> %d [%d]" , job.input.c_str() , batch_id , jobs.size());
job.pro->set_value(result);
}
batch_id++;
jobs.clear();
this_thread::sleep_for(chrono::milliseconds(1000));
}
printf("释放->%s \n", context_.c_str());
context_.clear();
printf("Worker Done\n");
}同时worker也要改变,while的判断机制也需要改变,cv_.wait也不能是只有qjobs为空,还要加上是否还在运行。如果不运行了要break出while循环。
在结束之后要释放模型。
析构函数
virtual ~InferImpl(){
running_ = false;
cv_.notify_one();
if(worker_thread_.joinable()){
worker_thread_.join();
}
} 重点在于析沟函数,在该类退出后设置线程同步,并且在running_设置为false的时候通知一次wait。






![[腾讯云Cloud Studio实战训练营]基于Cloud Studio完成图书管理系统](https://img-blog.csdnimg.cn/62e85a4e6dd14d68829b4d7583856e7b.png)