目录
前言:
1.缓冲流:
2.转换流:
3.序列化流:
4.打印流:
5.压缩流:
总结:
前言:
在前面我们从IO流体系出发,分别介绍了字节流和字符流,并且详细讲解了其下沿的各种基本流,而在今天我们就要学习一下IO流中的几个高级流。
1.缓冲流:

缓冲流其实就是可以让我们自己手动提供缓冲区,以此来增加读写速度,我们知道字节流是没有缓冲区的,因此创建一个缓冲区对于字节流的读写速度提高是很明显的。
缓冲区是计算机科学中常用的一个概念,用于在不同速度的系统或设备之间传输数据时解决速度不匹配的问题。它是用来临时存储数据的一段内存区域,可用于暂时保存输入数据、输出数据或处理中间数据。
缓冲区通常用于处理输入/输出(I/O)操作,例如在文件读写、网络通信、图像处理等过程中。它能够提高数据传输的效率,减少因速度不匹配而导致的延迟和性能瓶颈。
总结来说,缓冲区是一种临时存储数据的内存区域,可以解决不同速度设备之间数据传输的速度不匹配问题,提高系统的效率。它在输入/输出操作和数据处理过程中起到关键的作用。
- 字节缓冲流(BufferedInputStream和BufferedOutputStream):
- BufferedInputStream:将字节输入流包装起来,提供了在内存中创建缓冲区的功能,这样可以减少磁盘IO次数。
- BufferedOutputStream:将字节输出流包装起来,同样提供了缓冲区,可以减少磁盘IO次数。
示例代码:
import java.io.*;
public class ByteStreamExample {
public static void main(String[] args) {
try {
// 创建字节输入流
FileInputStream fileInputStream = new FileInputStream("input.txt");
// 使用字节缓冲流包装字节输入流
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
// 创建字节输出流
FileOutputStream fileOutputStream = new FileOutputStream("output.txt");
// 使用字节缓冲流包装字节输出流
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
// 读取文件内容并写入到目标文件
int data;
while ((data = bufferedInputStream.read()) != -1) {
bufferedOutputStream.write(data);
}
// 关闭流
bufferedInputStream.close();
bufferedOutputStream.close();
System.out.println("文件复制成功");
} catch (IOException e) {
e.printStackTrace();
}
}
}
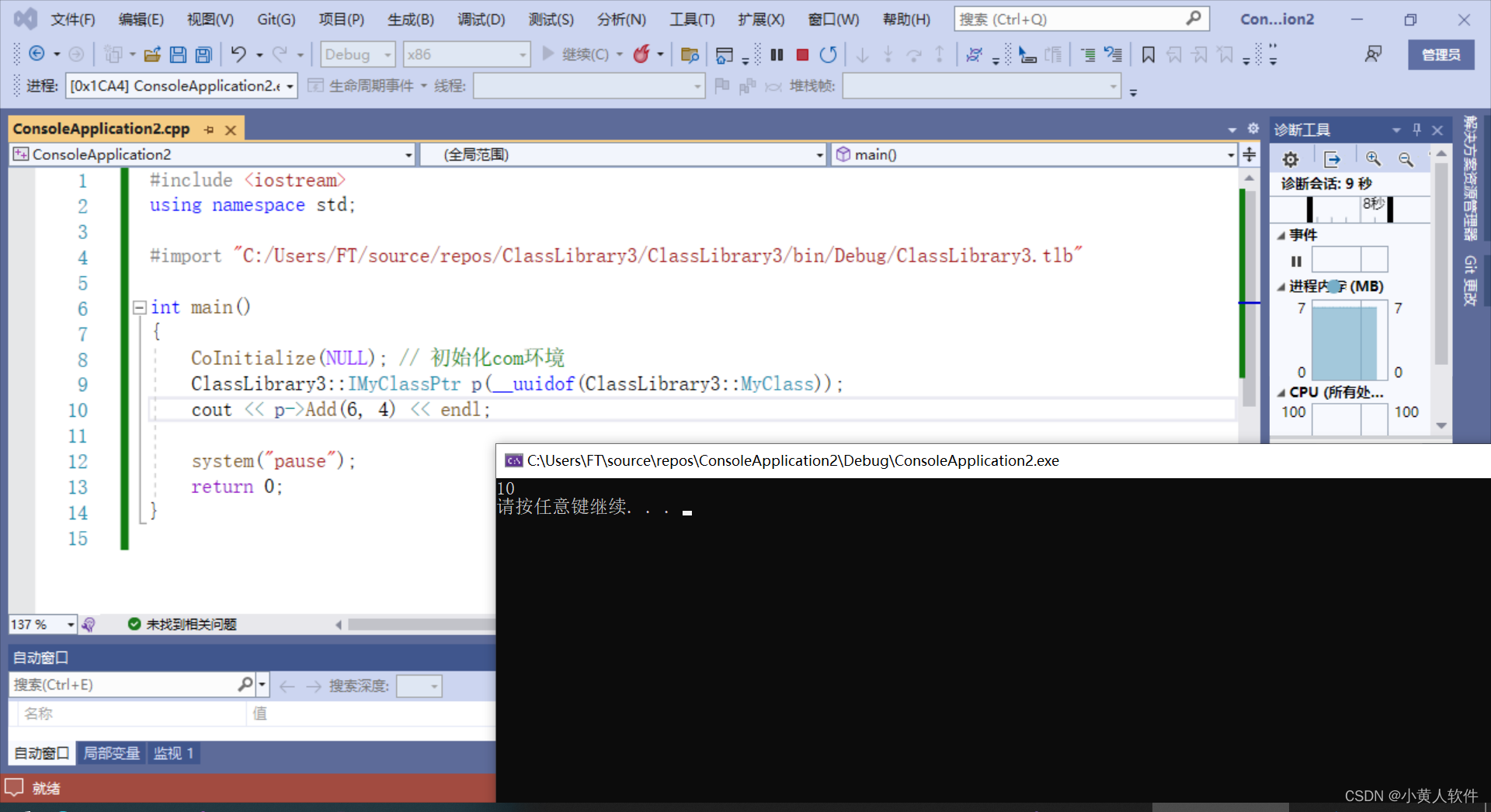
字节缓冲流的底层默认就自带了一个长度为8192的缓冲区,这在我们一开始学习到的基本字节流中是没有的。但其实字节缓冲流本质上只是对基本字节流的一个包装,在读取数据的时候依然是基本字节流在读取数据,并不是什么新的方法。
我们可以通过调试这段代码看到缓冲区:
- 字符缓冲流(BufferedReader和BufferedWriter):
- BufferedReader:将字符输入流包装起来,提供了在内存中创建缓冲区的功能,可以一次读取一行字符数据。
- BufferedWriter:将字符输出流包装起来,同样提供了缓冲区,可以一次写入一行字符数据。
示例代码:
import java.io.*;
public class CharacterStreamExample {
public static void main(String[] args) {
try {
// 创建字符输入流
FileReader fileReader = new FileReader("input.txt");
// 使用字符缓冲流包装字符输入流
BufferedReader bufferedReader = new BufferedReader(fileReader);
// 创建字符输出流
FileWriter fileWriter = new FileWriter("output.txt");
// 使用字符缓冲流包装字符输出流
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
// 读取文件内容并写入到目标文件
String line;
while ((line = bufferedReader.readLine()) != null) {
bufferedWriter.write(line);
bufferedWriter.newLine();
}
// 关闭流
bufferedReader.close();
bufferedWriter.close();
System.out.println("文件复制成功");
} catch (IOException e) {
e.printStackTrace();
}
}
}虽然基本的字符流方法就自带缓冲区,但是我们缓冲字符流也提供了一些很好的方法来便捷我们的使用。
readLine在读取方法时候,一次读一整行,遇到回车换行就结束
但是他不会把回车换行读到内存中

缓冲流的优点:
1. 提高读写性能:缓冲流通过在内存中创建缓冲区,减少IO操作的次数,从而提高读写性能。它们可以一次读取或写入多个字节或字符,减少了与磁盘或网络的交互次数。
2. 减少系统开销:使用缓冲流可以减少系统调用次数和CPU的使用率。通过将数据保存在内存中的缓冲区中,在进行大规模数据读写时,可以显著降低系统开销和资源消耗。
3. 支持高效的字符处理:字符缓冲流(BufferedReader和BufferedWriter)提供了方便的方法,比如一次读取一行字符数据或一次写入一行字符数据。这对于处理文本文件非常有用,可以简化代码并提高代码的可读性。
4. 缓冲区自动管理:缓冲流会自动管理缓冲区的大小和数据的填充和清空,无需手动处理。这样可以简化代码编写,并提高代码的可维护性。
5. 可以与其他IO流结合使用:缓冲流可以与其他各种字节流或字符流结合使用,如文件流、网络流等。这使得在不同场景下进行读写操作更加灵活和高效。
2.转换流:
转换流(InputStreamReader和OutputStreamWriter)是Java IO库中的字符流,用于在字节流和字符流之间进行转换。它们提供了将字节流转换为字符流的能力,以便更方便地处理文本数据。
转换流的主要作用是解决字节流和字符流之间的编码转换问题。在读取或写入文本数据时,需要将字节数据转换为字符数据或将字符数据转换为字节数据。转换流在内部实现了字符集的转换,可以根据指定的字符集将字节流转换为字符流,或将字符流转换为字节流。
转换流的构造函数接受两个参数:字节流和字符集。其中,字节流可以是字节输入流或字节输出流,而字符集可以是标准字符集名称或特定字符集名称。
主要的转换流类及其作用如下:
- InputStreamReader:
- 作用:将字节输入流转换为字符输入流。
- 构造函数:
- InputStreamReader(InputStream in):创建一个默认字符集的InputStreamReader对象。
- InputStreamReader(InputStream in, Charset cs):创建一个使用指定字符集的InputStreamReader对象。
- 示例代码:
import java.io.*;
public class InputStreamReaderExample {
public static void main(String[] args) {
try {
FileInputStream fileInputStream = new FileInputStream("input.txt");
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
bufferedReader.close();
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
- OutputStreamWriter:
- 作用:将字节输出流转换为字符输出流。
- 构造函数:
- OutputStreamWriter(OutputStream out):创建一个默认字符集的OutputStreamWriter对象。
- OutputStreamWriter(OutputStream out, Charset cs):创建一个使用指定字符集的OutputStreamWriter对象。
- 示例代码:
import java.io.*;
public class OutputStreamWriterExample {
public static void main(String[] args) {
try {
FileOutputStream fileOutputStream = new FileOutputStream("output.txt");
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream, "UTF-8");
BufferedWriter bufferedWriter = new BufferedWriter(outputStreamWriter);
bufferedWriter.write("Hello, World!");
bufferedWriter.newLine();
bufferedWriter.write("你好,世界!");
bufferedWriter.close();
outputStreamWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
通过使用转换流,我们可以在字节流和字符流之间进行方便的转换,使得处理文本数据更加简便和灵活。转换流还支持指定字符集,以便进行特定编码的读写操作。
转换流的存在主要是为了:让字节流使用字符流中的方法。
其实在以前,我们还可以利用转换流来使得读取文件的时候按照指定的字符编码读取。
3.序列化流:
序列化流是Java IO库中的一种特殊流,用于将对象转换为字节序列,以便存储到文件、数据库或通过网络进行传输。它们提供了对象的序列化和反序列化功能,使得可以方便地将对象持久化或在不同系统之间传输对象数据。
java中的序列化和反序列化是通过ObjectInputStream和ObjectOutputStream类来实现的,它们是字节流的子类,用于处理对象的读写操作。
序列化流的主要作用有以下几点:
-
对象的持久化:通过将对象转换为字节序列,可以将对象永久保存到磁盘上。这样即使程序结束,对象数据也可以被重新读取和使用。对象的持久化在很多场景中非常有用,比如保存用户信息、游戏进度等。
-
对象的传输:通过序列化流,可以将对象转换为字节序列,然后发送到网络上或通过进程间通信进行传输。接收方可以使用反序列化将字节序列转换回对象,以便获取传输的对象数据。这在分布式系统、远程方法调用等场景中非常常见。
序列化流的用法包括以下几个步骤:
- 对象的序列化:
- 创建一个输出流,如FileOutputStream或Socket.getOutputStream()。
- 创建一个ObjectOutputStream对象,将输出流传递给它。
- 使用ObjectOutputStream的writeObject()方法将对象写入输出流。该方法会将对象转换为字节序列并写入输出流。
try {
FileOutputStream fileOut = new FileOutputStream("object.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(object);
out.close();
fileOut.close();
} catch (IOException e) {
e.printStackTrace();
}
- 对象的反序列化:
- 创建一个输入流,如FileInputStream或Socket.getInputStream()。
- 创建一个ObjectInputStream对象,将输入流传递给它。
- 使用ObjectInputStream的readObject()方法从输入流中读取对象。该方法会将字节序列转换回对象。
try {
FileInputStream fileIn = new FileInputStream("object.ser");
ObjectInputStream in = new ObjectInputStream(fileIn);
Object object = in.readObject();
in.close();
fileIn.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
在进行对象的序列化和反序列化时,需要注意以下事项:
- 要求被序列化的类必须实现Serializable接口,该接口没有任何方法,只是起到一个标识作用,表明该类可以进行序列化。
- 被序列化的类中的字段也需要是可序列化的,即要求它们也是实现了Serializable接口的。
- 序列化和反序列化的顺序必须一致,否则会导致错误。
- 如果我们不想给对象中的某一个成员变量序列化,那么就使用transient关键字修饰,该关键字标记的成员变量不参与序列化过程。
使用序列化的注意点:
1. 类的版本控制:当你使用序列化流将对象写入文件时,类的定义可能会发生变化。为了确保在反序列化过程中能够正确地读取对象,你需要仔细控制类的版本。你可以使用 `serialVersionUID` 字段来指定类的版本号,并在类的变化过程中进行更新。
不过我们可以手动设置让idea能对此进行提示,方便我们快捷生成serialVersionUID
2. 数据完整性:序列化流允许你将整个对象图写入文件,包括对象之间的引用。然而,这也意味着你需要确保所有相关的对象都被正确地序列化和反序列化,以保持数据的完整性。如果某个对象没有被序列化或者反序列化,那么它在反序列化后可能会变成 `null` 或者其他未初始化的值。
3. 安全性考虑:序列化流允许你将对象写入文件并从文件中读取。这可能引发安全问题,因为恶意用户可能会修改序列化的数据。为了确保安全性,你应该对序列化的数据进行验证和过滤,以防止不可预测的行为。
4. 跨语言兼容性:序列化是一种用于对象持久化和传输的通用机制。然而,不同的编程语言可能会使用不同的序列化格式和机制。如果你计划在不同的编程语言之间进行对象的序列化和反序列化,你需要确保选择一个与目标编程语言兼容的序列化方式。
5. 性能问题:序列化和反序列化过程可能会占用大量的时间和资源。如果你需要频繁地将大量对象进行序列化和反序列化操作,你可能需要考虑性能优化方面的问题,例如使用更快速的序列化库或者改变序列化策略。、
总结来说,序列化流在Java IO库中是一种特殊的流,用于对象的序列化和反序列化操作,实现了对象的持久化和传输功能。通过序列化和反序列化,我们可以方便地将对象转换为字节序列,进行持久化存储或跨系统传输。
4.打印流:
打印流是Java IO库中的一种流,用于将数据以文本形式输出到控制台或文件。它提供了简洁易用的打印方法,方便用户进行输出操作。
Java中的打印流有两种主要的实现类:PrintStream和PrintWriter。
-
PrintStream:
PrintStream是字节打印流,它继承自OutputStream类,并且提供了一系列打印方法,例如print、println等。PrintStream可以接收字节数据,并将其转换为字符输出,它还具备自动刷新和在操作完成后关闭的能力。 -
PrintWriter:
PrintWriter是字符打印流,它继承自Writer类,也提供了一系列打印方法。PrintWriter可以接收字符数据,并将其直接输出到目标,它也具备自动刷新和在操作完成后关闭的能力。
打印流的主要优点在于它们的简化和便利性,使用打印流可以更方便地进行输出操作,而不需要手动进行转换和拼接字符串。打印流的常见用法包括以下几点:
- 创建打印流实例:
- PrintStream可以通过System.out获取标准输出流,也可以通过构造函数创建包装其他输出流的实例。
- PrintWriter可以通过System.out获取标准输出流,也可以通过构造函数创建包装其他Writer的实例。
PrintStream ps = System.out;
PrintWriter pw = new PrintWriter(System.out);
- 打印数据:
- 使用PrintStream的print和println方法可以打印各种数据类型的值,并通过toString方法将其转换为字符串。
- 使用PrintWriter的print和println方法同样可以打印各种数据类型的值,它们会自动调用值的toString方法。
ps.print("Hello");
pw.println(12345);
ps.println(3.14);
pw.print(true);
- 自动刷新:
- 打印流可以设置自动刷新功能,即每次写入后都会自动刷新缓冲区,将内容立即输出。
- 可以通过setAutoFlush方法设置自动刷新的条件,当写入的数据超过一定大小或使用println方法时,缓冲区会被自动刷新。
pw = new PrintWriter(System.out, true); // 设置自动刷新
pw.println("Auto flush");
自动刷新这个函数虽然PrintStream也有,但是我们不会使用,因为字节流底层就没有缓冲区,开不开自动刷新都一样。
- 关闭打印流:
- 使用打印流进行输出后,应该及时关闭它们。关闭打印流会自动关闭底层的输出流。
- 可以通过调用close方法来关闭打印流。
ps.close();
pw.close();
总结来说,打印流是Java IO库中方便的输出流,它提供了打印各种数据类型的方法,并具备自动刷新和关闭的功能。使用打印流可以简化输出操作,减少手动转换和拼接字符串的工作量。
5.压缩流:
压缩流和解压缩流是Java IO库中用于对数据进行压缩和解压缩的特殊流,它们可以用于减小文件大小、提高网络传输效率以及节省存储空间。压缩流用于将数据压缩成较小的字节序列,而解压缩流则用于将压缩后的字节序列还原成原始的数据。
在Java中,压缩流和解压缩流是通过GZIP压缩算法实现的,主要包括以下两个类:
- GZIPOutputStream(压缩流):
GZIPOutputStream是OutputStream的子类,它将数据压缩成GZIP格式的字节序列。可以将GZIPOutputStream连接到其他输出流(如FileOutputStream或Socket.getOutputStream()),将数据写入GZIPOutputStream,它会自动进行压缩并将结果写入连接的输出流。
压缩的代码示例:
try {
FileOutputStream fileOut = new FileOutputStream("compressed.gz");
GZIPOutputStream gzipOut = new GZIPOutputStream(fileOut);
gzipOut.write(data);
gzipOut.close();
fileOut.close();
} catch (IOException e) {
e.printStackTrace();
}
- GZIPInputStream(解压缩流):
GZIPInputStream是InputStream的子类,它从GZIP格式的字节序列中读取数据并解压缩成原始数据。可以将GZIPInputStream连接到其他输入流(如FileInputStream或Socket.getInputStream()),通过读取GZIPInputStream获取解压缩后的数据。
解压缩的代码示例:
try {
FileInputStream fileIn = new FileInputStream("compressed.gz");
GZIPInputStream gzipIn = new GZIPInputStream(fileIn);
byte[] buffer = new byte[1024];
int length;
while ((length = gzipIn.read(buffer)) != -1) {
// 处理解压缩后的数据
}
gzipIn.close();
fileIn.close();
} catch (IOException e) {
e.printStackTrace();
}
压缩流和解压缩流的使用需要注意以下几点:
- 压缩流和解压缩流只能处理单个文件或数据流,无法直接压缩多个文件或整个文件夹。如果需要压缩多个文件,可以将文件逐个写入压缩流,并标记文件名和内容长度,以便解压缩时进行还原。
- 在使用压缩流和解压缩流时,应注意关闭流以释放资源,可以使用try-with-resources语句来自动关闭这些流。
总结来说,压缩流和解压缩流是Java IO库中用于对数据进行压缩和解压缩的特殊流。通过GZIPOutputStream可以将数据压缩成GZIP格式的字节序列,而通过GZIPInputStream可以将压缩后的字节序列解压缩成原始数据。在使用压缩流和解压缩流时,需要将其连接到其他流,并注意关闭流以释放资源。
总结:
本文我们为大家介绍了这些IO流中的高级类,他们各自都有各自的最佳使用范围,我们可以根据自己的需求来选择到底使用哪一个高级类完成需求,而这些其实在日常中不是很普遍的使用,因此我们只需要知道这些东西,需要用的时候即用即查就好了。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!