这个地方我是先了解了Rete算法,才来看得这一部分,结果发现好像没有什么用......完全不知道讲的什么,估计之后在用的时候慢慢会明白。
RETE算法笔记:http://t.csdn.cn/iNZ8V
甩锅声明:本人英语一般,翻译只是为了做个笔记,所以有翻译错误的地方,错就错了,如果你想给我纠正,就给我留言,我会改过来,如果懒得理我,就直接划过即可。

目录
Drools的Phreak规则算法
Phreak的规则评估
使用前项链和后项链的规则评估
规则库配置
drools.consequenceExceptionHandler
drools.multithreadEvaluation
drools.sequential
Phreak中的顺序模式
Drools的Phreak规则算法
Drools使用Phreak算法去评估规则。Phreak是Rete算法的进阶,包括加强的Rete算法ReteOO,ReteOO算法是Drools之前版本的引入的算法。Phreak比Rete和ReteOO算法更加可扩展,并且在大型系统中速度更快。
Rete算法是实时的,面向数据的,而Phreak是懒加载的,面向目标的。Rete算法在插入,更新和删除操作时执行很多操作,为了让所有规则都能找到匹配的部分。在规则匹配期间,Rete算法在执行规则之前需要大量时间,尤其在大型系统中。使用Phreak,规则的匹配部分被故意延迟,以便可以更高效的处理大量数据。
Phreak算法相对于Rete算法添加了下面的增强:
-
上下文存储分为三层:节点,片段和规则存储类型
-
基于规则,基于片段,基于节点的连接
-
延迟规则评估
-
基于堆栈的暂停和恢复的评估
-
单独规则评估
-
面向集合传播
Phreak的规则评估
当drools启动时,所有的规则都被认为是与可以触发规则的模式匹配数据不关联的。在这个阶段,Phreak算法不会评估规则。插入,更新和删除操作是排队的,并且Phreak使用启发式的(基于最有可能导致执行的规则)方法计算和选择下一个规则去评估。当规则填充了所有必要的值时,这个规则被认为和相关模式匹配的数据是关联的。然后Phreak创建了一个目标,这个目标代表这条规则,同时Phreak将这个目标放入优先队列中,这个队列会根据规则的优先级排列规则的顺序。仅评估创建目标的规则,其他规则会延迟评估。在评估单个规则的同时,节点共享仍然是通过分割过程实现的。
和面向元组的Rete算法不同,Phreak的传播是面向集合的。对于被评估的规则,drools会访问第一个节点,并处理队列里所有的插入,更新和删除操作。操作的结果加入到一个集合中,将这个集合传播给子节点。在子节点里,所有的插入,更新和删除操作执行结束,依旧将结果添加到这个集合里面。然后再将这个集合传播给下一个子节点,一直重复这个操作,直到到达终止节点。这个循环创建了一个批处理的效果,可以为某些规则结构提供性能优势。
规则的连接和取消连接的发生是通过基于网络片段的位掩码系统。构建规则网络时,会为同一组规则共享的规则网络节点创建分段。规则由片段的路径组成,如果规则不与其他任何规则分享节点,这个规则会成为单个片段。
位掩码偏移量赋值给片段中的每个节点。另外的位掩码根据下面这些要求,赋值给规则路径上的每个片段:
-
如果对于节点至少存在一个输入,节点位设置为on状态
-
如果片段中的每个节点都是on状态,则该片段也设置为on状态
-
如果任意节点位被设置成off状态,则该片段也设置为off状态
-
如果规则路径的每个片段都被设置成了on状态,则规则被认为是连接的,并且创建一个目标去安排规则的评估。
相同位掩码技术被用于记录修改的节点,片段和规则。如果在创建了评估目标后对规则进行了修改,则这个记录能力能够将已经连接的规则从评估中取消。因此,没有规则能够评估部分匹配。
上面讲的这种评估规则的过程在Phreak算法中是可能的,但是在Rete算法中是不行的,因为Rete算法中的内存单元是单独的,而Phreak算法有三层的上下文内存,包括节点,片段和规则内存。这种分层能够在评估规则的过程中更多的上下文理解。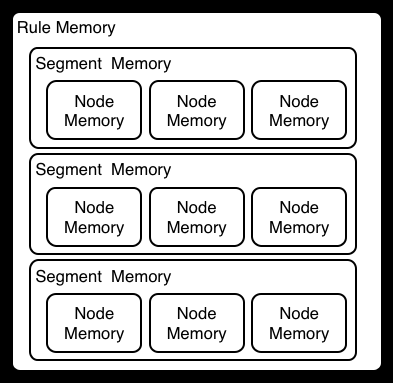
图示6. Phreak的三层内存系统
下面的例子展示了在Phreak算法中,规则是如何在三层内存系统中组织并评估。
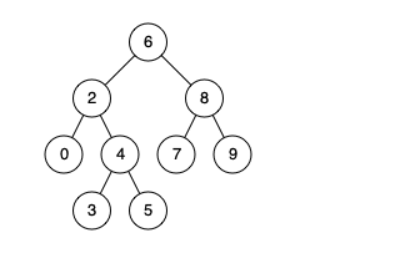
例子1:一条有三个模式单独的规则R1:A,B和C三种模式。这个规则形成一个单独的片段,其中1,2和4位是节点。这个单独片段的偏移量是1.
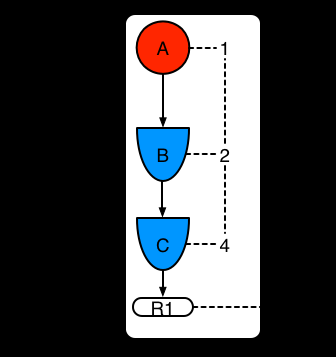
图示7. 例子1:单独规则
例子2: 规则2添加并分享模式A
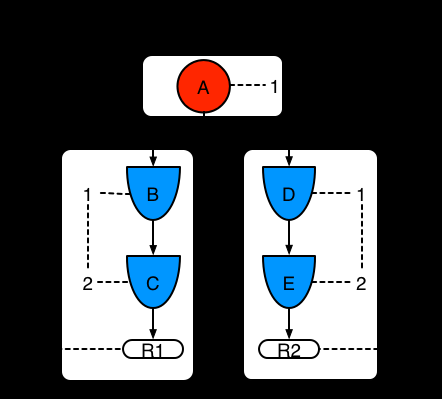
图示8. 例子2:模式共享的两条规则
模式A被放入了他自己的片段,导致每条规则又两个片段。那两个片段形成了各自规则的路径。第一个片段被两个路径共享。当模式A是关联的,片段就是关联的。如果模式B和C再之后被开启,路径R1的第二个片段被关联,并且这会导致用于R1的位2被开启。为R1打开位1和位2,这条规则就被关联,并且会创建一个目标来安排之后规则的评估和执行。
当规则被评估之后,片段能够使匹配的结果被分享。每个片段都有一个缓存去排列所有的插入,更新和删除操作。当R1被评估之后,规则处理模式A,会产生一组元组。算法检测片段分割,为该组中的每一个插入,更新个删除操作创建对等元组,并添加这些原组到R2的缓存中。这些原组之后会和存在于缓存的原组合并,并且当R2被评估之后执行这些原组。
示例3:规则R3和规则R4被添加,并在模式A和模式B中被分享。
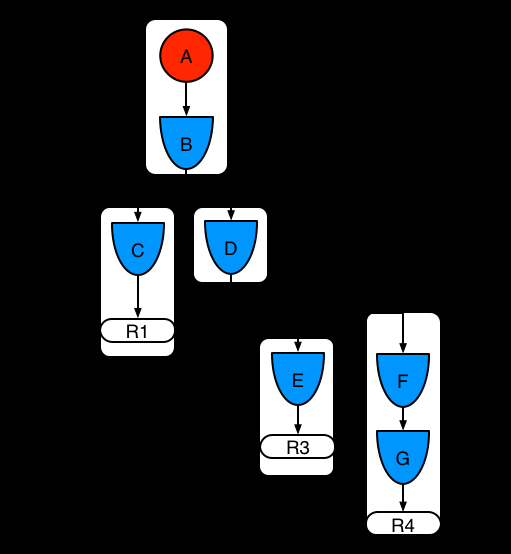
图示9.示例3:三条规则使用模式分享
规则R3和R4有三个片段,R1有两个片段,模式A和模式B被R1,R3和R4分享,而模式D被规则3和规则4分享。
示例4:一个使用子网的单独规则R1,没有模式分享
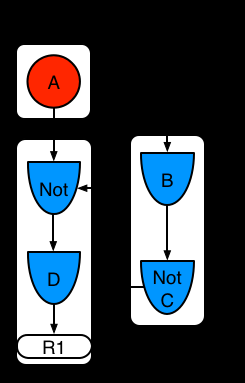
图示10.示例4:使用子网络和没有模式分享的单独规则
当Not,Exists或者Accumulate节点包含超过一个元素的时候,就形成了子网络。在这个例子里面,元素 B not(C)形成了子网络。元素Not(c)是一个单独的元素,不需要子网络,一次Not和里面的元素合并形成了节点。子网络使用专门的片段。规则R1仍然有两个片段的路径,并且子网络形成了两一个内部路径。当子网络是关联的,该子网络在外部的片段也是关联的。
示例5:规则R1使用被规则R2分享的子网络。
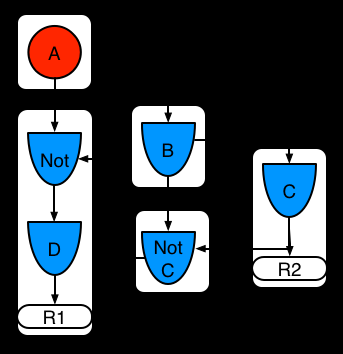
图示11.示例5:两个规则,一个用了子网络和模式分享
规则中的子网络可以被分享。这个分享会导致子网络片段被分割成两个片段。
Not节点和Accumulate节点从不取消关联片段,并且总是被认为打开他们的位。
Phreak评估算法是基于堆栈的,而不是基于算法递归的。当StackEntry被用于当前正在被评估的节点时,规则评估可以随时被暂停和开始。
当规则评估到达子网络时,为外路径片段和子网络片段创建StackEntry对象。子网络片段会被先评估,当集合到达子网络路径的末尾时,片段会被放入一个暂存列表里,这个列表是为了存哪些片段流入的外部节点。之前的StackEntry对象会被启动,并且处理子网络的结果。这个过程会有额外的好处,尤其对Accumulate节点,好处就是在传入到子节点之前,所有工作都是集群完成。
相同的堆栈系统被用于高效的后项链推理。当一条规则的评估到达一个查询节点时,评估被暂停,并且该查询被加入到堆栈中。然后评估查询生成一个结果集合,这个集合会被保存到本地内存中,并被用于恢复StackEntry对象去增强并传播到子节点。如果查询自己调用其他的查询,这个过程会重复,同时暂停当前查询并为当前查询设置一个新的评估。
使用前项链和后项链的规则评估
Drools是一个混合推理系统,既使用前项链推理,也使用后项链推理去评估规则。前项链规则系统是数据驱动系统,从一个事实开始,对该事实的更改做出反应。当对象被插入工作内存时,任何由于更改成立的规则条件会安排被议程执行。
相反的,后项链规则系统是目标驱动系统,从一个结论开始,系统会使用递归去尝试满足该结论。如果系统不能到达结论或者目标,系统会搜索子目标,这些子目标是当前目标完成的一部分。系统会继续这个过程,直到初始结论被满足或者所有的子目标都被满足。
下面的图标展示了Drools如何使用前项链和后项链来评估规则:
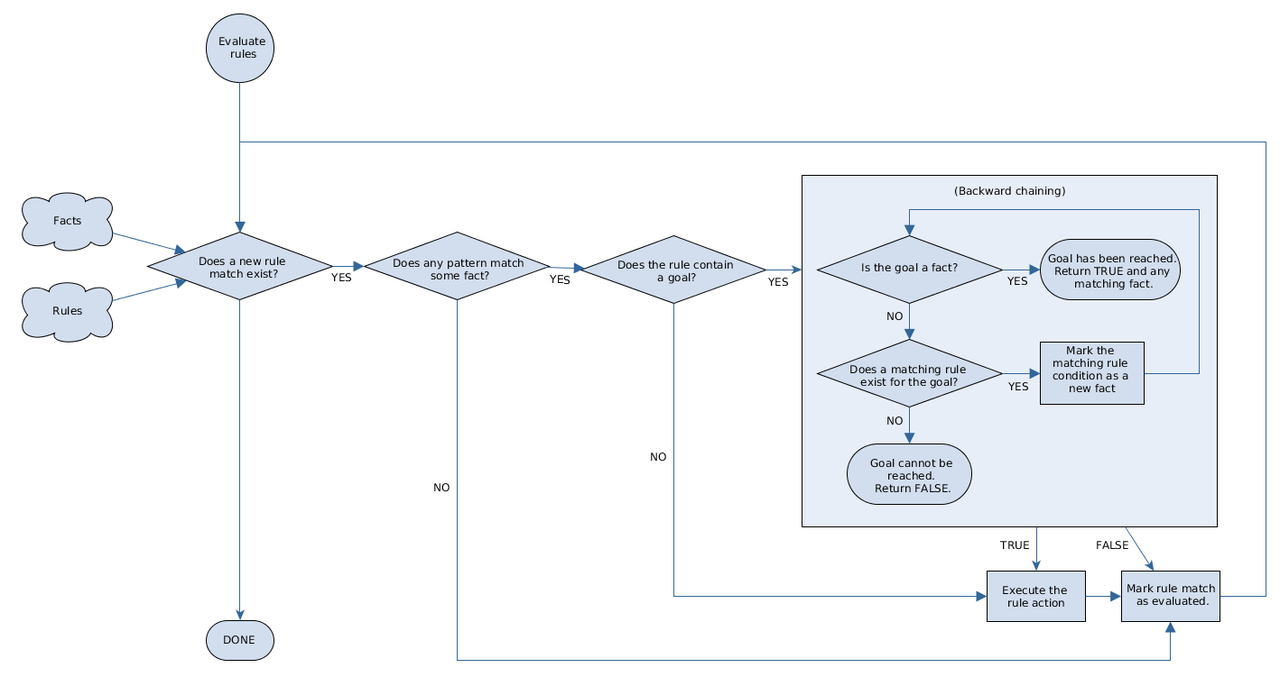
图示12.使用前项链和后项链规则评估逻辑
规则库配置
Drools包含一个RuleBaseConfiguration对象,这个对象可以用于配置异常处理的设置,多线程执行,
和连续模式。
对于规则库配置的选项,参见GitHub上的:https://github.com/kiegroup/drools/blob/7.59.x/drools-core/src/main/java/org/drools/core/RuleBaseConfiguration.java。
Drools提供下面的规则库配置选项:
drools.consequenceExceptionHandler
当配置这个选项时,系统属性定义管理哪些被规则抛出异常的类。可以使用属性指定自定义异常处理。
默认处理异常的类:org.drools.core.runtime.rule.impl.DefaultConsequenceExceptionHandler
- 在系统属性中指定异常处理:
drools.consequenceExceptionHandler=org.drools.core.runtime.rule.impl.MyCustomConsequenceExceptionHandler - 使用编程的方式创建Kie库时指定异常处理:
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(ConsequenceExceptionHandlerOption.get(MyCustomConsequenceExceptionHandler.class)); KieBase kieBase = kieContainer.newKieBase(kieBaseConf);
drools.multithreadEvaluation
当配置,系统属性能够让Drools将Phreak规则网络变为单独的部分并行评估规则。可以使用这个属性增加规则评估的速度。
默认:不开启
可以通过下面方式中的一种开启多线程评估:
- 能够启用多线程的系统配置:
drools.multithreadEvaluation=true - 通过编程方式在KIE库中启动多线程模式:
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(MultithreadEvaluationOption.YES); KieBase kieBase = kieContainer.newKieBase(kieBaseConf);
使用了查询,优先级,或者议程组的规则现在不支持并行。如果这些规则元素出现在了KIE库中,编译器会弹出警告并自动选择单线程模式评估。但是,在一些情况下,Drools可能检测不出不支持的规则原色,规则可能会被错误的评估。比如,当规则依赖隐式优先级(DRL文件中规则的顺序),Drools可能没有检测,导致错误评估由于对优先级属性的不支持。
drools.sequential
启用后,此系统属性会在Drools规则引擎中启用顺序模式。顺序模式,Drools按照顺序评估规则一次,不会因为工作内存中的改变而再次评估。这就意味着Drools忽略了规则中的insert,modify和update语句,以单个序列执行规则。这个模式适合在无状态会话中使用。会让规则执行的更快。
默认值:false
可以使用下面的方式之一开始这个配置:
- 使用下面系统属性配置
drools.sequential=true - 写代码的方式配置
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(SequentialOption.YES); KieBase kieBase = kieContainer.newKieBase(kieBaseConf); - 在kmodule文件中配置
<kmodule> ... <kbase name="KBase2" default="false" sequential="true" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1"> ... </kbase> ... </kmodule>
Phreak中的顺序模式
顺序模式是Drools的高级规则库配置,Phreak算法支持该模式,这个模式的启用让Drools按顺序一次性的评估工作内存中的规则,在评估的过程中忽略规则的更改。在顺序模式中,Drools会忽略规则中的insert,modify和update语句, 以单个序列执行规则。因此,在顺序模式中规则执行会更快一些,但是重要的更新不会被用于规则中去。
顺序模式只能在无状态会话中使用,因为有状态会话会使用之前会话调用产生的数据。如果使用无状态会话,并且想让规则的执行影响议程后续的规则,就不要开启顺序模式。顺序模式默认是不开启的。
可以使用下列方式之一开启顺序模式:
-
设置系统属性drools.sequentail为true。
-
以编码的方式当创建会话时启用:
KieServices ks = KieServices.Factory.get();
KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration();
kieBaseConf.setOption(SequentialOption.YES);
KieBase kieBase = kieContainer.newKieBase(kieBaseConf);-
在kmodule.xml中启用顺序模式:
<kmodule>
...
<kbase name="KBase2" default="false" sequential="true" packages="org.domain.pkg2, org.domain.pkg3" includes="KBase1">
...
</kbase>
...
</kmodule>使用动态议程配置顺序模式,使用下面选项之一:
- 设置系统属性drools.sequential.agenda为dynamic
- 以编码的方式,当创建会话的时候设置顺序议程:
KieServices ks = KieServices.Factory.get(); KieBaseConfiguration kieBaseConf = ks.newKieBaseConfiguration(); kieBaseConf.setOption(SequentialAgendaOption.DYNAMIC); KieBase kieBase = kieContainer.newKieBase(kieBaseConf);
当启动顺序模式时,drools会按下面的方式评估规则:
-
规则按照优先级顺序排列并放入规则集合中。
-
为每一个可能被匹配的规则创建一个元素。这个元素的位置下标就是执行顺序。
-
除了右手边输入内存外,节点内存被禁用。
-
左手边输入节点的传播被断开,带有节点的对象在Command对象中被引用。Command对象会被添加到工作内存的列表中,用以后续的执行。
-
所有的对象都被断言,然后检查并执行Command对象列表。
-
根据规则的序列号,将所有执行结果添加到元素中。
-
包含匹配项的元素按顺序执行。如果你设置了规则执行的最大数量,Drools激活的议程中的规则数量,不会超过该数量。
在顺序模式中,LeftInputAdapterNode节点创建Command对象,并且添加Command对象到工作内存列表中。这个Command对象包含LeftInputAdapterNode节点和Propahated对象的引用。这些引用在插入时会停止任何左输入的传播,所以导致右输入传播从不需要尝试连接左输入。引用还避免了对左输入内存的需求。
所有拥有内存的节点关闭,包括左输入元组内存,但是不包括右输入对象内存。完成所有断言并填充所有对象右输入内存后,Drools会迭代LeftInputAdaptNode Command对象列表。对象在网络中传播,尝试连接右输入对象,但是这些对象不会保留在左输入中。
具有调度元组的优先队列的议程被每个规则的元素替换。RuleTerminalNode节点的序列号代表放置匹配的元素。在所有Command对象结束之后,检查元素,并执行存在的匹配。
构建网络时,每个RuleTerminalNode节点都会根据其显着性编号和添加到网络的顺序接收一个序列号。
右输入内存通常是哈希映射表,为了可以快速的删除对象。因为对象的删除不被支持,Phreak算法使用了一个对象列表,当对象的值没有被索引时。对于大规模对象,索引哈希映射提供了性能上的提升。如果对象只有很少的实例,Phreak使用对象列表而不是索引。