互联网上充斥着有趣的假照片——从汽车上飞驰的鲨鱼和奶牛到令人眼花缭乱的名人混搭。然而,卷积神经网络(CNNs)生成的超现实图像和视频赝品绝非笑料——事实上,它们可能非常危险。Deepfake色情在2018年抬头,世界领导人的虚假政治演讲让人们对新闻来源产生了怀疑,在最近的澳大利亚丛林大火中,被操纵的图像在火灾的位置和规模上误导了人们。虚假的图像和视频给人工智能带来了黑眼圈——但机器学习社区如何反击?

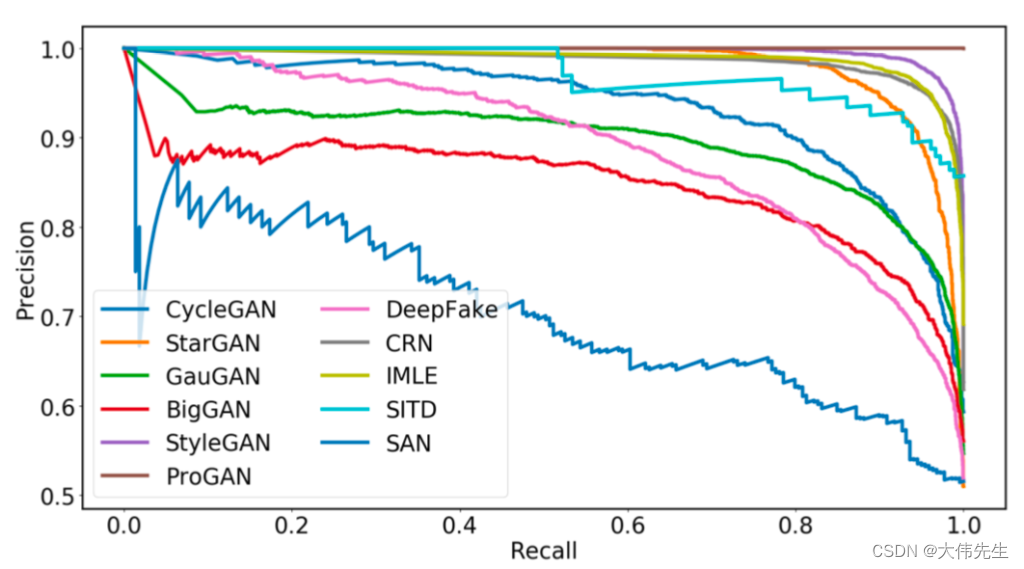
加州大学伯克利分校和Adobe研究人员的一篇新论文向假图像宣战。利用自定义数据集和新的评估指标,研究团队引入了一种通用的图像取证方法,该方法在检测CNN生成的图像时实现了高平均精度 发现此类生成的图像
似乎是一项相对简单的任务 - 只需使用假图像与真实图像训练分类器。事实上,由于多种原因,挑战要复杂得多。假图像可能会从不同的数据集生成,这将包含不同的数据集偏差。当模型的训练数据集与用于生成假图像的数据集不同时,假特征更难检测。此外,网络架构和损失函数可以迅速发展,超越假图像检测模型的能力。最后,图像可能被预处理或后处理,这增加了识别一组假图像的共同特征的难度。
为了解决这些问题和其他问题,研究人员建立了一个基于CNN的生成模型数据集,该数据集跨越了各种架构,数据集和损失函数。然后对真实图像进行预处理,并从每个模型生成相同数量的假图像 - 从GAN到deepfakes。由于其高度多样性,生成的数据集最大限度地减少了来自训练数据集或模型架构的偏差。

假图像检测模型建立在ProGAN上,ProGAN是一个无条件的GAN模型,用于随机图像生成,具有简单的基于CNN的结构,并在新的数据集上进行训练。在各种CNN图像生成方法上进行评估,该模型的平均精度明显高于对照组。
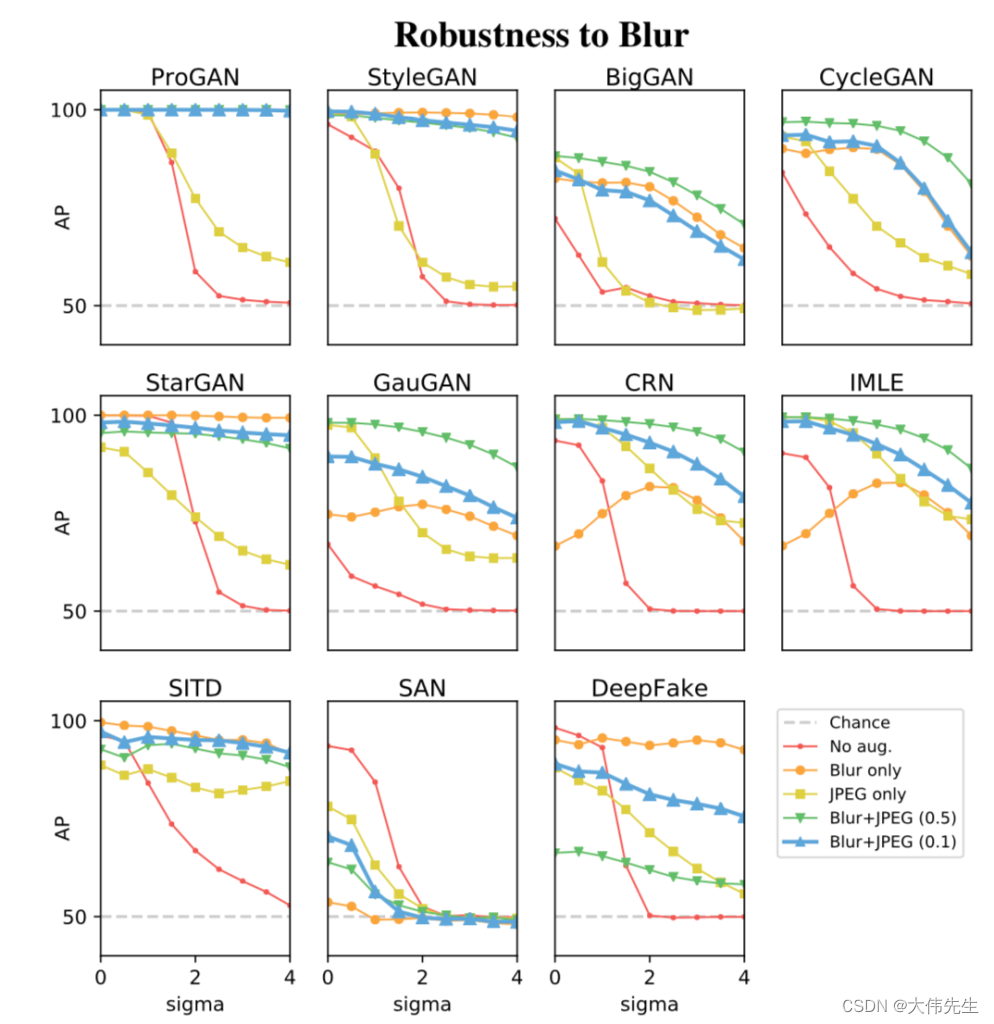
数据增强是研究人员用来改进对生成后经过后处理的假图像的检测的另一种方法。训练图像(假/真)经历了几个额外的增强变体,从高斯模糊到JPEG压缩。研究人员发现,在训练集中包括数据增强显着提高了模型的鲁棒性,尤其是在处理后处理图像时。
然而,研究人员指出,即使是最好的检测器,仍然需要在真实检测和假阳性率之间进行权衡,并且恶意用户很可能只是简单地挑选了通过检测阈值的简单假图像。另一个问题是,添加到假图像的后处理效果可能会增加检测难度,因为假图像指纹在后处理过程中可能会失真。还有许多假图像不是生成的,而是经过Photoshop处理的,探测器无法处理通过这种浅层方法生成的图像。
这项新研究在识别使用各种基于CNN的图像合成方法篡改的图像指纹方面做得很好。然而,研究人员警告说,这是一场战斗 - 对假图像的战争才刚刚开始。
CNN生成的论文图像出奇地容易被发现…现在在arXiv上。