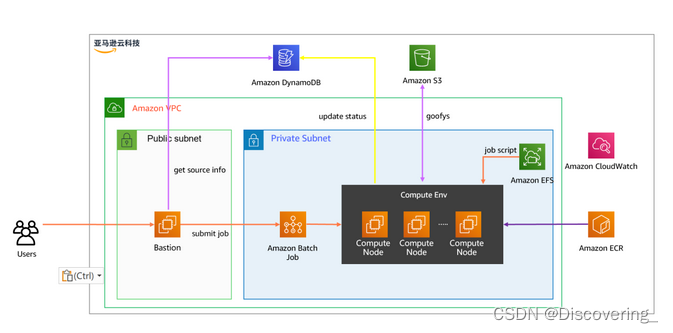
Flink非对齐checkpoint原理(Flink Unaligned Checkpoint)
为什么提出Unaligned Checkpoint(UC)?
因为反压严重时会导致Checkpoint失败,可能导致如下问题
- 恢复时间长-服务效率低
- 非幂等和非事务会导致数据重复
- 持续反压导致任务加入死循环(可能导致数据丢失,例如超过kafka的过期时间无法重置offset)
UC的原理
UC有两个阶段(UC主要是快速超越buffer data)
-
第一阶段:UC同步阶段(任意一个barrier加入缓冲区即开始UC,barrier 直接超越所有input和outputBuffer(算子暂停处理数据))
- barrier超越
- 对buffer进行引用
- 调用算子snapshot state
- 引用state
-
第二阶段:异步阶段(等待所有input channel的barrier都到达)
- 写算子的state(同步阶段引用的state)
- 同步阶段引用的input&output buffer
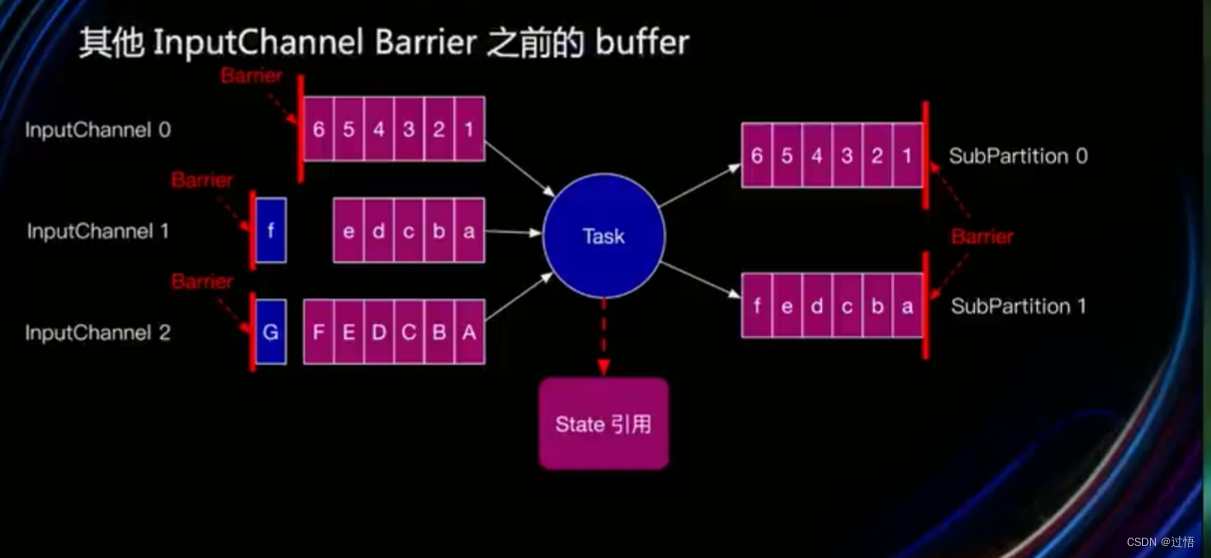
- 写其它inputChannel Barrier之前的buffer(如下图中蓝色f和G)
- 汇报给jobmanager
UC已进行的优化
Task原理
Task处理逻辑如下,线程可能卡在结果输出影响UC
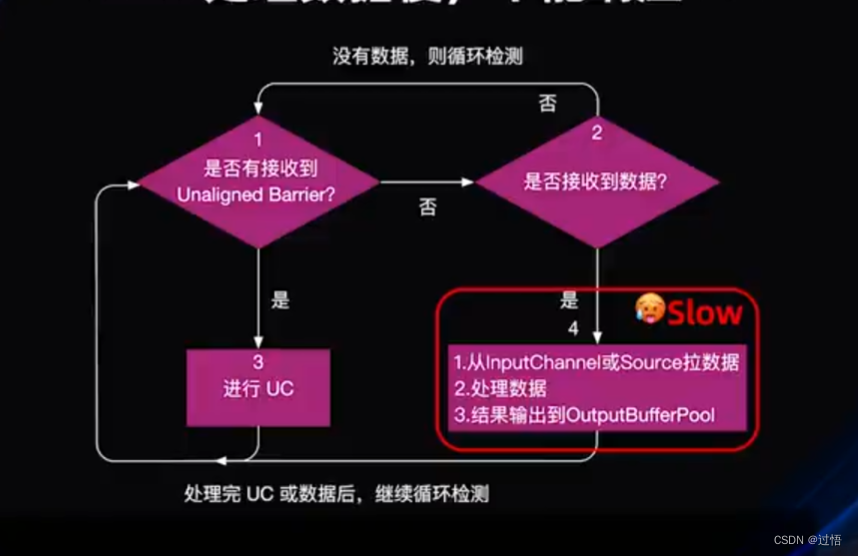
优化一
优化:判断有空闲output buffer再处理数据

需要多个buffer时还是会卡住,比如flatmap操作
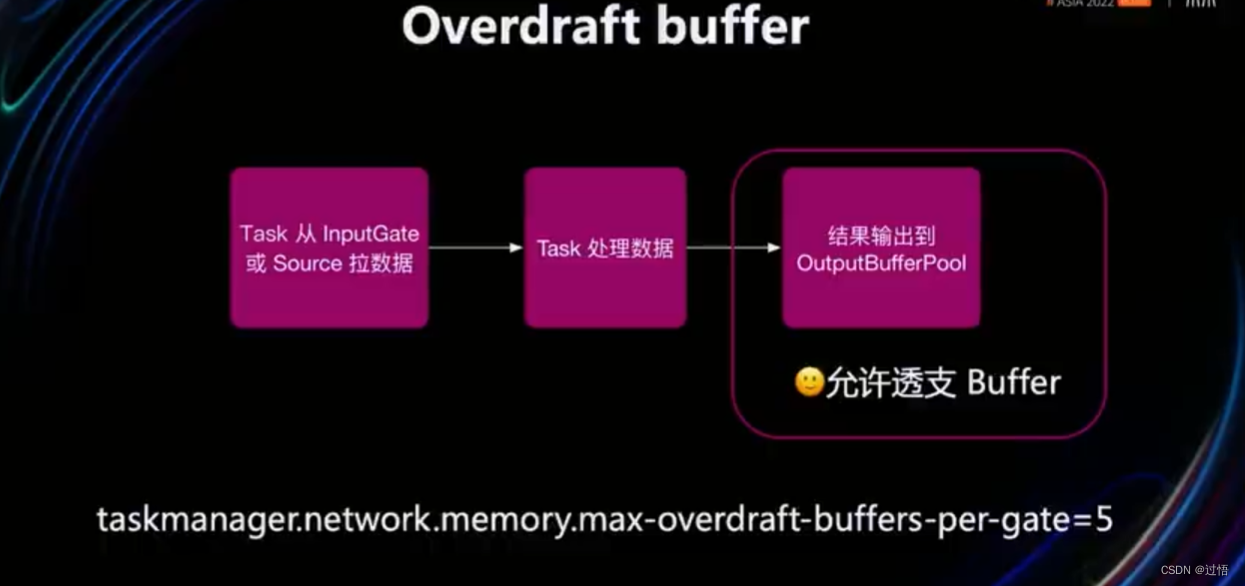
优化二
优化:使用OverDraft Buffer透支Buffer,一旦透支buffer则不能处理数据(1.16已有透支Buffer功能)
其它优化
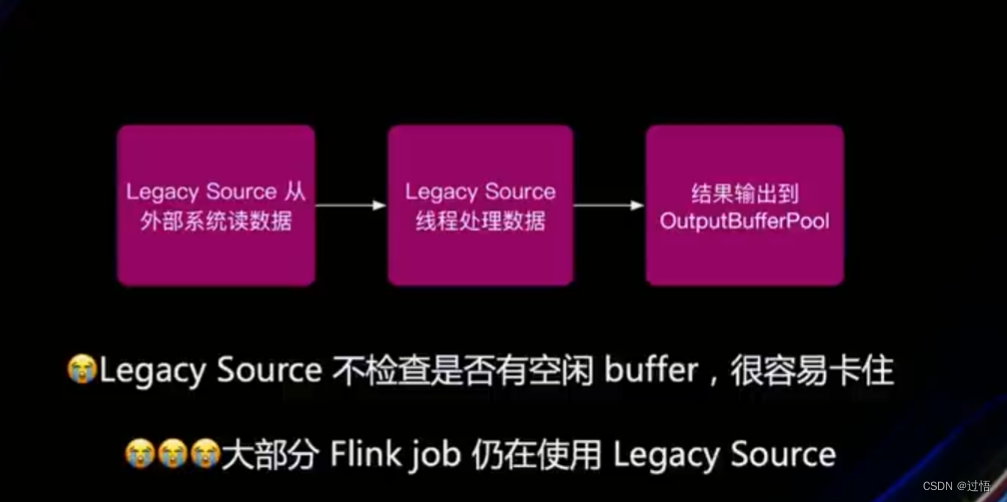
优化:Legacy Source(Legacy Source 是 Flink 中的一种数据源,它是在 Flink 1.0 版本中引入的,并在后续版本中被视为过时的来源)兼容UC
小结
- 等待空闲Buffer+引入透支overdraft Buffer解决卡顿问题
- Legacy source兼容等待空闲Buffer逻辑
UC风险
- 序列化不兼容,无法重启
- 算子连接变化UC无法恢复
- Data Buffer会写大量小文件,导致DataNode压力过大
- 使用Task共享文件(execution.checkpointing.channel-state.number-of-tasks-share-file)
- 会出现死锁或内存泄漏
UC&AC对比
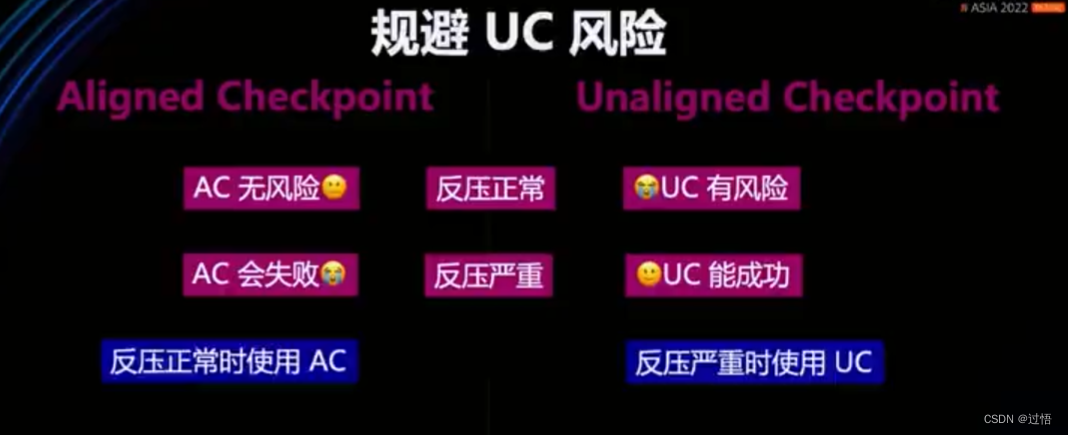
优化:在AC超时自动切换到UC(1.11版本开始)
配置方法(1.11以后版本)
execution.checkpointing.aligned-checkpoint.timeout: 10m
execution.checkpointing.unaligned-checkpoint.enabled: true
参考文档
https://www.bilibili.com/video/BV1tR4y1y7gQ/?spm_id_from=…search-card.all.click&vd_source=a52a4a5afaf8d47cb48d828c7e22e5f1