随着使用需求的增长,用户群的扩大以及新功能的引入,让工程师按照业务的主要领域进行组织变得不可避免。当这些领域在单个实体(如类、服务、应用程序或代码库)的层面变得过于庞大难以管理时,引入联合GraphQL成为优化系统架构的有效手段。
如果GraphQL还不是您在解决开发周期延迟、团队沟通不畅和错过截止日期方面的利器,请考虑采用它作为引入API的正式约定的简便方式,从而使系统架构和依赖该架构的客户端都受益。
我们已经看到一些公司如IMDb和Netflix开始利用GraphQL联合来实现团队自治,并同时保持大规模流量的处理能力,因此让我们更详细地了解如何实现这一点。
一个示例问题空间
让我们设想一个……比如说,博客平台,并考虑在提供该体验时涉及的主要实体。我们有注册的用户,他们可以创建和发布文章,其他用户会对这些文章进行评论和点赞。
一个简单的数据模型可能如下:
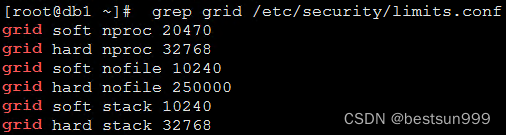
•user: id、name、email、createdAt、updatedAt•article: id、userId、title、body、publishedAt、createdAt、updatedAt•comment: id、userId、articleId、createdAt、updatedAt•favorite: id、userId、articleId、createdAt、updatedAt
请注意,我们可能将favorite作为实体的名称,而不是like,因为LIKE是SQL的关键字,可能会在未来引发问题。

四个表及其关系
单一应用程序方法
考虑如何在持久层处理 API 查询以获取由给定用户创建的所有文章(让我们使用SQL来说明):
SELECT a.id AS articleId, a.title, a.body, a.publishedAt, u.id AS userId, u.name
FROM article a, user u
WHERE a.userId = u.id AND u.id = <user_id>;然后,我们可以部署一个应用程序或无服务器函数,它以userId为输入,执行上述查询,将结果文章数组格式化为JSON响应,并返回给调用者。
在MVP阶段,这种耦合程度可能还可以接受,小的需求变更可能也会顺利处理:
我们可以添加user.imageUrl并在该查询中返回吗?
我们还可以添加article.seoKeywords吗?
这些变更可能会毫无问题地实现。
假设平台开始获得关注,用户从数百名增加到数十万名(做得很棒!),文章从数千篇增加到数百万篇,同时还有更多评论和点赞。我们可以想象这样的增长将导致我们组织内部的一些专业化,从而形成了处理用户(注册、账户管理、CRM)、内容(文章、审核、策划)和反馈(评论、点赞)的新领域和团队。
但是现在有个问题:用户和内容在最低层面上是相互关联的,更糟糕的是,它们部署在同一个应用程序中。如果用户和内容领域都有新功能要在本次迭代中发布,那么每个团队现在都依赖于彼此在规定的时间内完成开发,因为任何一端的错误都会阻塞另一端的部署。
引入GraphQL
好的,但是GraphQL有什么关系呢,更别说联合GraphQL了?

思考,思考,再思考……
最终,为了实现大规模数据服务,关键在于合同。在MVP中,用户和内容之间的合同嵌入在我们的SQL查询中的表JOIN中。这样的合同缺乏灵活性和可扩展性。
让我们试着在堆栈中向更高层次移动,寻找新的合同。也许我们可以有一个UserService类和一个ContentService类,分别查询它们自己的相关信息,并在上游控制器类中将这些查询的结果拼接成出站的文章数组和JSON响应。

在控制器层解决跨领域数据
这样做是更好的,但就开发速度而言,如果这些服务仍然属于同一个应用程序或部署,一个领域中的失败变更仍然会阻塞另一个领域中的成功变更。如果合同能够位于更高层次,那将会更好。
事实证明,GraphQL是声明合同的好方法,因为GraphQL模式本质上是客户端可以请求的内容和服务器将在响应中提供的内容之间的合同,类似于OpenAPI / Swagger文档可以告诉调用者关于REST API的信息
。
但是,GraphQL的妙处在于我们还可以在一个或多个GraphQL端点之前运行网关,并让它们协同工作,以实现统一的模式。这就是GraphQL联合,如果我们为每个领域分配自己的端点,那么每个团队可以有效地独立扩展、维护和部署合同的各个部分,而不会影响其他团队。
在实践中,我们可以利用Apollo的GraphQL功能来实现一个带有GraphQL联合的系统。具体细节可以留待另一篇文章,但是Apollo联合指南提供了您需要立即开始实施的所有内容。
联合GraphQL方法

通过GraphQL联合实现领域分离
首先,我们需要搭建一个网关服务器,该服务器配置有一个服务列表,即参与组合GraphQL模式的URL数组。在我们的情况下,这意味着为每个领域(用户、内容和反馈)都搭建一个单独的端点。
用户和内容的一些模式片段可能如下所示:
services/user/index.graphql
services/content/index.graphql
然后,每个个别的GraphQL模式,称为子图,都贡献到整体模式中,并可以在网关中访问。但是,真正的魔法发生在我们开始定义这些子图之间类似外键的依赖关系时。
例如,我们有一个Article模式,其中包含一个userId属性。如果我们可以根据来自用户服务的实际User类型定义一个User属性,那将会怎样?例如,用户服务端点定义的User类型,即在用户端点中定义的User类型。
要做到这一点,我们需要围绕Article类型中的外键userId形成一个合同,这样,每次请求Article中的User属性时,网关服务器将从用户服务端点获取User属性,并将其拼接到出站响应中。
extend语法和将相关属性装饰为@external允许我们在用户领域中定义与其他领域类型(如Article)相关的关系。这相当于我们在外键上进行SQL连接,但是在网关层面进行的连接,这已经是我们在后端响应中能够实现的最远的地方了。
services/user/index.graphql
现在,唯一剩下的就是在解析器中处理我们的User属性,我们在输入中给出userId并用它作为查找依据。
services/user/resolver.ts
这意味着在网关的最终合同中,联合GraphQL模式中User和Article的类型如下所示:
实现领域分离
因为用户和内容领域都拥有各自的端点和GraphQL模式,它们各自的团队现在可以独立于彼此进行部署,使得团队更加快速和高效。
现在,仅仅依赖于各自子图中的外键关系,这些关系在网关层面更容易维护。
实现跨领域的蓝图 🥂