概览
本篇主要介绍数据来源、数据加载进数据库过程
1 数据获取
使用Scrapy爬取豆瓣电影数据,然后利用movielens数据集来造一份rating数据。
1.1 数据集获取
- 数据集获取:选取movielens 数据集:movielens官网
- 数据集包括:movies,ratings,tags文件
1.2 数据爬取
- 使用scrapy+xpath爬取豆瓣电影数据,最后存入csv,命名为movie.csv
- 对于爬取的数据进行预处理:包括字段选取、相关字符处理
1.3 数据转换
- 由于缺少rating数据,因此我们使用movielens的rating文件来造一下评分数据。
- movielens数据集movie文件一共2791条电影数据,因此我们直接截取爬取的
movie.csv前2791条数据。 - 直接用movielens的电影ID替换爬取
movie.csv的电影ID,因此最后我们得到的电影数据也就有了对应的评分数据。 - 最后,我们需要的只是两个文件:movie.csv,rating.csv
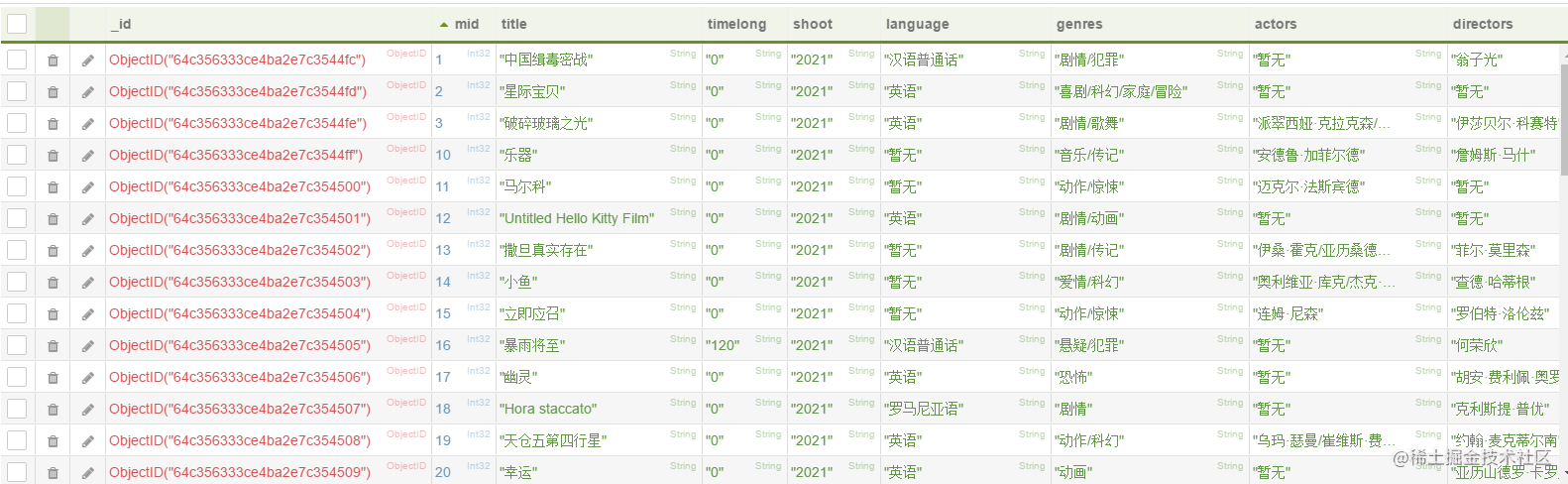
(1)Movie数据
数据表格式为:
mid,title,desc,minute,year,year,language,geners,actors,director
(2)Rating数据
userID,mid,score,timestamp
2 将数据加载进MongoDB数据库
我们选择MongoDB数据库的原因如下:
- 千万级别的文档对象,近10G的数据,对有索引的ID的查询不会比mysql慢,而对非索引字段的查询,则是全面胜出
- 可以进行深度查询
接下来,我们在云服务器部署MongoDB,主机远程连接数据库,将文件加载进数据库中。
2.1 MongoDB安装
- 安装教程:linux安装MongoDB
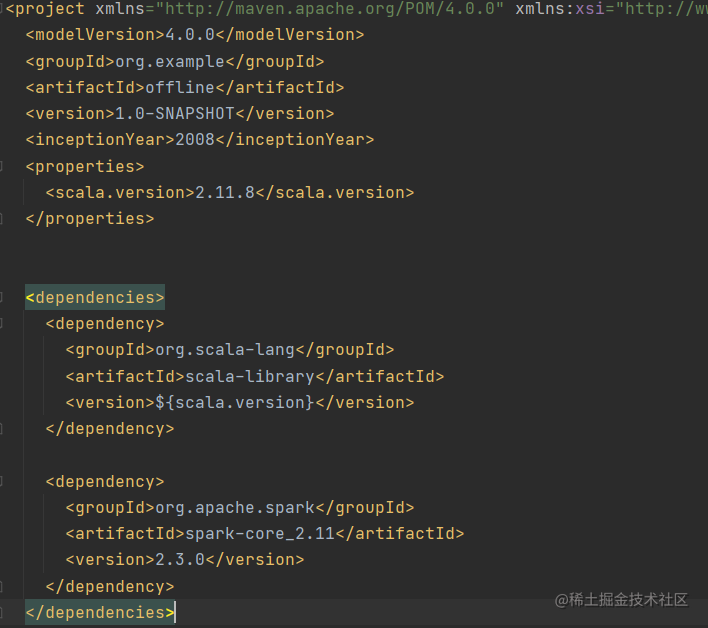
2.2 maven依赖
maven相关依赖版本如下
注意:Spark版本和Spark集群的版本需要一致
scala:2.11.8Spark:2.3.0
<properties>
<scala.version>2.11.8</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
2.3 数据加载的程序
// 加载数据主程序
object DataLoader {
val MONGODB_MOVIE_COLLECTION = "Movie"
val MONGODB_RATING_COLLECTION = "Rating"
val mgo_host = "root"
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://root:123456@服务器公网IP:27017/recommender",
"mongo.db" -> "recommender"
)
// 文件位置
val MOVIE_DATA_PATH = "F:\\1-project\\offline\\src\\main\\resources\\file\\movie.csv"
val RATING_DATA_PATH = "F:\\1-project\\offline\\src\\main\\resources\\file\\ratings.csv"
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("DataLoader")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val movieRDD = spark.sparkContext.textFile(MOVIE_DATA_PATH) // 加载数据
// 转为df
val movieDF = movieRDD.map(
item => {
val attr = item.split(",")
Movie(attr(0).toInt, attr(1).trim, attr(2).trim, attr(3).trim, attr(4).trim, attr(5).trim, attr(6).trim, attr(7).trim, attr(8).trim)
}
).toDF()
val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH)
val ratingDF = ratingRDD.map(item => {
val attr = item.split(",")
Rating(attr(0).toInt,attr(1).toInt,attr(2).toDouble,attr(3).toInt)
}).toDF()
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 将数据保存到MongoDB
storeDataInMongoDB(movieDF, ratingDF)
spark.stop()
}
}
def storeDataInMongoDB(movieDF: DataFrame, ratingDF: DataFrame)(implicit mongoConfig: MongoConfig): Unit ={
// 新建一个mongodb的连接
val mongoClient = MongoClient(MongoClientURI(mongoConfig.uri))
// 将DF数据写入对应的mongodb表中
movieDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
ratingDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//对数据表建索引
mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("uid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient.close()
}
2.4 查看数据
- 使用软件Mongo Management studio查看是否成功