一、总体架构设计原则
企业级大数据应用框架需要满足业务的需求,一是要求能够满足基于数据容量大,数据类型多,数据流通快的大数据基本处理需求,能够支持大数据的采集,存储,处理和分析,二是要能够满足企业级应用在可用性,可靠性,可扩展性,容错性,安全性和隐私性等方面的基本准则,三是要能够满足用原始技术和格式来实现数据分析的基本要求
满足大数据的V3要求
大数据容量的加载、处理和分析 - 要求大数据应用平台经过扩展可以支持 GB、TB、PB、EB甚至ZB规模的数据集
各种类型数据的加载、处理和分析 - 支持各种各样的数据类型,支持处理交易数据、各种非结构化数据、机器数据以及其他新数据结构
大数据的处理速度 - 在很高速度(GB/s)的加载过程中集成来自多个来源的数据
满足企业级应用的要求
高可扩展性 - 要求平台符合企业未来业务发展要求以及对新业务的响应,要求大数据架构具备支持调度和执行数百上千节点的负载工作流
高可用性 - 要求平台能够具备实时计算环境所具备的高可用性,在单点故障的情况下能够保证应用的可用性
安全性和保护隐私 - 系统在数据采集、存储、分析架构上保证数据、网络、存储和计算的安全性,具备保护个人和企业隐私的措施
开放性 - 要求平台能够支持计算和存储数以千计的、地理位置可能不同的、可能异构的计算 节点
易用性
二、总体架构参考模型
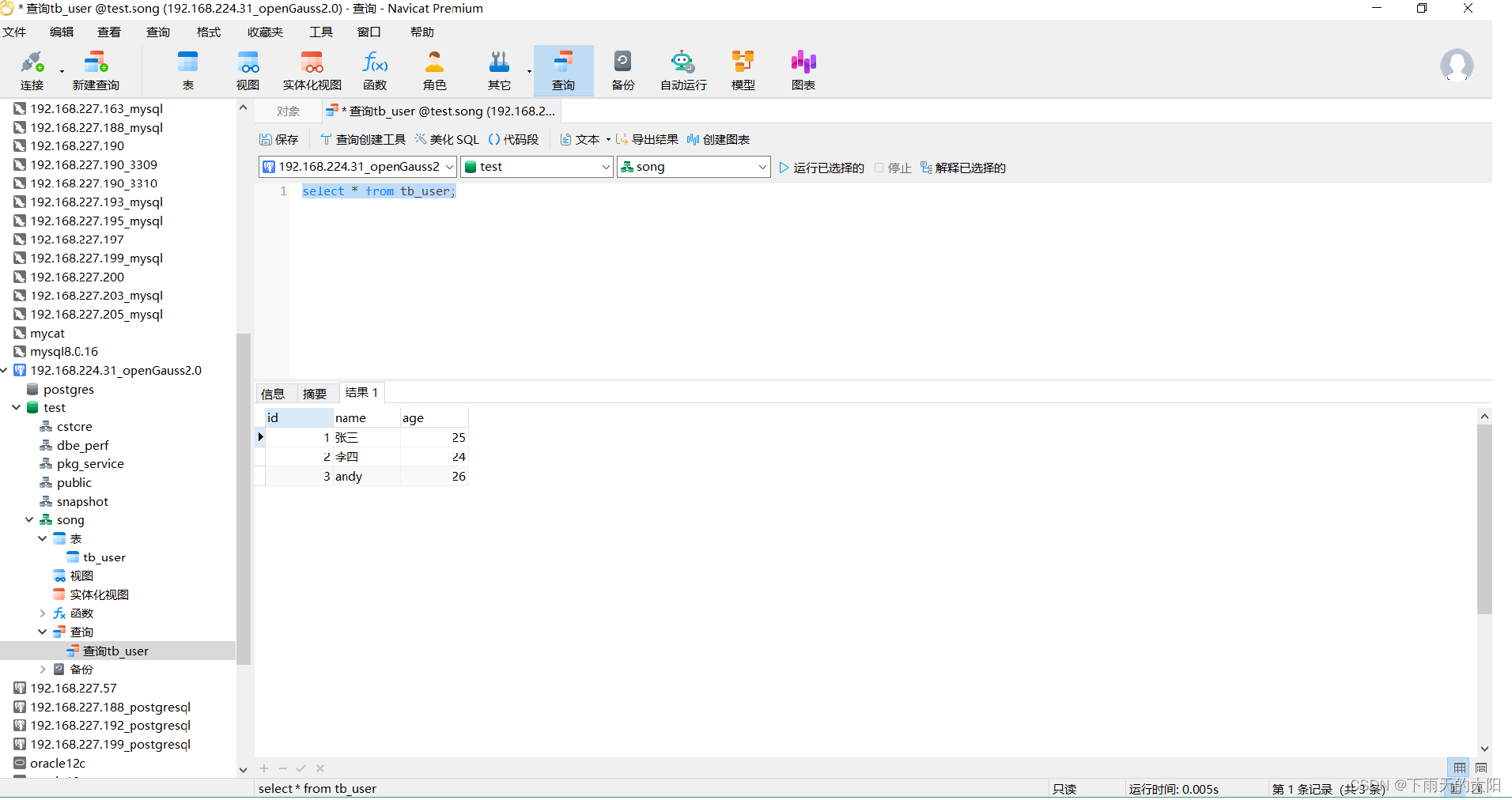
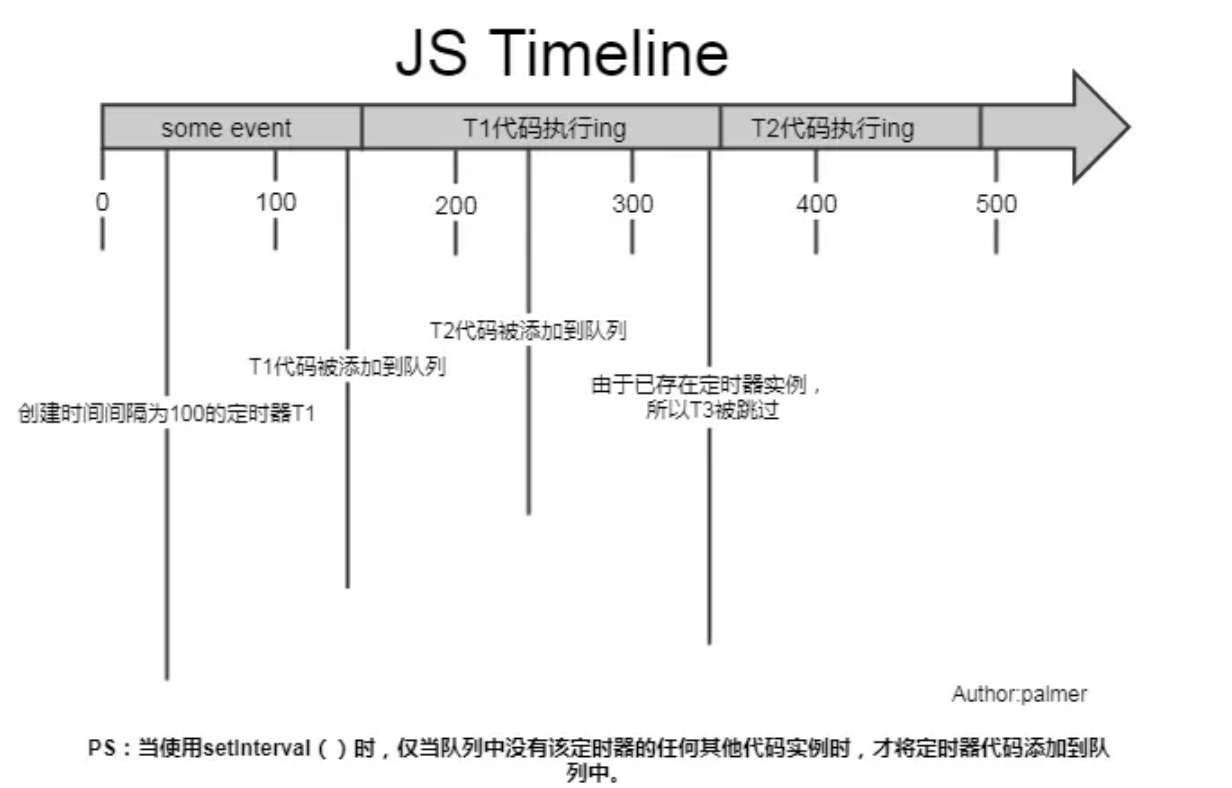
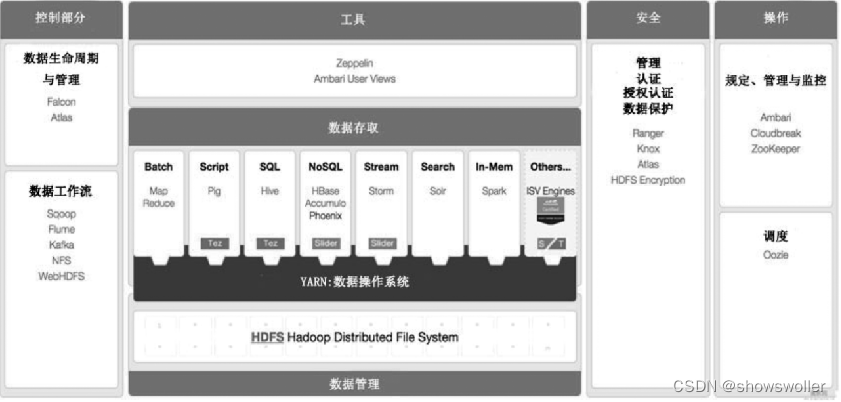
基于Apache开源技术的大数据平台总体架构参考模型如图所示,大数据的产生、组织和处理主要是通过分布式分拣处理系统来实现的,主流的技术是 Hadoop+ MapReduce
其中Hadoop的分布式文件处理系统(HDFS)作为大数据存储的框架,分布式计算框架MapReduce作为大数据处理的框架
大数据基础
这一部分提供了大数据框架的基础,包括序列化、分布式协同等基础服务, 构成了上层应用的基础
Avro - 新的数据序列化与传输工具,将逐步取代Hadoop原有的IPC机制
ZooKeeper - 分布式锁设施 ,它是一个分布式应用程序的集中配置管理器, 用户分布式应用的高性能协同服务,由 Facebook贡献,也可以独立于 Hadoop使用。
大数据存储
HDFS是Hadoop分布式文件系统, HDFS运行于大规模集群之上, 集群使用廉价的普通机器构建, 整个文件系统采用的是元数据集中管理与数据块分散存储相结合的模式, 并通过数据的冗余复制来实现高度容错
大数据处理
基于 MapReduce写出的应用程序能够运行在由上千个普通机器组成的大型集群上, 并以一种可靠容错的方式并行处理TB级别以上的数 据集
大数据访问和分析
在 Hadoop + MapReduce之上架构的是基础平台服务,在基础平台之上是大数据访问和分析的应用服务
Pig - Pig支持的常用数据分析主要有分组、过滤、合并等,Pig为创建 Apache MapReduce应用程序提供了一款相对简单的工具
Hive - Hive是由Facebook贡献的数据仓库工具, 是MapReduce实现的用来查询分析 结构化数据的中间件
Sqoop - Sqoop由Cloudera开发,是一种用于在 Hadoop与传统数据库间进行数据传递的开源工具
Mahout - Apache Mahout 项目提供分布式机器学习和数据挖掘库
创作不易 觉得有帮助请点赞关注收藏~~~