周末邓总让我帮忙看下重采样的代码,然后我就用上了自己的神器。
我的神器就是Google
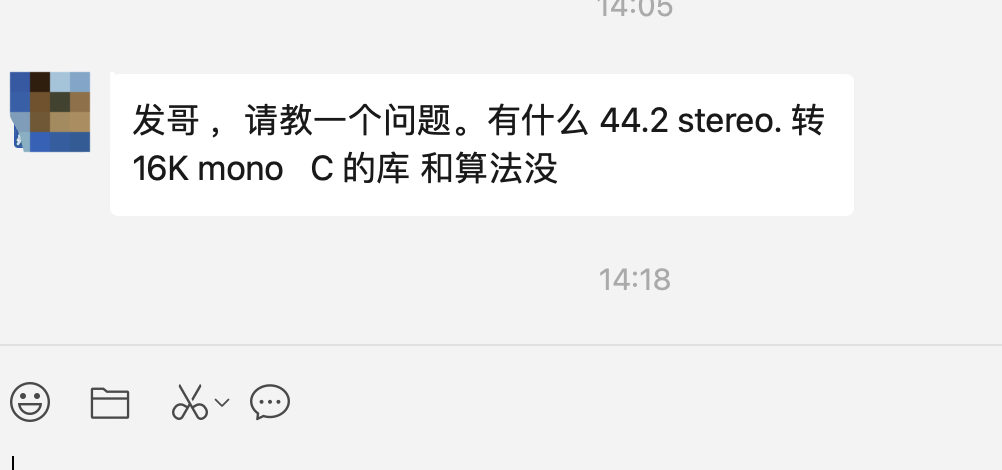
之后总结了下代码,完整的代码可以往下看,我们平时也会用到重采样,通道转换、交织和非交织的相互转换、给音频重新map等等。
这些都是做音频需要搞的东西,这可能和驱动还不太一样,驱动需要了解传输的协议,需要搞定寄存器,需要用示波器量清楚你的信号,需要对platform dai部分有了解等等。
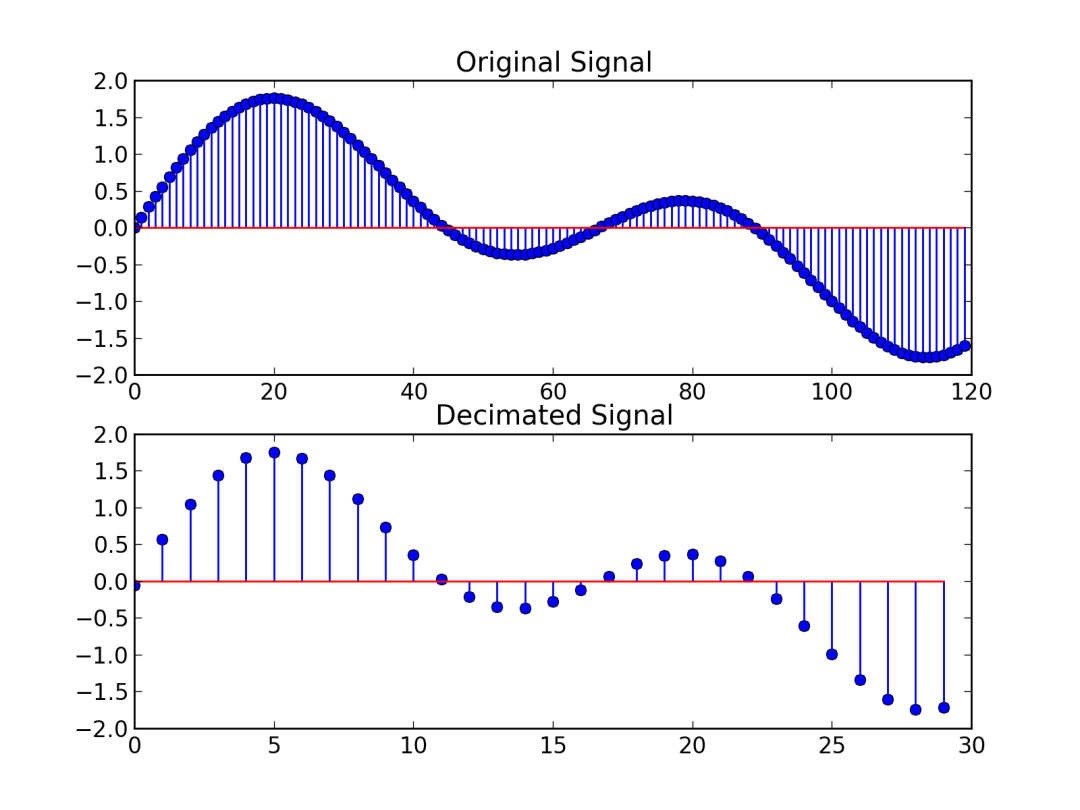
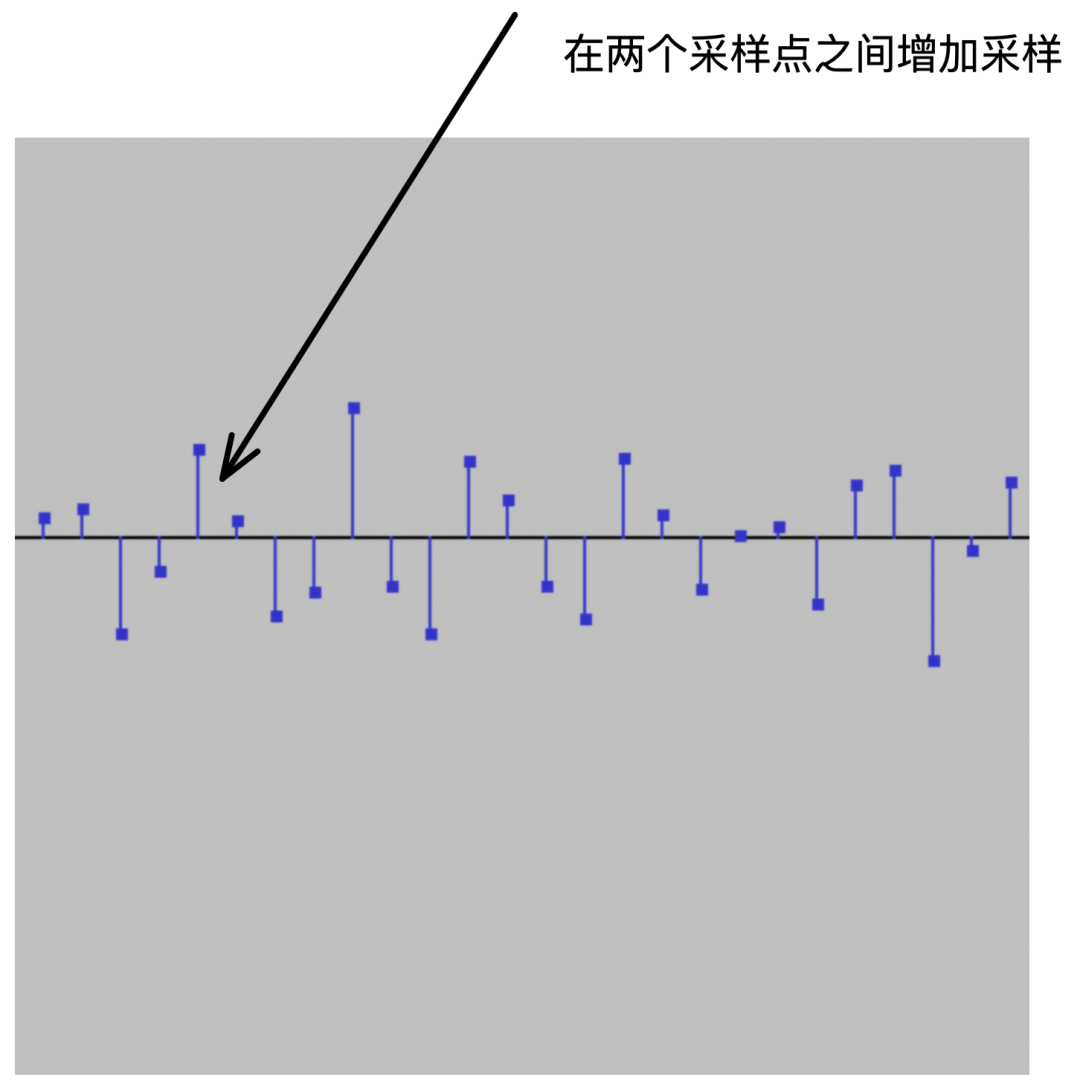
如果是把低采样率重采样成高采样率,那势必会导致音频数据的增大,这个时候就一定要搞清楚自己要用多大的buff,而且低采样率重采样成高采样率是有一定的处理要求的,相当于做原来没有的两个点之间插上新的数据点。
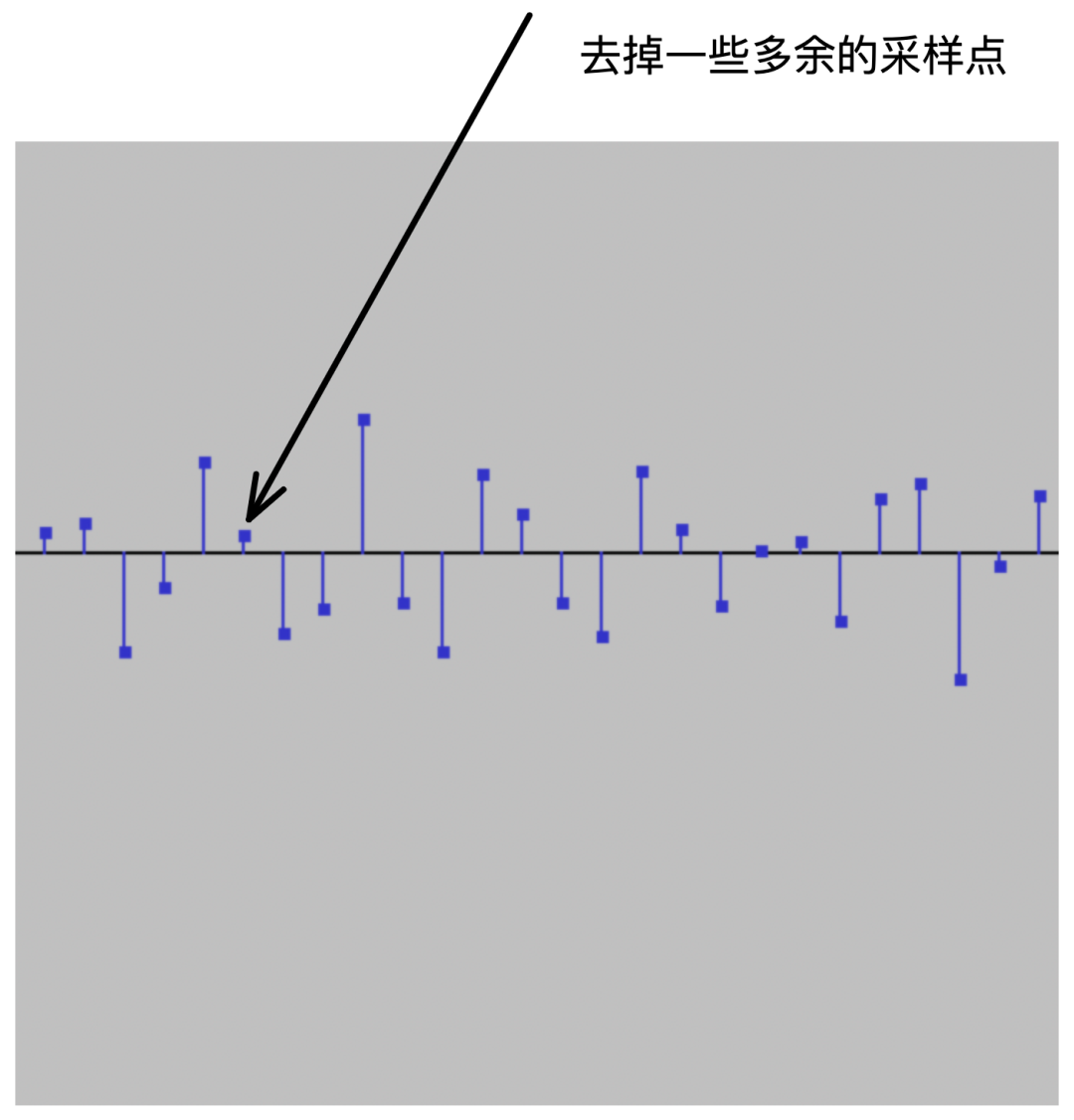
如果是高采样降低成低采样,从软件处理上会相对好处理一些,相当于把一些多余的数据给丢弃掉,只保留对应采样点上的数据。
下面是网上找的代码,并自己验证
github:
https://github.com/weiqifa0/c_resample
里面写了一些介绍
# c_resample
======================
代码来自并做了一些修改,降噪只能支持8k和16k
https://www.cnblogs.com/cpuimage/
# 编译
make
# 运行
./main_resample 8000hz_1ch_16bit.wav out.wav 44100
./main_noise noise_16k_16bit_1ch.wav 3
# 生成的文件
8000hz_1ch_16bit_out.wav
noise_16k_16bit_1ch_out.wav
重采样前的音频
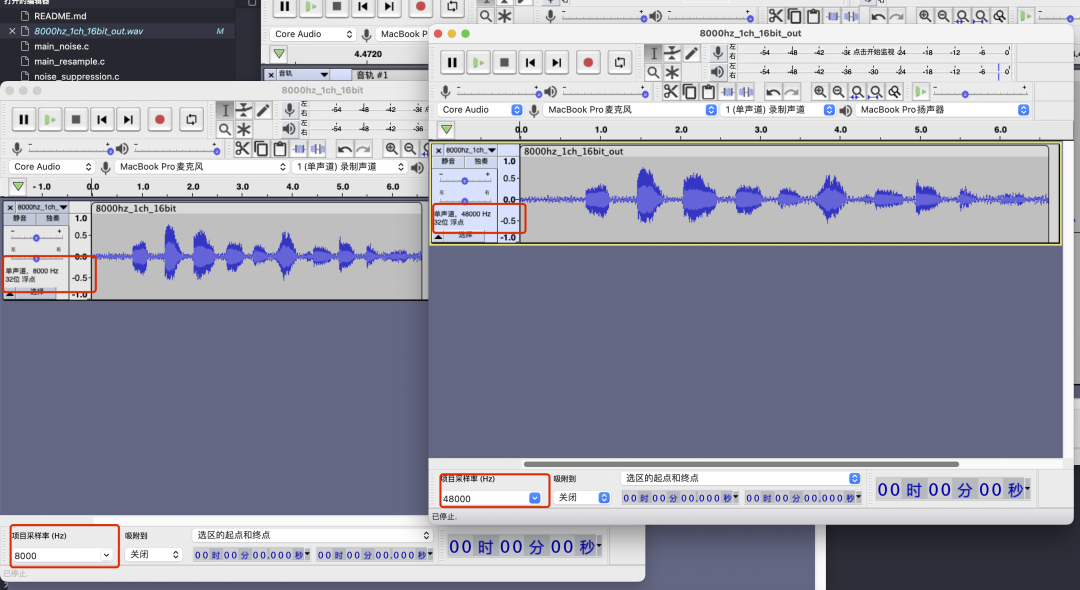
输入8K
输出48K
之后看了这个博主有一个降噪的案例
https://www.cnblogs.com/cpuimage/p/8905965.html
音频降噪算法,网上公开的算法不多,资源也比较有限。还是谷歌做了好事,把WebRTC开源,确实是一个基础。前人种树,后人乘凉。花了点时间,把WebRTC的噪声抑制模块提取出来,方便他人。噪声抑制在WebRTC中有两个版本,一个是浮点,一个是定点。一般定点做法是为了在一些特定环境下牺牲极少的精度,提升计算性能。这个就不展开了,涉及到算法性能优化方面的一些知识点。
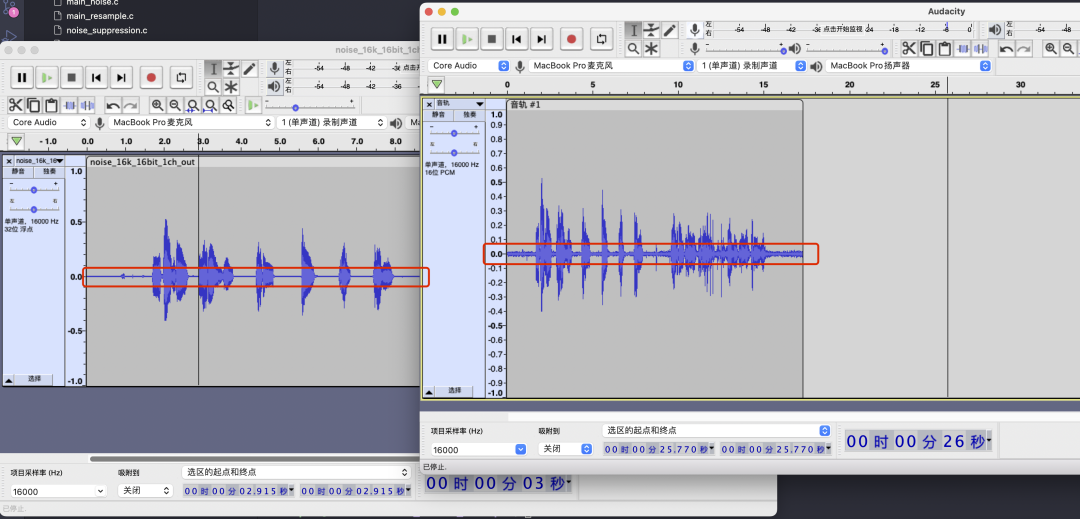
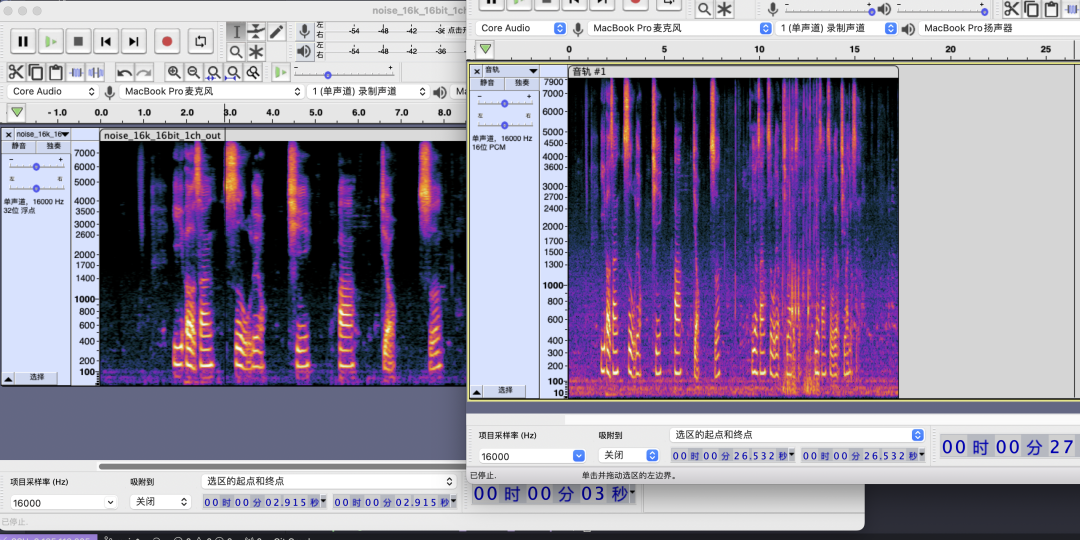
降噪前
降噪后
听了下音频,感觉降噪的效果不大,可能这个不是消噪,而是降低底噪。
好了,就这些
希望给做音视频的人一些帮助