文章目录
- 一、MySQL-优化
- 1、在MySQL中,如何定位慢查询?
- 2、SQL语句执行很慢, 如何分析呢?
- 3、了解过索引吗?(什么是索引)
- 4、索引的底层数据结构了解过嘛 ?
- 5、什么是聚簇索引什么是非聚簇索引 ?
- 6、知道什么是回表查询嘛 ?
- 7、知道什么叫覆盖索引嘛 ?
- 8、MYSQL超大分页怎么处理 ?
- 9、索引创建原则有哪些?
- 10、什么情况下索引会失效 ?(在联合索引的情况下)
- 11、谈一谈你对sql的优化的经验
- 二、事务
- 1、事务的特性是什么?可以详细说一下吗?
- 2、并发事务带来哪些问题?怎么解决这些问题呢?MySQL的默认隔离级别是?
- 2.1. 并发事务问题
- 2.2. MySQL的默认隔离级别
一、MySQL-优化
1、在MySQL中,如何定位慢查询?
- 方案一:开源工具
调试工具:Arthas
运维工具:Prometheus 、Skywalking
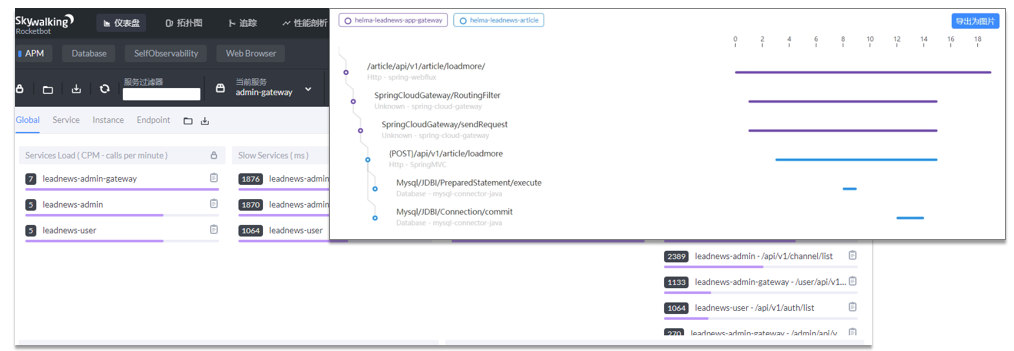
- 方案二:MySQL自带慢日志
可在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
慢日志文件中记录会记录sql执行时间超过设置时间的sql信息
localhost-slow.log。
- 其中就包括了sql执行的耗时,以及记录sql语句

2、SQL语句执行很慢, 如何分析呢?
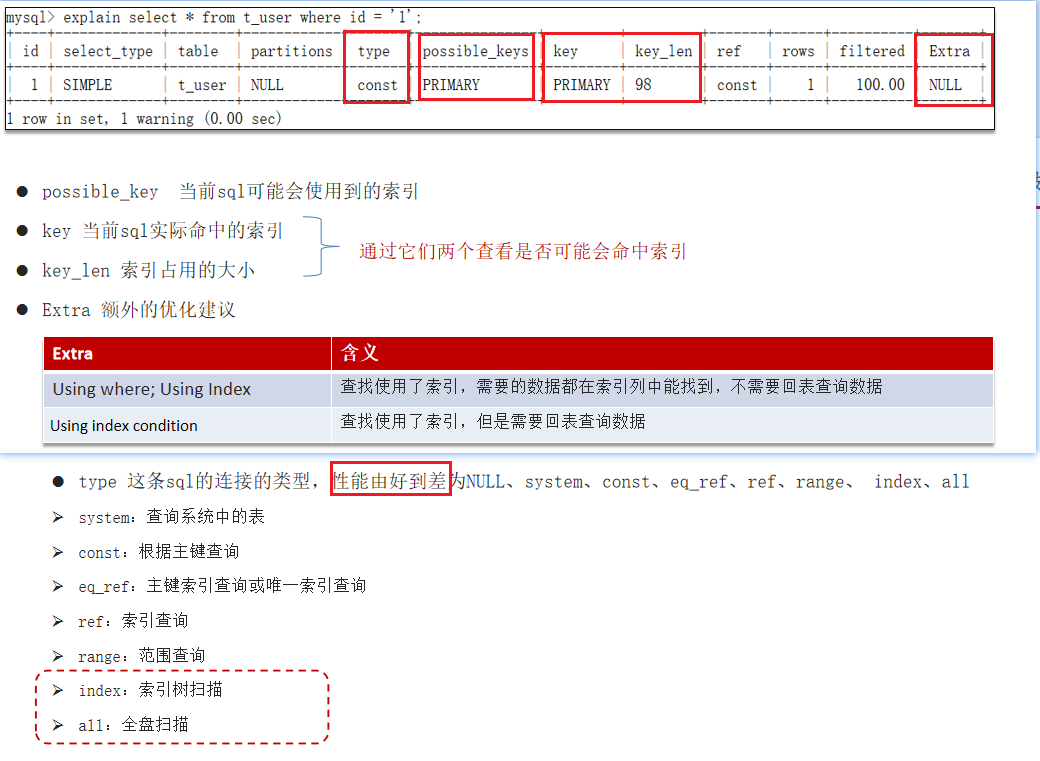 采用MySQL自带的分析工具
采用MySQL自带的分析工具 EXPLAIN:
也就是在sql前面加上EXPLAIN
- 通过
key和key_len检查是否命中了索引(索引本身存在是否有失效的情况) - 通过
type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描 - 通过
extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
3、了解过索引吗?(什么是索引)
- 索引(index)是帮助MySQL高效
获取数据的数据结构(有序) - 提高数据
检索的效率,降低数据库的IO成本(不需要全表扫描) - 通过索引列对数据进行排序,降低
数据排序的成本,降低了CPU的消耗
4、索引的底层数据结构了解过嘛 ?
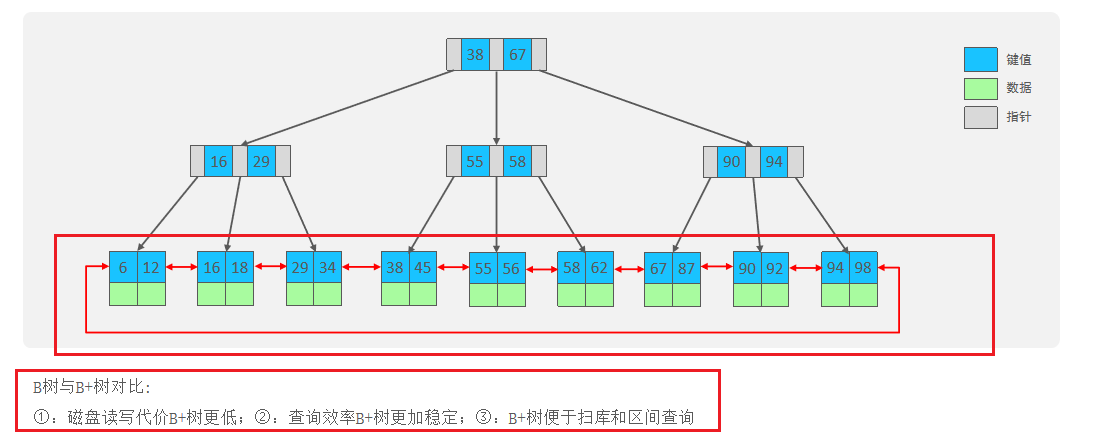
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,
非叶子节点只存储指针,叶子阶段存储数据 - B+树便于
扫库和区间查询,叶子节点是一个双向链表
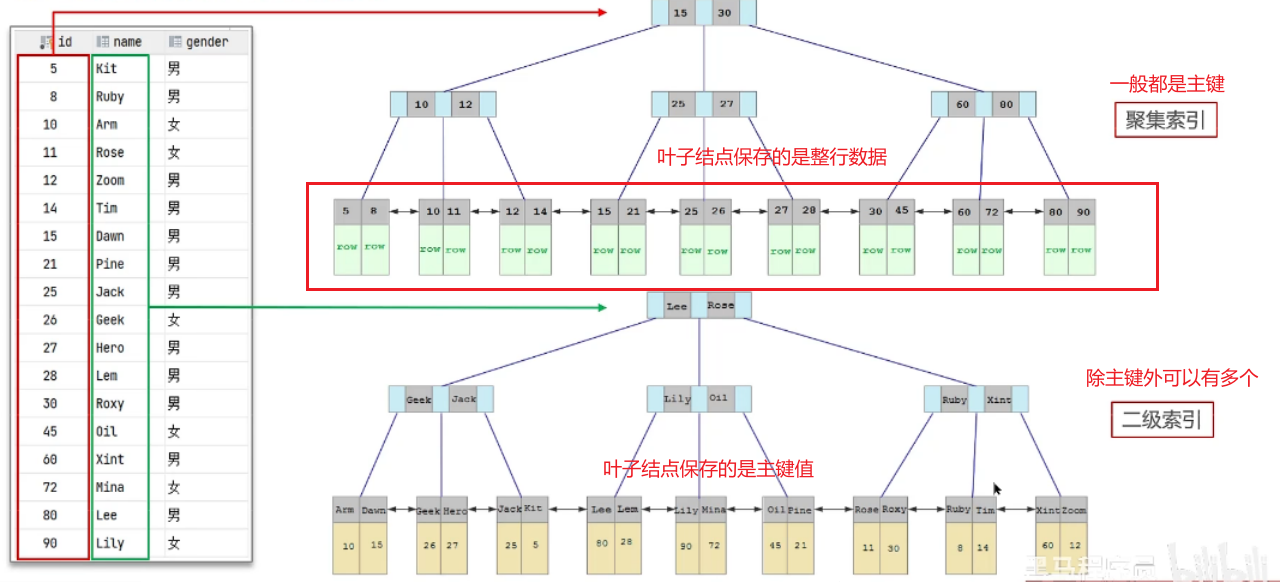
5、什么是聚簇索引什么是非聚簇索引 ?
- 聚簇索引:
聚簇索引(聚集索引):
数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个
- 非聚簇索引
非聚簇索引(二级索引):
数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个
6、知道什么是回表查询嘛 ?
要解释回表,就得解释一下聚簇索引和非聚簇索引。
通过二级索引找到对应的
主键值,到聚集索引中查找整行数据,这个过程就是回表
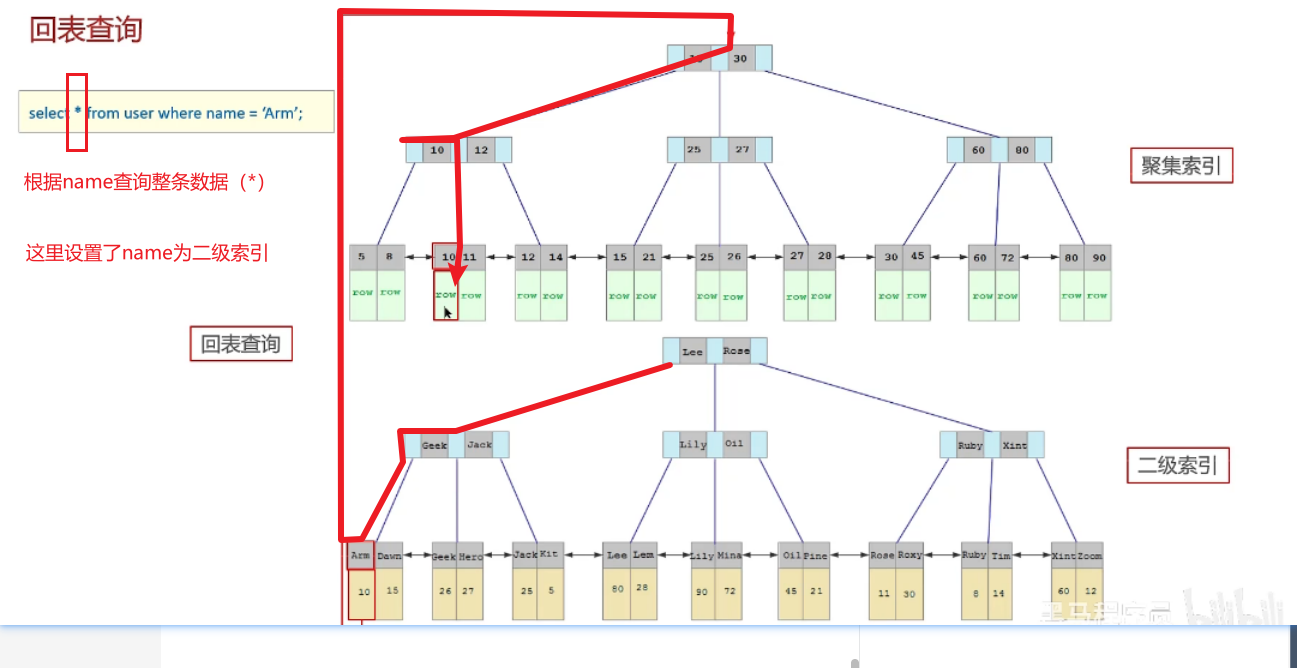
也就是说通过二级索引查到的仅仅是主键的值,索引还要根据查到的主键通过聚簇索引去查询到整条数据的信息。
7、知道什么叫覆盖索引嘛 ?
覆盖索引是指 查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到,
也就是通过索引能直接查询到想要的数据,不需要回表。
例如下面的sql:
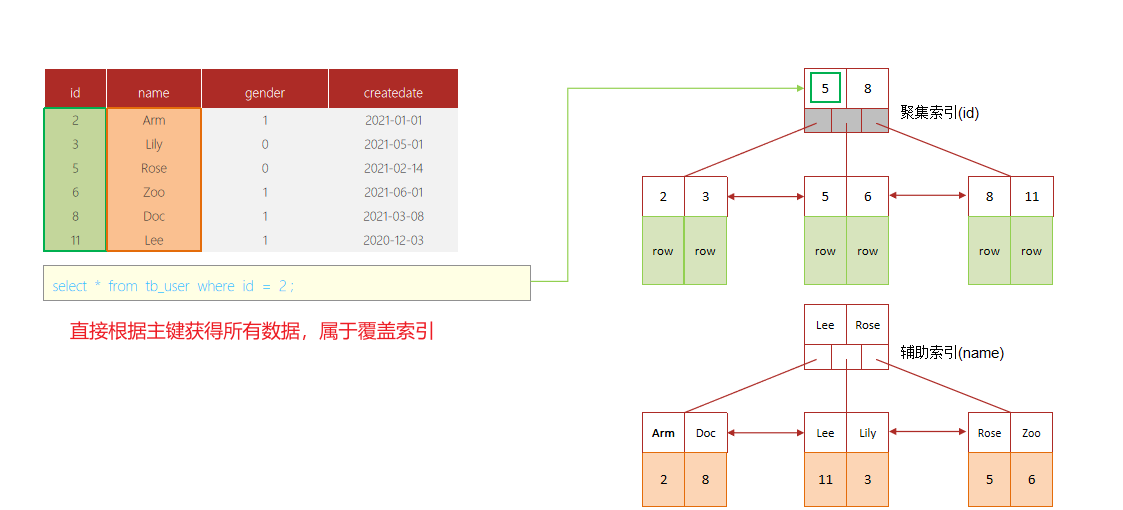

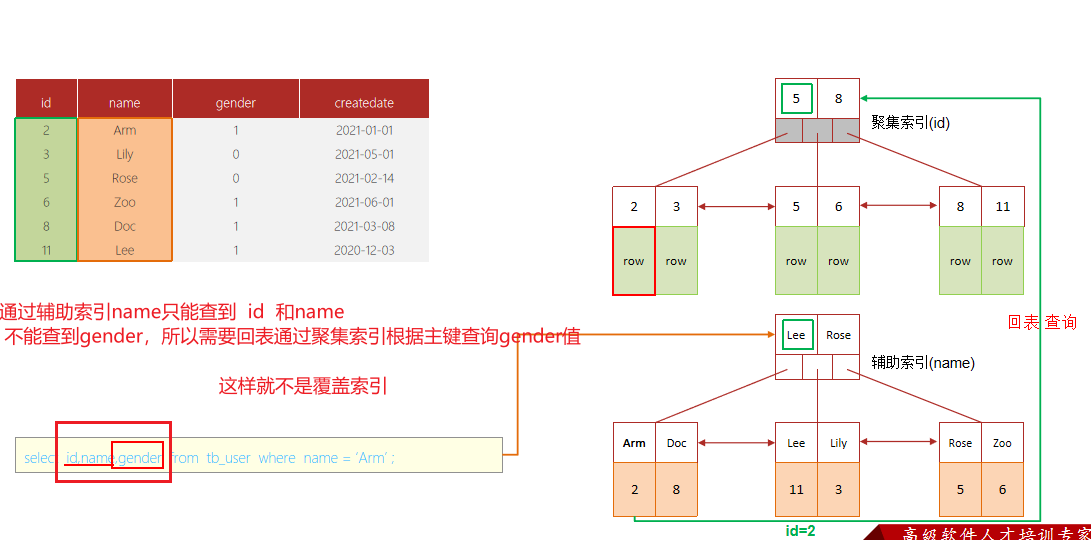
- 覆盖索引是指查询
使用了索引,返回的列,必须在索引中全部能够找到 - 使用
id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。 - 如果返回的列中没有创建索引,有可能会触发回表查询,尽量
避免使用select *
8、MYSQL超大分页怎么处理 ?
可以使用覆盖索引+子查询解决

9、索引创建原则有哪些?
1). 数据量较大,且查询比较频繁的表
2). 常作为查询条件、排序、分组的字段
3). 字段内容区分度高
4). 内容较长,使用前缀索引
5). 尽量联合索引
6). 要控制索引的数量
7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它
10、什么情况下索引会失效 ?(在联合索引的情况下)

假设该表使用了如下联合索引:

name, status, address
-
违反
最左前缀法则

-
范围查询右边的列,不能使用索引

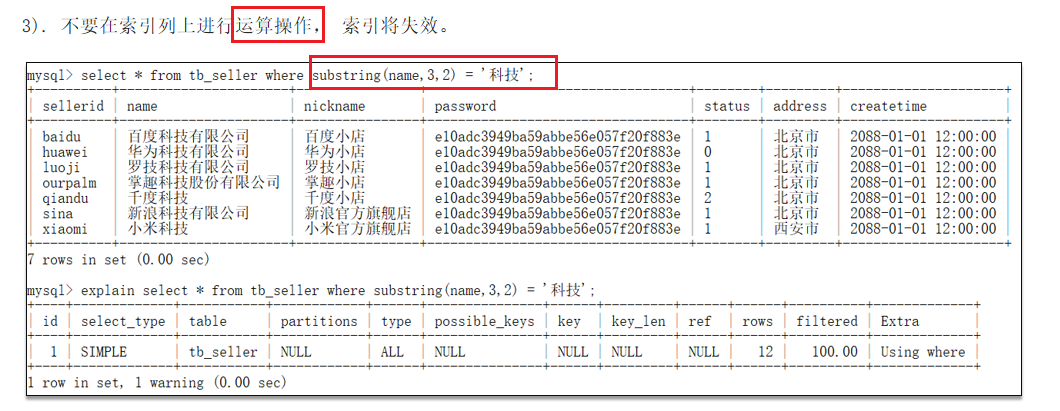
-
不要在
索引列上进行运算操作, 索引将失效
-
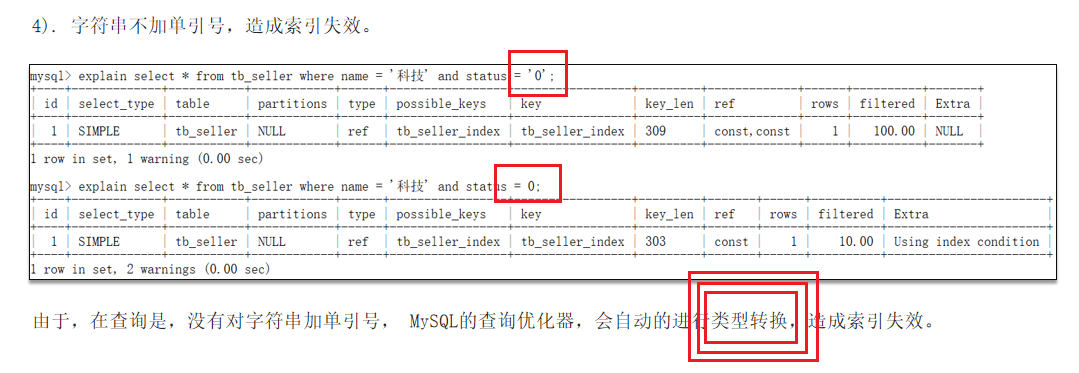
字符串不加单引号,造成索引失效。(类型转换)
-
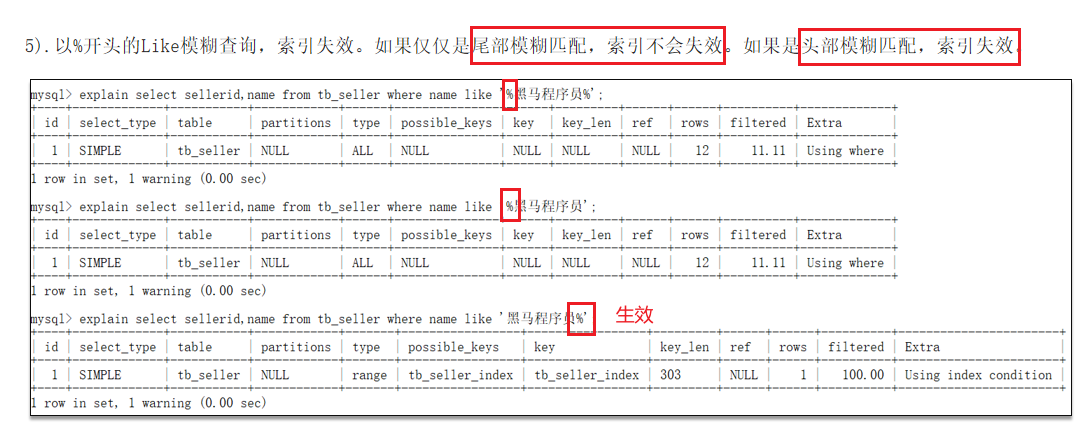
以%开头的Like模糊查询,索引失效
11、谈一谈你对sql的优化的经验
1. 表的设计优化
比如设置合适的数值(tinyint int bigint),要
根据实际情况选择
比如
设置合适的字符串类型(char和varchar)char定长效率高,varchar可变长度,效率稍低
2. 索引优化
3. SQL语句优化
SELECT语句务必
指明字段名称(避免直接使用select * ,也是为了能使用覆盖索引,用什么数据就查什么数据)
SQL语句要避免造成索引失效的写法
尽量用union all代替union
union会多一次过滤,效率低(数据量多了,执行过滤操作耗时严重)
避免在where子句中对字段进行
表达式操作(也就是怕索引失效)
Join优化
能用innerjoin 就不用left join right join,如必须使用 一定要以小表为驱动
内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。left join 或 right join,不会重新调整顺序
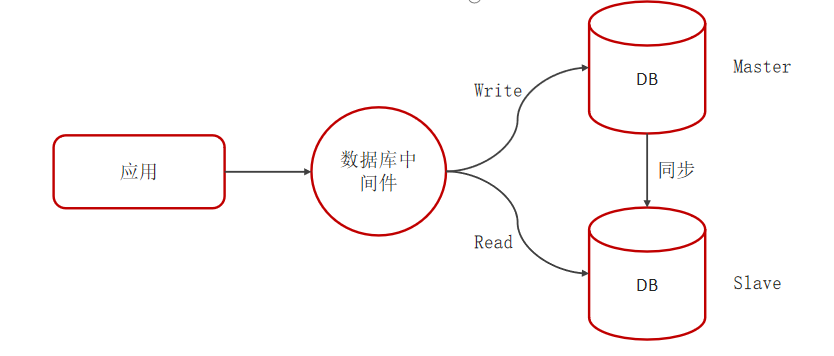
4. 主从复制、读写分离
- 如果数据库的使用场景读的操作比较多的时候,为了避免写的操作所造成的性能影响 可以采用读写分离的架构。
- 读写分离解决的是,数据库的写入,影响了查询的效率。
5. 分库分表
只在数据量非常大的情况才去做
二、事务
1、事务的特性是什么?可以详细说一下吗?
原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。(不成功,便成仁)一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。(双方都是一致的状态)隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。(不受干扰)持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。(写进磁盘)
很好的例子就是转账操作
2、并发事务带来哪些问题?怎么解决这些问题呢?MySQL的默认隔离级别是?
2.1. 并发事务问题
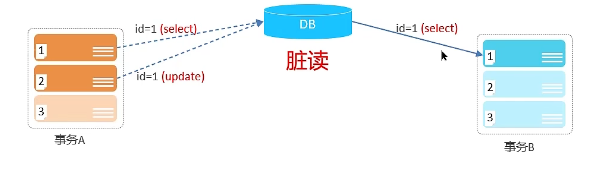
脏读:一个事务读到另外一个事务还没有提交的数据。
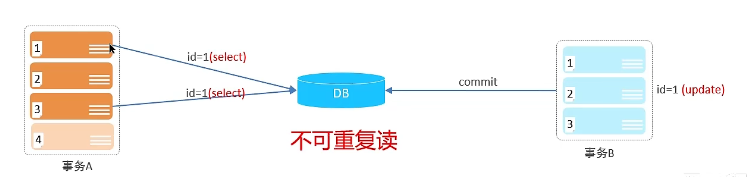
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
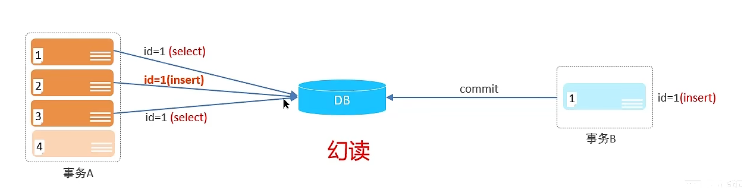
幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了”幻影”。
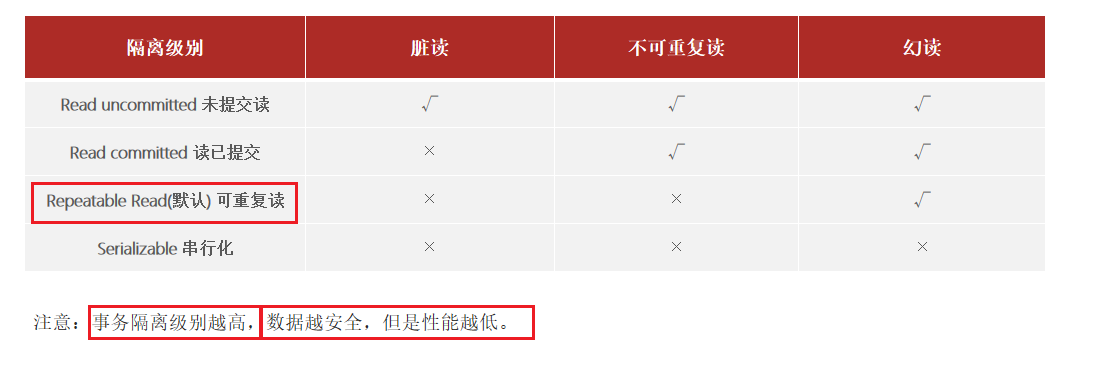
2.2. MySQL的默认隔离级别
解决方案:对事务进行隔离
默认采用的隔离机制可重复读(不能解决幻读,但是相比其他的隔离机制,在性能和安全级别算是最优解了)
更新中》》》》》》》
参考来自:黑马程序员