目录
1.PCIe Dma coherent前言
2.DMA与Cache 的一致性
2.1一致性问题
2.2Coherent DMA buffers 一致性
2.3DMA Streaming Mapping 流式DMA映射
2.4dma_alloc_coherent的例外
2.5SMMU | IOMMU
3.Linux 内核中 DMA 及 Cache 分析
3.1arm
3.2DMA ZONE
3.3DMA ZONE 的内存只能做 DMA 吗?
3.4dma_mask 与 coherent_dma_mask 的定义
3.5dma_alloc_coherent 分配的内存一定在 DMA ZONE 内吗?
3.6dma_alloc_coherent() 申请的内存是非 cache 的吗?
1.PCIe Dma coherent前言
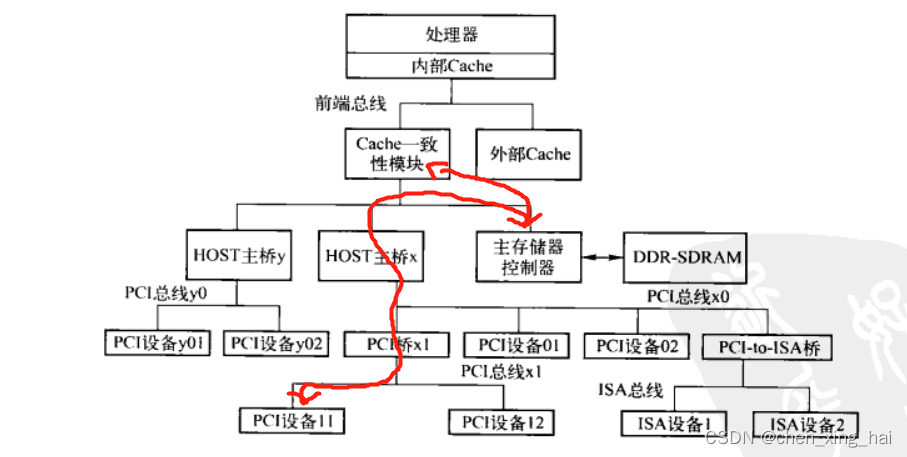
HOST主桥与主存存储器来同一级内部高速总线上,方便PCI设备通过HOST主桥访问主存储器,即进行DMA操作。
值得注意的是,PCI设备的DMA操作需要处理器系统的Cache进行一致性操作。当PCI设备通过HOST主桥访问主存储器时,Cache一致性模块将进行地址监听,并根据监听结果改变Cache状态。
Linux对cache一致性有两种管理方式:1. mem 硬件上uncache 2. 使用过程中,通过flush cache 保证data 一致性。
使用大块DMA一致性内存,此操作分配的内存大小有限制,如最小分配一个页:
dma_alloc_coherent dma_zalloc_coherent 分配dma使用的内存,并返回内存的物理地址及对应虚拟地址,与其他内存分配函数不同必须在中断使能的情况下使用
dma_free_coherent 释放dma_alloc_coherent分配的内存。
使用小块DMA一致性内存,先创建dma内存池,然后在内存池中分配小内存:
struct dma_pool* dma_pool_create(const char *name, struct device *dev, size_t size, size_t align, size_t alloc); 创建DMA一致性内存的内存池,必须在可睡眠的上下文中执行。align必须2的幂次方,如果等于0则为1,size最小为4
void dma_pool_destroy(struct dma_pool *pool);在调用此函数之前,必须free掉所有从此pool中分配的内存
void *dma_pool_alloc(struct dma_pool *pool, gfp_t gfp_flags, dma_addr_t *dma_handle);从内存池中分配内存,返回的内存同时满足申请的大小及对齐要求。如果内存池中内存不够,则会自动kmalloc内存并放入到pool中
void dma_pool_free(struct dma_pool *pool, void *vaddr, dma_addr_t addr);
2.DMA与Cache 的一致性
2.1一致性问题
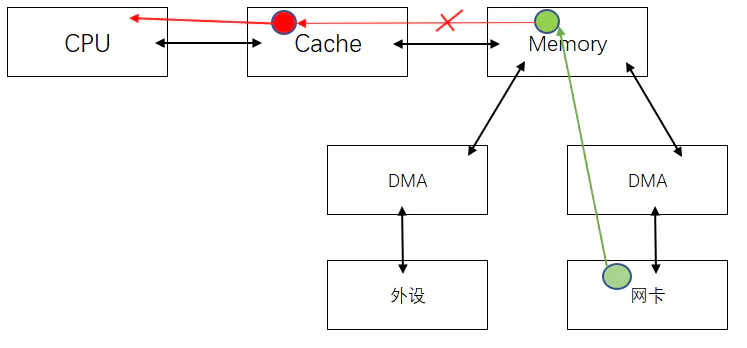
mem中有一块报文,cpu会将这块报文读到cache,cpu再读这块,cache hit。则会从cache中取值。
- 如果外设是一张网卡,通过DMA 数据传到内存,将红色这块涂成了绿色。内存已经绿了,但是cpu读这块数据却还是红色。造成内存 cache 不一致。
- 同样 CPU 写红色区域数据的告诉cache, cache 并没有与mem做同步的话,此时数据经过DMA,发送的报文也是有问题的。
解决方案:
- Coherent DMA buffers 一致性
- DMA Streaming Mapping 流式DMA映射
2.2Coherent DMA buffers 一致性
-
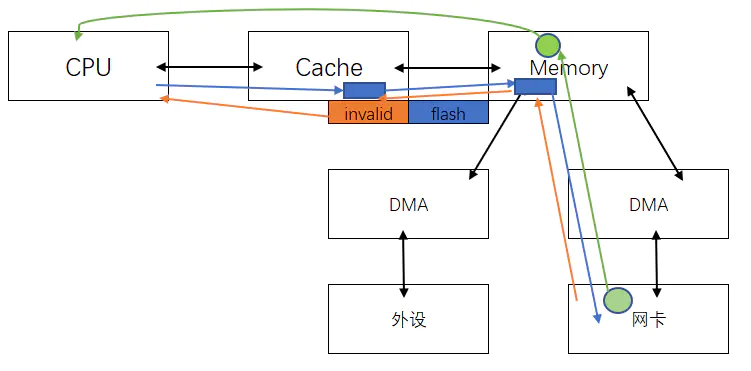
对于一个很弱的硬件,当硬件没有对一致性问题有帮助的时候。
dma_alloc_coherent, 写驱动的时候自己申请的一片内存。- cpu 读写不带cache
- dma读写也不带cache
这样就不会出现一致性问题。但是很多情况下你又不能用dma_alloc_coherent, 除非自己写驱动,自己申请的内存。
但是很多情况下,一个tcp/ip 协议栈,有一个 socket buffer, 这块buffer 并不是程序员申请出来的内存。这时候不可能用dma_alloc_coherent.
2.3DMA Streaming Mapping 流式DMA映射
- DMA Streaming Mapping 流式DMA映射
- 发包
此时可以用 dma_map_single 与 dma_unmap_single, 这个api 会将cache里的非程序员用dma申请的内存做一次flush,同步到内存中。 - 收包
会将cache 里的内容 置换为 invalid, 详情见cache line 那一章节的 关于MESI一致性的阐述。CPU是可以控制cache 的 flag,但他不能访问某块cache的 第几个byte的
还有 dma_map_sg, dma_unmap_sg这两个API,有的dma引擎较强,支持 聚集散列,自动传n个buffer,第一个传完,传第二个,并不需要连续的内存做DMA.可以用上述两个api,可以将多个不连续的 buffer 做自动传输(以后接触到再查资料学习把)。
- 发包
2.4dma_alloc_coherent的例外

一般情况下这个api 是不带cache(绿色)。但是当cpu支持cache互联网络。cache coherent interconnnect,CPU的cache 可以感知到外部设备。硬件做同步。 (就是MESI的同步手段)。此时dam_alloc_coherent申请的内存就可以带上cache
表面上都是 上述关于dma的API,但是后端针对不同的平台,实现的可能不同。
2.5SMMU | IOMMU
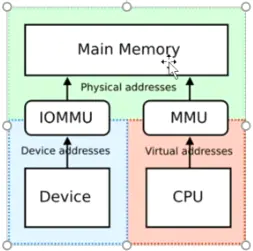
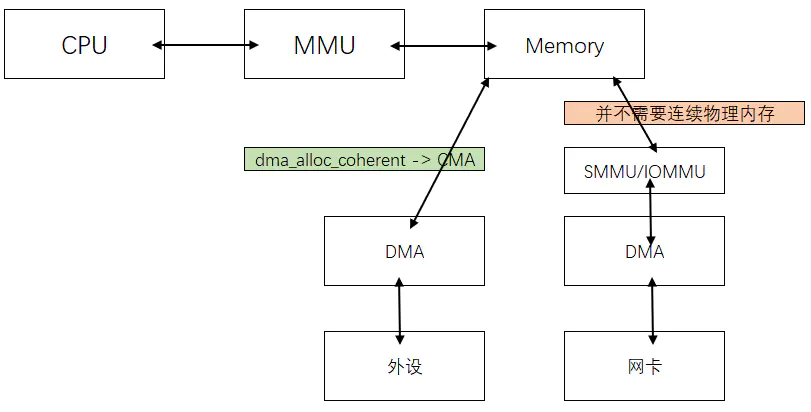
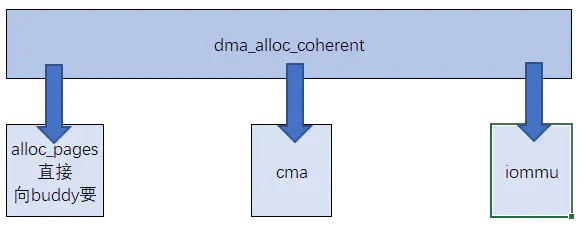
DMA 自带 MMU,因此带有SMMU的DMA并不在乎申请的内存是否连续,会将物理地址映射成虚拟连续的。但是申请内存依旧使用dma_alloc_coherent。上述几个不带MMU的DMA 申请的内存 都是通过CMA (管CMA要)申请的连续内存。
但是带有MMU的DMA申请内存可以不连续
由此可以看出硬件帮你做了很多工作后,你就少操心很多啦。
3.Linux 内核中 DMA 及 Cache 分析
涉及以下函数
dma_alloc_coherentdma_map_singledma_alloc_writecombinepgprot_noncachedremap_pfn_range
- Linux Kernel: 4.9.22
- Arch: arm
3.1arm
arch/arm/mm/dma-mapping.cinclude/linux/dma-mapping.h
几个关键变量和函数
atomic_pool_init和DEFAULT_DMA_COHERENT_POOL_SIZEdma zone、dma pool、setup_dma_zone和CONFIG_ZONE_DMAcoherent_dma_mask和dma_zone_size
3.2DMA ZONE
存在 DMA ZONE 的原因是某些硬件的 DMA 引擎 不能访问到所有的内存区域,因此,加上一个 DMA ZONE,当使用 GFP_DMA 方式申请内存时,获得的内存限制在 DMA ZONE 的范围内,这些特定的硬件需要使用 GFP_DMA 方式获得可以做 DMA 的内存;
如果系统中所有的设备都可选址所有的内存,那么 DMA ZONE 覆盖所有内存。DMA ZONE 的大小,以及 DMA ZONE 要不要存在,都取决于你实际的硬件是什么。
由于设计及硬件的使用模式, DMA ZONE 可以不存在
由于现如今绝大多少的
SoC都很牛逼,似乎DMA都没有什么缺陷了,根本就不太可能给我们机会指定DMA ZONE大小装逼了,那个这个ZONE就不太需要存在了。反正任何DMA在任何地方申请的内存,这个DMA都可以存取到。
3.3DMA ZONE 的内存只能做 DMA 吗?
DMA ZONE 的内存做什么都可以。 DMA ZONE 的作用是让有缺陷的 DMA 对应的外设驱动申请 DMA buffer 的时候从这个区域申请而已,但是它不是专有的。其他所有人的内存(包括应用程序和内核)也可以来自这个区域。
3.4dma_mask 与 coherent_dma_mask 的定义
include/linux/device.h
struct device {
...
u64 *dma_mask; /* dma mask (if dma'able device) */
u64 coherent_dma_mask;/* Like dma_mask, but for
alloc_coherent mappings as
not all hardware supports
64 bit addresses for consistent
allocations such descriptors. */
unsigned long dma_pfn_offset;
struct device_dma_parameters *dma_parms;
struct list_head dma_pools; /* dma pools (if dma'ble) */
struct dma_coherent_mem *dma_mem; /* internal for coherent mem
...
};
dma_mask 与 coherent_dma_mask 这两个参数表示它能寻址的物理地址的范围,内核通过这两个参数分配合适的物理内存给 device。 dma_mask 是 设备 DMA 能访问的内存范围, coherent_dma_mask 则作用于申请 一致性 DMA 缓冲区。因为不是所有的硬件都能够支持 64bit 的地址宽度。如果 addr_phy 是一个物理地址,且 (u64)addr_phy <= *dev->dma_mask,那么该 device 就可以寻址该物理地址。如果 device 只能寻址 32 位地址,那么 mask 应为 0xffffffff。依此类推。
例如内核代码 arch/arm/mm/dma-mapping.c
static void *__dma_alloc(struct device *dev, size_t size, dma_addr_t *handle,
gfp_t gfp, pgprot_t prot, bool is_coherent,
unsigned long attrs, const void *caller)
{
u64 mask = get_coherent_dma_mask(dev);
struct page *page = NULL;
void *addr;
bool allowblock, cma;
struct arm_dma_buffer *buf;
struct arm_dma_alloc_args args = {
.dev = dev,
.size = PAGE_ALIGN(size),
.gfp = gfp,
.prot = prot,
.caller = caller,
.want_vaddr = ((attrs & DMA_ATTR_NO_KERNEL_MAPPING) == 0),
.coherent_flag = is_coherent ? COHERENT : NORMAL,
};
#ifdef CONFIG_DMA_API_DEBUG
u64 limit = (mask + 1) & ~mask;
if (limit && size >= limit) {
dev_warn(dev, "coherent allocation too big (requested %#x mask %#llx)\n",
size, mask);
return NULL;
}
#endif
...
}
imit 就是通过 mask 计算得到的设备最大寻址范围
3.5dma_alloc_coherent 分配的内存一定在 DMA ZONE 内吗?
dma_alloc_coherent() 申请的内存来自于哪里,不是因为它的名字前面带了个 dma_ 就来自 DMA ZONE 的,本质上取决于对应的 DMA 硬件是谁。应该说绝对多数情况下都不在 DMA ZONE 内,代码如下
dma_alloc_coherent -> dma_alloc_attr
static inline void *dma_alloc_attrs(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flag,
unsigned long attrs)
{
struct dma_map_ops *ops = get_dma_ops(dev);
void *cpu_addr;
BUG_ON(!ops);
if (dma_alloc_from_coherent(dev, size, dma_handle, &cpu_addr))
return cpu_addr;
if (!arch_dma_alloc_attrs(&dev, &flag))
return NULL;
if (!ops->alloc)
return NULL;
cpu_addr = ops->alloc(dev, size, dma_handle, flag, attrs);
debug_dma_alloc_coherent(dev, size, *dma_handle, cpu_addr);
return cpu_addr;
}
在 dma_alloc_attrs 首先通过 dma_alloc_from_coherent 从 device 自己的 dma memory 中申请,如果没有再通过 ops->alloc 申请, arm 如下
static struct dma_map_ops *arm_get_dma_map_ops(bool coherent)
{
return coherent ? &arm_coherent_dma_ops : &arm_dma_ops;
}
struct dma_map_ops arm_coherent_dma_ops = {
.alloc = arm_coherent_dma_alloc,
.free = arm_coherent_dma_free,
.mmap = arm_coherent_dma_mmap,
.get_sgtable = arm_dma_get_sgtable,
.map_page = arm_coherent_dma_map_page,
.map_sg = arm_dma_map_sg,
};
EXPORT_SYMBOL(arm_coherent_dma_ops);
static void *arm_coherent_dma_alloc(struct device *dev, size_t size,
dma_addr_t *handle, gfp_t gfp, unsigned long attrs)
{
return __dma_alloc(dev, size, handle, gfp, PAGE_KERNEL, true,
attrs, __builtin_return_address(0));
}
static void *__dma_alloc(struct device *dev, size_t size, dma_addr_t *handle,
gfp_t gfp, pgprot_t prot, bool is_coherent,
unsigned long attrs, const void *caller)
{
u64 mask = get_coherent_dma_mask(dev);
struct page *page = NULL;
void *addr;
bool allowblock, cma;
struct arm_dma_buffer *buf;
struct arm_dma_alloc_args args = {
.dev = dev,
.size = PAGE_ALIGN(size),
.gfp = gfp,
.prot = prot,
.caller = caller,
.want_vaddr = ((attrs & DMA_ATTR_NO_KERNEL_MAPPING) == 0),
.coherent_flag = is_coherent ? COHERENT : NORMAL,
};
#ifdef CONFIG_DMA_API_DEBUG
u64 limit = (mask + 1) & ~mask;
if (limit && size >= limit) {
dev_warn(dev, "coherent allocation too big (requested %#x mask %#llx)\n",
size, mask);
return NULL;
}
#endif
if (!mask)
return NULL;
buf = kzalloc(sizeof(*buf),
gfp & ~(__GFP_DMA | __GFP_DMA32 | __GFP_HIGHMEM));
if (!buf)
return NULL;
if (mask < 0xffffffffULL)
gfp |= GFP_DMA;
/*
* Following is a work-around (a.k.a. hack) to prevent pages
* with __GFP_COMP being passed to split_page() which cannot
* handle them. The real problem is that this flag probably
* should be 0 on ARM as it is not supported on this
* platform; see CONFIG_HUGETLBFS.
*/
gfp &= ~(__GFP_COMP);
args.gfp = gfp;
*handle = DMA_ERROR_CODE;
allowblock = gfpflags_allow_blocking(gfp); // gfp
cma = allowblock ? dev_get_cma_area(dev) : false;
根据不同的取值采用不同allowblock
if (cma)
buf->allocator = &cma_allocator;
else if (nommu() || is_coherent)
buf->allocator = &simple_allocator;
else if (allowblock)
buf->allocator = &remap_allocator;
else
buf->allocator = &pool_allocator;
addr = buf->allocator->alloc(&args, &page);
if (page) {
unsigned long flags;
*handle = pfn_to_dma(dev, page_to_pfn(page));
buf->virt = args.want_vaddr ? addr : page;
spin_lock_irqsave(&arm_dma_bufs_lock, flags);
list_add(&buf->list, &arm_dma_bufs);
spin_unlock_irqrestore(&arm_dma_bufs_lock, flags);
} else {
kfree(buf);
}
return args.want_vaddr ? addr : page;
}
&pool_allocator 从 DMA POOL 中分配,使用函数 atomic_pool_init 创建
代码段
if (mask < 0xffffffffULL)
gfp |= GFP_DMA;
GFP_DMA 标记被设置,以指挥内核从 DMA ZONE 申请内存。但是 mask 覆盖了整个 4GB,调用 dma_alloc_coherent() 获得的内存就不需要一定是来自 DMA ZON
static void *pool_allocator_alloc(struct arm_dma_alloc_args *args,
struct page **ret_page)
{
return __alloc_from_pool(args->size, ret_page);
}
static void pool_allocator_free(struct arm_dma_free_args *args)
{
__free_from_pool(args->cpu_addr, args->size);
}
static struct arm_dma_allocator pool_allocator = {
.alloc = pool_allocator_alloc,
.free = pool_allocator_free,
};
static void *__alloc_from_pool(size_t size, struct page **ret_page)
{
unsigned long val;
void *ptr = NULL;
if (!atomic_pool) {
WARN(1, "coherent pool not initialised!\n");
return NULL;
}
val = gen_pool_alloc(atomic_pool, size);
if (val) {
phys_addr_t phys = gen_pool_virt_to_phys(atomic_pool, val);
*ret_page = phys_to_page(phys);
ptr = (void *)val;
}
return ptr;
}
3.6dma_alloc_coherent() 申请的内存是非 cache 的吗?
缺省情况下, dma_alloc_coherent() 申请的内存缺省是进行 uncache 配置的。但是现代 SOC 有可能会将内核的通用实现 overwrite 掉,变成 dma_alloc_coherent() 申请的内存也是可以带 cache 的。
static struct dma_map_ops *arm_get_dma_map_ops(bool coherent)
{
return coherent ? &arm_coherent_dma_ops : &arm_dma_ops;
}
struct dma_map_ops arm_coherent_dma_ops = {
.alloc = arm_coherent_dma_alloc,
.free = arm_coherent_dma_free,
.mmap = arm_coherent_dma_mmap,
.get_sgtable = arm_dma_get_sgtable,
.map_page = arm_coherent_dma_map_page,
.map_sg = arm_dma_map_sg,
};
EXPORT_SYMBOL(arm_coherent_dma_ops);
static int macb_alloc_consistent(struct macb *bp)
{
struct macb_queue *queue;
unsigned int q;
int size;
for (q = 0, queue = bp->queues; q < bp->num_queues; ++q, ++queue) {
size = TX_RING_BYTES(bp) + bp->tx_bd_rd_prefetch;
queue->tx_ring = dma_alloc_coherent(&bp->pdev->dev, size,
&queue->tx_ring_dma,
GFP_KERNEL);
if (!queue->tx_ring)
goto out_err;
netdev_dbg(bp->dev,
"Allocated TX ring for queue %u of %d bytes at %08lx (mapped %p)\n",
q, size, (unsigned long)queue->tx_ring_dma,
queue->tx_ring);
size = bp->tx_ring_size * sizeof(struct macb_tx_skb);
queue->tx_skb = kmalloc(size, GFP_KERNEL);
if (!queue->tx_skb)
goto out_err;
size = RX_RING_BYTES(bp) + bp->rx_bd_rd_prefetch;
queue->rx_ring = dma_alloc_coherent(&bp->pdev->dev, size,
&queue->rx_ring_dma, GFP_KERNEL);
if (!queue->rx_ring)
goto out_err;
netdev_dbg(bp->dev,
"Allocated RX ring of %d bytes at %08lx (mapped %p)\n",
size, (unsigned long)queue->rx_ring_dma, queue->rx_ring);
}
if (bp->macbgem_ops.mog_alloc_rx_buffers(bp))
goto out_err;
return 0;
out_err:
macb_free_consistent(bp);
return -ENOMEM;
}
-
dma_alloc_coherent 在 arm 平台上会禁止页表项中的 C (Cacheable) 域以及 B (Bufferable)域。 -
而 dma_alloc_writecombine 只禁止 C (Cacheable) 域.
C 代表是否使用高速缓冲存储器(cacheline), 而 B 代表是否使用写缓冲区。
这样,dma_alloc_writecombine 分配出来的内存不使用缓存,但是会使用写缓冲区。而 dma_alloc_coherent 则二者都不使用。
C B 位的具体含义
0 0 无cache,无写缓冲;任何对memory的读写都反映到总线上。对 memory 的操作过程中CPU需要等待。
0 1 无cache,有写缓冲;读操作直接反映到总线上;写操作,CPU将数据写入到写缓冲后继续运行,由写缓冲进行写回操作。
1 0 有cache,写通模式;读操作首先考虑cache hit;写操作时直接将数据写入写缓冲,如果同时出现cache hit,那么也更新cache。
1 1 有cache,写回模式;读操作首先考虑cache hit;写操作也首先考虑cache hit。
效率最高的写回,其次写通,再次写缓冲,最次非CACHE一致性操作。
其实,写缓冲也是一种非常简单得CACHE,为何这么说呢。
我们知道,DDR是以突发读写的,一次读写总线上实际会传输一个burst的长度,这个长度一般等于一个cache line的长度。
cache line是32bytes。即使读1个字节数据,也会传输32字节,放弃31字节。
写缓冲是以CACHE LINE进行的,所以写效率会高很多。






![[附源码]Nodejs计算机毕业设计基于Java的智慧停车软件Express(程序+LW)](https://img-blog.csdnimg.cn/2e958b72a9284b55a3dca85219b6cb49.png)