一、Blip2出现的意义不比ChatGPT差
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
论文链接:https://arxiv.org/abs/2301.12597
代码仓库:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
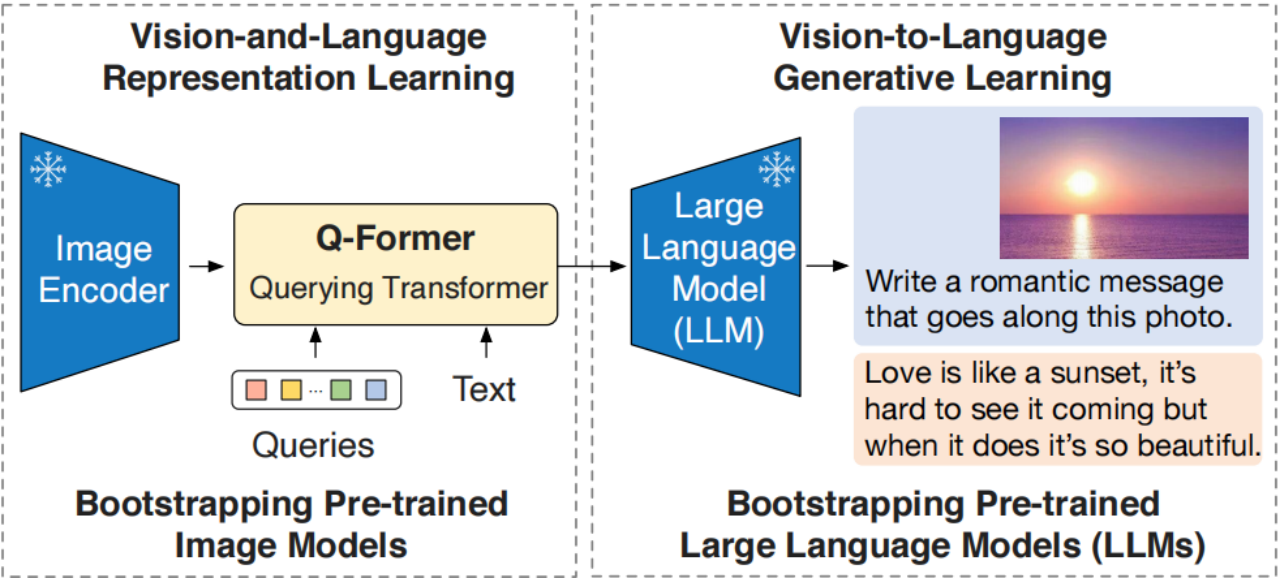
总体思路:图像与语言特征空间对齐,这样就能复用训练好的大模型
如下图,语言编码(这里是VQA),LLM模型(这里是LLAMA)都是冻结训练的。
1 训练过程
1.1 第一阶段训练
只看生成图像模型(Bootstrapping Pre-trained Image Models)部分,从冻结图像编码器(ViT)引导视觉-语言表示学习,强制 Q-Former 学习与文本最相关的视觉表示。下图左边为图像解码器+内部放大的Q-Former。Q-Former 通过一组可学习的嵌入(Learned Queries),与三个损失函数进行训练。下面详细说明这三个损失函数。
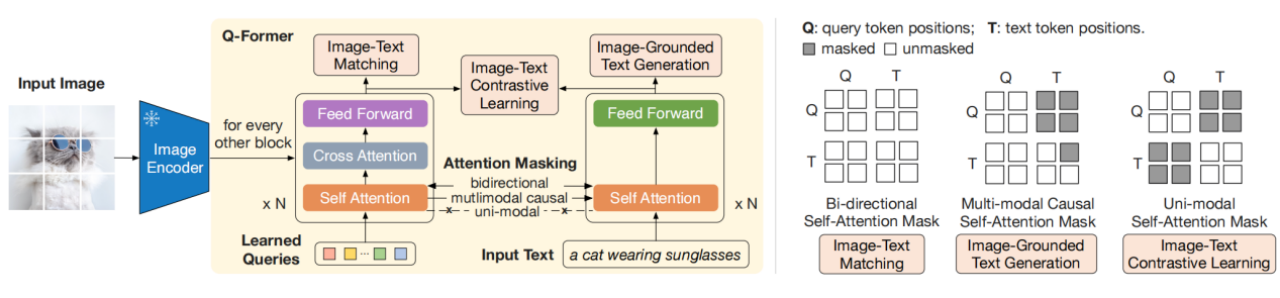
1)图文匹配损失(image-text matching loss)
(上图右部分的第一个矩阵)训练模型得到“图文细粒度对齐”的能力。
Query(这是Learne Queries和图片ViT编码经过cross-attention后的结果,后面统称为Query,不做翻译)和文本可以看到彼此,最终获得一个几率 (logit) 用以表示文字与图像是否匹配。这是一个二值分类任务,要求模型预测一个图像-文本对是正的(匹配的)还是负的(不匹配的)。
2)基于图像的文本生成损失(image-grounded text generation)
(上图右部分的第二个矩阵)训练模型得到“依据Query生成文本”的能力。
Query内部可以相互计算注意力但不计算文本词元对Query的注意力,同时文本内部的自注意力使用因果掩码且需计算所有Query对文本的注意力。
3)图文对比损失 (image-text contrastive loss)
(上图右部分的第三个矩阵)训练模型得到“图像信息与文本信息对齐”的能力。首先利用对比学习方法进行“单模态特征抽取”,然后通过相识度运算损失函数最大化互信息(Mutual Information)。
每个Query的输出都与文本输出的 CLS 词元计算成对相似度,并从中选择相似度最高的一个最终计算对比损失。在该损失函数下,查询嵌入和文本不会 “看到” 彼此。
1.2 第二阶段训练
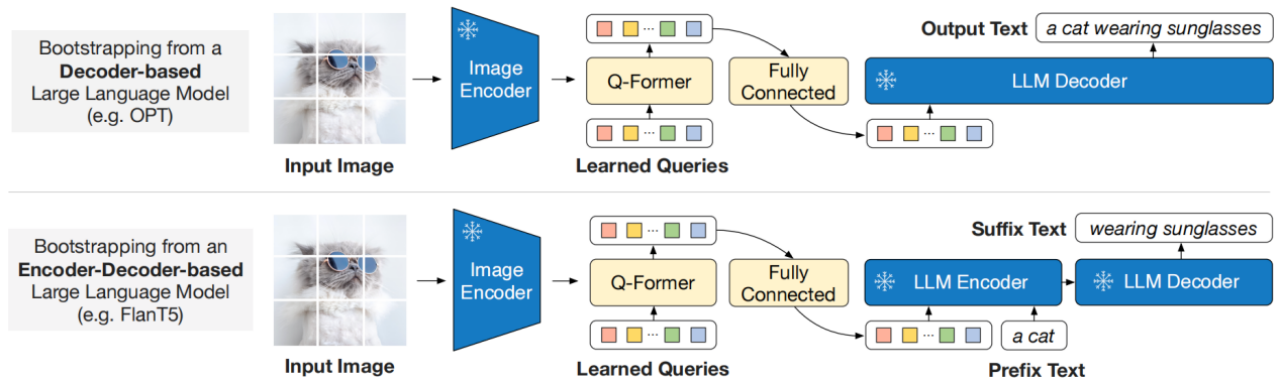
我们将Q-Frormer(附带冻结图像编码器)连接到冻结LLM,以获取LLM的生成语言能力。如下图所示,我们使用了一个全连接层,将输出Query embedding Z线性投影到与LLM的文本嵌入相同的维度。然后,将线性投影的Query embedding前置到输入text embedding上,作为软视觉提示(soft visual prompts)。以上的做法都是依据于“Q-Former在第一训练阶段被用来训练提取视觉表示”这一前提。这减少了LLM学习视觉-语言对齐的负担,从而减轻了灾难性的遗忘问题。
二、SEEChat,自己的孩子自己得疼。
论文链接:
GitHub - 360CVGroup/SEEChat: Multimodal chatbot with computer vision capabilities integrated
这是我们的团队搞的VQA多模态大模型。搞到最后身心俱疲。这可能就是资源少的团队搞大模型的能力天花板了。
总体思路:整体框架与Blip2相似,语言模块改为清华大学的ChatGLM-6B。
1. 训练过程
1.1 第一阶段训练 图文对齐
如同Blip2第一训练阶段。使用360人工智能研究院开源的Zero数据集,共计2300万图文对桥接层进行训练。这里训练了50轮。
1.2 第二阶段训练 人机对齐
如同Blip2第二训练阶段。衔接GLM中文语音模块,使用LLAVA开源数据集158K instruction翻译成中文的数据对桥接层和语言模型部分进行微调。这部分大约训练300轮。
2. 推理过程
图像经ViT,和Learned Queries 在Q-Former进行cross-attention后,与文本embedding进行的拼接。拼接后的结果经语言模块ChatGLM-6B输出结果。
3. 小团队大模型天花板(因体量小,而无法解决的问题)
二轮微调训练的数据还不够。158K 万图文依然不够,让最后输出的所有问答结果都有一种图片描述caption的味道。尝试过加LoRA的方法,但是效果不好,大概率是数据集的问题。因为同样用LoRA的中文VQA算法,VisualGLM效果就很好。下面我给大家介绍一下。
三、VisualGLM,如要玩中文多模态,还是用这个吧
代码仓库:
GitHub - THUDM/VisualGLM-6B: Chinese and English multimodal conversational language model | 多模态中英双语对话语言模型
视频讲解:https://www.bilibili.com/video/BV14L411q7fk/
这个工程与360的SEEChat很相似,是GLM的官方多模态嫁接实现。但是因为清华的资源比较好,在“图像编码器ViT”与“语言模型ChatGLM”处都使用LoRA进行训练,效果会变好。
训练过程
第一训练阶段,使用大量低质量图文对,对 ViT的LoRA,Q-Former进行学习。第二训练阶段使用高质量图文对,对Q-Former,ChatGLM的LoRA进行微调学习。
注意:在清华大学公布的视频中,作者提到并没有完全冻结ViT与ChatGLM的参数,为了避免灾难性遗忘。但究竟什么叫“没有完全冻结”参数,作者并没有详细公布。
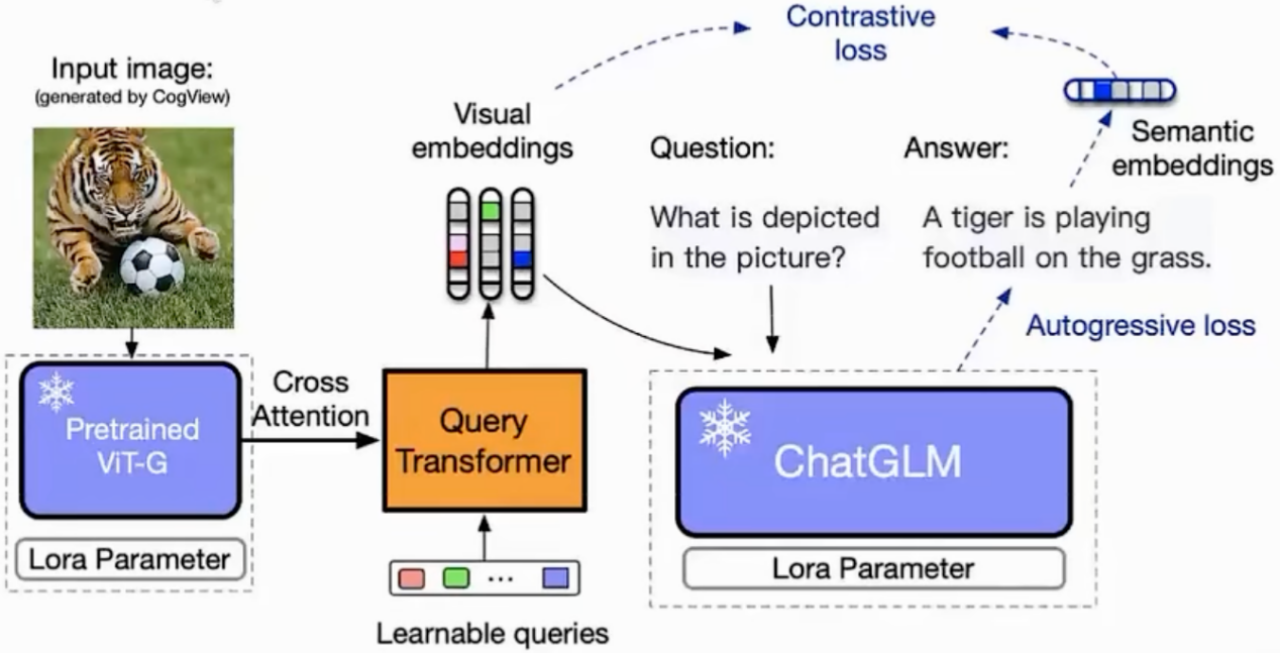
训练目标
对比损失(如上图):输入ChatGLM的视觉特征与对应文本的语义特征对齐。
自回归损失:根据图像生成正确的文本
训练数据
1) CogView工作积累的30M中文图文对
2) 精选LAION+CC12M的100M英文图文对
3) 来自其他工作和数据集的视觉问答指令微调数据集
4) 自己构建的数据集(有这个,就很难复现了)
VisualGLM-6B更令人兴奋的一个方面是其集成了模型量化技术,用户可以在消费级显卡上本地部署模型,INT4量化级别只需要8.7G的显存。同时还有微调模块代码。
四、类BLIP2模型的通病
1. 图像细节信息捕捉不足
这大概率是ViT的问题了。ViT对全局性描述很好,但细节处理能力一般。个人感觉将ViT改进成其他transform视觉backbone网络,是未来发展的趋势。
2. 大语言模型常见问题:复读机行为,重复用户问题
复读机问题比如:ABCABCABC 不断循环输出到 max length。对于这种现象可能得解释是:生成文本本质上是找条件概率的最大值token。生成重复内容,条件概率 P(B|A)一直是最大的。这是语言模型本身的一个弱点,无论是否微调,都有可能出现。并且,理论上良好的指令微调能够缓解大语言模型生成重复内容的问题。
重复用户问题,原因未知。